Java版Flink使用指南——定制RabbitMQ数据源的序列化器
在《Java版Flink使用指南——从RabbitMQ中队列中接入消息流》一文中,我们从RabbitMQ队列中读取了字符串型数据。如果我们希望读取的数据被自动化转换为一个对象,则需要定制序列化器。本文我们就将讲解数据源序列化器的定制方法。
新建工程
我们在IntelliJ中新建一个工程SourceSerializer。
Archetype填入:org.apache.flink:flink-quickstart-java
版本填入与Flink的版本:1.19.1

新增依赖
在pom.xml中新增RabbitMQ连接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-rabbitmq</artifactId>
<version>3.0.1-1.17</version>
</dependency>
新增Json库依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.17.1</version>
</dependency>
新增lombok库,主要是为了使用它的一些注解
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
数据对象
我们新建一个简单的数据对象SampleData
src/main/java/org/example/vo/SampleData.java
package org.example.vo;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SampleData {
private Long id;
private String name;
private int age;
private Boolean married;
private Double salary;
public String toJson() throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
return mapper.writeValueAsString(this);
}
public static SampleData fromJson(String json) throws JsonProcessingException {
ObjectMapper mapper = new ObjectMapper();
return mapper.readValue(json, SampleData.class);
}
}
这个方法包含两个方法,一个是将SampleData 转换成字符串,另一个是将字符串转成SampleData 对象。
序列化器
我们定义的数据源序列化器要实现AbstractDeserializationSchema接口,主要是通过deserialize方法将二进制数组转换成SampleData 对象。
src/main/java/org/example/serializer/SampleDataRabbitMQSourceSerializer.java
package org.example.serializer;
import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.example.vo.SampleData;
import java.io.IOException;
public class SampleDataRabbitMQSourceSerializer extends AbstractDeserializationSchema<SampleData> {
@Override
public SampleData deserialize(byte[] message) throws IOException {
return SampleData.fromJson(new String(message));
}
@Override
public boolean isEndOfStream(SampleData nextElement) {
return false;
}
@Override
public TypeInformation<SampleData> getProducedType() {
return TypeInformation.of(SampleData.class);
}
}
接入数据源
我们在《Java版Flink使用指南——定制RabbitMQ的Sink序列化器》一文中,往data.to.rbtmq对了写入了大量SampleData 数据。这次我们将其作为数据源来做测试
这次我们在创建RMQSource时传入序列化器SampleDataRabbitMQSourceSerializer。它会将从RabbitMQ获取的数据转换成SampleData对象。
然后我们获取所有“已婚”(filter.getMarried() == true)的数据,将其打印到日志中。
String queueName = "data.to.rbtmq";
String host = "172.21.112.140"; // IP of the rabbitmq server
int port = 5672;
String username = "admin";
String password = "fangliang";
String virtualHost = "/";
int parallelism = 1;
// create a RabbitMQ source
RMQConnectionConfig rmqConnectionConfig = new RMQConnectionConfig.Builder()
.setHost(host)
.setPort(port)
.setUserName(username)
.setPassword(password)
.setVirtualHost(virtualHost)
.build();
RMQSource<SampleData> rmqSource = new RMQSource<>(rmqConnectionConfig, queueName, true, new SampleDataRabbitMQSourceSerializer());
final DataStream<SampleData> stream = env.addSource(rmqSource).name(username + "'s source from " + queueName).setParallelism(parallelism);
stream.filter(filter -> filter.getMarried() == true).print().name(username + "'s sink to stdout").setParallelism(parallelism);
测试
修改Slot个数
由于我们要运行两个流式计算任务,于是需要两个Slot。
vim conf/config.yaml
将numberOfTaskSlots的值改成2。
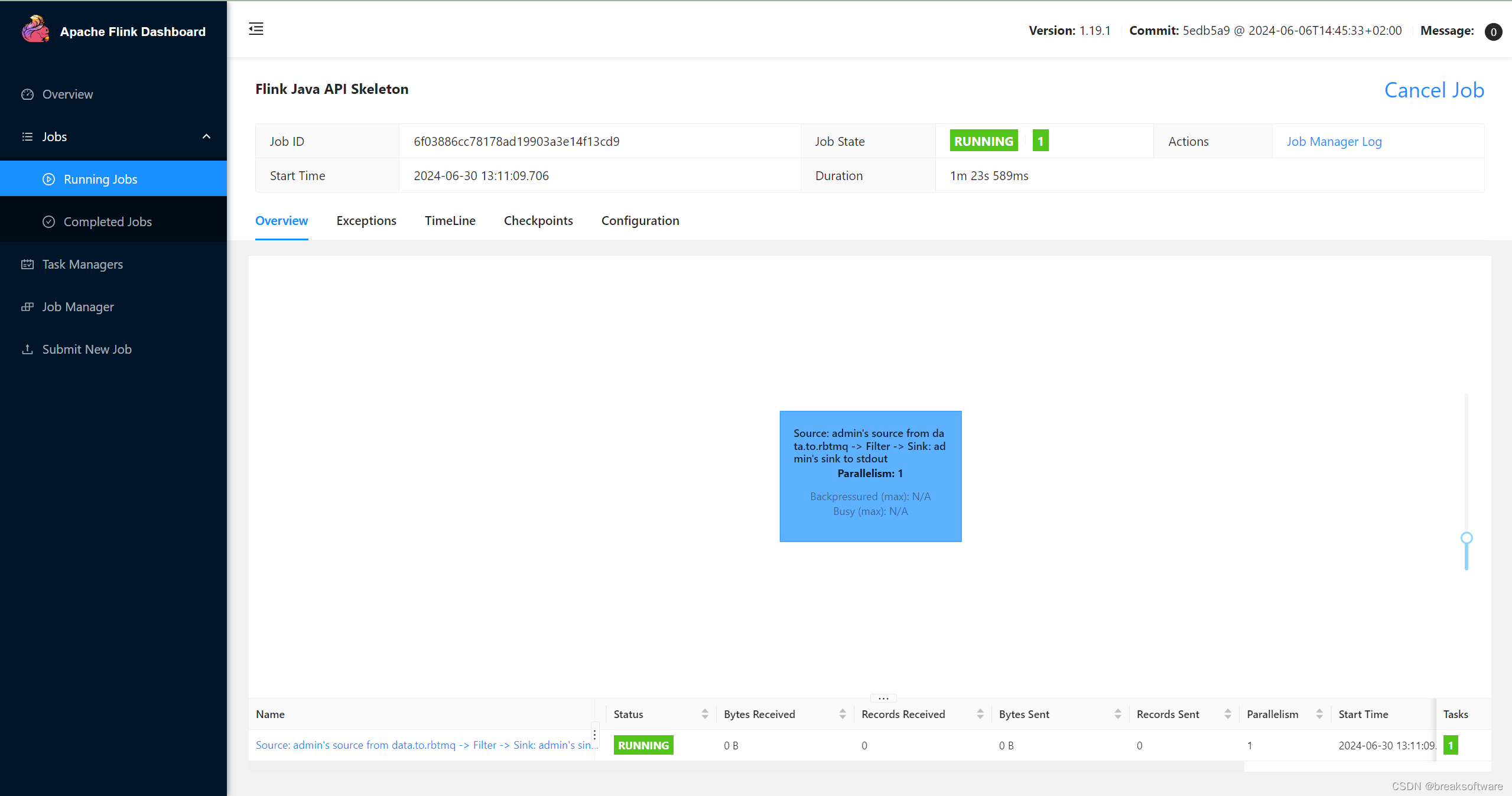
打包、提交、运行
我们将本例和《Java版Flink使用指南——定制RabbitMQ的Sink序列化器》中的包都提交运行
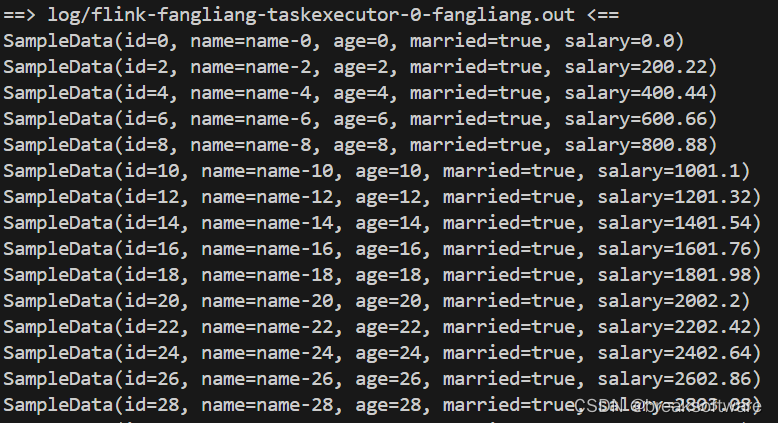
然后在日志中可以看到“已婚”的数据都在输出
tail -f log/*
工程代码
https://github.com/f304646673/FlinkDemo
原文地址:https://blog.csdn.net/breaksoftware/article/details/140077842
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!