基于卷积神经网络的交通标志识别(pytorch,opencv,yolov5)
本文共包含两部分,
第一部分是用resnet18对交通标志分类,仅仅只是交通标志分类
文末附有yolov5和resnet18结合的源码,yolov5复制检测交通标志位置,然后使用resnet18对交通标志进行分类。
数据集介绍:
本文使用的数据集共有6000多张,共包含58个类别。部分数据集如下:



resnet18模型代码
使用pytorch自带的resnet18模型,代码如下:
from torchvision import models
import torch.nn as nn
#加载resnet18模型
net=models.resnet18(weights=None)
#因为分类个数为58,所以需要修改模型最后一层全连接层
net.fc=nn.Linear(in_features=512, out_features=58, bias=True)
# print(net)
加载数据集(Dataset与Dataloader)
from torch.utils.data import Dataset,DataLoader
import numpy as np
import cv2
import imgaug.augmenters as iaa
from imgaug.augmentables.segmaps import SegmentationMapsOnImage
from PIL import Image
import os
from torchvision import transforms
import torch
import random
a=[]
class Mydata(Dataset):
def __init__(self,lines,train=True):
super(Mydata, self).__init__()
self.lines=lines
random.shuffle(self.lines)
self.train=train
def __len__(self):
return len(self.lines)
def __getitem__(self, index):
txts=self.lines[index].strip().split(';')
src_path='pic/'+txts[0]
w=int(txts[1])
h=int(txts[2])
x1=int(txts[3])
y1=int(txts[4])
x2=int(txts[5])
y2=int(txts[6])
new_x1=random.randint(0,x1)
new_y1=random.randint(0,y1)
new_x2=random.randint(x2,w-1)
new_y2=random.randint(y2,h-1)
lab=int(txts[7])
# if lab in a:
# pass
# else:a.append(lab)
#
# a.sort()
# print(len(a))
# print(a)
img = Image.open(src_path)
img=np.array(img)[...,:3]
img=img[new_y1:new_y2,new_x1:new_x2]
#数据增强
if self.train:
img=self.get_random_data(img)
else:
img = cv2.resize(img, (128, 128))
# cv2.imshow('img',img[...,::-1])
# cv2.waitKey(0)
#归一化
img=(img/255.0).astype('float32')
img=np.transpose(img,(2,0,1))
img=torch.from_numpy(img)
return img,lab
def get_random_data(self,img):
seq = iaa.Sequential([
# iaa.Flipud(0.5), # flip up and down (vertical)
# iaa.Fliplr(0.5), # flip left and right (horizontal)
iaa.Multiply((0.8, 1.2)), # change brightness, doesn't affect BBs(bounding boxes)
iaa.GaussianBlur(sigma=(0, 1.0)), # 标准差为0到3之间的值
iaa.Crop(percent=(0, 0.2)),
iaa.Affine(
translate_px={"x": (0,15), "y": (0,15)}, # 平移
scale=(0.8, 1.2), # 尺度变换
rotate=(-20, 20),
mode='constant',
cval=(125)
),
iaa.Resize(128)
])
img= seq(image=img)
return img
if __name__ == '__main__':
lines=open('data.txt','r').readlines()
my=Mydata(lines=lines,train=True)
myloader=DataLoader(dataset=my,batch_size=3,shuffle=False)
for i,j in myloader:
print(i.shape,j.shape)
模型训练
经过60个epoch训练后,模型准确率基本上达到百分百
from mymodel import net
from myDataset import Mydata
import random
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import torch
from tqdm import tqdm
import matplotlib.pylab as plt
batch_size=32
Epoch=60
lr=0.001
lines=open('data.txt','r').readlines()
random.shuffle(lines)
val_lines=random.sample(lines,int(len(lines)*0.1))
train_lines=list(set(lines)-set(val_lines))
train_data=Mydata(lines=train_lines)
val_data=Mydata(lines=val_lines,train=False)
train_loader=DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
val_loader=DataLoader(dataset=val_data,batch_size=batch_size,shuffle=False)
num_train = len(train_lines)
epoch_step = num_train // batch_size
BCE_loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=lr, betas=(0.5, 0.999))
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.99)
#获取学习率函数
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
#计算准确率函数
def metric_func(pred,lab):
_,index=torch.max(pred,dim=-1)
acc=torch.where(index==lab,1.,0.).mean()
return acc
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net=net.to(device)
#设置损失函数
loss_fun = nn.CrossEntropyLoss()
if __name__ == '__main__':
T_acc=[]
V_acc=[]
T_loss=[]
V_loss=[]
# 设置迭代次数200次
epoch_step = num_train // batch_size
for epoch in range(1, Epoch + 1):
net.train()
total_loss = 0
loss_sum = 0.0
train_acc_sum=0.0
with tqdm(total=epoch_step, desc=f'Epoch {epoch}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
for step, (features, labels) in enumerate(train_loader, 1):
features = features.to(device)
labels = labels.to(device)
batch_size = labels.size()[0]
optimizer.zero_grad()
predictions = net(features)
loss = loss_fun(predictions, labels)
loss.backward()
optimizer.step()
total_loss += loss
train_acc = metric_func(predictions, labels)
train_acc_sum+=train_acc
pbar.set_postfix(**{'loss': total_loss.item() / (step),
"acc":train_acc_sum.item()/(step),
'lr': get_lr(optimizer)})
pbar.update(1)
T_acc.append(train_acc_sum.item()/(step))
T_loss.append(total_loss.item() / (step))
# 验证
net.eval()
val_acc_sum = 0
val_loss_sum=0
for val_step, (features, labels) in enumerate(val_loader, 1):
with torch.no_grad():
features = features.to(device)
labels = labels.to(device)
predictions = net(features)
val_metric = metric_func(predictions, labels)
loss=loss_fun(predictions,labels)
val_acc_sum += val_metric.item()
val_loss_sum+=loss.item()
print('val_acc=%.4f' % (val_acc_sum / val_step))
V_acc.append(round(val_acc_sum / val_step,2))
V_loss.append(val_loss_sum/val_step)
# 保存模型
if (epoch) % 2 == 0:
torch.save(net.state_dict(), 'logs/Epoch%d-Loss%.4f_.pth' % (
epoch, total_loss / (epoch_step + 1)))
lr_scheduler.step()
plt.figure()
plt.plot(T_acc,'r')
plt.plot(V_acc,'b')
plt.title('Training and validation Acc')
plt.xlabel("Epochs")
plt.ylabel("Acc")
plt.legend(["Train_acc", "Val_acc"])
# plt.show()
plt.savefig("ACC.png")
plt.figure()
plt.plot(T_loss, 'r')
plt.plot(V_loss, 'b')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("loss")
plt.legend(["Train_loss", "Val_loss"])
plt.savefig("LOSS.png")
plt.show()
训练准确率及损失函数:
准确率:
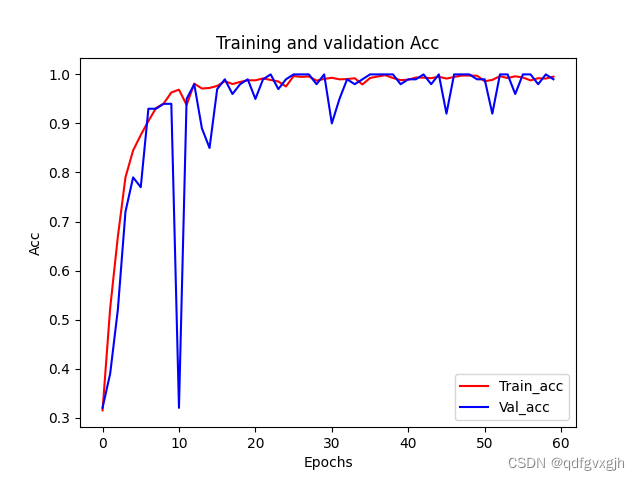
损失函数:

resnet18交通标志分类源码
(包含训练,预测代码,准确率,损失函结果图像,数据集等):
下载地址:
yolov5检测与识别(交通标志)
前面是使用resnet18网络对交通标志分类,只是单单的分类,无法从一张完整的全局图像中检测交通标志位置。对此,首先使用yolov5从全局图像中检测交通标志的位置,只是检测没有分类,然后再使用前面训练好的resnet18模型对交通标志分类。其效果如下:
原文地址:https://blog.csdn.net/qq_45087786/article/details/139195732
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!