springboot集成MyBatis
概述
- MyBatis是一个半ORM的数据库持久化框架,它是三层架构中持久层的技术
-
- 框架:框架指的就是一些类和接口的集合,是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。在框架的基础上进行软件开发更加高效、规范、通用、可拓展
- 持久化:就是将对象数据,保存到数据库当中,从而达到数据断电也存在的目的,叫做持久化
- 持久层:指的是就是数据访问层/Dao层,是用来操作数据库的
- ORM:对象关系映射(Object Relational Mapping,简称ORM):是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术
- 半ORM(半映射):不是通过完整的映射方式,需要自己写sql语句
- 全ORM框架(全映射):JPA、Hibernate、MyBatis-Plus
什么是连接池
- 数据库连接池是个容器,负责分配、管理数据库连接
- 连接池就是为了避免关系型数据库频繁创建、销毁的技术。它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 连接池执行流程
-
- 在系统启动时,创建固定数量的连接放入到集合中
- 在需要执行SQL语句的地方从连接池中获取到连接
- 执行完SQL语句后不进行销毁,返回到连接池中
- 使用数据库连接池的好处
-
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
SpringBoot整合mybatis
导包
//mybatis依赖
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
//数据库驱动
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
//阿里德鲁伊连接池
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>YML配置文件
spring:
datasource:
druid: #使用druid连接池
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/java-926
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启sql日志
map-underscore-to-camel-case: true #开驼峰命名
type-aliases-package: cn.lgc.domain #扫描基本包,可以使用别名编写mapper接口
@Mapper //交给spring管理
public interface StudentMapper {
void save(Student student);
void update(Student student);
void delete(Long id);
Student findById(Long id);
List<Student> findAll();
}编写sql文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.lgc.mapper.TeacherMapper">
<!--添加-->
<insert id="save">
INSERT INTO t_teacher(name, age, sex, birthDay, creatDate, money)
VALUES (#{name},#{age},#{sex},now(),#{creatDate},#{money})
</insert>
<!--修改-->
<update id="update">
UPDATE t_teacher
<set>
<if test="name !=null and name !=''">
name=#{name},
</if>
<if test="age !=null">
age=#{age},
</if>
<if test="age !=null">
sex=#{sex},
</if>
<if test="age !=null">
birthDay=#{birthDay},
</if>
<if test="age !=null">
creatDate=#{creatDate},
</if>
<if test="age !=null">
money=#{money}
</if>
</set>
WHERE id = #{id}
</update>
<!--删除-->
<delete id="delete">
DELETE
FROM t_teacher
WHERE id = #{id}
</delete>
<!--查询-->
<select id="loadOne" resultType="teacher">
SELECT *
FROM t_teacher
where id=#{id}
</select>
<select id="loadAll" resultType="teacher">
SELECT * FROM t_teacher
</select>
<select id="queryData" resultType="teacher">
SELECT *
FROM t_teacher
<include refid="query"></include>
</select>
<select id="queryCount" resultType="java.lang.Long">
SELECT COUNT(id)
FROM t_teacher
<include refid="query">
</include>
</select>
<!--抽取公共sql-->
<sql id="query">
<where>
<if test="name != null and name != ''">
AND name like concat('%',#{name},'%')
</if>
<if test="minAge != null">
AND age >= #{minAge}
</if>
<if test="maxAge != null">
AND age < #{maxAge}
</if>
</where>
</sql>
</mapper>mybatis高级查询
批量删除
<!--批量删除-->
<delete id="deleteBatch">
DELETE FROM t_student WHERE id IN
<foreach collection="list" separator="," open="(" close=")" item="id">
#{id}
</foreach>
</delete>批量添加
<!--批量添加-->
<insert id="saveBatch">
INSERT INTO t_student (name, age, sex, birth_day, creat_date, money)
VALUES
<foreach collection="list" item="s" separator=",">
(#{s.name}, #{s.age}, #{s.sex}, #{s.birthDay}, now(), #{s.money})
</foreach>
</insert>定制排序
<!--定制排序查询-->
<select id="sort" resultType="cn.lgc.domain.Student">
SELECT *
FROM t_student
order by ${queryFiled} ${queryType}
</select>关联查询
关联查询和嵌套查询的区别:
关联查询就是联表查询,嵌套查询会出现n+1情况,就是每查询一条结果都会发送一条子查询
使用情况,查询数据多用关联,查询单个用嵌套
多对一
1.关联查询自定义映射
<!--查询单个-->
<select id="findById" resultMap="queryProduct1">
<include refid="productSql"></include>
WHERE p.id = #{id}
</select>
<!--查询多个-->
<select id="loadAll" resultMap="queryProduct1">
<include refid="productSql"></include>
</select>
<!--公共sql-->
<sql id="productSql">
SELECT p.*, p2.id pid, p2.dirName pname
FROM product p
LEFT JOIN productdir p2 on p.dir_id = p2.id
</sql>
<!--自定义映射-->
<resultMap id="queryProduct1" type="product">
<id column="id" property="id"></id>
<result column="productName" property="productName"></result>
<result column="salePrice" property="salePrice"></result>
<result column="supplier" property="supplier"></result>
<result column="brand" property="brand"></result>
<result column="cutoff" property="cutoff"></result>
<result column="costPrice" property="costPrice"></result>
<association property="productDir" javaType="productDir">
<id column="pid" property="id"></id>
<result column="pname" property="dirName"></result>
</association>
</resultMap>2.嵌套查询
<!--嵌套查询-->
<select id="queryById" resultMap="queryProduct2">
SELECT * FROM product
WHERE id=#{id}
</select>
<!--查询所有-->
<select id="query" resultMap="queryProduct2">
SELECT * FROM product
</select>
<!--嵌套查询>
<resultMap id="queryProduct2" type="product">
<id column="id" property="id"></id>
<result column="productName" property="productName"></result>
<result column="salePrice" property="salePrice"></result>
<result column="supplier" property="supplier"></result>
<result column="brand" property="brand"></result>
<result column="cutoff" property="cutoff"></result>
<result column="costPrice" property="costPrice"></result>
<association property="productDir" javaType="productDir" column="dir_id"
select="cn.lgc.mapper.ProductDirMapper.findById">
</association>
</resultMap>
一对多
1.关联查询
<!--关联查询自定义映射-->
<!--1对多-->
<sql id="dirSql">
SELECT p1.*, p2.id pid, p2.productName pname
FROM productdir p1
LEFT JOIN product p2 on p1.id = p2.dir_id
</sql>
<select id="searchOne" resultMap="queryDir">
<include refid="dirSql"></include>
WHERE p1.id = #{id}
</select>
<resultMap id="queryDir" type="productDir">
<id column="id" property="id"></id>
<result column="dirName" property="dirName"></result>
<result column="parent_id" property="parentId"></result>
<collection property="products" ofType="product">
<id column="pid" property="id"></id>
<result column="pname" property="productName"></result>
</collection>
</resultMap>
<!--查询所有-->
<select id="searchAll" resultMap="queryDir">
<include refid="dirSql"></include>
</select>2.嵌套查询
<!--嵌套查询-->
<!--查询单个-->
<select id="findOne" resultMap="queryDir2">
SELECT *
FROM productdir
WHERE id = #{id}
</select>
<select id="findAll" resultMap="queryDir2">
SELECT *
FROM productdir
</select>
<resultMap id="queryDir2" type="productDir">
<id column="id" property="id"></id>
<result column="dirName" property="dirName"></result>
<result column="parent_id" property="parentId"></result>
<collection property="products" ofType="product"
column="id" select="cn.lgc.mapper.ProductMapper.queryByDir">
</collection>mybatis缓存
1.概述
- 一级缓存又被称为 SqlSession 级别的缓存,是MyBatis默认开启的缓存,无法关闭
- SqlSession是什么:SqlSession 是 SqlSessionFactory会话工厂创建出来的一个会话的对象,这个SqlSession对象用于执行具体的SQL语句并返回给用户请求的结果
- SqlSession级别的缓存是什么意思?SqlSession级别的缓存表示的就是每当执行一条SQL语句后,默认就会把该SQL语句缓存起来,也被称为会话缓存
- 缓存的数据存储在SqlSession对象中,类似Map集合,键对应的SQL语句,值就是语句对应的结果
- 当执行查询语句时,自动走缓存,缓存中如果有数据就返回,缓存没有就查询数据库,更新缓存
- 当执行非查询语句时(新增、修改、删除),就会自动删除缓存
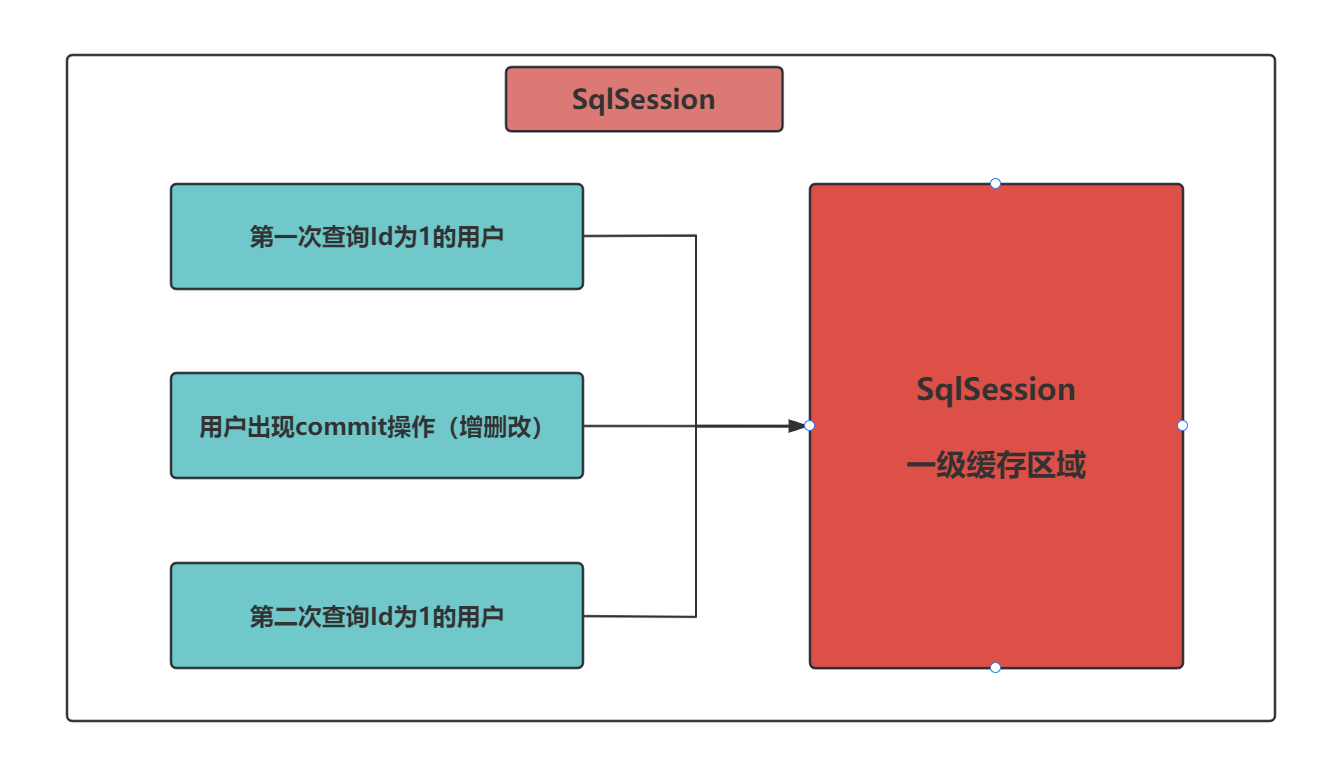
2.一级缓存失效
- 使用不同的SqlSession查询数据
- 同一个SqlSession但是查询条件不同
- 同一个SqlSession两次查询期间执行了任意一次增删改操作
- 同一个SqlSession两次查询期间手动清除了缓存
3、二级缓存
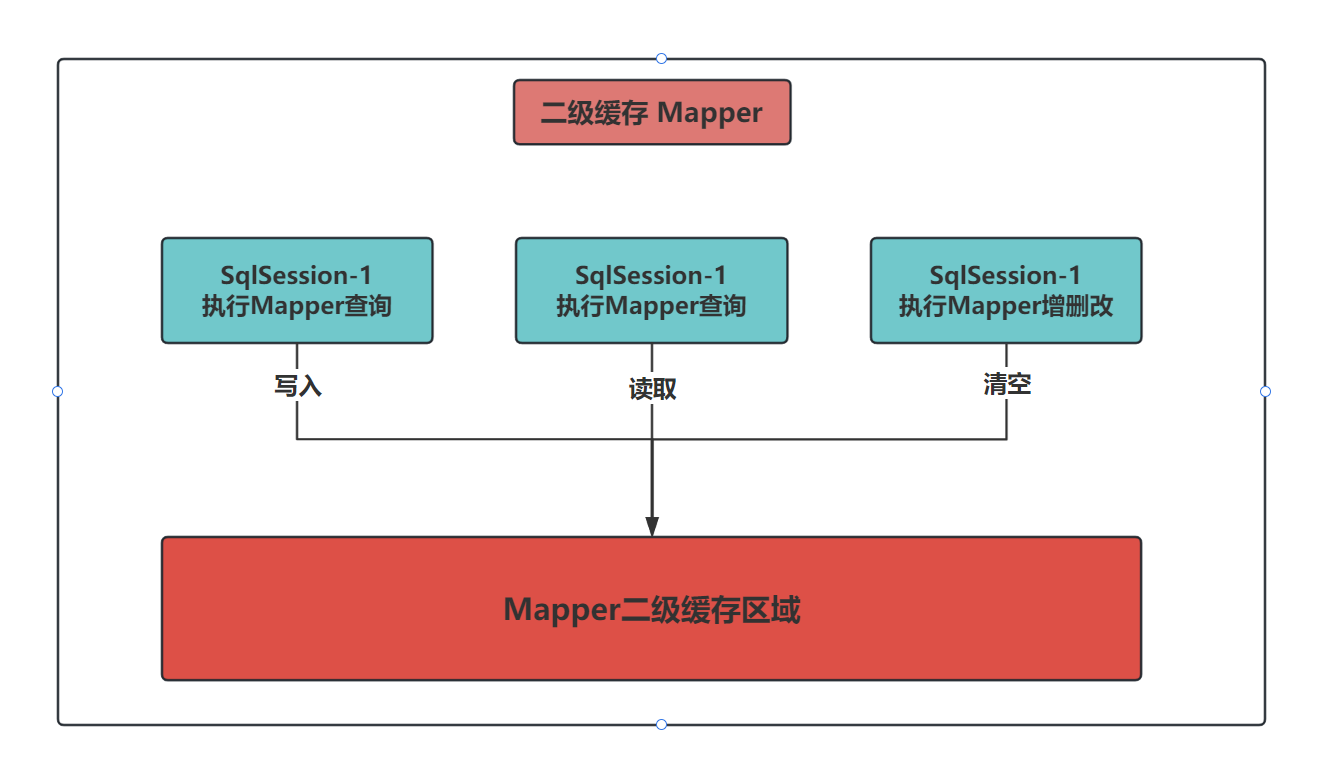
1.概述
- 二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取
- 二级缓存是把缓存的数据存储在SqlSessionFactory中
- 二级缓存的数据,所有的SqlSession对象都可以共用
- 二级缓存默认关闭,需要进行配置进行开启
2.开启条件
- 在核心配置文件中,设置全局配置属性cacheEnabled="true",默认为true,不需要设置
- 在映射文件中设置标签
- 二级缓存必须在SqlSession关闭或提交之后有效
- 查询的数据所转换的实体类类型必须实现序列化的接口
3.二级缓存失效
- 两次查询之间执行了任意的增删改,会使一级和二级缓存同时失效
4、缓存查询执行顺序
- 先查询二级缓存,因为二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用
- 如果二级缓存没有命中,再查询一级缓存
- 如果一级缓存也没有命中,则查询数据库
- SqlSession关闭之后,一级缓存中的数据会写入二级缓存
集成PageHelper
1. PageHelper概述
PageHelper是MyBatis框架上的一款后端分页插件。通过它友好的Api设计,可省去写count,分页sql嵌套的繁琐工作。同时插件内部兼容不同数据库间(MySql、Oracle等)的分页实现。开发者只需关注具体业务sql,其他的统计封装交给PageHelper插件动态处理
2.导入依赖
<!--
单独使用的时候:
PageHelper支持的常见的12种关系型数据库,在编写SQL的时候不会手动写limit关键字,所以代码可以移植
Github项目地址: https://github.com/pagehelper/Mybatis-PageHelper
-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>4.1.0</version>
</dependency>
<!-- 在SpringBoot项目中使用-->
<!-- pagehelper分页插件-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.7</version>
</dependency>3.yml配置
# 分页配置
page helper:
helper-dialect: mysql#数据库方言:mysql, oracle, sqlite
reasonable: true #开启优化,在分页页码结果没有数据的时候,会显示有数据的页码数据,也就是当当前页<1时,返回第 1 页, 当当前页 > 最大页时, 返回最后一页的数据
support-methods-arguments: true #是否支持接口参数来传递分页参数,默认false
pageSizeZero: false #表示当 pageSize=0 时返回所有4.逻辑代码
//原生的写法:1.先查询总页数 2.再根据分页的信息查询当前页的数据
//PageHelper的写法:开启分页
PageHelper.startPage(当前页,每页显示的条数);
//分页查询:只要开启了分页,它会帮助我们做什么事情?
//1.先查询总数量 //2.根据application.yml中驱动名自动实现分页,如果是mysql就用limit
//3.自动计算limit的第一个值:limit a,b [a = 当前页的起始下标 = (当前页-1)*每页显示的条数]
List<Emp> emps = empMapper.pageQuery(empQuery);原文地址:https://blog.csdn.net/LG_971124/article/details/142559912
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!