今日Arxiv最热NLP大模型论文:北京大学发布“讨论链”,利用LLM协作回答复杂问题
开放式问答(Open-ended Question Answering, QA)是人工智能领域的一个重要分支,它要求模型能够找到合适的证据,并形成有理有据、全面且有帮助的答案。在实际应用中,模型还需要能够就与问题紧密相关的潜在场景进行扩展讨论。虽然开源的大型语言模型(Large Language Models, LLMs)通过检索模块的增强能够产生连贯的答案,但在可靠证据选择和深入问题分析方面仍然存在不足。本文提出了一个新颖的“讨论链”框架(Chain-of-Discussion framework),通过利用多个开源LLMs之间的协同作用,旨在为开放式QA提供更正确、更全面的答案。实验表明,多个LLMs之间的讨论在提高答案质量方面起着至关重要的作用。
论文标题:
Chain-of-Discussion: A Multi-Model Framework for Complex Evidence-Based Question Answering
论文链接:
https://arxiv.org/pdf/2402.16313.pdf
复杂开放式问答的现状与问题
1. LLMs在长篇问答中的局限性
大语言模型(LLMs)在开放式问答任务中表现出了卓越的语言生成能力,但在复杂的开放式问答中,它们仍然存在局限性。这类任务通常要求模型首先分析问题,然后检索相应的证据,最后形成一个正确、合理且有详细证据支持的长篇答案。然而,LLMs在可靠证据选择和深入问题分析方面仍然表现不佳,尤其是在与法律咨询、医疗建议等知识密集型问题相关的场景中。
以法律咨询为例,模型在回应关于子女抚养费必要性的问题时,可能会由于语义相似性而错误地返回与监护资格相关的法律条文。LLMs通常无法过滤掉所有这些噪声证据,这可能导致不完整的分析、错误的推理路径、偏见的观点,最终产生问题性或误导性的答案。
以法律咨询为例,模型在回应关于子女抚养费必要性的问题时,可能会由于语义相似性而错误地选取与监护资格相关的法律条文。LLMs通常无法过滤掉所有这些噪声证据,这可能导致不完整的分析、错误的推理路径、偏见的观点,最终产生误导性的答案。
2. 不完善的检索模型与深度问题分析
LLMs在提供正确回应和一致解释的同时,还需要提供关于潜在场景的更有用建议,即使这些场景没有在问题中直接提及。例如,模型在回应一个面临财务困难的用户关于支付子女抚养费的义务时,也应提醒用户关于子女抚养费标准的信息以及如何协商减轻抚养负担的方法。这对于人类来说都是一项挑战,因为需要访问适当的证据并提供合理的提醒和解释,更不用说没有大量注释数据进行训练或微调的LLMs了。
CoD框架的提出背景
1. 多模型协作的必要性
不同的LLMs由于训练数据的不同,可能具有不同的内在知识和推理能力。因此,多个LLMs协作可能比单个LLM犯错误的可能性要小。最近的研究表明,通过检查多个LLMs的一致性有助于减少输出幻觉。该研究提出了一个批评与修正的框架,要求多个LLMs讨论并达成共识以获得更好的回应。对于需要涉及有用场景或可能扩展的问题,研究者猜测多个LLMs可能提供多样化的视角来解决这些可能性。
2. CoD框架的核心思想
该研究提出了一个新颖的Chain-of-Discussion(CoD)框架,涉及多个LLMs在总结、批评和修订彼此的输出以达到一个有良好支持和有帮助的回应。与现有的多模型交互工作不同,研究者决定研究如何最好地利用小规模的开源LLMs,例如约7B参数的模型,共同实现一个目标,同时推动多模型交互研究的边界。
CoD框架的工作流程
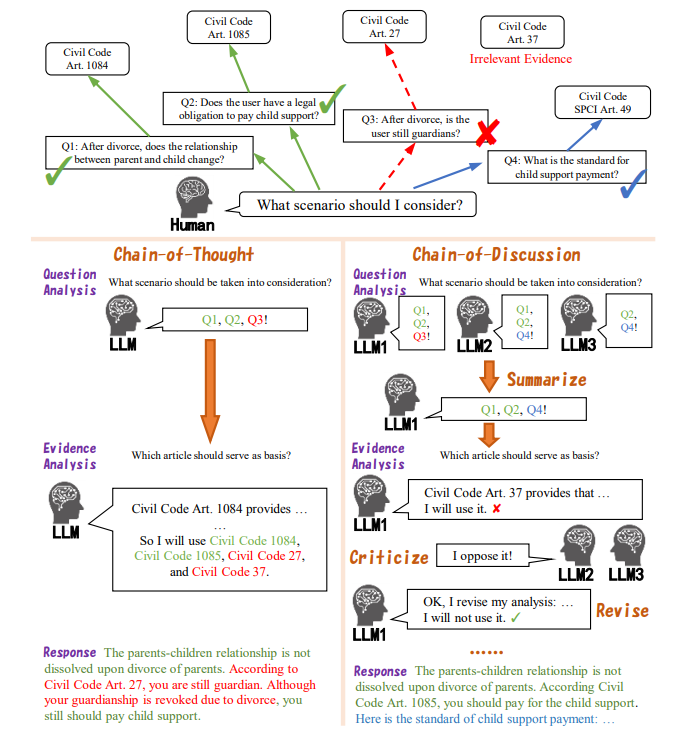
1. 问题分析
在CoD框架的问题分析阶段,多个开源大语言模型(LLMs)被用来分析用户提出的问题。每个模型都会独立地考虑问题中提到的事实、用户的主要需求以及与问题相关的潜在情景。由于不同的LLMs可能会有不同的知识和推理能力,它们可能会对潜在情景进行不同的分析。因此,通过整合多个LLMs的输出,可以考虑到更多有用的情景,从而提高问题分析的全面性。目标LLM将总结所有模型的问题分析,以确保一致性和全面性。
2. 证据分析
在证据分析阶段,目标模型需要判断检索到的每个证据文档是否能够用于回答问题。然而,单个LLM可能会产生错误的输出,错误地评估证据文档与问题之间的相关性。为了提高证据分析的质量,CoD框架引入了多方讨论机制。除了目标模型外,其他LLMs将批评目标模型的证据分析,并明确指出是否存在与目标模型相反的意见。如果批评中相反意见的比例超过设定的阈值,目标模型将根据批评结果修正其证据分析。
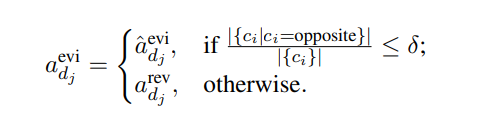
3. 响应生成
在响应生成阶段,目标LLM将基于总结的问题分析和修正后的证据分析生成最终的响应。该响应旨在正确并且有帮助,同时避免使用与问题无关的证据。
实验设计与数据集
1. 法律咨询任务的选择
法律咨询任务是基于证据的复杂问答任务(CEBQA)的一个典型例子,要求模型生成准确的响应,并包括对相关情景的有用讨论。实验选择了中国的法律咨询任务,因为所有的法律活动都应该基于法律条文和司法解释,这些可以自然地被视为框架中的证据存储。
2. 数据集的构建与质量保证
为了确保数据质量,研究者们收集了200个来自真实用户的法律咨询问题及其对应的咨询回答,并进行了人工检查。为了评估这些回答的正确性和逻辑一致性,两名具有民法背景的注释者对回答进行了检查。在证据注释方面,研究者们基于民法典和民事诉讼法及其司法解释构建了证据库,并将这些条文分为三类:必要、可选和不需要。必要条文与问题高度相关,可选条文可以作为讨论潜在情景的基础。平均每个例子包含1.52个必要条文、1.23个可选条文和2.25个不需要的条文,这意味着大约45%的检索到的条文根本不需要。
实验结果与分析
1. CoD框架在不同模型上的表现
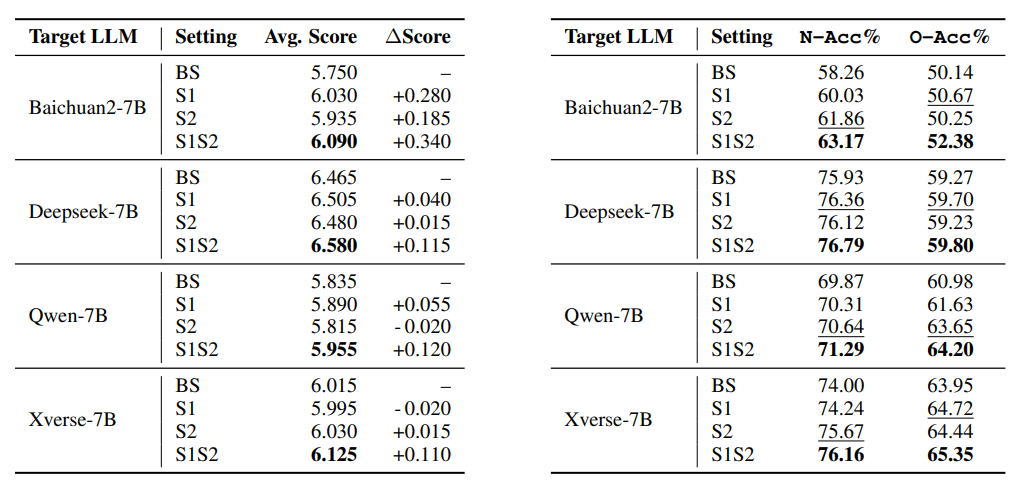
在实验中,CoD框架被应用于多个开源大语言模型(LLMs),包括Baichuan2-7B、Deepseek-7B、Qwen-7B和Xverse-7B。这些模型在处理基于证据的复杂问答任务(CEBQA)时,通过相互总结、批评和修正输出,以达到更好的回答质量。实验设置包括单模型基线、仅第一阶段、仅第二阶段以及完整的Chain-of-Discussion框架。
实验结果表明,CoD框架在提高模型在正确性和全面性方面的表现上具有显著效果。例如,当使用CoD框架时,Baichuan2-7B在N-Acc(必要法条选取准确性)和O-Acc(可选法条选取准确性)上分别提高了约2%,而Deepseek-7B也分别提高了0.86%和0.53%。这些提升表明,通过多模型间的讨论,LLMs能够更准确地引用正确的证据,从而提高了回答的质量。
2. CoD框架的优势:正确性与全面性
CoD框架的设计旨在通过多个LLMs之间的互动讨论,来提高回答的正确性和全面性。在正确性方面,CoD框架通过批评和修正过程,减少了单个模型可能产生的幻觉输出和错误推理路径。在全面性方面,CoD框架通过总结步骤,整合了多个模型对潜在情景的不同视角,从而提供了更为详尽和全面的回答。
CoD框架的局限性与挑战
1. 开源LLMs的限制
尽管CoD框架在多个LLMs之间的互动中取得了一定的成功,但开源LLMs的限制仍然是一个挑战。由于参数规模的限制,这些模型可能产生不可靠的输出或在遵循指令方面表现出较差的能力。例如,在实验中,Qwen-14B和Baichuan2-13B在处理长输入序列时表现出次优能力,这可能导致它们无法遵循指令,进而输出碎片化的文本。
2. 幻觉传播与模型修正偏好
CoD框架在总结问题分析的阶段可能会遇到幻觉传播的问题。即使目标模型被明确指示评估其他LLMs的问题分析的逻辑正确性和相关性,它仍可能将幻觉分析纳入总结中。此外,不同的LLMs在是否修改证据分析方面表现出不同的偏好。有些模型可能更倾向于修正分析,而有些则可能拒绝修改,这可能导致CoD框架无法如预期那样带来足够的改进。
总的来说,CoD框架在提高开源LLMs的性能方面展现出了潜力,但仍需要解决开源LLMs的局限性和幻觉传播等问题。未来的研究可以探索如何通过监督训练和奖励建模来影响LLMs的偏好,从而进一步提高CoD框架的有效性。
结论与未来展望
1. CoD框架的贡献与应用潜力
本研究提出的Chain-of-Discussion(CoD)框架,通过多个开源大型语言模型(LLMs)之间的互动讨论,显著提升了复杂证据支持型问答(CEBQA)任务的答案质量。CoD框架的核心在于利用不同LLMs的独特知识和推理能力,通过总结、批评和修正的过程,生成更准确、全面的回答。实验结果表明,CoD框架能够有效减少错误信息的传播,提高答案的正确性和细节丰富度。
CoD框架的应用潜力巨大,尤其是在法律咨询、医疗建议、教育支持和金融分析等领域。在这些领域,用户常常提出复杂且知识密集型的问题,需要模型不仅提供正确答案,还要涉及潜在相关场景的深入讨论。CoD框架通过多模型互动,能够从多个角度分析问题,提供更全面的建议和解决方案。
未来,CoD框架的研究可以在多个方向上进一步深入。例如,探索如何更有效地整合不同LLMs的知识,以及如何减少计算资源消耗以适应更大规模的应用场景。此外,研究如何将CoD框架应用于更多语言和领域,以及如何进一步提高模型的自适应能力和鲁棒性,也是未来工作的重要方向。
2. 对开放式问答技术的影响与改进方向
CoD框架对开放式问答技术产生了显著影响,特别是在处理复杂问题和提供基于证据的回答方面。传统的LLMs在处理开放式问答时,常常受限于单一模型的知识和推理能力,而CoD框架通过模型间的互动讨论,有效地弥补了这一不足。
然而,CoD框架也面临一些挑战和改进方向。首先,如何确保多个模型间讨论的质量和效率,避免错误信息的传播,是一个需要解决的问题。其次,如何平衡模型间讨论的深度和广度,以及如何处理模型间意见不一致的情况,也是未来研究的重点。此外,开放式问答技术的改进还需要考虑如何减少对大量计算资源的依赖,以及如何提高模型的可解释性和用户信任度。
总之,CoD框架为开放式问答技术带来了新的视角和方法,未来的研究将继续在提高答案质量、扩展应用范围和优化计算效率等方面进行探索和创新。

原文地址:https://blog.csdn.net/xixiaoyaoww/article/details/136473481
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!