一次奇怪的事故:机器网络连接打满,导致服务不可用
业务背景
发生事故的业务系统是一个toB业务,业务是服务很多中小企业进行某项公共信息指标查询。系统特点:业务处理相对简单,但是流量大,且对请求响应要求较高:
业务请求峰值qps达50w,平时流量达20w左右。
请求响应时间需控制在50ms内。
系统整体架构如下:
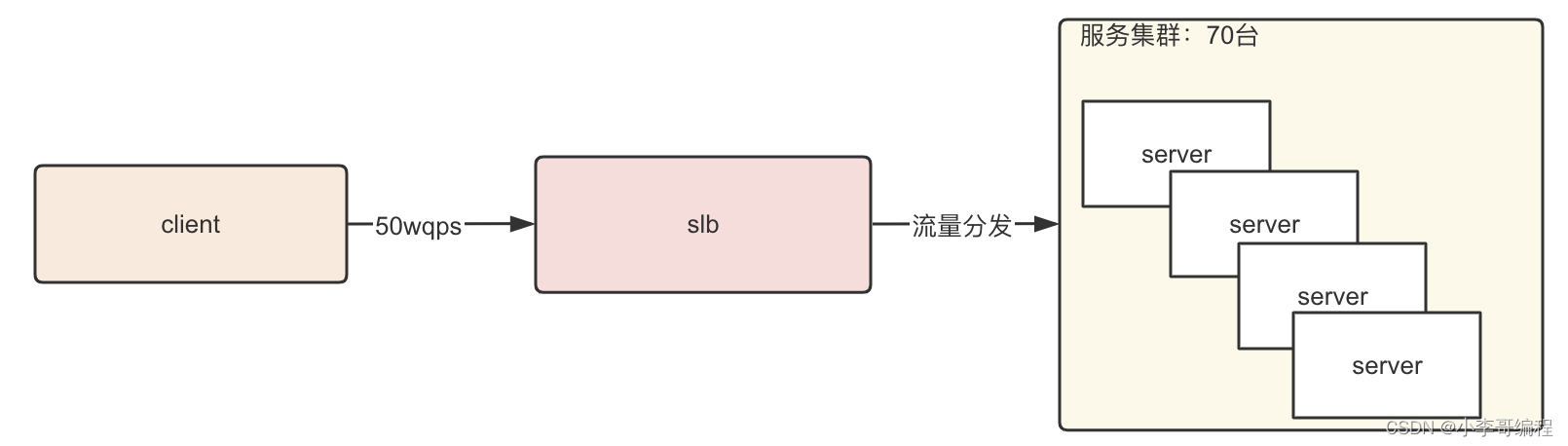
为了方便下文描述,我简化一下业务处理逻辑:根据请求的内容,从数据库中查询对应的结果,然后返回,为了支撑大并发,把数据库中的数据全部缓存到了redis中,简单来说就是查询redis,返回结果。
业务系统的实现技术也比较常规,采用springboot+redis来完成。为了保证系统的高可用性,我们在系统的入口处添加了限流处理,正常单机可以处理1w并发,为了防止系统过载,限流阈值设置8000qps,超过8000的流量会进行降级处理:返回一个默认值。
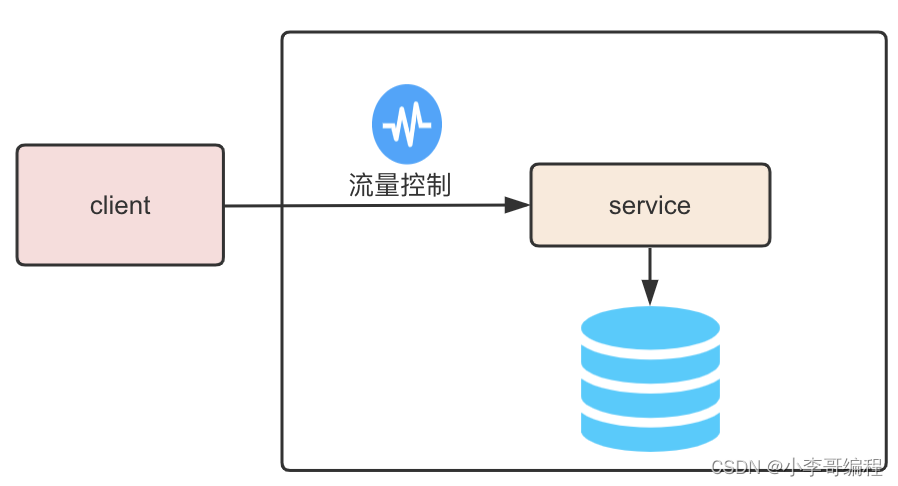
整个业务服务集群70台机器,可以轻松抗住50w并发
系统自上线后的半年多的时间内,都比较稳定。不过就在前几天出了一个奇怪的问题。
事故描述
业务系统的前端的slb告警:新建网络连接过多。
但是同一时刻后端服务的负载却是正常的,过了几秒后,
slb告警:与某几个后端服务实例健康检查失败。
随后该后端服务实例,从slb上被摘除,实例上流量跌零。
看到这一连串的告警,瞬间觉得很懵逼:发生什么事了?这个时候,查看监控,业务请求的qps并没有出现异常流量,请求的qps在45w左右,远没有超过系统容量。
查看日志发现:后端服务和redis之间的网络在刚刚出现了一点抖动,但是很快就恢复了正常了。
为什么后端服务与redis之间瞬间的网络抖动,会触发这么一连串的问题呢?更何况现在后端服务已经恢复了正常?
既然现在后端服务是正常的,那么就对这几个实例进行重启,实例重启后,实例重新注册到了slb上,流量正常进入,一切又恢复了正常。
事故起因
虽然线上问题解决了,但是我们心中的疑问并没有解决。
冷静过后,开发同学对刚刚的问题进行了复盘:为什么后端服务与redis之间短时间的网络抖动,会导致slb上连接被占满呢?看着两者好像没有什么关系
通过观察事故发生事件段内的监控和日志:
网络抖动期间,服务器实例创建了大量的网络连接,新建网络连接超过10000多个,平常只有几百个。
结合日志和监控,系统出现问题的大致流程如下:
后端服务与redis之间网络抖动,使服务实例与redis进行了连接重试,导致在那段时间内,该服务实例对请求的处理变慢。
但slb到该实例的请求转发还是正常,因为后端服务请求处理的比较慢,所以slb需要和后端服务建立新的网络连接来进行新的请求的发送,新建连接发送的请求,被处理的速度依旧很慢,所以需要不断的建立新的连接,很快导致该实例所在的机器的网络连接被占满。
机器网络连接被占满后,slb再将请求转发到该机器上时,网络连接的建立就会被阻塞,直至超时,而超时后,slb又会进行重试,导致出现的大量链接建立行为,也就出现了slb连接创建过多的告警,这个时候slb与该实例的健康检查请求也会出现问题,导致该实例从slb上被摘除。
问题分析
问题的原因虽然找到了,但是这里还有几个问题需要继续讨论一下:
后端服务的限流配置是:该服务实例1s最大可以处理8000个请求,而网络连接被打满时,最多可以建立8000个链接,难道限流没有生效吗?
通过查看日志发现,事故时间段内,并没有达到限流的条件,也没有进行限流相关的处理。
看到这里就有点想不明白了,为什么创建了8000个链接,却没有触发限流呢?
其实这里要了解一个springboot中tomcat中关于网络连接相关的配置了,下面是本项目中关于tomcat的配置:
server:
tomcat:
accept-count: 1000
max-connections: 8000
tomcat网络连接管理模型如下:
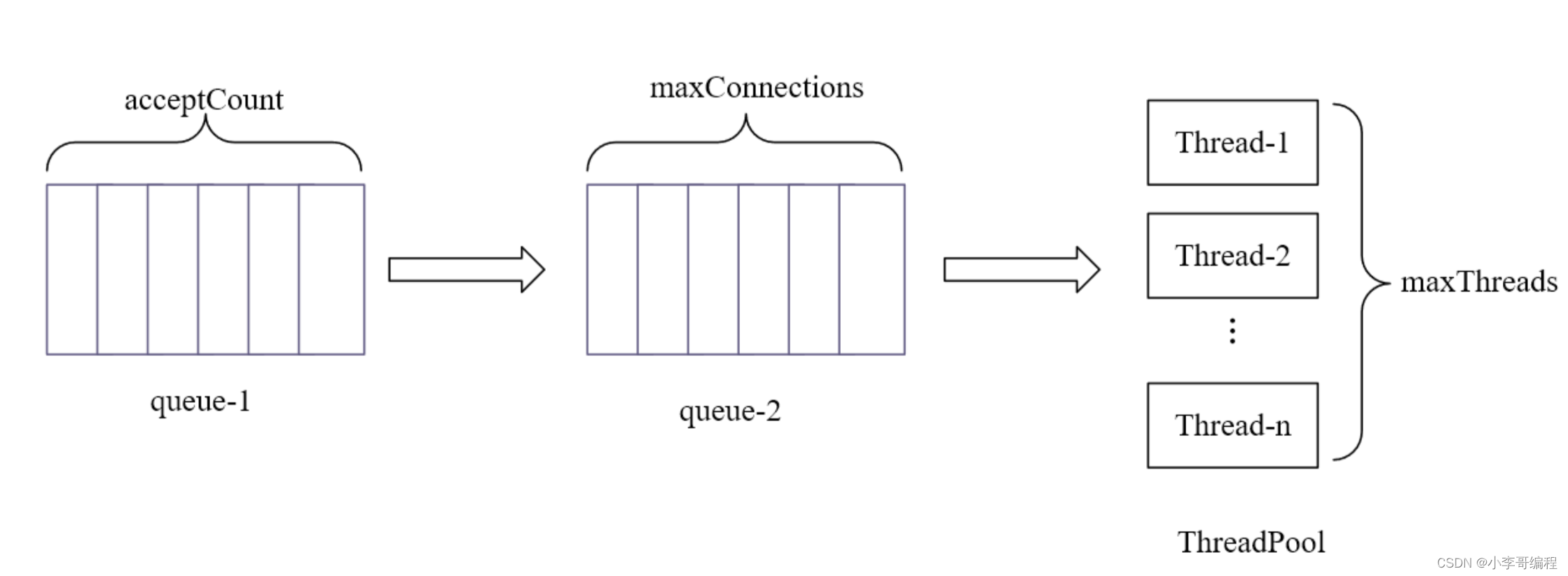
maxConnections:
服务程序可以在一定时间内接收并处理的连接数目如图1中queue-2,超过这个数,会根据acceptCount 这个值继续建立连接存放在queue-1中,但是该连接不会被处理,只有当queue-2中的连接数小于maxConnections值,queue-1中的连接才会进入queue-2中,该连接才有可能被执行。queue-2中的连接状态如图2标注所示。当同时请求数大于maxConnections+acceptCount 时,新的请求将会被拒绝连接。
acceptCount
超过maxConnections这个值的连接数将根据acceptCount这个值继续建立连接,如图1 queue-1,当queue-2的连接数小于maxConnections, queue-1的连接进入queue-2.
maxThreads:
服务程序可以同时处理的线程数如图1 ThreadPool,可以理解为通过设定 maxConnections=10 ,同时可以建立10个连接,maxThreads=3,则这10个连接中同时只有3个连接被处理,其余7个连接都在queue-2中等待被处理,等这3个连接处理完之后,其余的7个连接中的3个才可以被处理。如果处理完的3个连接关闭后,queue-1中就可以有3个连接进入queue-2。
总结来说:当客户端发送请求时,完成三次握手建立连接后,先进入queue1中,然后在转移到queue2中,然后在被ThreaPool中的线程处理。
我们系统中 maxConnections参数值 是8000,也就是进入系统的最大并发也就是8000,当系统请求处理比较慢时,系统中进行8000qps的限流,其实是不起作用的。
当服务业务处理变慢时,也就是ThreadPool从queue2中取出请求速度变慢了,那么queue2就会变满,进而queue1也会变满,此时,当再有请求过来时,就会等待,直到queue1空出一个位置,或者请求连接建立超时。
解决方案
到这里,我们明白了为什么机器实例的链接会被打满,以及系统服务的限流降级策无法生效了。
解决方案就比较简单了:
首先出现上述一连串问题的根本原因是:实例机器网络连接被占满。
所以解决方案的出发点就是:避免实例机器网络连接被占满,因此需要把maxConnections 和
我们将 acceptCount设置大一些。
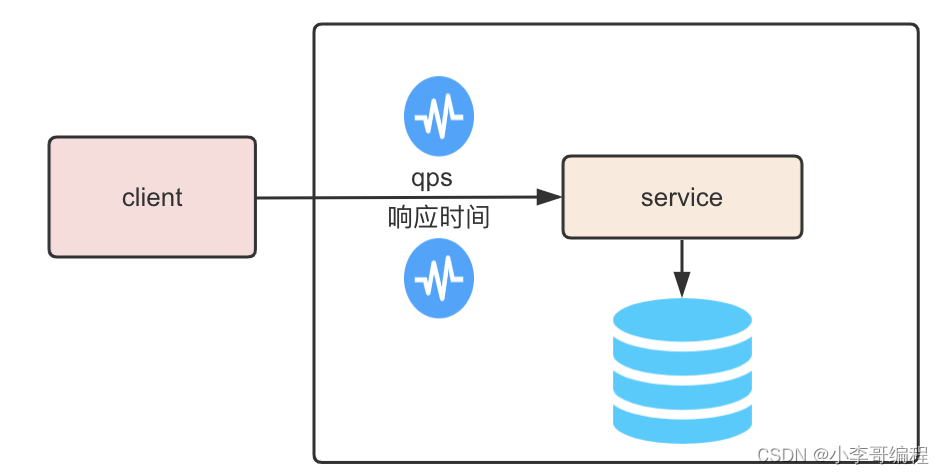
同时给业务系统添加请求处理响应时间的限流和降级策略。
这样可以保证流量都能进到系统中,而不至于连接建立失败,只是超过系统可承载的部分被限流出去了。
调整后的系统架构图如下:
原文地址:https://blog.csdn.net/weixin_45701550/article/details/136310121
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!