GitHub热榜第二的sora同款工具——DUSt3R
目录
Sora - 探索AI视频模型的无限可能
随着人工智能技术的飞速发展,AI视频模型已成为科技领域的新热点。而在这个浪潮中,OpenAI推出的首个AI视频模型Sora,以其卓越的性能和前瞻性的技术,引领着AI视频领域的创新发展。让我们将一起探讨Sora的技术特点、应用场景以及对未来创作方式的深远影响。
提醒:在发布作品前,请把不需要的内容删掉。
方向一:技术解析
提示:深入探讨Sora的技术架构、算法原理以及实现过程。通过专业性的文章或视频,向读者和观众展示Sora是如何通过深度学习和自然语言处理技术实现视频内容的智能生成和互动的。
方向二:应用场景
提示:想象并描述Sora在不同领域的应用场景,如影视制作、广告创意、游戏设计、在线教育等。通过故事性的叙述或案例分析,展示Sora如何为这些领域带来革命性的变革。
方向三:未来展望
提示:预测并讨论Sora对未来数字内容创作方式的影响。分析在AI视频模型的助力下,创作者们将如何突破传统限制,实现更加个性化、高效和创新的创作过程。
方向四:伦理与创意
提示:探讨在AI技术日益普及的背景下,如何平衡技术创新与伦理道德的关系。讨论Sora等AI视频模型在提升创意效率的同时,如何尊重原创精神、保护知识产权等问题。
方向五:用户体验与互动
提示:分析Sora如何提升用户体验和互动性。探讨在AI技术的驱动下,视频内容将如何更加智能地适应用户需求,实现更加自然和高效的人机交互。
只要两张照片,无需任何额外的数据,一个完整的模型就能生成了。
这个名为DUSt3R的新工具,用汤家凤的话说,就是火的一塌糊涂。才上线没多久,就成拥有了2k的star,可见其受欢迎的程度。
有网友实测,拍两张照片,真的就重建出了他家的厨房,整个过程耗时不到2秒钟!
(除了3D图,深度图、置信度图和点云图它都能一并给出)
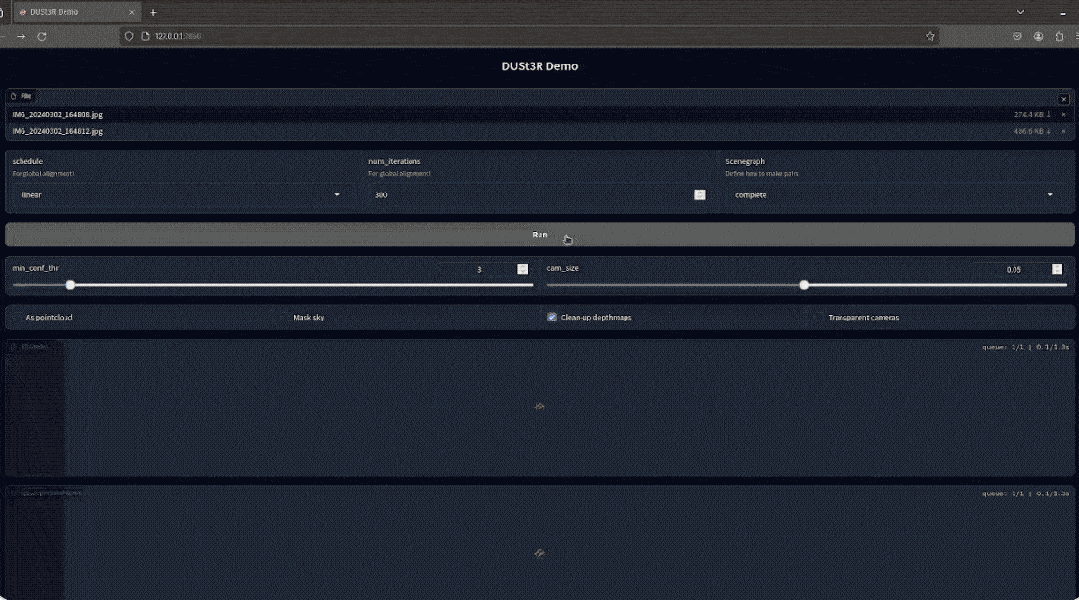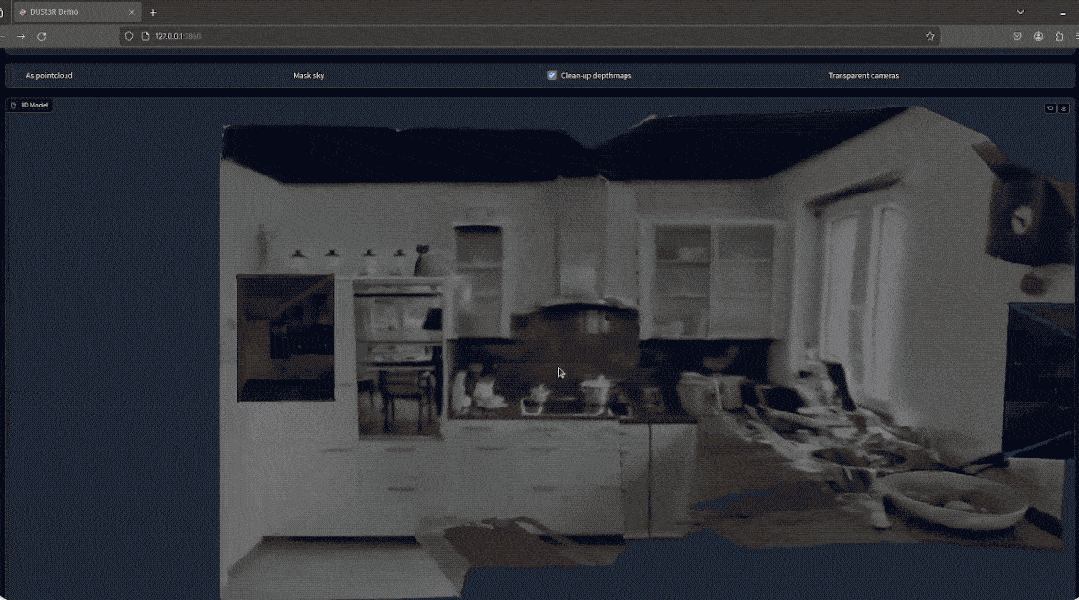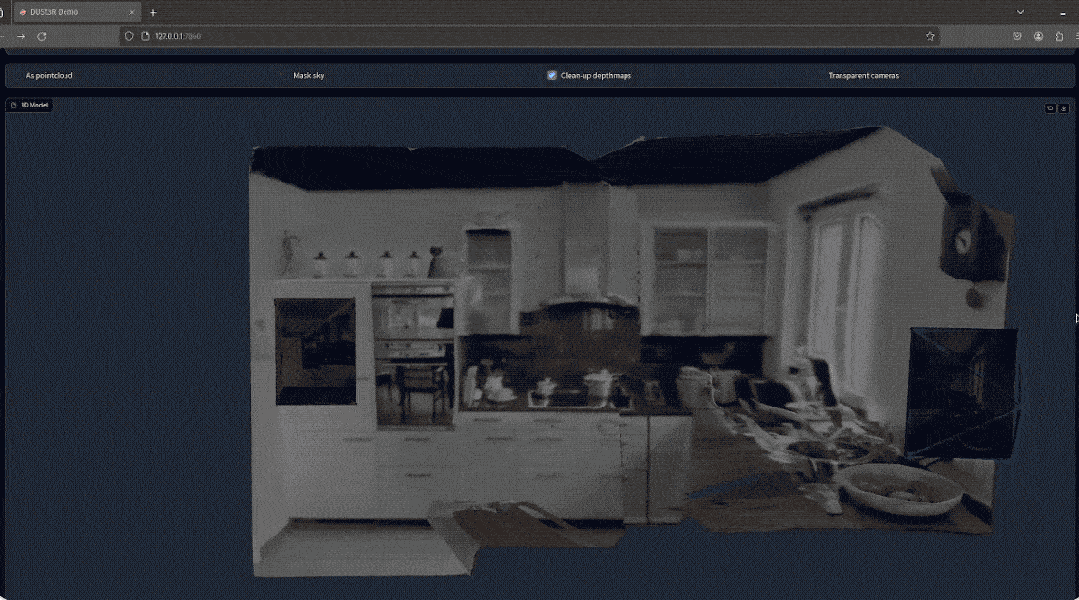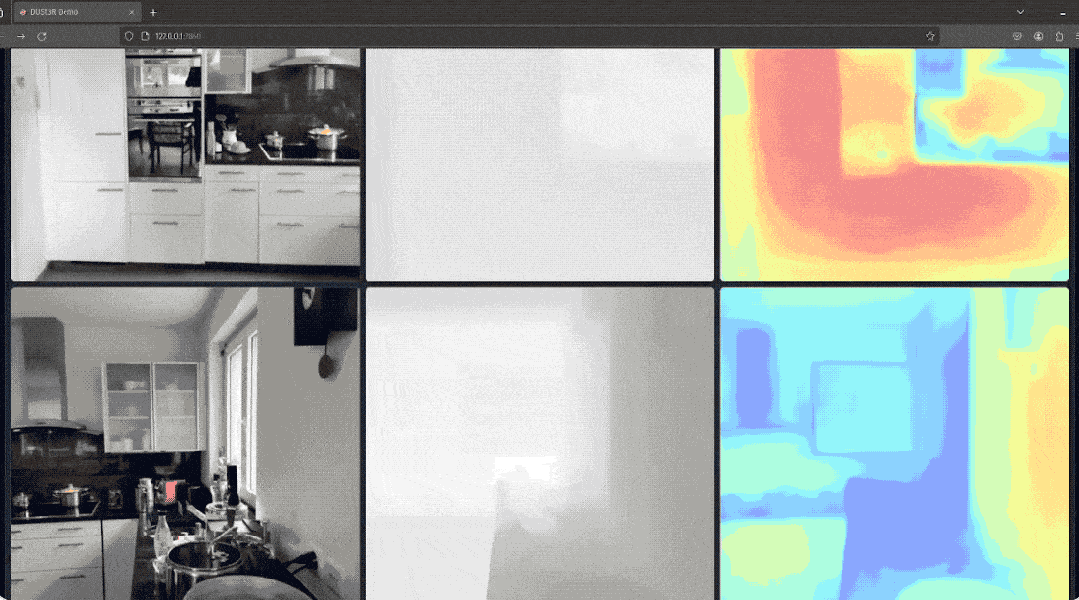

网友如此评价道:

实验显示,DUSt3R在单目/多视图深度估计以及相对位姿估计三个任务上,均取得SOTA。
以下是两组官方给出的3D重建效果,再给大伙感受一下,都是仅输入两张图像:


有网友给了DUSt3R两张没有任何重叠内容的图像,结果它也在几秒内输出了准确的3D视图:
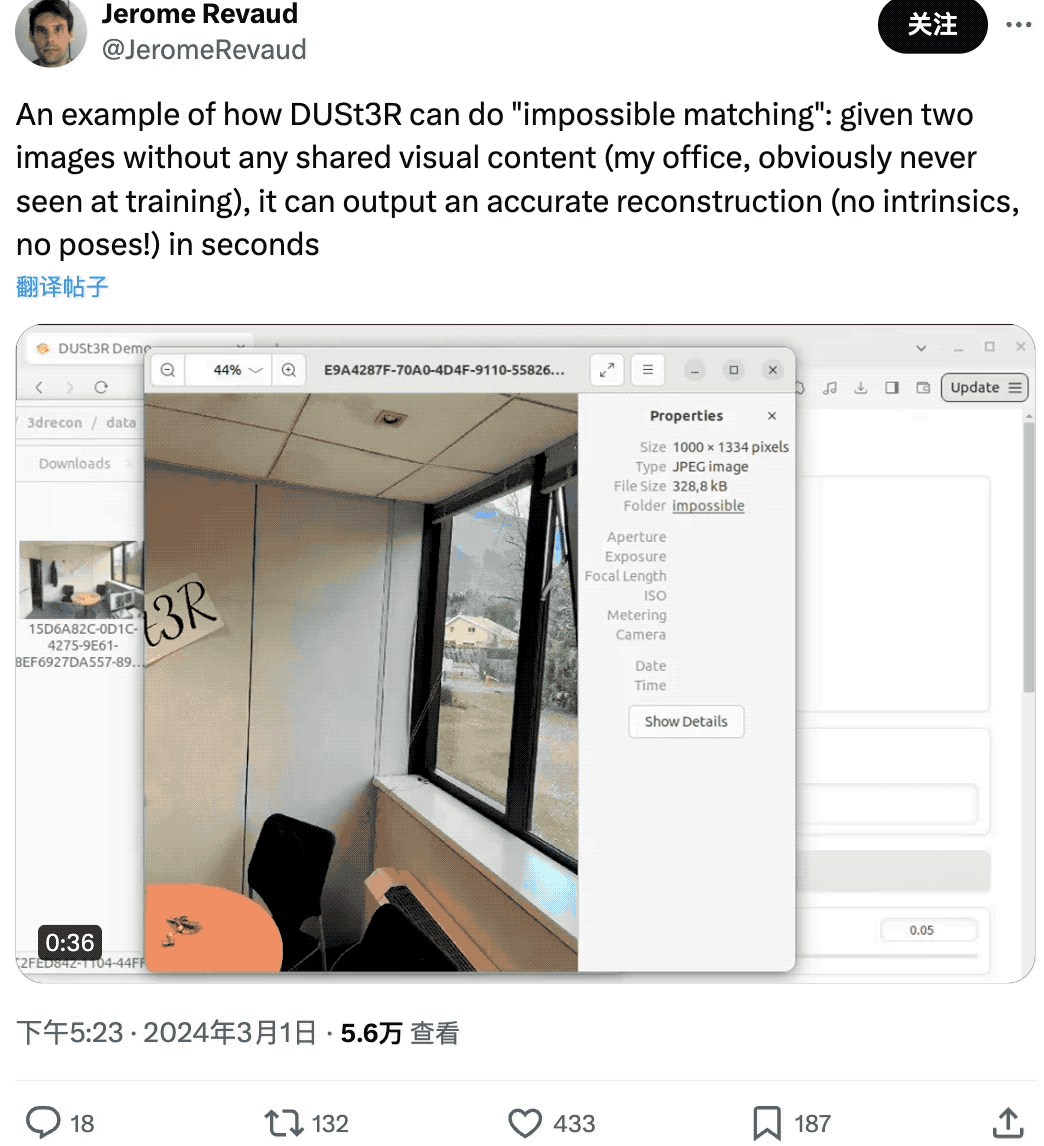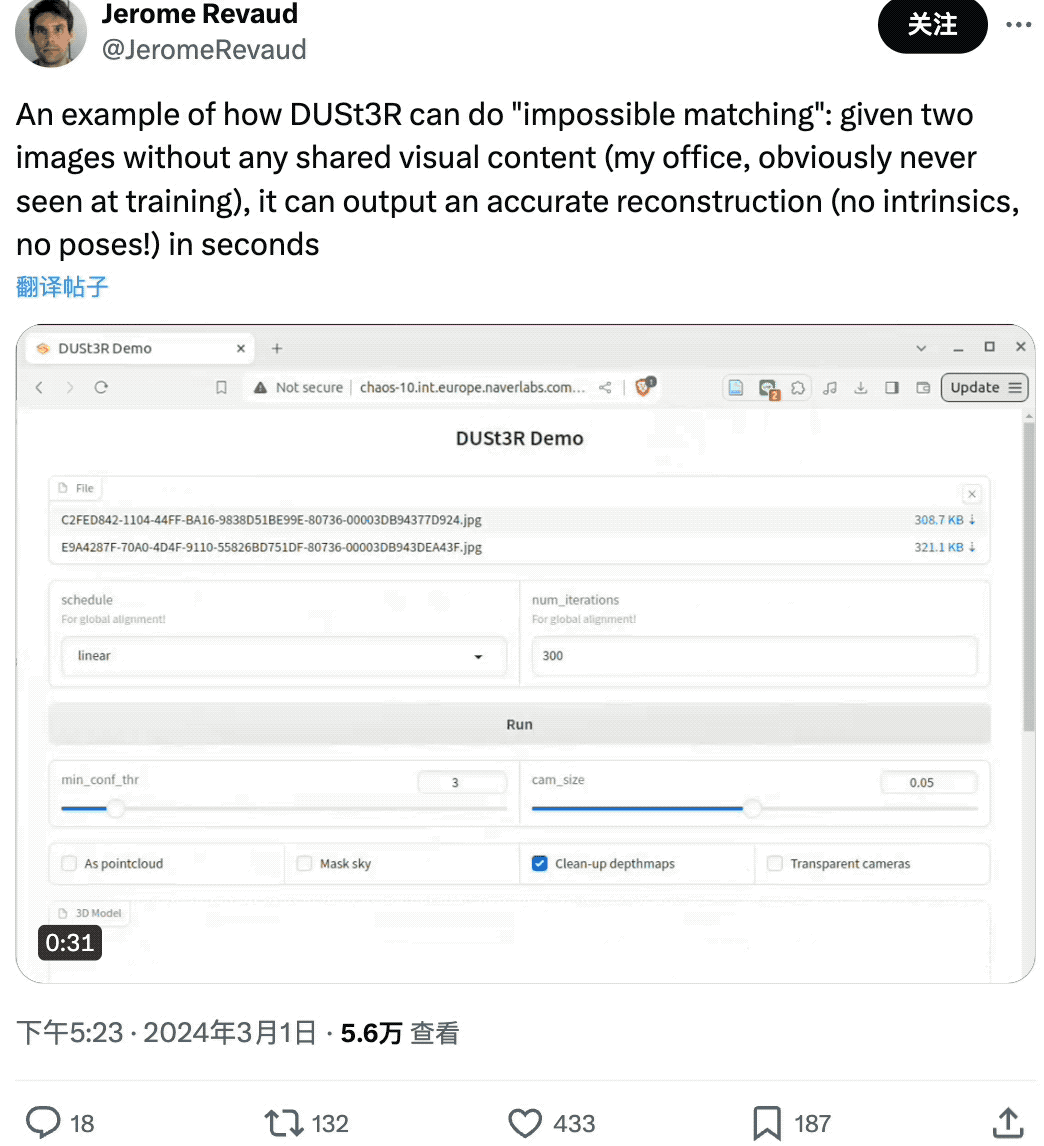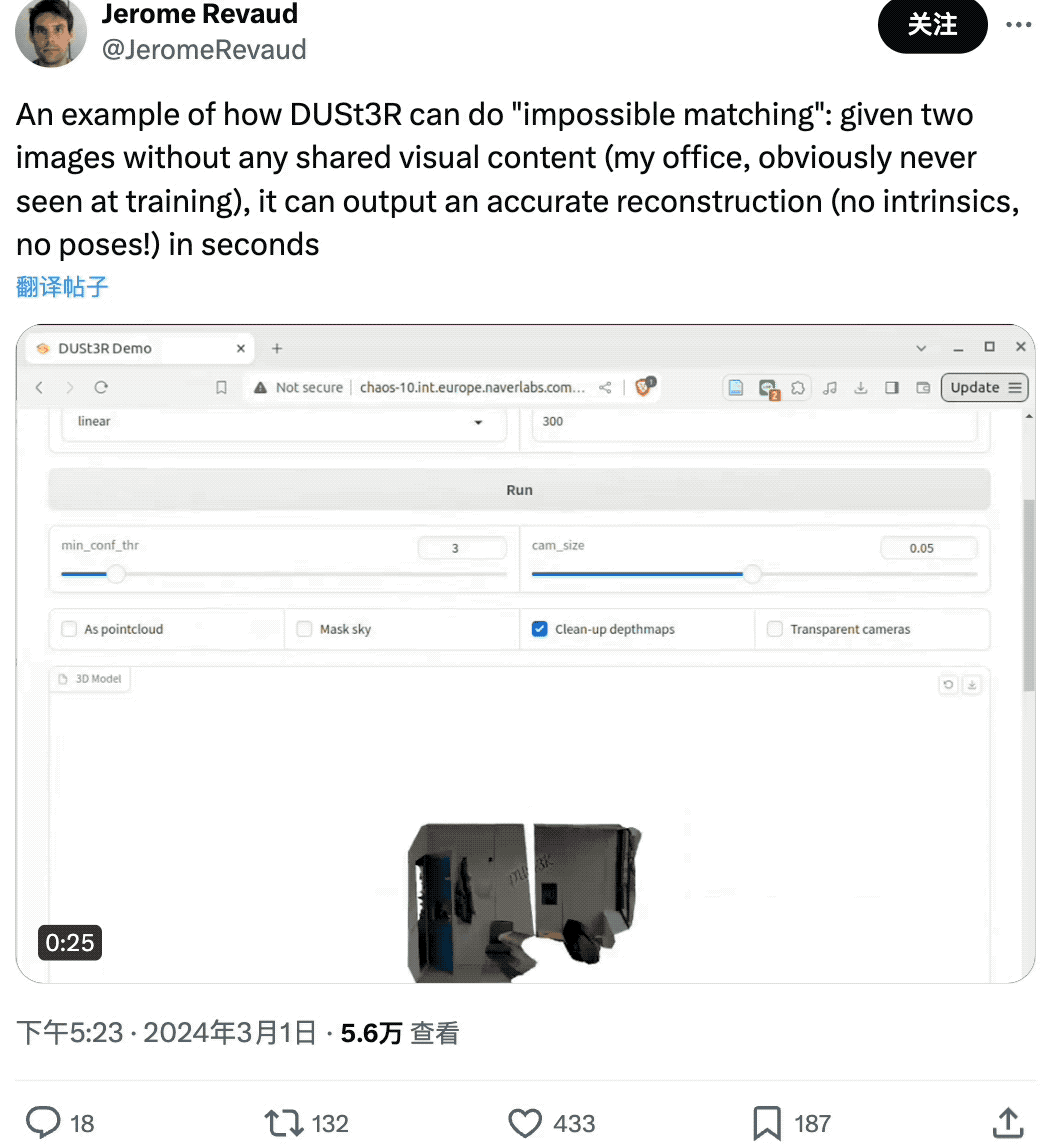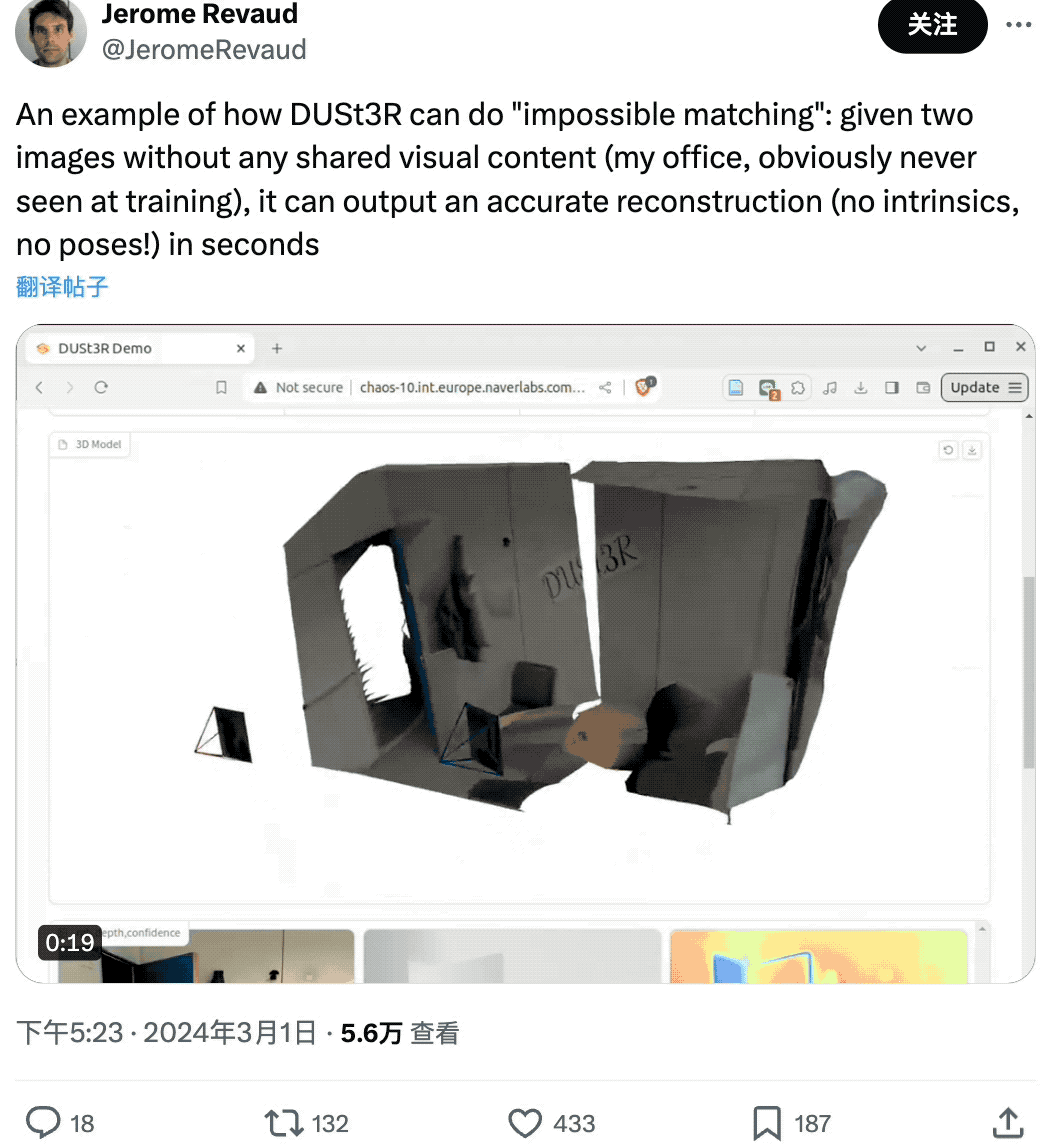
厉不厉害?想不想去试试
# download and prepare the co3d subset
mkdir -p data/co3d_subset
cd data/co3d_subset
git clone https://github.com/facebookresearch/co3d
cd co3d
python3 ./co3d/download_dataset.py --download_folder ../ --single_sequence_subset
rm ../*.zip
cd ../../..
python3 datasets_preprocess/preprocess_co3d.py --co3d_dir data/co3d_subset --output_dir data/co3d_subset_processed --single_sequence_subset
# download the pretrained croco v2 checkpoint
mkdir -p checkpoints/
wget https://download.europe.naverlabs.com/ComputerVision/CroCo/CroCo_V2_ViTLarge_BaseDecoder.pth -P checkpoints/
# the training of dust3r is done in 3 steps.
# for this example we'll do fewer epochs, for the actual hyperparameters we used in the paper, see the next section: "Our Hyperparameters"
# step 1 - train dust3r for 224 resolution
torchrun --nproc_per_node=4 train.py \
--train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=224, transform=ColorJitter)" \
--test_dataset "100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=224, seed=777)" \
--model "AsymmetricCroCo3DStereo(pos_embed='RoPE100', img_size=(224, 224), head_type='linear', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \
--train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \
--test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \
--pretrained checkpoints/CroCo_V2_ViTLarge_BaseDecoder.pth \
--lr 0.0001 --min_lr 1e-06 --warmup_epochs 1 --epochs 10 --batch_size 16 --accum_iter 1 \
--save_freq 1 --keep_freq 5 --eval_freq 1 \
--output_dir checkpoints/dust3r_demo_224
# step 2 - train dust3r for 512 resolution
torchrun --nproc_per_node=4 train.py \
--train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], transform=ColorJitter)" \
--test_dataset="100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=(512,384), seed=777)" \
--model="AsymmetricCroCo3DStereo(pos_embed='RoPE100', patch_embed_cls='ManyAR_PatchEmbed', img_size=(512, 512), head_type='linear', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \
--train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \
--test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \
--pretrained='checkpoints/dust3r_demo_224/checkpoint-best.pth' \
--lr=0.0001 --min_lr=1e-06 --warmup_epochs 1 --epochs 10 --batch_size 4 --accum_iter 4 \
--save_freq 1 --keep_freq 5 --eval_freq 1 \
--output_dir checkpoints/dust3r_demo_512
# step 3 - train dust3r for 512 resolution with dpt
torchrun --nproc_per_node=4 train.py \
--train_dataset "1000 @ Co3d(split='train', ROOT='data/co3d_subset_processed', aug_crop=16, mask_bg='rand', resolution=[(512, 384), (512, 336), (512, 288), (512, 256), (512, 160)], transform=ColorJitter)" \
--test_dataset="100 @ Co3d(split='test', ROOT='data/co3d_subset_processed', resolution=(512,384), seed=777)" \
--model="AsymmetricCroCo3DStereo(pos_embed='RoPE100', patch_embed_cls='ManyAR_PatchEmbed', img_size=(512, 512), head_type='dpt', output_mode='pts3d', depth_mode=('exp', -inf, inf), conf_mode=('exp', 1, inf), enc_embed_dim=1024, enc_depth=24, enc_num_heads=16, dec_embed_dim=768, dec_depth=12, dec_num_heads=12)" \
--train_criterion "ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)" \
--test_criterion "Regr3D_ScaleShiftInv(L21, gt_scale=True)" \
--pretrained='checkpoints/dust3r_demo_512/checkpoint-best.pth' \
--lr=0.0001 --min_lr=1e-06 --warmup_epochs 1 --epochs 10 --batch_size 2 --accum_iter 8 \
--save_freq 1 --keep_freq 5 --eval_freq 1 \
--output_dir checkpoints/dust3r_demo_512dpt
传送门:
[1]论文https://arxiv.org/abs/2312.14132
[2]代码https://github.com/naver/dust3r
原文地址:https://blog.csdn.net/m0_67647321/article/details/136476194
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!