【无标题】
StarRocks Lakehouse 快速入门旨在帮助大家快速了解湖仓相关技术,内容涵盖关键特性介绍、独特的优势、使用场景和如何与 StarRocks 快速构建一套解决方案。最后大家也可以通过用户真实的使用场景来了解 StarRocks Lakehouse 的最佳实践!
本文主要分享 StarRocks Hive Catalog 最佳实践。场景基于订单管理的具体应用展开。
Apache Hive 介绍
Apache Hive 是一个分布式、容错的数据仓库系统,能够实现大规模的分析。Hive Metastore (HMS) 提供了一个元数据存储库,可以轻松分析这些元数据以做出基于数据的决策,因此它是许多数据湖架构中的关键组件。Hive 构建于 Apache Hadoop 之上,并通过 HDFS 支持在 S3、ADLS、GS 等存储上的数据管理。Hive 允许用户使用 SQL 读取、写入和管理 PB 级的数据。
Hive 架构与关键特性
架构设计

关键特性
-
Hive-Server 2 (HS2) :支持多客户端并发和身份验证,优化了对 JDBC 和 ODBC 客户端的支持。
-
Hive Metastore Server (HMS) :用于存储 Hive 表及分区元数据,支持 Spark 和 Presto 等多种开源软件,是数据湖的重要组成部分。
-
Hive ACID :为 ORC 表提供完整的 ACID 支持,并为其他格式提供仅插入操作的支持。
-
Hive Iceberg :通过 Hive StorageHandler 原生支持 Apache Iceberg 表,适合云原生的高性能场景。
-
安全性与可观测性 :支持 Kerberos 认证,集成 Apache Ranger 和 Apache Atlas。
-
Hive LLAP :实现低延迟、交互式 SQL 查询,优化数据缓存,加速查询。
-
查询优化 :基于 Apache Calcite 的成本优化器(CBO)提升查询效率。
Apache Hive 的优势
-
数据仓库 功能 :支持数据库、表、分区等基本功能,方便数据管理与查询。
-
多执行引擎 :支持MapReduce、Tez、Spark等引擎,用户可根据需求优化查询性能。
-
扩展性 :支持自定义函数(UDF),可与其他Hadoop生态工具集成,提高处理灵活性。
-
适合批处理 :特别适合大规模数据分析、报表生成和ETL任务。
-
易于集成 :可与Flume、Sqoop、Oozie等工具集成,增强大数据处理能力。
Apache Hive 的使用场景
-
数据仓库 :将Hadoop中的数据转换为SQL查询形式,提供数据仓库功能,便于用户查询和管理数据。
-
数据分析 :通过HiveQL进行数据查询、聚合和过滤,适合大规模数据分析场景。
-
数据挖掘 :与机器学习工具集成,进行数据挖掘与模式分析。
-
ETL操作 :适用于大规模日志分析与历史数据处理,优化系统性能,理解用户行为。
-
离线 处理 :适合离线的大数据处理场景,批处理引擎支持大规模查询任务。
-
工具集成 :与Apache Spark、Mahout等工具无缝集成,提升查询性能和数据建模能力。
StarRocks Hive Catalog
Hive 作为经典的MapReduce 底层引擎,常用于批处理和离线分析,在实时分析领域则由于查询性能相对较低,资源使用率较高则存在短板。
而 StarRocks 是一个 MPP 数据库,能够快速处理大规模数据集的复杂查询,支持实时分析,提供快速的查询响应,适合需要即时数据反馈的场景。
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、S3、OSS,支持的文件格式包括 Parquet、ORC、CSV。
通过 StarRocks Hive Catalog,实现了 StarRocks 与 Hive 的无缝集成,结合了两者的优势。在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/ 报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能。
数据模型
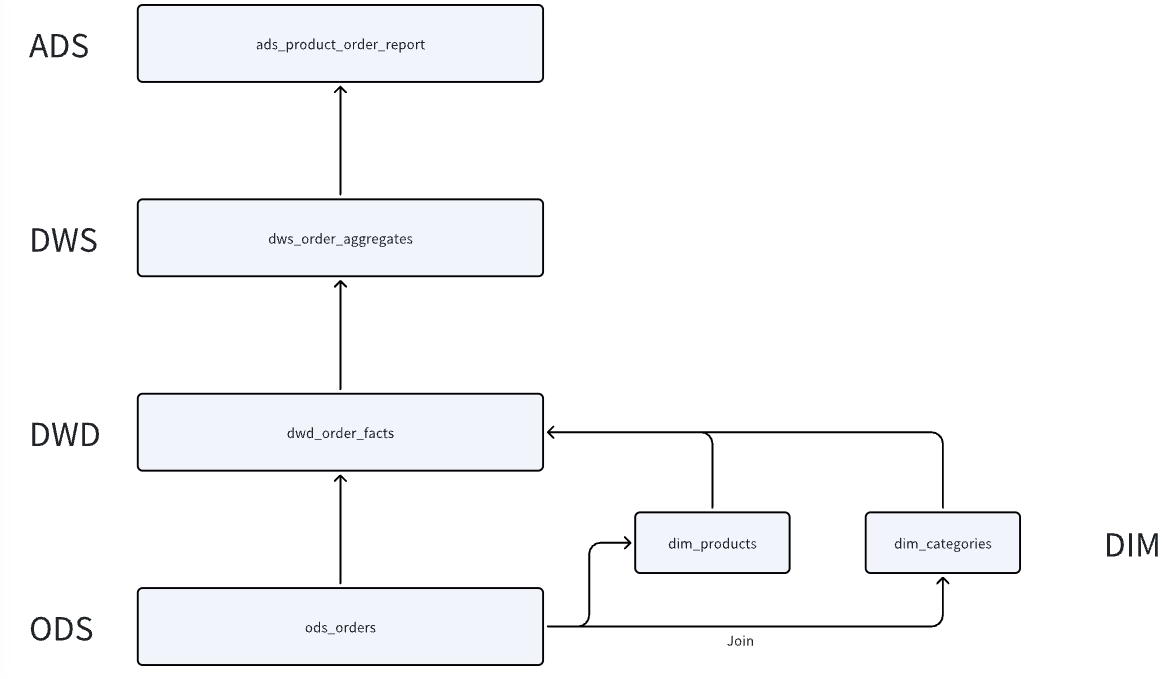
技术架构演进
StarRocks Hive Catalog可以按照如下的方式演进:
直接查 Hive 表的数据 --> 使用 Data Cache 加速查询 Hive 表的数据 --> 使用 Data Cache 和 异步物化视图 加速查询 Hive 表的数据
-
StarRocks Hive Catalog直接查结果集
-
所有ETL都是在Hive中完成,StarRocks利用Hive Catalog查询DWD、DWS和ADS的结果集
-
利用StarRocks Hive Catalog + datacache现查
-
只有ODS和DWD是在Hive中完成,后续DWS和ADS都是利用StarRocks的Hive Catalog现查(现计算)
-
异步物化视图加速
-
只有ODS在Hive侧,DWD和DWS都是利用StarRocks异步物化视图构建,ADS直查

快速开始
1.基础环境

2.Hive建表
create database orders;
--ODS
--用于导入本地生成的测试数据过渡用的
CREATE EXTERNAL TABLE IF NOT EXISTS ods_orders_text(
order_id STRING,
user_id STRING,
order_time STRING,
product_id STRING,
quantity INT,
price DECIMAL(10, 2),
order_status STRING
)
COMMENT '订单操作数据存储表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
CREATE TABLE IF NOT EXISTS ods_orders (
order_id INT,
user_id INT,
order_time STRING,
product_id INT,
quantity INT,
price DOUBLE,
order_status STRING
)
COMMENT '订单操作数据存储表'
PARTITIONED BY (order_date STRING)
STORED AS PARQUET;
CREATE TABLE IF NOT EXISTS dim_products (
product_id INT,
product_name STRING,
category_id INT,
price DECIMAL(10, 2),
product_description STRING
)
COMMENT '产品维度表'
STORED AS PARQUET;
CREATE TABLE IF NOT EXISTS dim_categories (
category_id INT,
category_name STRING,
category_description STRING
)
COMMENT '分类维度表'
STORED AS PARQUET;
--DWD
CREATE TABLE IF NOT EXISTS dwd_order_facts (
order_id STRING,
user_id STRING,
order_time STRING,
product_id STRING,
quantity INT,
price DECIMAL(10, 2),
order_status STRING,
product_name STRING,
category_id STRING,
category_name STRING
)
COMMENT '订单事实表'
PARTITIONED BY (order_date DATE)
STORED AS PARQUET;
3. 数据构造
3.1构造维表数据
#用于生成随机数
CREATE TABLE aux_order_data (seq_num INT);
#!/usr/bin/env python3
with open('aux_order_data.txt', 'w') as f:
for i in range(1, 10000001):
f.write("{}\n".format(i))
LOAD DATA LOCAL INPATH '/home/disk1/sr/aux_order_data.txt' INTO TABLE aux_order_data;
INSERT INTO dim_products
SELECT
floor(RAND() * 10000) + 1 AS product_id,
CONCAT('产品名称', floor(RAND() * 10000) + 1) AS product_name,
floor(RAND() * 1000) + 1 AS category_id,
ROUND(100 + RAND() * 5000, 2) AS price,
CONCAT('产品描述', floor(RAND() * 100)) AS product_description
FROM aux_order_data a
CROSS JOIN aux_order_data b
LIMIT 10000;
INSERT INTO dim_categories
SELECT
floor(RAND() * 1000) + 1 AS category_id,
CONCAT('分类名称', floor(RAND() * 1000) + 1) AS category_name,
CONCAT('分类描述', floor(RAND() * 100)) AS category_description
FROM aux_order_data a
CROSS JOIN aux_order_data b
LIMIT 1000;
3.2 构造ODS数据
分别构造2024年8月3号到8月5号的数
#!/usr/bin/env python3
import random
import time
def generate_order_data(num_records):
with open('ods_orders.txt', 'w') as f:
for i in range(1, num_records + 1):
order_id = i
user_id = random.randint(1, 1000)
order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722614400, 1722700800))) #替换开始和结束时间戳分别为8月3、4、5号
product_id = random.randint(1, 10000)
quantity = random.randint(1, 10)
price = round(random.uniform(10, 1000), 2)
order_status = '已完成' if random.random() < 0.9 else '已取消'
f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n")
generate_order_data(10000000)
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders.txt' INTO TABLE ods_orders_text;
insert
overwrite table ods_orders PARTITION (order_date)
select
order_id,
user_id,
order_time,
product_id,
quantity,
price,
order_status,
substr(order_time, 1, 10) as order_date
from
ods_orders_text;
3.3 构造DWD数据
INSERT OVERWRITE table dwd_order_facts PARTITION (order_date)
SELECT
o.order_id,
o.user_id,
o.order_time,
o.product_id,
o.quantity,
o.price,
COALESCE(o.order_status,'UNKNOWN'),
p.product_name,
p.category_id,
c.category_name,
o.order_date
FROM ods_orders o
JOIN dim_products p ON o.product_id = p.product_id
JOIN dim_categories c ON p.category_id = c.category_id
where o.price > 0;
3.4 构造DWS数据
CREATE TABLE IF NOT EXISTS dws_order_aggregates (
user_id STRING,
category_name STRING,
order_date DATE,
total_quantity INT,
total_revenue DECIMAL(10, 2),
total_orders INT
)
COMMENT '订单聚合服务表'
STORED AS PARQUET;
INSERT OVERWRITE table dws_order_aggregates
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
3.5 构造ADS数据
CREATE TABLE IF NOT EXISTS ads_product_order_report (
category_name STRING,
report_date STRING,
total_orders INT,
total_quantity INT,
total_revenue DECIMAL(10, 2)
)
COMMENT 'TOP商品报告表'
STORED AS PARQUET;
WITH ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates
)
INSERT OVERWRITE table ads_product_order_report
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;
4. Hive Catalog 打通
Hive配置和Hadoop配置
scp hive-site.xml hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/fe/conf
scp hdfs-site.xml core-site.xml sr@node:/home/disk1/sr/be/conf
重启BE和FE加载配置
./bin/stop_be.sh
./bin/start_be.sh --daemon
./bin/stop_fe.sh
./bin/start_fe.sh --daemon
5. 湖分析
5.1 Hive Catalog查Hive结果集
DWS
CREATE EXTERNAL CATALOG `hive_catalog_krb5_sr`
PROPERTIES (
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://cs02.starrocks.com:9083",
"type" = "hive"
)
set catalog hive_catalog_krb5;
use orders;
SELECT * from dws_order_aggregates;

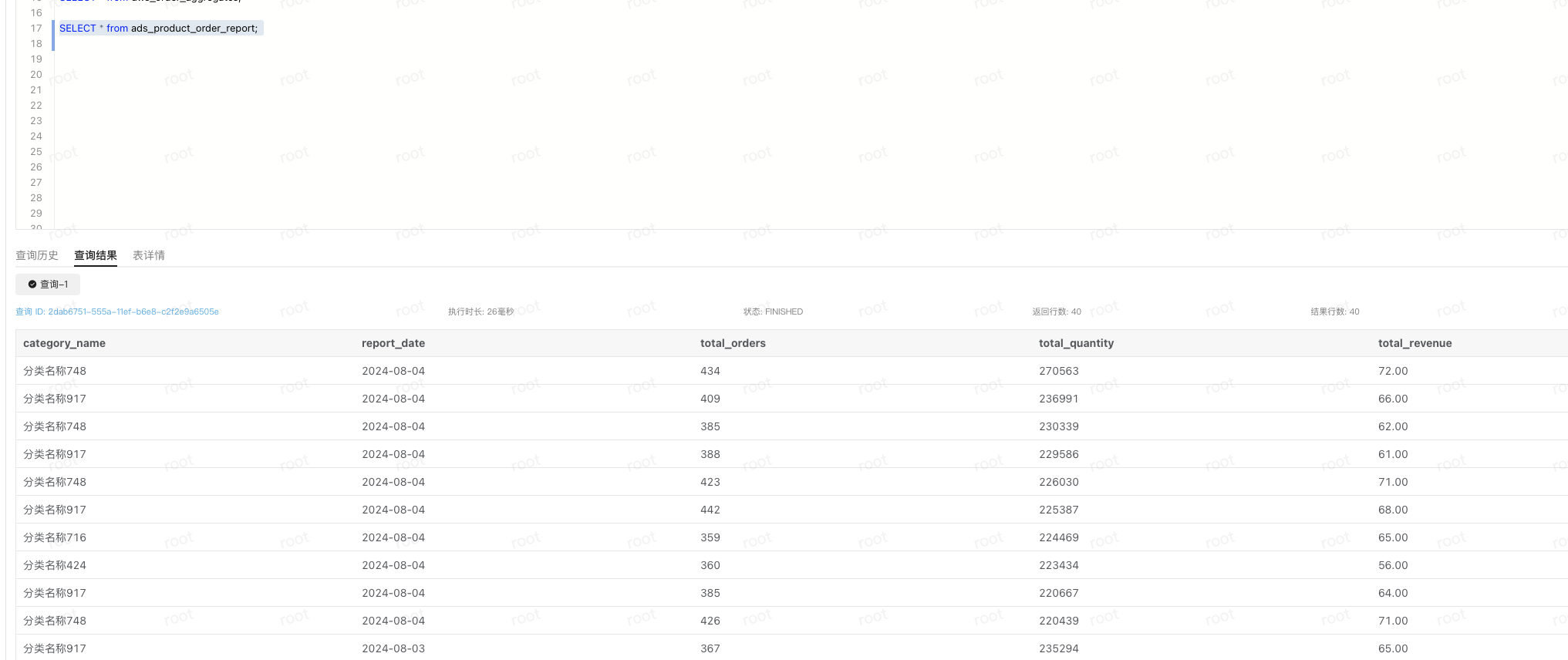
ADS
SELECT * from ads_product_order_report;
5.2 利用StarRocks Hive Catalog + datacache现查
--打开datacache
SET enable_scan_datacache = true;
be配置(be.conf)开启datacache
datacache_disk_path = /data2/datacache
datacache_enable = true
datacache_disk_size = 200G
--cache预加载
cache select * from hive_catalog_krb5.orders.dwd_order_facts;

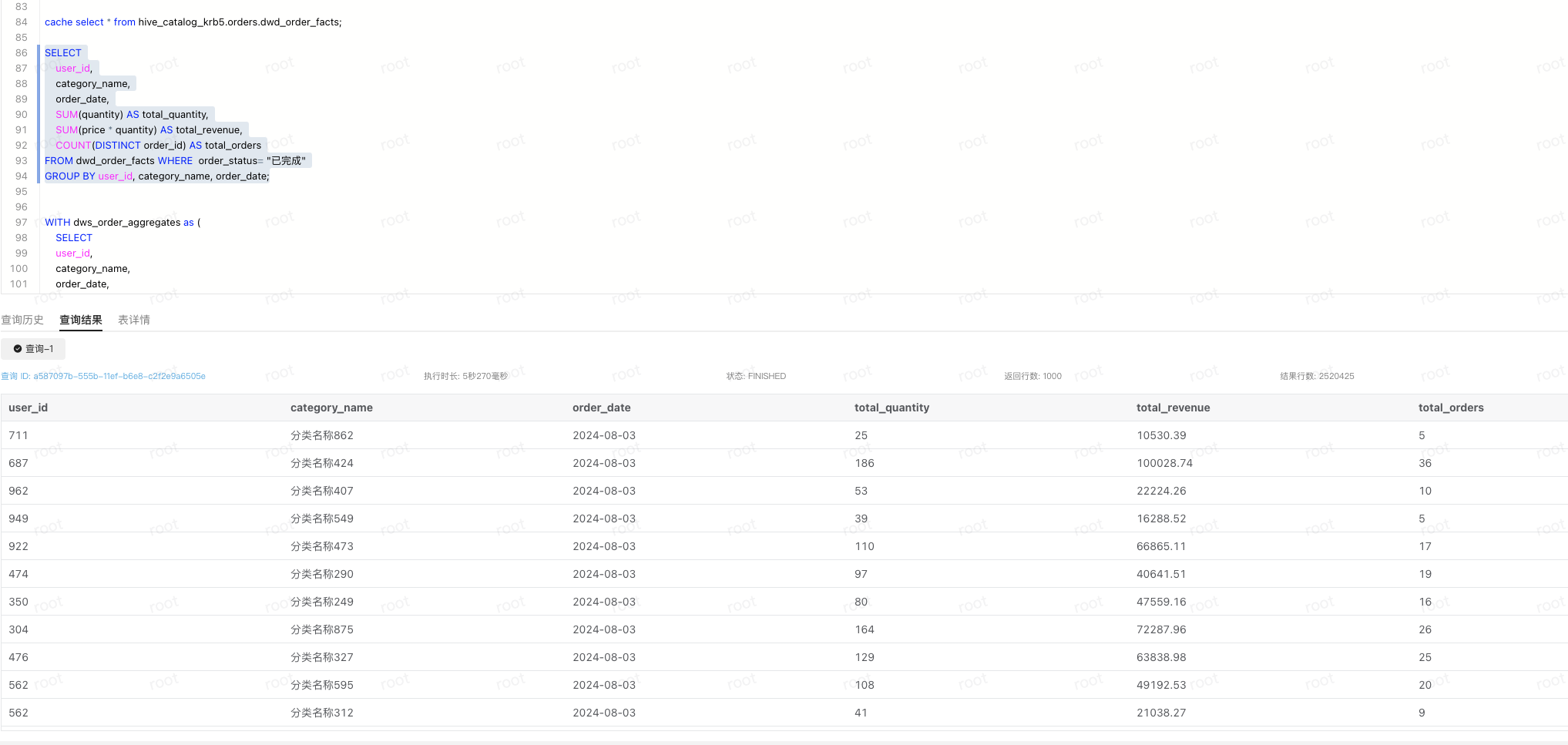
DWS
set catalog hive_catalog_krb5;
use orders;
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
ADS
set catalog hive_catalog_krb5;
use orders;
WITH dws_order_aggregates as (
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date
)
, ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates
)
-- 选择排名前10的类别
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;

5.3 异步物化视图加速
set catalog default_catalog;
use orders;
CREATE MATERIALIZED VIEW dwd_order_facts_mv PARTITION BY str2date(order_date,'%Y-%m-%d') DISTRIBUTED BY HASH(`order_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 01:00:00') EVERY (interval 1 day) as
SELECT
o.order_date,
o.order_id,
o.user_id,
o.order_time,
o.product_id,
o.quantity,
o.price,
COALESCE(o.order_status,'UNKNOWN') as order_status,
p.product_name,
p.category_id,
c.category_name
FROM hive_catalog_krb5.orders.ods_orders o
JOIN hive_catalog_krb5.orders.dim_products p ON o.product_id = p.product_id
JOIN hive_catalog_krb5.orders.dim_categories c ON p.category_id = c.category_id
where o.price > 0;
新分区自动感知
新增8月6号的数据(hive侧),构造数据
#!/usr/bin/env python3
import random
import time
def generate_order_data(num_records):
with open('ods_orders_0806.txt', 'w') as f:
for i in range(1, num_records + 1):
order_id = i
user_id = random.randint(1, 1000)
order_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1722873600, 1722959999)))
product_id = random.randint(1, 10000)
quantity = random.randint(1, 10)
price = round(random.uniform(10, 1000), 2)
order_status = '已完成' if random.random() < 0.9 else '已取消'
f.write(f"{order_id},{user_id},{order_time},{product_id},{quantity},{price},{order_status}\n")
generate_order_data(10000000)
--hive侧执行
LOAD DATA LOCAL INPATH '/home/disk1/sr/ods_orders_0806.txt' INTO TABLE ods_orders_text;
INSERT OVERWRITE table ods_orders PARTITION (order_date="2024-08-06") select * from ods_orders_text where order_date >= "2024-08-06 00:00:00";
--手动触发一次物化视图刷新
REFRESH MATERIALIZED VIEW dwd_order_facts_mv;
--查看对应的物化视图刷新状态为SUCCESS后,即可进行后续的查询
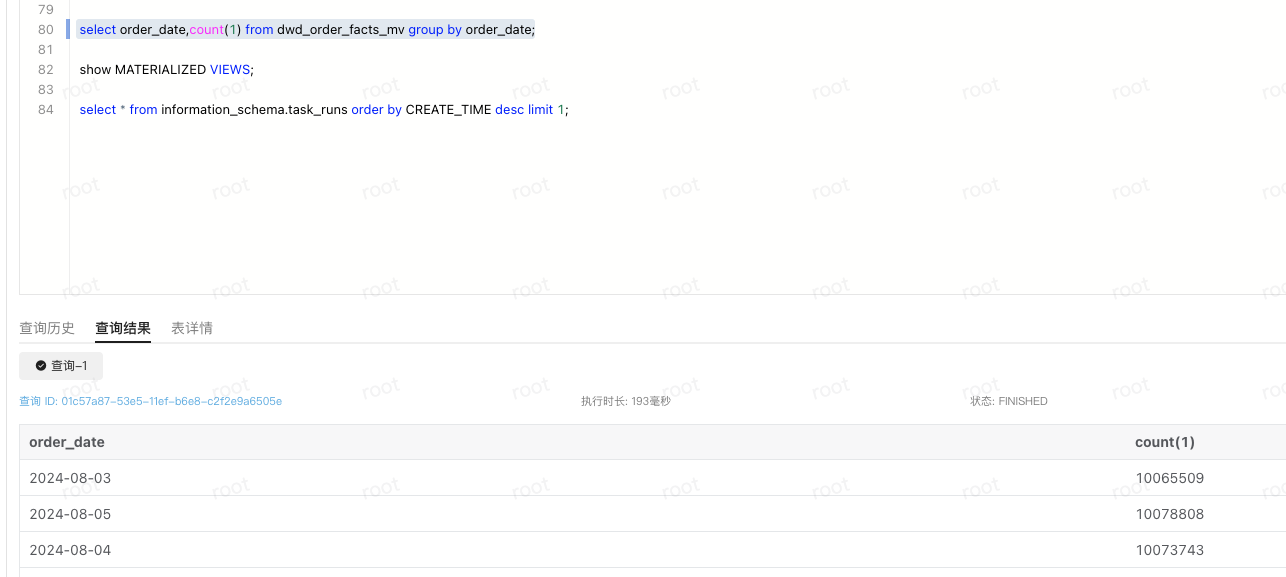
select * from information_schema.task_runs order by CREATE_TIME desc limit 1;
--查看物化视图是否感知到新的数据
select order_date,count(1) from dwd_order_facts_mv group by order_date;

DWS
set catalog default_catalog;
use orders;
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts_mv WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;

ADS
set catalog default_catalog;
use orders;
CREATE MATERIALIZED VIEW dws_order_aggregates_mv PARTITION BY str2date(order_date,'%Y-%m-%d') DISTRIBUTED BY HASH(`user_id`) BUCKETS 12 PROPERTIES ("replication_num" = "3") REFRESH ASYNC START('2024-08-01 04:00:00') EVERY (interval 1 day) as
SELECT
user_id,
category_name,
order_date,
SUM(quantity) AS total_quantity,
SUM(price * quantity) AS total_revenue,
COUNT(DISTINCT order_id) AS total_orders
FROM dwd_order_facts_mv WHERE order_status= "已完成"
GROUP BY user_id, category_name, order_date;
--手动触发一次刷新
REFRESH MATERIALIZED VIEW dws_order_aggregates_mv;
--查看对应的物化视图刷新状态为SUCCESS后,即可进行后续的查询
select * from information_schema.task_runs order by CREATE_TIME desc limit 1;
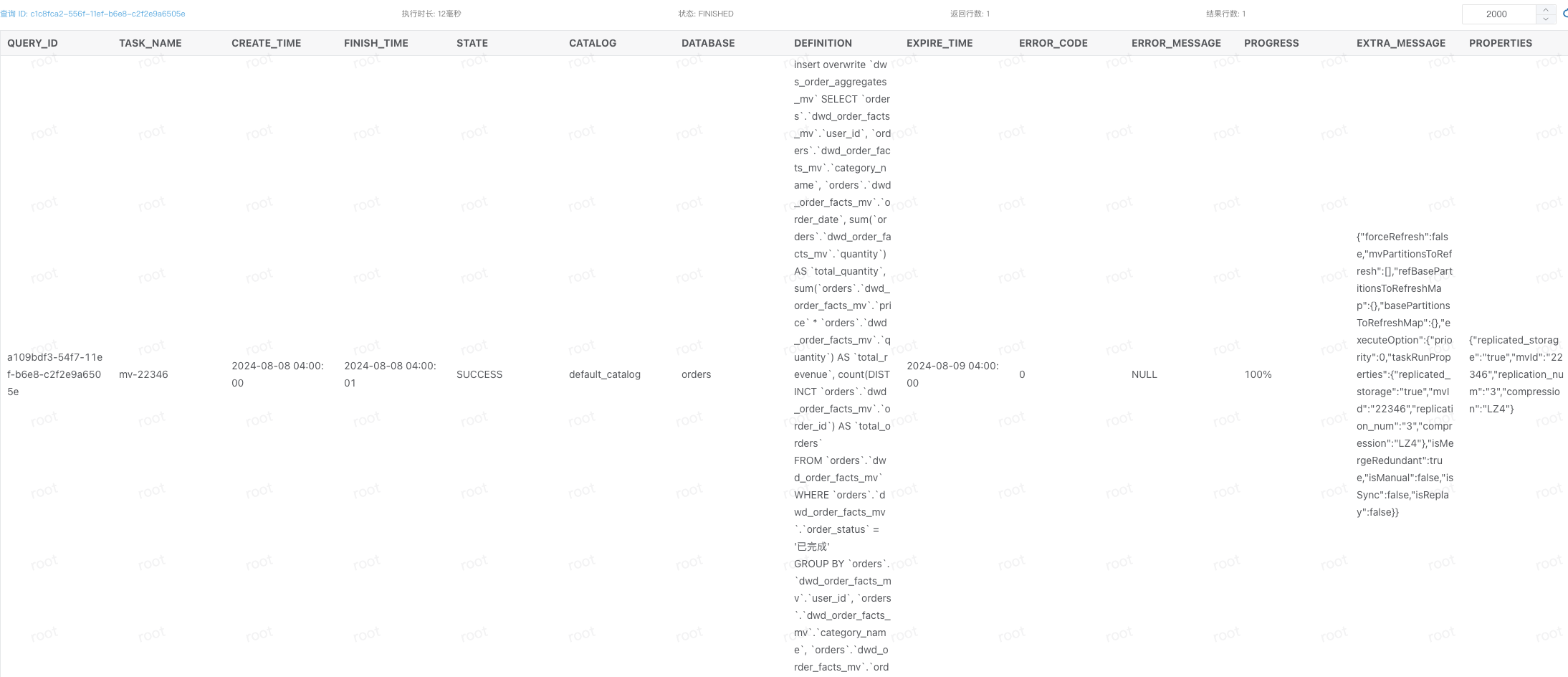
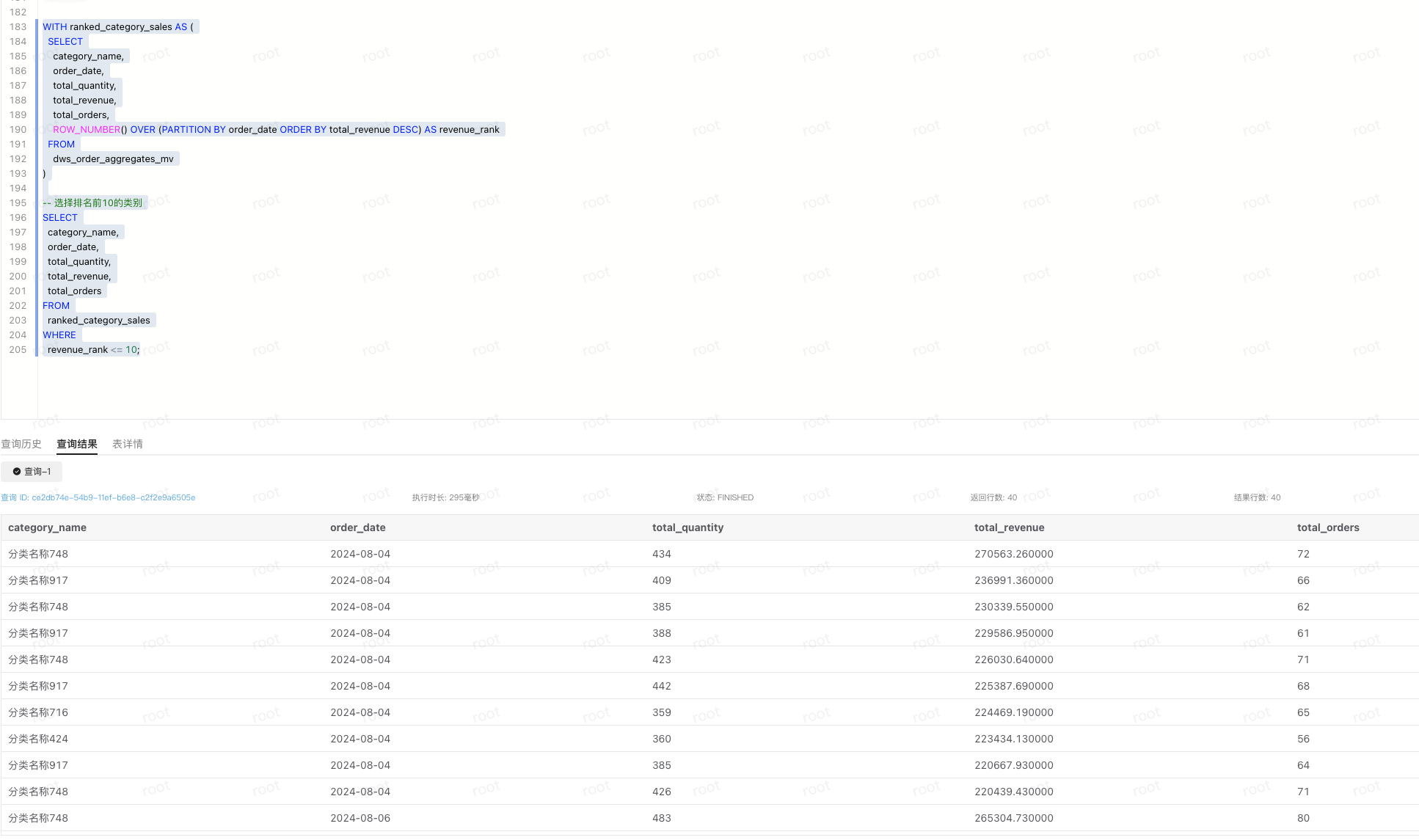
WITH ranked_category_sales AS (
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_revenue DESC) AS revenue_rank
FROM
dws_order_aggregates_mv
)
-- 选择排名前10的类别
SELECT
category_name,
order_date,
total_quantity,
total_revenue,
total_orders
FROM
ranked_category_sales
WHERE
revenue_rank <= 10;
总结
-
在大多数场景下,利用 StarRocks Hive Catalog 结合 DataCache 能很好地满足湖分析需求。
-
借助 StarRocks 的异步物化视图,不仅可以简化 ETL 流程,降低业务复杂度,还能同时确保查询性能。
用户案例
更多交流,联系我们:StarRocks
原文地址:https://blog.csdn.net/StarRocks/article/details/143024809
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!