编译和链接
啥
1.我们输入的代码在变为命令时,要经过翻译环境(将代码变为可执行的机器指令)和运行环境(执行对应指令)
即将.c文件转化为.exe文件
2. 翻译环境具体搜:
3.编译具体三个步骤(预编译(也称预处理),编译,汇编)搜:
预处理:
4.在C语言中,#开头的指令都是预处理指令,在预处理阶段完成,
5.预处理过程中,进行了
(1).头文件的包含还有#define的替换(就是运行了#开头的指令)
(2).注释的删除(替换成了空格)
6.在预处理过程中,源文件和头文件都会被处理成.i为后缀的文件
7.预处理阶段主要处理#开头的指令,处理规则如下
将所有的 #define 删除,并展开所有的宏定义。
处理所有的条件编译指令,如: #if、#elif、#else
处理#include 预编译指令,将包含的头文件的内容插入到该预编译指令的位置。
删除所有的注释
添加行号和文件名标识,方便后续编译器生成调试信息等
或保留所有的#pragma的编译器指令,编译器后续会使用。
编译:
8.将C语言代码转化为汇编
9.词法分析:
源代码被输入到扫描器中,扫描器的任务就是简单的进行词法分析,把代码中的字符分割成一系列的记号(关键字、标识符、字面量、特殊字符等)。(完全肢解)
10.语法分析:
接下来语法分析器将对被扫描产生的记号进行语法分析,从而产生语法树。这些语法树是以表达式为节点的树.具体搜:
11.语义分析:
由语义分析器来完成语义分析,即对表达式的语法层面分析。编译器所能做的分析是语义的静态分析。静态语义分析通常包括了声明和类型的匹配,类型的转换等。这个阶段会报告错误的语法信息。具体搜:
汇编:
12.汇编器将汇编代码转转变成机器可执行的指令,每一个汇编语句几乎都对应一条机器指令。就是根据汇编指令和机器指令的对照表一一进行翻译,不做指令优化。
链接:
13.链接是一个复杂的过程,链接的时候需要把一堆文件链接在一起才生成可执行程序。
链接过程主要包括了地址和空间分配,符号决议和重定位等这些步骤。
链接解决的是一个项目中多文件、多模块之间互相调用的问题.
插播一下:
运用外部函数的话要用ertern
例:
在2.c中代码是:
int Add(int x, int y)
{
return x + y;
}
那么要想在1.c中运用该函数,则要这样:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
extern int Add(int, int);
int main()
{
printf("%d\n", Add(2, 3));
return 0;
}链接继续:
在编译(小编译阶段)阶段有一个符号汇总,就是相当于将各个.c文件中的符号各自汇集起来
而在汇编阶段有一个叫形成符号表,相当于将各个.c文件中的符号各自汇集起来并形成表
而在链接阶段有一个叫符号决议和重定位,相当于将上边的几个表都汇集起来形成新表 (帮助上边插播的例子中的函数声明找到对应的对象函数)
重定位:
我们在test.c的文件中使用了add.c文件中的Add 函数和g_val变量,我们在 test.c 文件中每一次使用Add 函数和 g_val的时候必须确切的知道Add 和 gval 的地址,但是由于每个文件是单独编译的,在编译器编译 test. c的时候并不知道Add 函数和 g_val 变量的地址,所以暂时把调用Add 的指令的目标地址和 g_val 的地址搁置。等待最后链接的时候由链接器根据引用的符号 Add 在其他模块中查找 Add 函数的地址,然后将 test, 中所有引用到 Add 的指令重新修正,让他们的目标地址为真正的 Add 函数的地址,对于全局变量 g_val 也是类似的方法来修正地址。而这个地址修正的过程也被叫做:重定位。
上边的那四个步骤更加详细的内容在<<编译原理>>可以看到
运行程序:
1.程序必须载入要内存中,在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2.接着程序的执行便开始了。接着便调用main函数。
3.开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址,程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
4.终止程序。正常终止main函数;也有可能是意外终止。
另:
1.对代码:
#define name content
在预处理阶段会将全部代码中的对应的name通通置换成content,不擅自加括号
例:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define m 100+3
int main()
{
printf("%d", m * 2);
//输出:106
return 0;
}2.#define后边定义的content可以是表达式,可以是整数,可以是字符串,可以是其它代码
例:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define w while(1)
int main()
{
w
{
printf("1");
}
//输出结果是死循环打印1
return 0;
}3.简而言之:#define name content就是将代码中的name全部替换成原封不动的content
4.\可以是续航符,示例:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define s(x) x*x
int main()
{
printf("%d %d %d", s(3)\
,
s(5), \
s(2));
//输出9 25 4
return 0;
}printf是一个整体不能这样写:
pr\
intf
5.用#define定义宏(宏也一样是完全替换和先替换在做下一步的操作):
例1:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define s(x) x*x
int main()
{
printf("%d\n", s(3));
//输出9
return 0;
}例2:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define s(x) x*x
int main()
{
printf("%d\n", s(3 + 1));
//输出结果:7.因为3 + 1 * 3 + 1
return 0;
}所以宏在书写的时候,尽量加括号
6.#define定义的宏不能递归
7.宏相比函数的优势是:
(1).规模更小,速度更快
(2).宏的参数无类型区别
(3).宏还可以传类型作为参数
例:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#define m(n, t) (t*)malloc(n * sizeof(t))
int main()
{
int* p = m(10, int);
return 0;
}劣势是:
(1).每次使用宏的时候一纷宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度.
(2).宏没法调试
(3).宏由于与类型无关,所以不够严谨
(4).宏可能会带来运算符优先级的问题,导致程序容易出错。
8.一般简单的运算用宏,复杂的运算用函数
9.宏和函数的对比(具体)搜
10.注:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main()
{
printf("hello world\n");
printf("hello ""world\n");
//上述代码效果一样
return 0;
}11.#运算符所执行的操作可以理解为字符串化
例:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define PRINTF(val, tem) printf("The val of "#val" is "tem"\n", val)
int main()
{
int a = 10;
printf("The val of a is %d\n", a);
PRINTF(a, "%d");
//第九行的代码即:
//printf("The val of ""a"" is ""%d""\n", a);
int b = 20;
printf("The val of b is %d\n", b);
PRINTF(b, "%d");
float c = 10.2f;
printf("The val of a is %f\n", c);
PRINTF(c, "%f");
/*输出结果:
The val of a is 10
The val of a is 10
The val of b is 20
The val of b is 20
The val of a is 10.200000
The val of c is 10.200000
*/
return 0;
}12.## 可以把位于它两边的符号合成一个符号,它允许宏定义从分离的文本片段创建标识符。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define G_MAX(type)\
type type##_MAX(type x, type y)\
{\
return (x>y?x:y);\
}
G_MAX(int)
G_MAX(float)
G_MAX(double)
//不能去掉##,因为去掉了之后就变为了type_MAX,他是一个新的东西,和type安全不同,
//编译器在预处理阶段不会将其化为对应的参数
int main()
{
printf("%d\n", int_MAX(3, 5));
printf("%f\n", float_MAX(3.3f, 5.5f));
printf("%lf\n", double_MAX(3.99, 5.33));
/*
输出结果:
5
5.500000
5.330000
*/
return 0;
}上边这个用了宏来定义函数
13.命名约定:
函数名一般不全为大写
宏一般全为大写
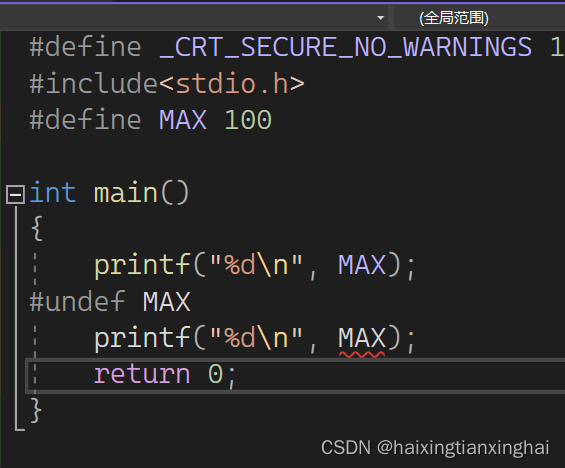
14.#undef可以用来移除一个宏定义
例:
15.命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号用于启动编译过程。假定某个程序中声明了一个某个长度的数组,如果其中一个机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要一个大些的数组。
16.条件编译:
条件编译是预处理阶段进行判断的
#ifdef m
代码块
#endif
若条件满足(即m被定义过(即在此之前有#define m))则执行代码块
还有:
#ifndef m
代码
#endif
若条件满足(即m没被定义过(即在此之前没有#define m))则执行代码
还有:
#if 常量表达式
代码
#endif
还有多分支的:
#if 常量表达式
代码
#elif 常量表达式
代码
#else 常量表达式
代码
#endif
还有嵌套指令:
类似于嵌套条件:
如:
if 条件:
if 条件:
if 条件:
这样的
接着:
1.嵌套文件包含:
我们已经知道, #include 指令替换的方式:预处理器先删除这条指令,并用包含文件的内容替换。
一个头文件被包含10次,那就实际被编译10次.
即在预处理的过程中将内容覆盖掉#include<......>
那么为了防止头文件的多次包含,我们通常运用条件编译的方式
例:
在test.c文件当中,有多个
#include"tem.h"
#include"tem.h"
#include"tem.h"
#include"tem.h"
那么为了防止出现头文件的多次包含
我们会在tem.h对应的文件当中这样写:
#ifndef _TEM_
#define _TEM_
一系列函数的声明
......
......
#endif
还有一种方式:
在tem.h最上边写上:
#pragma once即可
2.C推荐的书搜
原文地址:https://blog.csdn.net/haipengzhou/article/details/135999346
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!