大模型常见的LoRA算法原理、实现和运用详解
文章目录
1. 前言
本文是常用算法的快速浏览入门(扫盲),结合论文+代码,从原理、实现以及实际应用上深入介绍。
LoRA(Low-Rank Adaptation)是一种用于在预训练模型基础上进行高效微调(Fine-Tuning)的算法,特别适用于大规模语言模型(LLMs)。LoRA 通过引入低秩矩阵的方式来适应和调整模型参数,从而在保持预训练模型原有能力的同时,显著减少微调的计算成本和存储需求。(以上如果看不明白,往后看完一定能懂!)
简言 LoRA:
(1)适用:预训练之后的微调阶段
(2)优势:减少计算成本和存储需求,同时不引入推理延迟(Inference Latency),方便在不同的微调任务灵活切换
论文原文:https://arxiv.org/abs/2106.09685
2. 算法介绍
2.1 微调
首先理解,为什么大模型需要微调。
(1)预训练的语言模型通常在大规模的通用语料库上进行训练,具备广泛的语言理解能力。微调的目的是让这些模型能够适应特定的任务,如情感分析、文本分类、机器翻译、问答系统等。
(2)某些应用可能涉及到专业领域的语言和术语,如医学、法律、金融等。通过在领域特定的数据集上进行微调,模型能够更好地理解和处理这些特定领域的语言和内容。
我们假设预训练得到的参数权重为 W 0 W_0 W0,在微调阶段,更新权重:
W = W 0 + Δ W W = W_0 + \Delta W W=W0+ΔW
其中 Δ W \Delta W ΔW 是微调训练阶段更新的权重大小。
如果直接训练,当预训练模型的 W 0 W_0 W0 矩阵的参数量太大时,导致微调 Δ W \Delta W ΔW 需要计算梯度并维护如此大量的优化器状态,对于动辄几百上千亿的参数量,会消耗大量存储空间。
2.2 核心思想
LoRA 将
Δ
W
\Delta W
ΔW 进行矩阵变换(忽略缩放
α
/
r
\alpha /r
α/r等):
Δ
W
=
B
A
\Delta W = BA
ΔW=BA
其中 Δ W ∈ R d × k \Delta W \in \mathbb{R^{d \times k}} ΔW∈Rd×k, B ∈ R d × r B \in \mathbb{R^{d\times r}} B∈Rd×r, A ∈ R r × k A \in \mathbb{R^{r\times k}} A∈Rr×k。 r ≪ m i n ( d , k ) r\ll min(d, k) r≪min(d,k), r r r 取值一般 1,2,4,8等。
如论文中的下图:
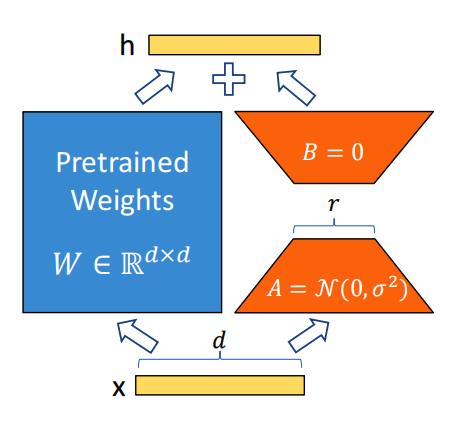
其中
Δ
W
\Delta W
ΔW:
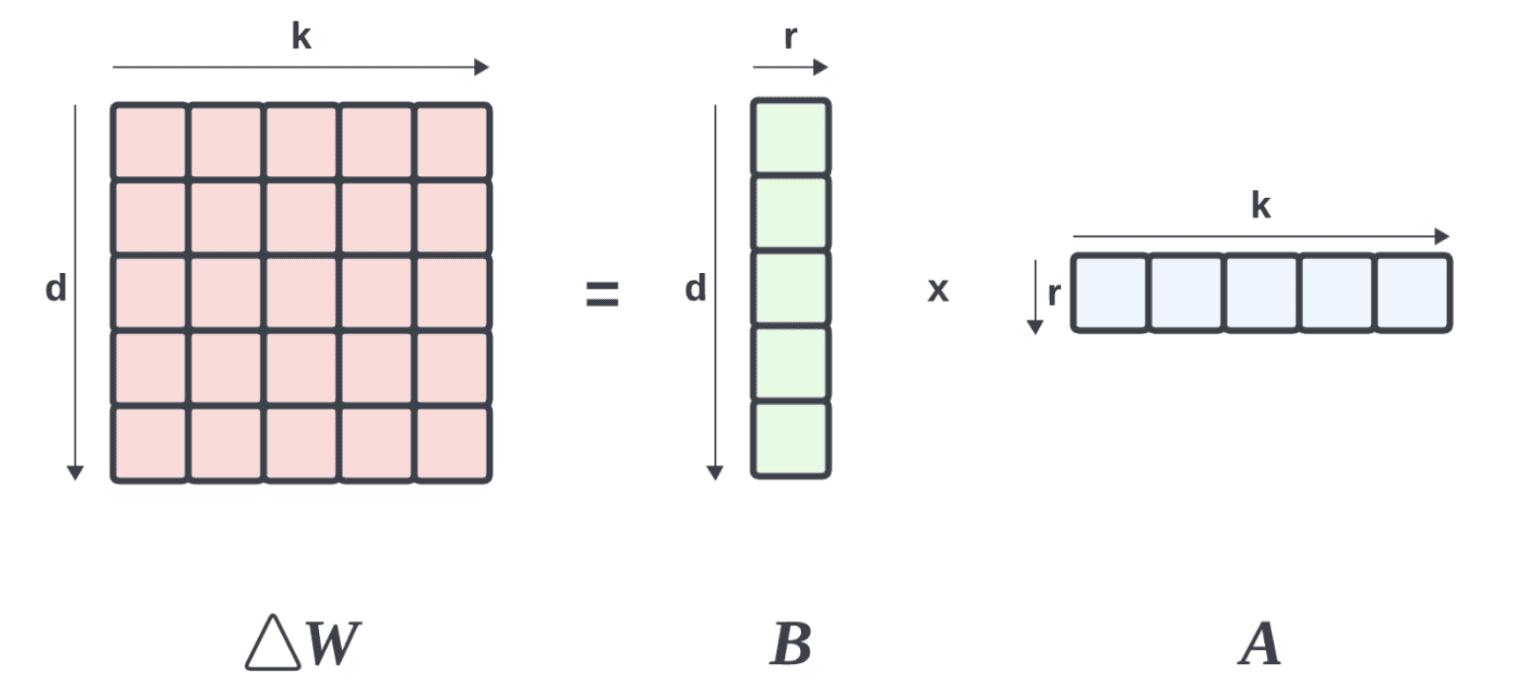
在微调训练中,仅需要计算右边的 A A A、 B B B 矩阵,而不需要变动左边的 W W W(预训练的权重)
这样的权重参数总量
Θ
\Theta
Θ:
Θ
=
(
d
+
k
)
×
r
≪
d
×
k
\Theta=(d+k) \times r \ll d\times k
Θ=(d+k)×r≪d×k
需要维护的权重参数量远远降低了,这个思路是不是有点类似 SVD(奇异值分解)。
论文中表明在 GPT-3 175B 模型上,LoRA 将训练期间的 VRAM 消耗从1.2TB 减少到 350GB。一般对于 Transformer 可以减少 2/3 的内存占用。
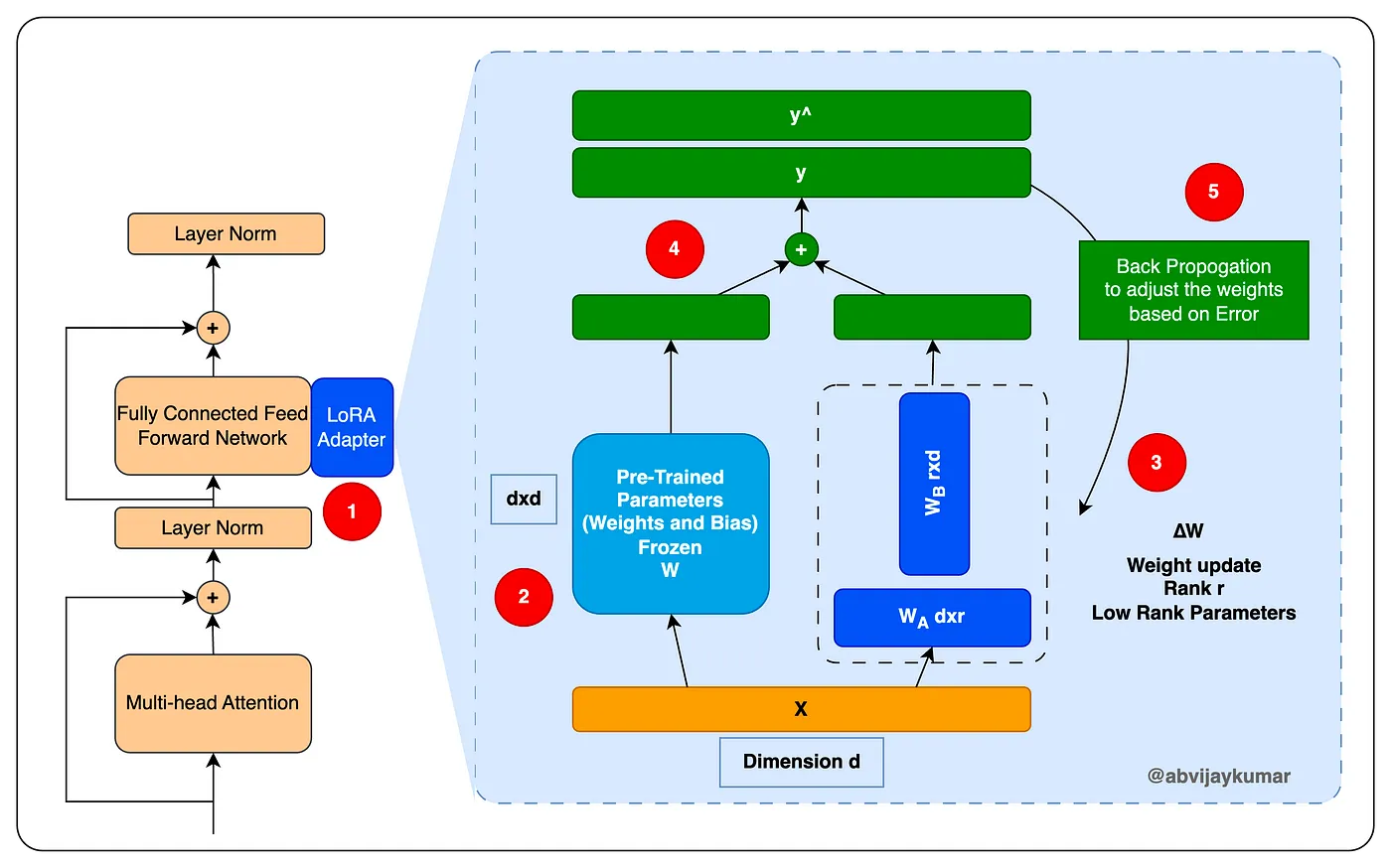
训练过程:
3. 几个关键问题
以下也是论文中提到的在更新权重时的几个重要问题,下面结合本人的理解进行阐述!
3.1 LoRA如何应用在Transformer上
Transformer 的详细介绍参考:
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
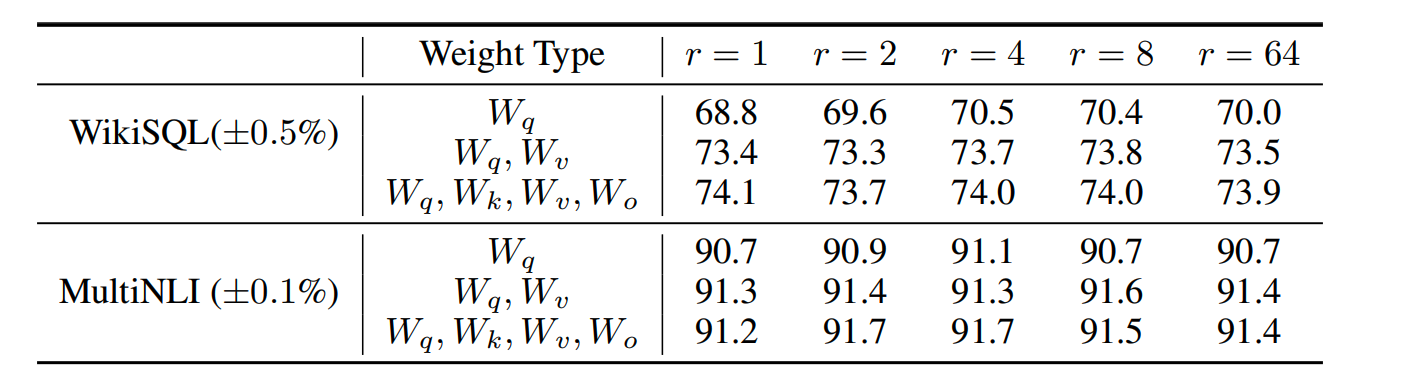
Transformer 有几个权重变换矩阵, W q W_q Wq、 W k W_k Wk、 W v W_v Wv,实际应用 LoRA 是作用在哪些矩阵效果最佳呢?
在 WikiSQL 和 MultiNLI 数据集进行验证:
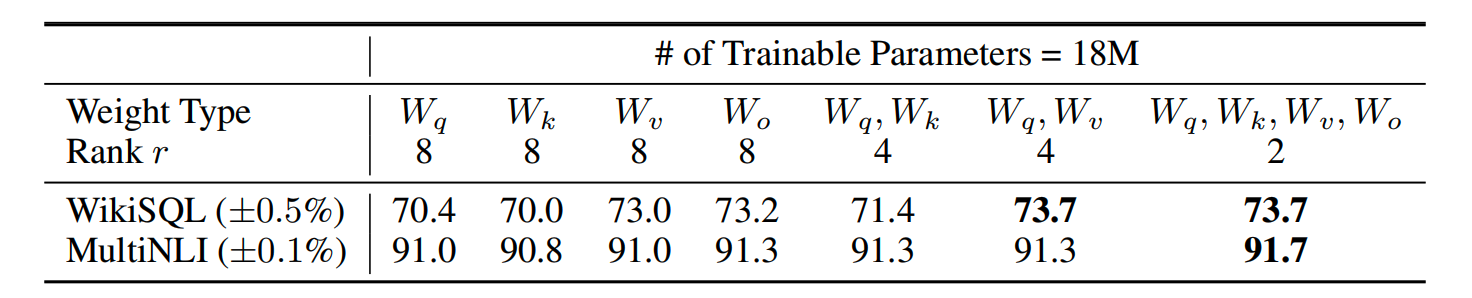
根据实验结果,得出以下结论:
(1)只作用于 W q W_q Wq 或 只作用于 W k W_k Wk 效果最差;
(2)同时作用于 W q W_q Wq 及 W v W_v Wv 效果最好;
(3)秩大、作用于单一矩阵,不如秩小、作用于多种矩阵。
3.2 LoRA的最佳秩r如何选择
以下是实验:
根据实验结果,得出以下结论:
(1)秩非常小都表现出很好的效果,表明更新矩阵 Δ W \Delta W ΔW 可能具有非常小的“内在秩”;
(2)LoRA 作用于越多的矩阵,表现效果越好;
(3)对于简单模型一味增大秩不具备太大的意义,r=4 和 r=64 效果差距不大,但是 r=64 反而消耗了更大的资源;
经验法则:
在实践经验中,选择 r r r 的典型范围在 1 到 64 之间(不绝对)。这个范围内的 r r r 通常可以在性能和效率之间取得较好的平衡。
实验确定:
-
初始尝试:可以从 r = 4 r = 4 r=4 或 r = 8 r = 8 r=8 开始。这些值通常可以提供良好的性能,同时保持低计算成本。
-
性能评估:在验证集上评估模型性能,记录各个 r r r 值对应的性能指标。
-
优化调整:根据评估结果,逐步调整 r r r,如从 r = 4 r = 4 r=4 增加到 r = 128 r = 128 r=128(或更大),观察性能提升情况。
3.3 W W W和 Δ W \Delta W ΔW有什么关系
论文通过计算降维后的 W W W 和 Δ W \Delta W ΔW 的相似程度,得出以下结论:
(1)与随机矩阵相比, Δ W \Delta W ΔW 与 W W W 的相关性更强,这表明 Δ W \Delta W ΔW 放大了 W W W 中已经存在的一些特征;
(2)低秩矩阵潜在地放大了特定下游任务的重要特征,这些特征在一般的预训练模型中被学习但没有被强调。
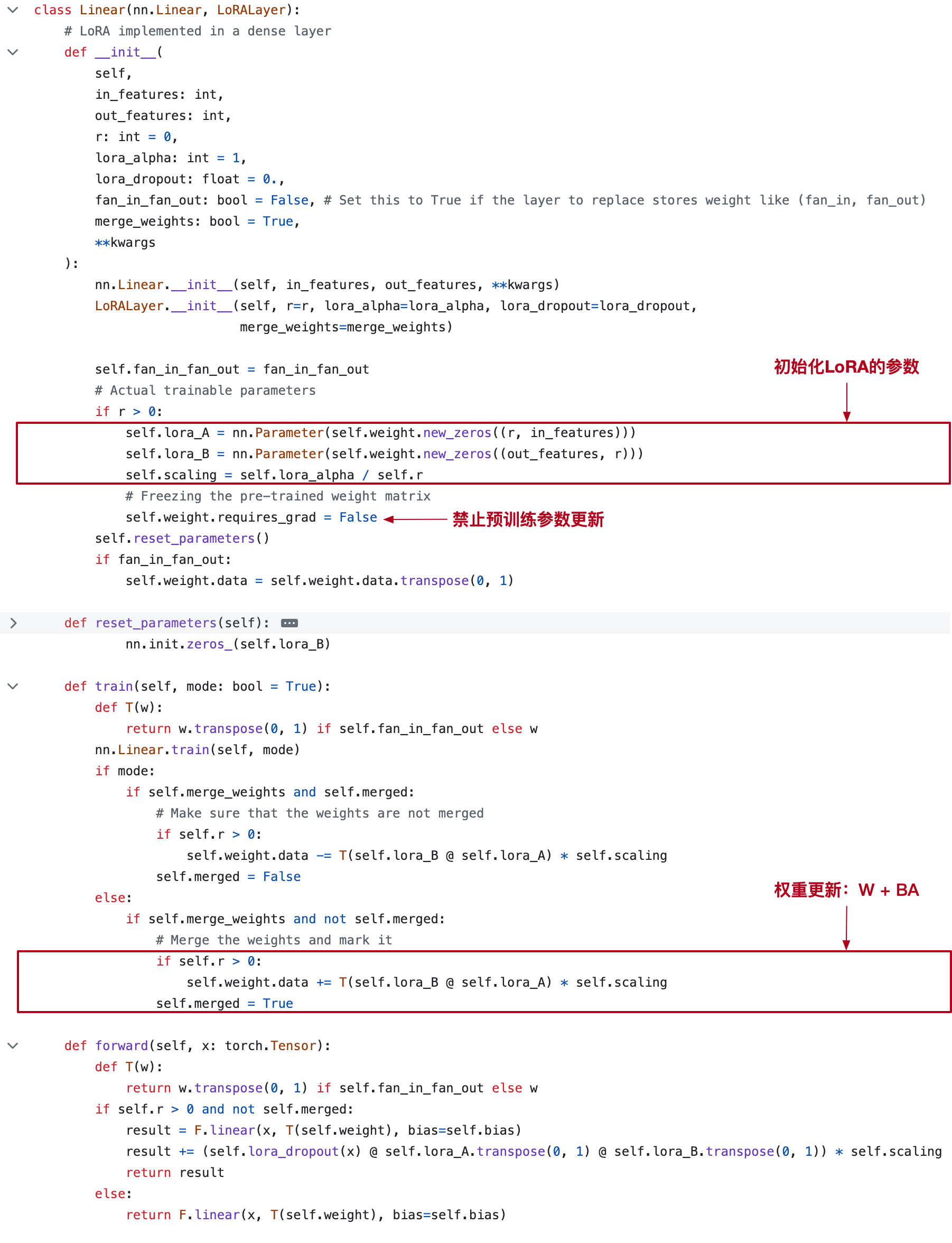
4. 源码
源码:https://github.com/microsoft/LoRA
以 Linear 为例,代码比较简单:
5. 实际应用
LoRA 集成到 peft 库中。使用 LoRA,需要增加一个配置,其他代码没有变化。
(1)配置 LoRA 参数:
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
LORA_R = 16
LORA_ALPHA = 32
LORA_DROPOUT = 0.05
# Define LoRA Config
lora_config = LoraConfig(
r = LORA_R, # the dimension of the low-rank matrices
lora_alpha = LORA_ALPHA, # scaling factor for the weight matrices
lora_dropout = LORA_DROPOUT, # dropout probability of the LoRA layers
bias="none",
task_type="CAUSAL_LM",
target_modules=["query_key_value"],
)
# Prepare int-8 model for training - utility function that prepares a PyTorch model for int8 quantization training. <https://huggingface.co/docs/peft/task_guides/int8-asr>
model = prepare_model_for_int8_training(model)
# initialize the model with the LoRA framework
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
(2)训练部分(不变):
from transformers import TrainingArguments, Trainer
import bitsandbytes
EPOCHS = 3
LEARNING_RATE = 1e-4
MODEL_SAVE_FOLDER_NAME = "dolly-3b-lora"
training_args = TrainingArguments(
output_dir=output_dir,
learning_rate=1e-5,
logging_steps=100,
num_train_epochs=EPOCHS,
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_data_tokenized,
eval_dataset=val_data_tokenized,
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
# only saves the incremental PEFT weights (adapter_model.bin) that were trained, meaning it is super efficient to store, transfer, and load.
trainer.model.save_pretrained(MODEL_SAVE_FOLDER_NAME)
# save the full model and the training arguments
trainer.save_model(MODEL_SAVE_FOLDER_NAME)
trainer.model.config.save_pretrained(MODEL_SAVE_FOLDER_NAME)
6. 总结
(1)低秩近似:LoRA 假设预训练模型的权重变化可以通过低秩矩阵来表示。这意味着相对于直接微调所有模型参数,通过低秩矩阵的调整,可以用更少的参数达到近似效果。
(2)参数效率:LoRA 只引入了少量的附加参数,这些参数是低秩矩阵的元素。由于这些矩阵的秩较低,所需的附加参数数量远小于模型的原始参数数量,显著减少了存储和计算开销。
(3)模块化设计:LoRA 通过在模型的特定层或模块中插入低秩矩阵,使其易于集成到各种预训练模型中,不需要对模型的原始结构进行大幅度修改。
LoRA 的设计和应用有效地解决了大规模模型微调中的高成本问题,使得在资源有限的环境中进行高效的模型适应成为可能。
7. 参考
[1] https://arxiv.org/abs/2106.09685
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤

原文地址:https://blog.csdn.net/qq_36803941/article/details/140298164
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!