多模态理论基础——什么是多模态?
多模态理论
1.什么是多模态(multimodal)
模态指的是数据或者信息的表现形式,如文本、图像、音频、视频等
多模态指的是数据或者信息的多种表现形式,一个信息,它可以存在多种表现形式。

为什么会有多模态呢?
因为人类有多种感官来处理信息:比如听觉、嗅觉、视觉、触觉、味觉等,它们都可以获取并且处理不同形式的信息。
为了让计算机具备分析互联网数据的能力、模拟人类的认知方式,同时处理多个模态数据的多模态信息处理技术应运而生。
2.深度学习中的多模态
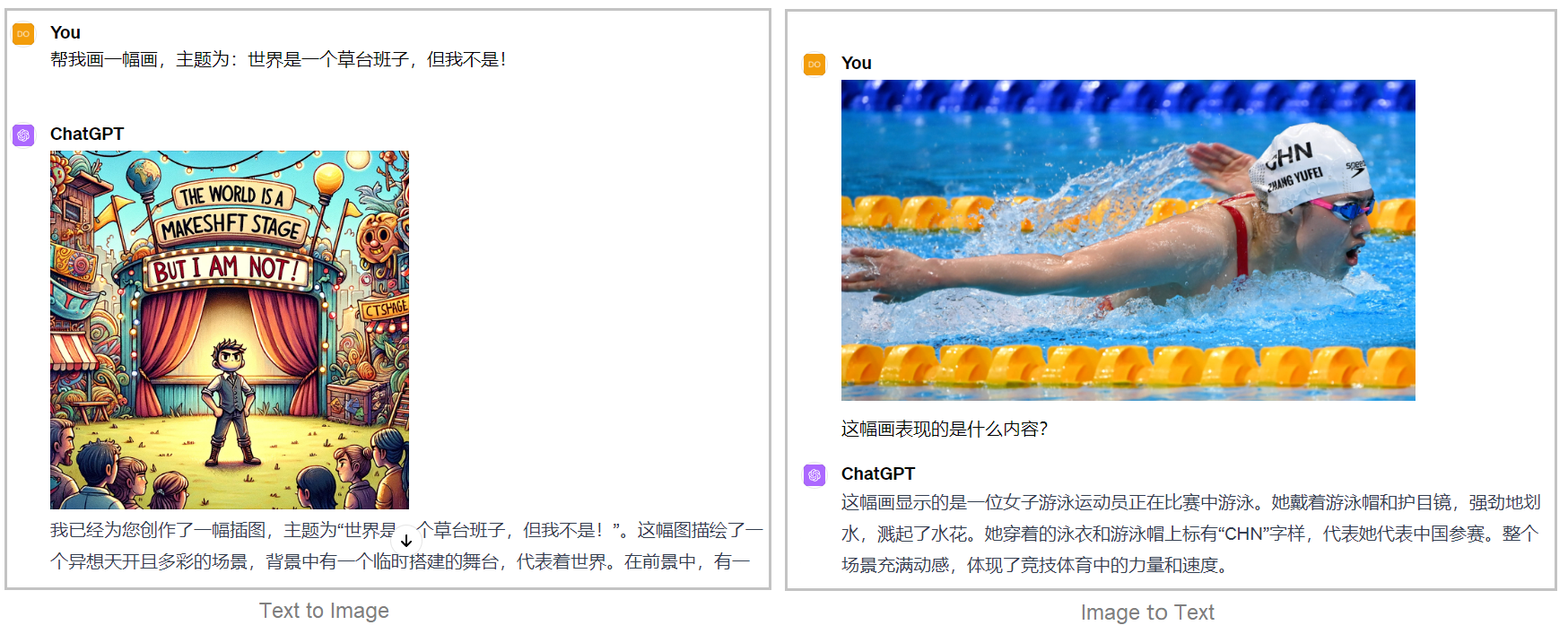
在目前的人工智能任务中,我们所说的多模态更多的指对于 3V 任务的支持,也即 Verbal(文本)、Vocal(语音) 和 Visual(视觉)。
深度学习中有很多经典的任务,都是基于这三种任务之间互相转换的。比如图像生成任务(Image Generation from Text),根据文本描述生成图像,反过来的图像描述任务(Image Captioning),根据图像来生成文本,就像是我们小学学的看图作文一样。
原文地址:https://blog.csdn.net/qq_54695558/article/details/142721276
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!