一站式实时数仓Hologres整体能力介绍
讲师:阿里云Hologres PD丁烨
一、产品定位
随着技术的进步,大数据正从规模化转向实时化处理。用户对传统的T+1分析已不满足,期望获得更高时效性的计算和分析能力。例如实时大屏,城市大脑的交通监控、风控和实时的个性化推荐,各行各业、各种业务都在试图从实时分析中寻找、洞察和创造业务价值。
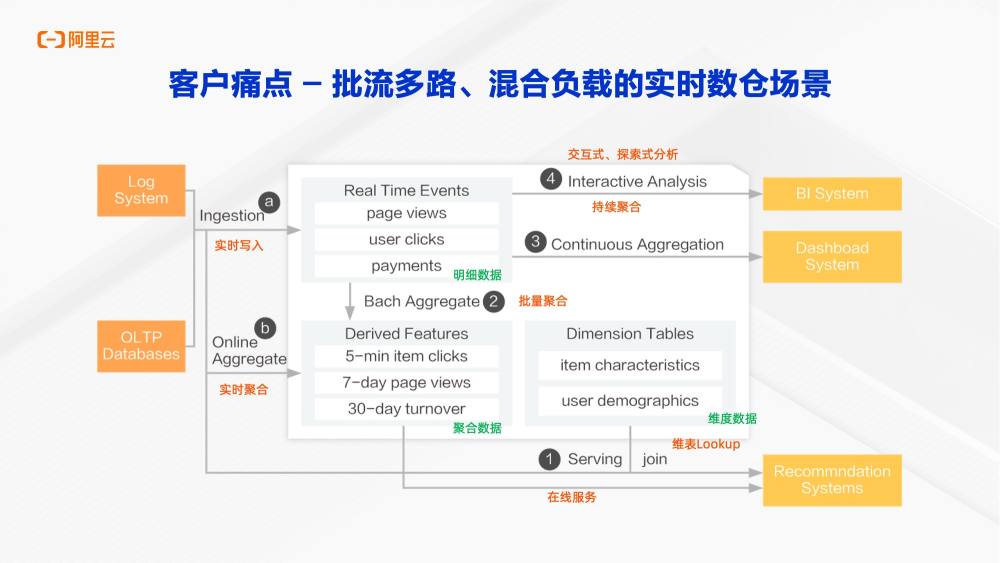
在典型业务场景中,数据会从交易系统和日志实时同步到数仓。明细数据被实时加工,对于应用和BI提供交互式探索式的分析。同时也会批量化的进行聚合,实现离线的数仓分层。同时,实时数据会与维表进行即时关联(join),之后进行聚合并写入KV数据库,以服务推荐系统。
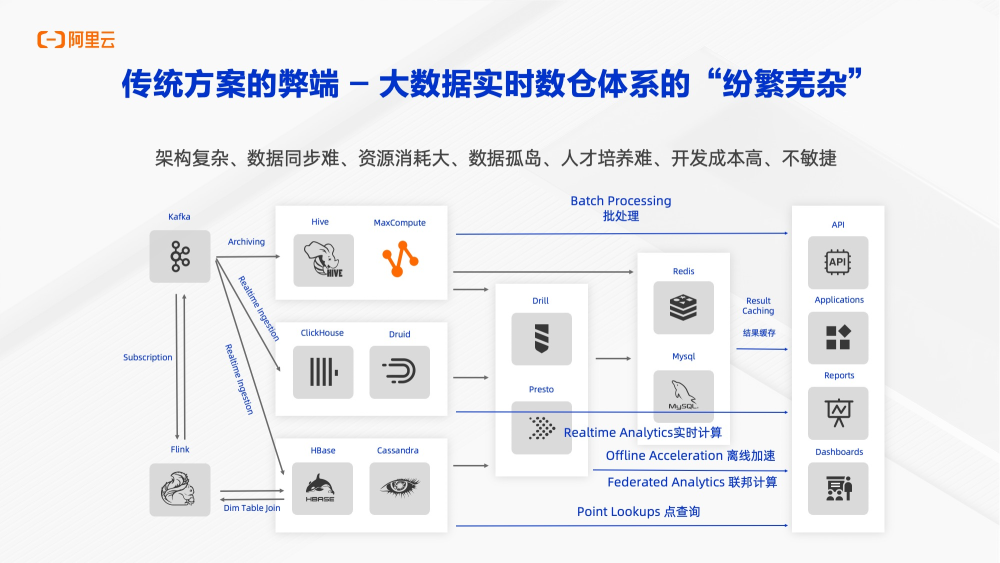
如今,实时数据正在从成本中心转化成为一种在线业务系统。整套系统包括批、流、olap分析、KV的明细查询,混合多种负载。首先,数据处理分为三个主要链路:离线数据归档至如MaxCompute、Hive等离线数仓,数据在离线数仓中分层后对外提供服务;实时数据写入如ClickHouse、Druid等OLAP系统,提供即时聚合分析;最后,使用Flink进行流式计算,实时汇总数据并写入KV数据库。这个过程中也可能会将实时事件的流数据和存储在KV存储中的维表属性进行打宽,然后再进行聚合。例如真正的事件流是用户浏览淘宝的记录,那么就会匹配上用户的属性、特征,再进行聚合,最后写到KV数据库中。
对于业务,通常需要同时查询历史的数据和实时的数据,进行结果对比。例如今年双十一需要使用去年双十一的数据进行对比和参照。此时就需要使用联邦分析的查询系统,但是对于联邦分析的查询系统来说,性能会受限于最慢的那一方,性能一般无法满足要求。所以在前面可能会把结果导入MySQL或者Redis中进行结果缓存,最终服务于业务报表、业务应用等。图里的每一根线都是一次数据的迁移。
为了搭建实时数仓,一共用了十余种数据技术,架构非常的复杂,数据同步很难且资源消耗大,各个资源之间无法共享,最终还产生了一堆数据孤岛。

面对这样的场景和痛点,Hologres应运而生。Hologres提供了一种数据存储,一款产品能够同时服务上层的多维分析、在线应用数据看板等。同时支持数据离线的高性能导入,也支持实时数据的实时更新,写入即可见,真正做到了一站式实时入仓。
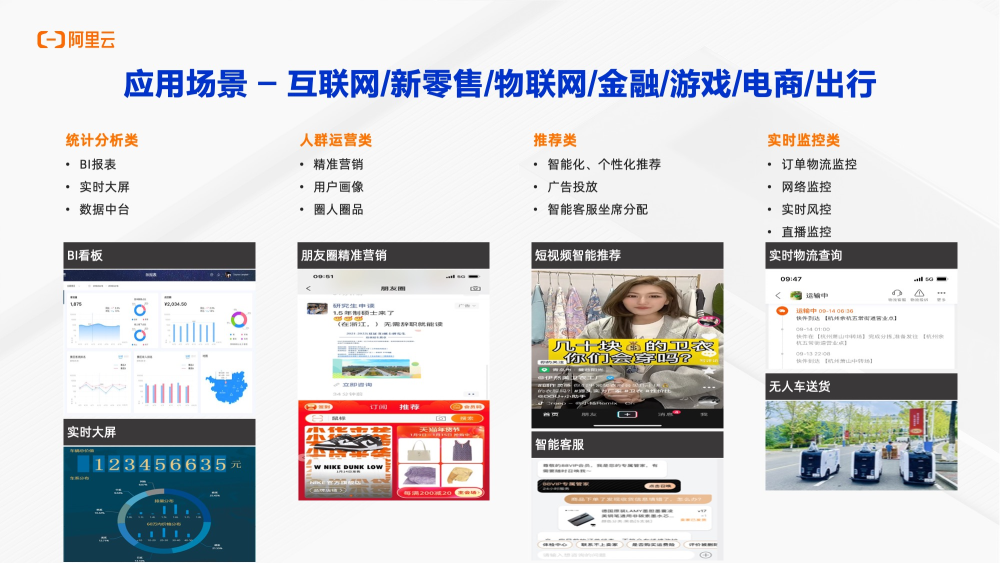
下图是Hologres典型的应用场景。包括传统的统计分析,例如BI报表、实时大屏、数据中台以及现在大量应用的人群运营推荐等,做精准的营销用户画像以及广告投放智能化、个性化的推荐。还包括实时流量监控、网络流量的监控、实时风控、直播的监控,例如实时观看直播间的观看情况、观看时长、进入和退出的用户数等信息。
二、Hologres核心功能及核心优势
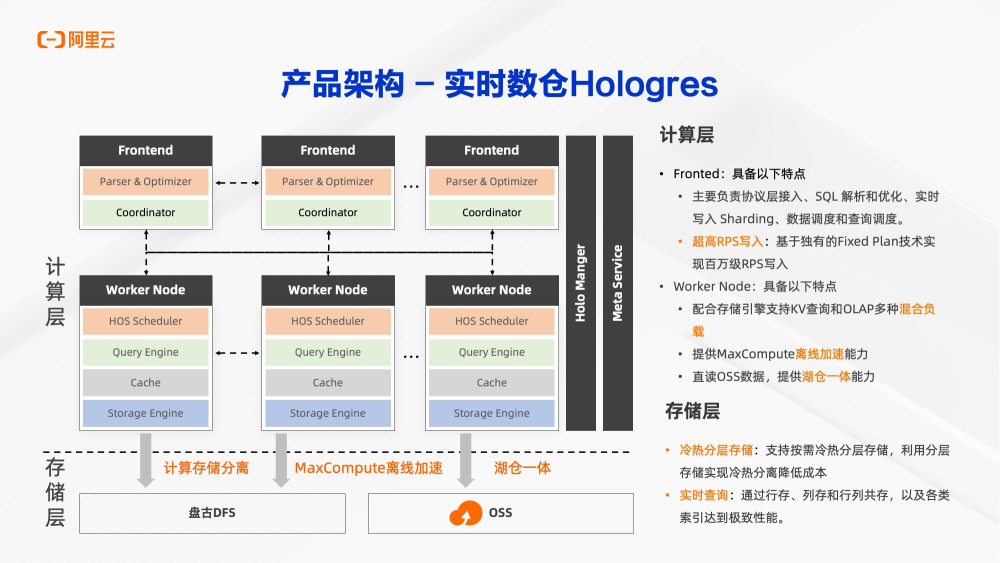
Hologres是存储和计算分离的架构。每一个实例的计算层是容器化部署的,分为frontend和worker node两类节点。frontend主要负责协议层的接入、sql的解析优化、实时写入、数据的调度和查询。同时基于独有的fixed plan的技术,实现百万级的RPS写入。worker node主要用于计算,主要负责配合存储引擎实现KV的查询、OLAP查询的多种负载查询,以及读取MaxCompute、OSS等存储,提供湖仓一体的能力。存储层使用阿里自研的DFS盘古存储。存储层支持按需冷热的分层存储。利用分层存储实现冷热数据的分离,从而降低成本,实现性能和成本之间的平衡,同时还支持行存、列存和行列共存以及各类索引,达到不同场景上均有极致的性能。
产品优势

产品的优势主要来自四个方面。
首先支持实时OLAP分析,支持高性能写入,写入即可查。使用了业界主流的列式存储,用来支持OLAP的场景。支持多种索引,包括聚簇索引、Bitmap、字典等。支持向量化的引擎,使用全异步调度框架,最大程度的释放硬件的性能。Hologres从诞生就支持了主键模型,并且支持主键去重,基于主键的全量更新,部分列更新等场景。其次支持Serving的场景、百万到千万级别的高性能检查、行存。同时也支持多副本模式。当副本发生故障的时候,点查会自动重试,最大程度的保证了点查场景的可用性。
其次点查不仅对查询延时非常敏感,同时对稳定性也非常敏感。所以也支持容器级别物理资源隔离,支持读写分离架构,也推出了计算组模式,最大程度保证了多种负载不互相影响。
还支持数据湖的数据交互式分析,不仅支持对maxcompute数据进行分析,还支持对数据湖中表进行秒级交互式查询和加速。在导入能力上,支持百万行每秒极速数据同步,能够快速从MaxCompute或者其他湖存储中把数据同步到Hologres中。在用户使用体验上,无需主动建表,支持原数据自动发现,极大简化用户使用。
最后,Hologres使用PostgreSQL生态,兼容这个生态下的开发工具和BI工具。支持PostgreSQL生态下多种扩展。支持做空间地理分析、空间维度分析。
重点特性
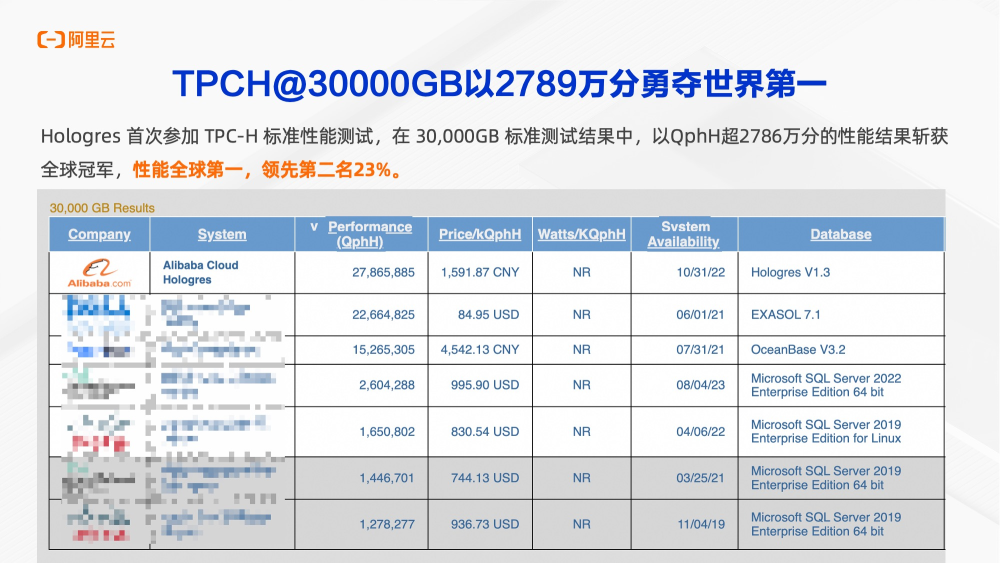
首先是分析性能,TPC-H是世界公认OLAP性能排行榜。至今Hologres以2786万分占据TPC-H性能榜首。
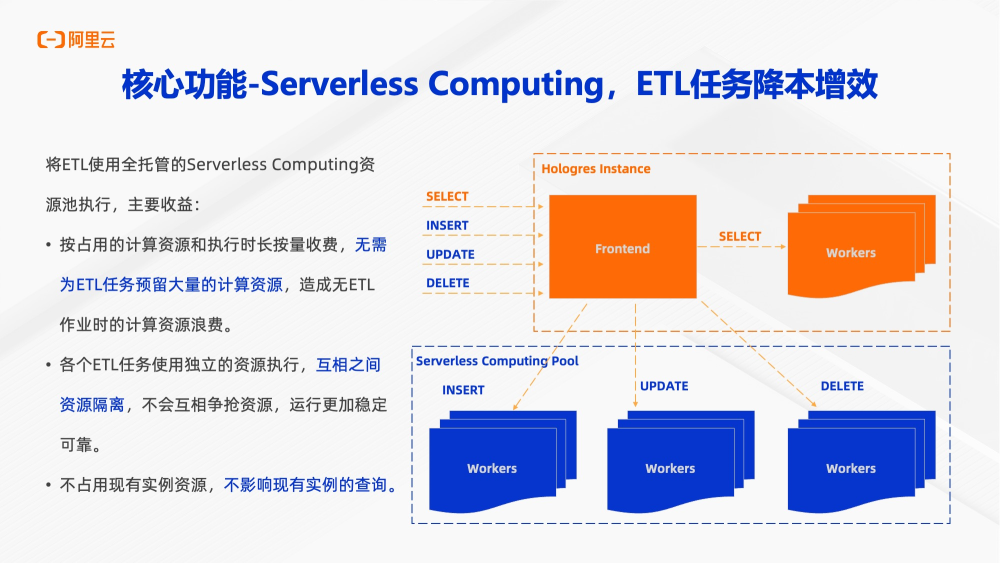
Serverless computing是Hologres最新推出功能,它支持用户将大任务(例如insert查询、update查询、delete查询) 使用全托管Serverless computing资源池执行。每条查询单独分配使用资源进行操作,资源与资源之间互相隔离,互不影响。Serverless computing按照占用计算资源和执行时长收费。那么就无需为周期性大任务预留大量计算资源,而造成没有大作业时计算资源浪费。同时各个ETL任务独立使用资源进行,互相之间资源隔离,互相之间不会争抢,运行更加稳定和更加可靠。最后他不占用现有实例资源,不会影响现有实例的查询,从源头上解决了MPP架构上跑大任务的痛点,在稳定性和性价比上找到了平衡。

其次是资源隔离能力,MPP架构中最大痛点也就是资源隔离。Hologres在之前已经推出了共享存储的读写分离模式,它有主实例和从实例,主从之间数据毫秒级延迟。在原有架构基础上,Hologres再做升级,推出了计算组实例,实例内可以划分多个计算组,多个计算组之间共享存储,数据毫秒延迟,计算资源物理隔离,计算组与计算组之间故障式隔离。计算组支持弹性扩缩容,支持按时弹性,支持系统级高可用。通过标准SQL接口可以支持根据用户路由、负载自动路由自动切换。对外只暴露统一的endpoint。在用户需要切换的时候,无需上层应用变更任何代码,不用做任何配置修改,用户即可在实例层面主动进行切换。同时计算组支持在线扩缩容,在扩容和缩容期间查询不会中断。

高性能、高吞吐的实时写入是Hologres一直以来的优势能力。传统OLAP引擎写入数据时需要经过查询优化器、协调器、查询引擎、存储引擎等多个组件。Hologres对于特定查询,可以用FixedPlan模式进行写入数据,即不经过优化器、协调器、查询引擎、存储引擎等多个组件,极大缩短写入链路,显著提高写入性能。上图左下角是典型insert语句执行过程,它会经过各个组件才把数据写下去。使用FixedPlan之后,省去了中间的多余步骤,提高了性能。数据通过SQL写入的时候,SQL返回即表示写入完成,数据写入即可见,从写入到可查询的延迟在毫秒级别。同时Hologres支持多种存储,包括行存、列存和行列共存,用来服务不同负载场景。同时基于自研的FixedPlan优化原理,简化写入链路,实现高吞吐高并发的更新和删除,RPS可达百万以上。
Hologres在第一天就完整支持了组件场景,支持了exactly once语义,全场景支持主键去重、完整支持高性能,可以根据业务场景去选择适合写入模式,来满足不同场景下对于写入的需求。
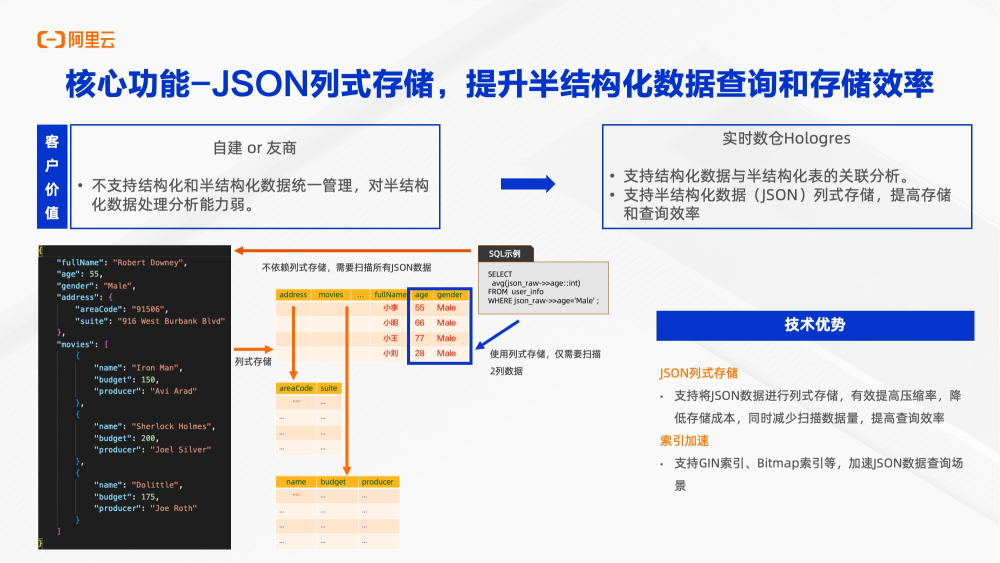
随着日志分析兴起,半结构化数据变得越来越流行。它有很多优势,例如可以自由增加Key,在Key时不需要变更上下游数据。但是JSON也会带来很多问题,比如说查询更加耗费资源等问题。那么Hologres支持将Jason数据在写入的时候就做解析,它可以解析出来key和value,然后使用列存方式存储下来。例如上图左侧的JSON数据,如果需要查询男性平均年龄,当没有使用列存的时候,需要把当中所有key和value都查询出来,在列存中做筛选再做聚合。如果使用列存化之后,当数据存储的时候,就已经按照列存储下来。Hologres会根据解析出来的数据类型,选择合适的数据类型进行列存压缩和存储。在存储上会有明显提升,减少存储空间和降低存储成本。在查询时只需要查出年龄相关数据和性别相关数据。
同时在数据上可以使用bitmap索引。进一步提升查询和检索数据效率。从数据量、IO量、检索量上,多重方式、多种层次去优化查询性能。同时,和其他厂商不同,Hologres使用了原生PG协议下的JSON数据类型,可以很好跟与BI工具兼容,在BI场景下也可以原生使用列 存化能力。
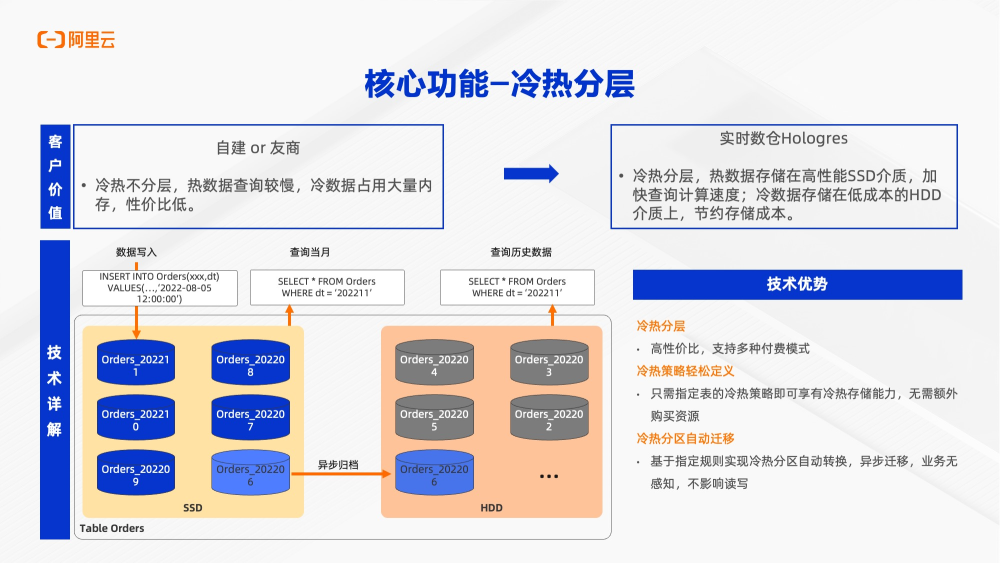
同时,Hologres也支持冷热分层,只需指定表的冷热分层策略,即可以享受冷热分层存储能力,无需购买其他额外存储或者做其他数据搬迁。支持基于指定规则实现冷热分层的自动转储。转储过程中是异步,业务无感知,也不会影响读写。在使用查询的时候,会根据不同存储去查不同存储上数据。
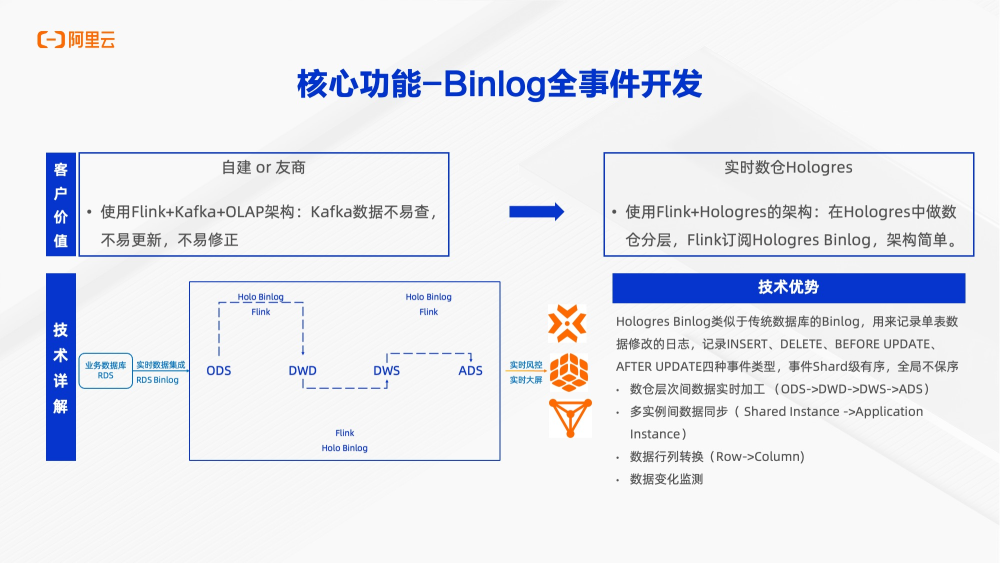
Binlog能力是Hologres有别于其他olap的重要能力。在传统数仓中,olap就是数据终点。但是Hologres提供了Binlog,让Hologres不再仅仅是数据终点,它也可以是数据起点。Hologres的Binlog类似于传统数据库Binlog,用来记录单条数据修改日志。包括insert、delete before update、after update 4种事件类型。基于这样能力,Binlog可以被JDBC消费,也可以被flink消费,实现实时数仓分层。Flink可以基于ODS层的Binlog加工DWD层Binlog,最终得到ADS层数据,实现层层数据加工。做到真正全链路事件驱动开发,而不是原基于调度任务的开发。

Hologres一直在深耕流量分析场景,支持了丰富的分析函数,从最初的漏斗分析函数扩展到区间漏斗分析函数语法,可以用来做漏斗转化的分析。后来又实现了路径分析。它可以用于分析每个步骤流向和流量分层。在Hologres里面只需要通过简单函数,即可以实现复杂桑基图分析。在其他引擎里面如果要做分析,需要多种函数,多条语句互相嵌套,才可以实现部分桑基图功能。最后还有留存扩展函数,仅需要函数就可以画出数据分析。且中间经过高度优化, 性能比传统嵌套写法会有数百倍提升。

在数仓上,行为分析、画像分析都是非常核心场景。对比Doris、Clickhouse等产品在这些场景上的能力,Hologres完整覆盖了漏斗分析、留存分析、路径分析、属性标签分析和行为分析五大分析场景,真正做到了全场景全覆盖。而且在每场景都有完整函数支持。不仅在性能上全覆盖,功能上全覆盖,在函数上也做到了真正全覆盖。

在Hologres中原生支持Roaring Bitmap函数,可以将用户ID构建成Roaring Bitmap,实现标签快速分析。同时在2.1版本开始,支持了BSI函数,通过BSI高效压缩和切片索引实现标签高效分析。同时在查询时,可以通过二进制原理和Roaring Bitmap交并差进行快速计算,支持对高基数进行标签压缩存储和低延迟查询,从而实现属性标签和行为标签高效联动分析。Roaring Bitmap多用于属性标签,BSI函数多用于行为标签和属性标签联合查询。在保证精度的同时还可以避免与明细表进行关联查询。同时也支持高基数的行为标签,通常与Roaring Bitmap连用。
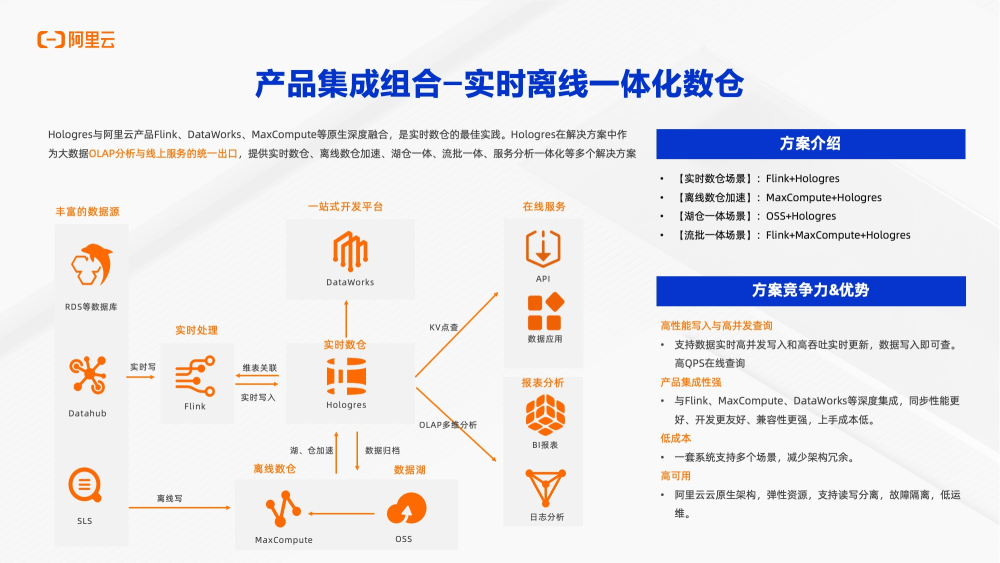
上图是Hologres主要产品组合,覆盖了实时数仓、离线数仓、湖仓一体和流批一体场景。实时交易系统的数据和消息队列的数据通常使用Flink进行实时处理,同时和Hologres可能会有维表关联,然后将数据写到Hologres里面。Dataworks作为统一开发平台,做离线和实时全链路开发。包括支持统一血缘分析,以及数据集成,能够将数据库里的数据通过简单配置就可以实时同步到Hologres中。对于离线部分,Hologres支持对湖上数据和MaxCompute数据进行高速分析,高速加速以及高速导入。同时也支持高速归档到MaxCompute或OSS中。
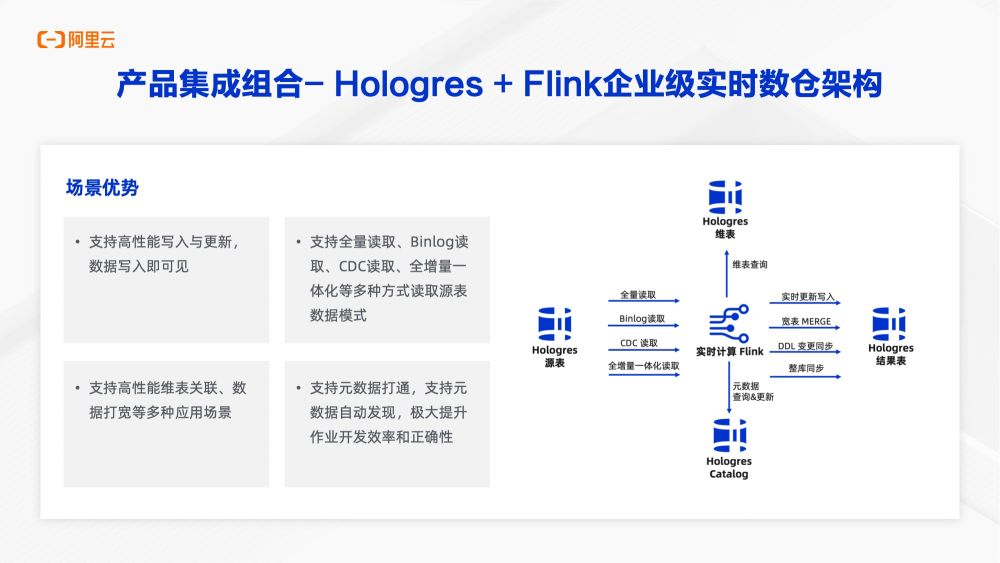
对外提供KV高性能点查服务,以及olap多维分析能力。首先Hologres和flink可以组成企业级实时数仓架构。Hologres作为flink最佳搭档,同时支持了flink所有功能特性。当作为结果表时,支持高性能写入和更新数据,写入即可见。作为源表时,支持全量读取、binlog读取、CDC读取和全增量一体化多种方式读取。作为维表,支持高性能维表关联,数据打宽等多种应用场景。最后深度集成了catalog能力,支持原数据打通,支持原数据自动发现。在CDC场景中,上游数据发生了变化,就可以驱动Hologres中的表结构发生变更,进行schema evolution,不需要额外去重新配置flink任务即可实现。
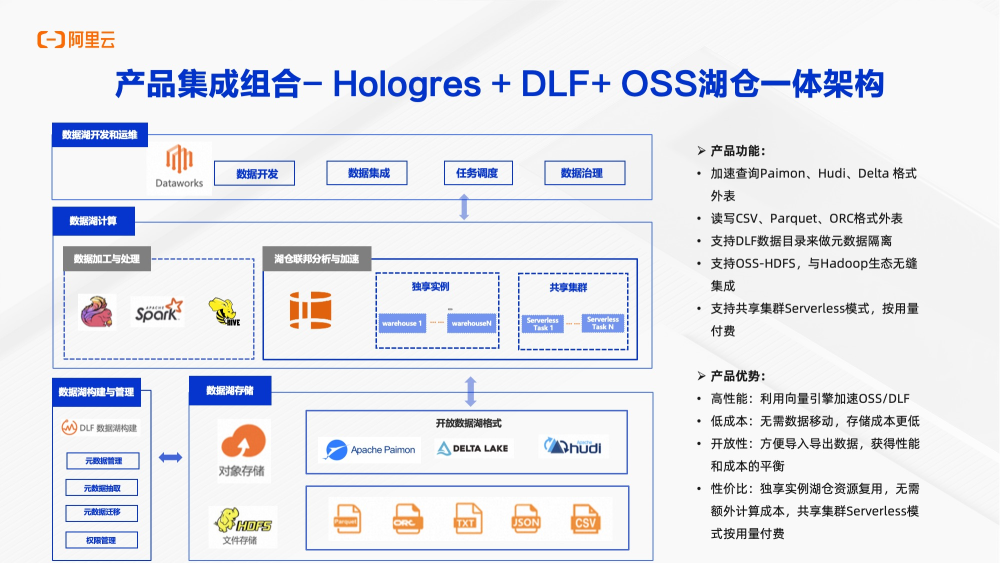
上图是湖仓一体场景。DLF在这个场景中会提供原数据管理和发现能力。Hologres可以无缝自动发现DLF原数据。在整个架构中,Hologres支持加速和读取多种数据库格式,包括Paimon、Hudi、delta等外表格式。同时支持DLF源数据自动发现,支持OSS-HDFS高性能读取,与hadoop生态无缝集成。使用形态上, Hologres还提供了共享集群模式,可以按照查询、扫描量来按量付费,极大降低了数据库的分析门槛。
三、典型案例
案例一:国民种草笔记小红书
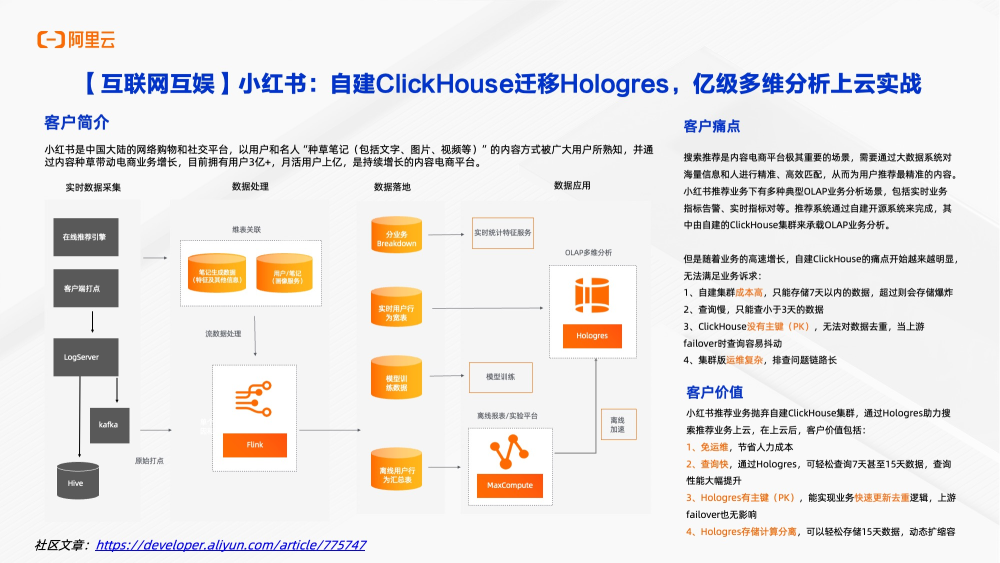
Hologresce主要应用在客户搜索推荐场景。搜索推荐是内容平台电商极其重要场景,需要通过大数据体系对海量信息和人群进行精准高效匹配,从而为用户推荐最精准内容。小红书推荐业务下有多种典型OLAP业务和分析场景,包括实时业务指标告警,实时指标核对等。推荐系统通过自建开源系统来完成,其中由自建的Clickhouse集群承担OLAP分析业务。但是随着业务高速增长,自建Clickhouse痛点越来越明显,无法满足业务诉求。其中包括自建的集群成本高,只能存储七天以内数据,否则就会存储爆炸;其次是查询慢,只能查询三天以内数据;接着Clickhouse没有主键,无法对主键去重,当上游flink任务fillover时很容易抖动。集群摆运维复杂,排查问题链路长。小红书业务就抛弃了自建的Clickhouse集群。通过Hologres助力搜索推荐业务上云。上云之后,客户收到了明显收益,包括免运维,节省人力成本;查询快,通过Hologres可以轻松查询 15天数据。同时Hologres提供了各类场景分析类函数,极大简化了查询使用成本和使用门槛。最后Hologres能够实现业务快速去重。上游任务有任何fillover也没有影响。Hologres在重新写入的时候,不会产生脏数据。Hologres存储和计算分离,可以轻松存储15天数据。如果后面数据还要多,可以轻松实现动态扩容。
案例二:阿里妈妈

广告业务是核心场景业务。在广告场景上实时推荐是非常典型的提升商业化收入方法。对于阿里妈妈这样广告平台来说,其目标是用更好商家端营销产品服务广告主,帮助广告主进行人群投放,提升经营效果。为了解决广告主更加实时且智能的实时推荐需求,阿里妈妈通过数据团队,通过flink加sql自研了一套具有AI分析的超融合一体化平台。其中flink提供实时计算,支持streaming和batch计算能力,实现流批一体。Hologres负责存储一体,并且向上提供olap分析能力,结合AI计算能力实现人群圈选,实时推荐。团队在上层自研SQL组件,实现SQL自动转移路由等能力;index build等组件,充分资源调度并改善算法能力,支持精准向量召回模型打分。
阿里妈妈通过flink加Hologres搭建广告智能计算引擎,尤其是结合Hologres bitmap和向量计算能力,给下游业务带来了巨大收益。包括秒级olap计算能力,毫秒级在线服务,提供毫秒级实时营销推荐和毫秒级用户召回计算,开发效率提升了三倍以上。Flink加Hologres的深度集成系统,支持数据加工和在线服务,显著提高了开发效率。
案例三:37手游

37手游是37互娱集团下的运营子公司,致力于游戏发行业务,在中国大陆地区37手游已近10%市场占有率,仅次于腾讯和网易,位居top 3。37手游原有大数据平台全套使用开源flink+Presto+HBase+Clickhouse的架构。主要具有如下痛点,原有的ETL链路非常复杂;开源flink缺乏schema evolution能力,变更表结构需要重启任务,操作非常麻烦;查询需要额外加速,整个链路非常冗余。同时两种查询引擎不能统一起来,OLAP架构冗余,查询慢,OLAP组件多,操作非常繁琐;OLAP查询引擎性能不足,无法满足业务快速增长的需求;系统多,存储冗余,成本居高不下,集群稳定性需要专人去做运维。
在全面上云之后,带来了非常显著的业务收益。首先使用Hologres之后,业务写入即可见,百万数据更新毫秒延迟,业务拿数据更实时,不同于过去Clickhouse方式,需要和数据合并之后,才能看到最新的结果。然后阿里云flink提供了完整schema evolution能力,降低了开发和运维管理成本、使用成本。实时链路flink直接读取,Hologres+Binlog替代kafka,减少了数据流转。在整个数仓分层中,不需要两套存储即可实现整个实时数仓分层。Hologres统一了数据服务出口,查询毫秒级延迟,相比Clickhouse性能有百分之百的提升,join运行性能有十倍以上提升。架构更简单、更灵活,运维更方便;上新业务或业务变更的时候变得更加敏捷,整个开发效率变得更高。
原文地址:https://blog.csdn.net/weixin_48534929/article/details/139821725
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!