如何解决selenium无头浏览器访问页面失败问题!!
无头浏览器简介
无头浏览器(Headless browser)是一种没有图形用户界面(GUI)的网络浏览器。它可以在后台运行,并通过编程接口进行控制和操作,而不需要显示界面。通常,传统的浏览器如 Chrome、Firefox 和 Safari 都具有图形用户界面,但这些浏览器也提供了无头模式的选项。无头浏览器的主要用途是自动化测试和网页爬取。通过使用编程语言(如JavaScript,Python,Java等)的驱动程序或库,开发者可以模拟用户交互,并执行各种操作,如加载页面、点击按钮、填写表单等。由于无头浏览器在后台运行,因此可以在服务器上高效地进行自动化测试和数据抓取,而无需实际显示浏览器窗口。
无头浏览器优点
没有图形用户界面,可以节省资源和内存消耗。提供编程接口,可以通过代码进行控制和操作。支持模拟用户行为,如点击、输入、提交表单等。可以访问网页的 DOM 结构和网络请求,并进行相应的处理和分析。
无头浏览器代码设置
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
完整无头浏览器代码设置
由于谷歌浏览器会自动更新,每次运行脚本会判断chromedeiver是否和chrome浏览器版本匹配。所以需要设置自动下载最新chromedriver驱动的脚本。
from selenium.webdriver.chrome.service import Service as ChromeService
# WebDriver-Manager自动更新驱动程序的版本
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
service = ChromeService(ChromeDriverManager().install(), 30)
# 设置无头浏览器,解决无头浏览器定位元素失败
options = Options()
self.driver = webdriver.Chrome(options=options, service=service)
运行当前脚本
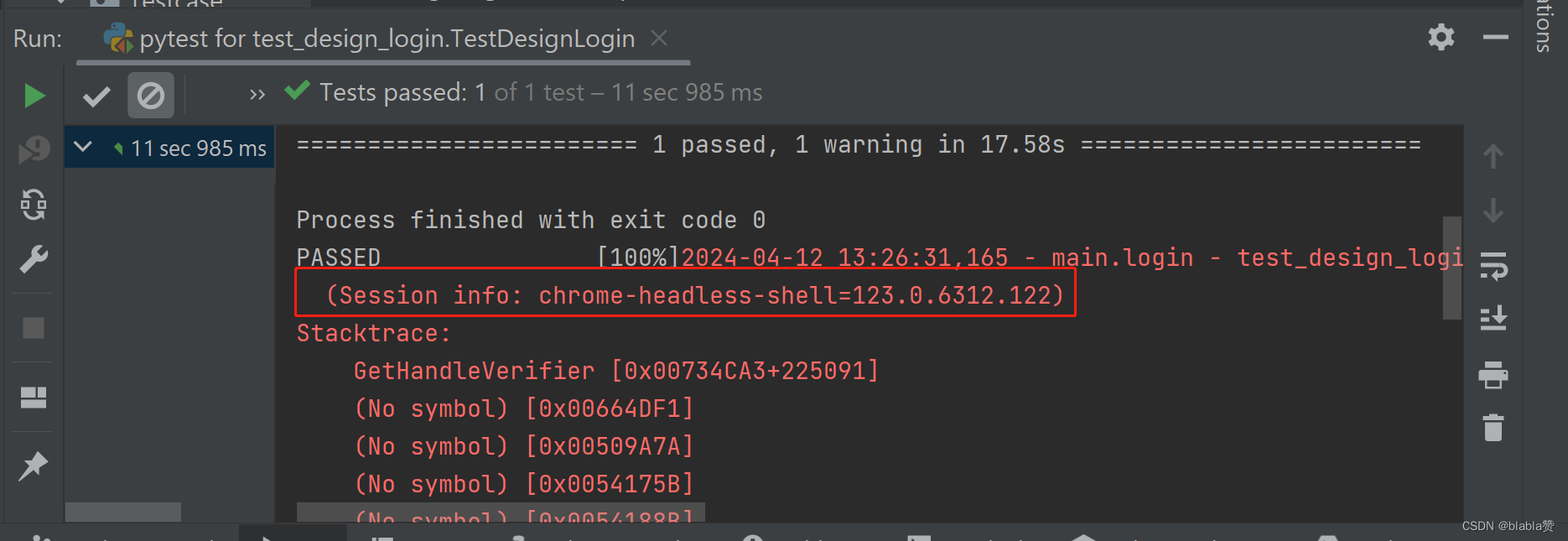
当前截图错误是由于selenium通过无头浏览器操作页面,受到了反向爬虫限制,导致页面访问被禁止。导致定位元素失败。
解决方案-附上完整代码
service = ChromeService(ChromeDriverManager().install(), 30)
# 设置无头浏览器,解决无头浏览器定位元素失败
options = Options()
options.add_argument("--window-size=1920,1080")
options.add_argument("--disable-extensions")
options.add_argument("--proxy-server='direct://'")
options.add_argument("--proxy-bypass-list=*")
options.add_argument("--start-maximized")
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')
options.add_argument('--ignore-certificate-errors')
self.driver = webdriver.Chrome(options=options, service=service)
原文地址:https://blog.csdn.net/dadati/article/details/137674418
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!