NVIDIA RTX 4090解析:卓越的性能表现带来全新的AI探索高度
前言
NVIDIA GeForce RTX 4090 在性能、效率和 AI 驱动的图形领域实现了质的飞跃。这款 GPU 采用 NVIDIA Ada Lovelace 架构,配备 24 GB 的 GDDR6X 显存。此外,RTX 4090还引入了多项创新技术。例如,它支持 DirectX12Ultimate,能够在即将推出的视频游戏中支持硬件光线追踪和可变速率着色,为用户带来更加逼真的游戏画面。同时,其采用的第三代光线追踪核心RT Core和第四代 Tensor 内核,使得显卡在光线追踪和 AI 辅助渲染方面的性能达到新的高度。
同时在此还要重点提一下4090显卡在AI和机器学习上的优势:首先,NVIDIA GeForce RTX 4090配备强大的人工智能加速功能,如Tensor内核和CUDA内核,可用于加速人工智能和机器学习任务;其次,该显卡与TensorFlow和PyTorch等流行的人工智能库兼容,使开发人员能够轻松地使用这些库实现人工智能和机器学习模型;支持CUDA优化库,如cuDNN、TensorRT和CUDA-X AI,进一步加速AI-ML工作负载的同时也为显卡提供了强大的并行处理能力。
出色的性能表现;相比于前作提升明显
- 专业图形处理方面:在 CAD 建模、3D 渲染、影视后期、深度学习等专业领域,RTX 4090 凭借其强大的浮点运算能力和对 CUDA、OpenCL 等 API 的良好支持,大幅提升了工作效率。
- 科学计算与仿真方面:科研工作者和工程师可以利用 RTX 4090 进行复杂的科学计算和大规模仿真项目,显著加快数据处理速度,缩短研究周期。
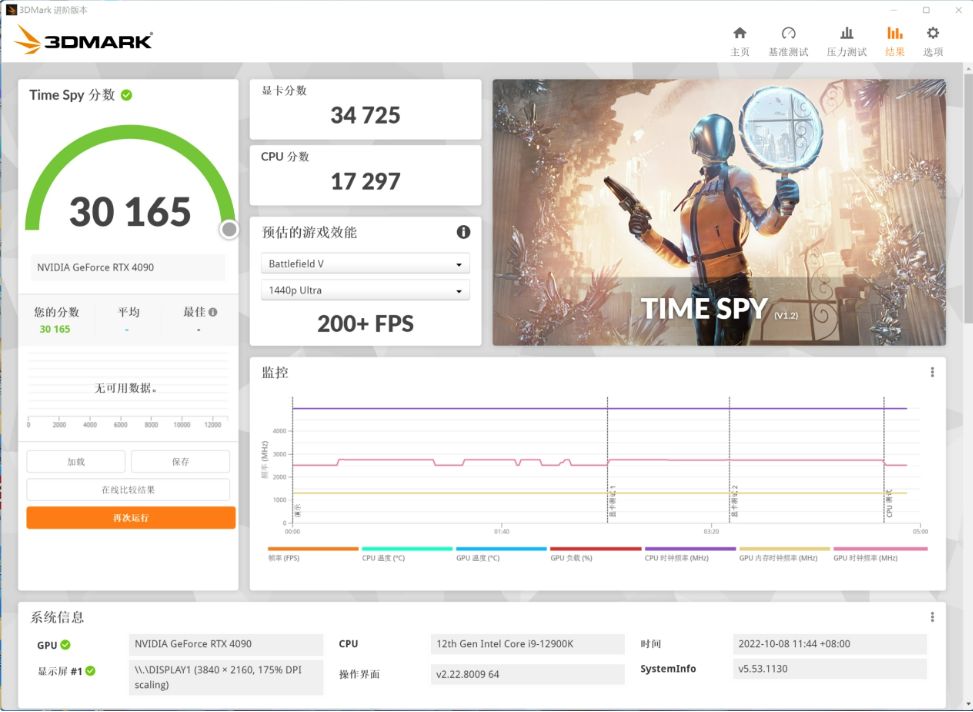
在3DMark TimeSpy DX12 测试中,GeForce RTX 4090 显卡分数达到了 34725 分,作为对比,GeForce RTX 3090 的分数为 18981 分,RTX 3090Ti 为 21862 分。也就是说 GeForce RTX 4090 的提升达到了 82.95%,这个提升幅度堪称恐怖。

在3DMark Fire Strike DX11 测试中,GeForce RTX 4090 显卡分数达到了 75013 分,作为对比,GeForce RTX 3090 的分数为 46045 分,GeForce RTX 3090Ti 为 52630 分。提升幅度同样有达到了 62.91%,这个分数意味着可以 4K 分辨率流畅运行所有的游戏了,哪怕是光追游戏和 VR 游戏也能满足高刷新率的需求。


以下是一张GPU 物理分数的对比表,在所有项目中 RTX 4090 相比于前代旗舰卡都有着几乎翻倍的提升。

核心技术暴涨;助力AI能力跃进
GeForce RTX 4090 是基于目前最高端的 AD102 核心打造的,内有 16384 个 CUDA 核心、512 个 Tensor 核心、128 个光追核心、512 个纹理单元、176 个 ROP 单元,比上一代 RTX 3090 核心规模大了一半还多。后续应该还有真旗舰 RTX 4090Ti,解锁全部 GPC 单元。

GeForce RTX 4090 的核心频率是 2230-2520MHz,相比上代同样提升了一半多。显存方面依旧是 384-bit 24GB GDDR6X,但带宽提升到了 1TB / s。TDP 为 450W,达到了 RTX 3090 Ti 的档次,相比于 RTX 3090 增加了整整 100W。猜测是由于核心规模和频率双双暴涨,因此功耗也不得不提高了。
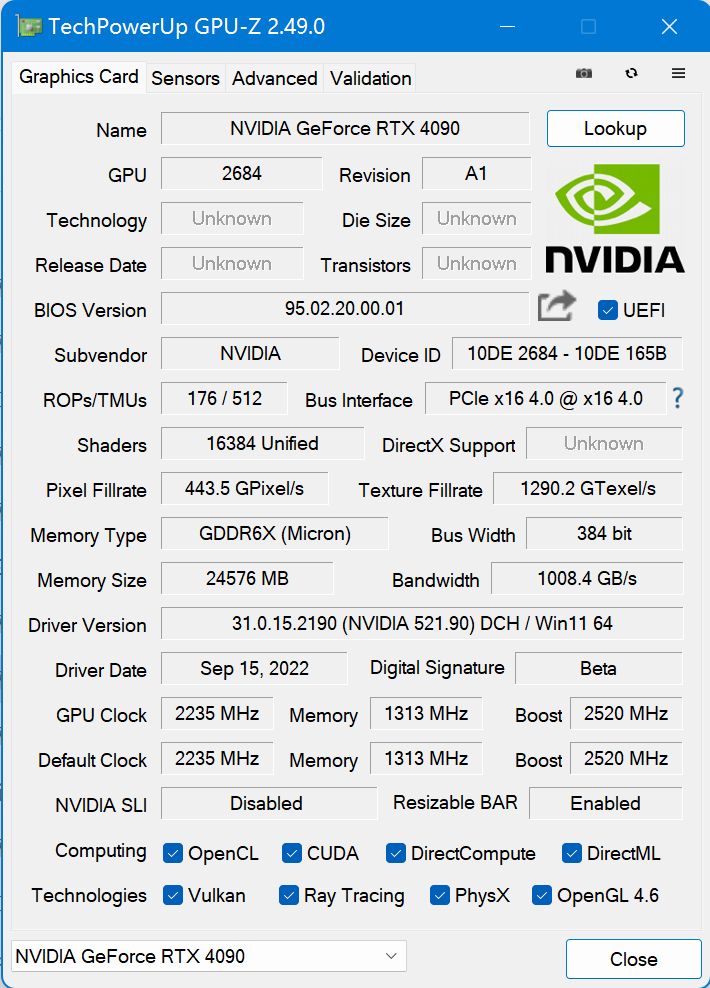
GeForce RTX 4090 的架构也发生了不小的变化,它升级到了最新的 NVIDIA Ada Lovelace 架构。它基于 TSMC 4N NVIDIA 定制工艺打造,因此实现了高达 2 倍的性能功耗比飞跃。流式多处理器具有高达 83 TFLOPS 的着色能力,吞吐量超过上一代产品 2 倍。第三代 RT Cores 的有效光线追踪计算能力达到 191 TFLOPS,是上一代产品 2.8 倍。第四代 Tensor Cores 新增 FP8 引擎,具有高达 1.32 petaflops 的 Tensor 处理性能,超过上一代的 5 倍。
SER 为光线追踪带来最高可达 3 倍的性能提升,整体游戏性能提升可高达 25%。以上这些数据可能比较抽象。反映到具象的功能上,新架构带来了不少的新功能:由于 Ada 光流加速器的引入,使得 DLSS 3 能够预测场景中帧和帧之间的运动变化,实现 AI 插帧,在保持图像质量的同时提高帧率。同时支持双 AV1 编码器的应用,不仅可以将视频导出时间缩短,还能拥有更好的画质。总之就是游戏生产两相宜。
RTX 4090 拥有强大的 Tensor 核心和 FP16/INT8 计算能力,非常适合进行 AI 模型的训练和推理。对于需要进行大量计算和数据处理的 AI 研究者和工程师来说,RTX 4090 是一个理想的工具。ensor Core 可实现混合精度计算,动态调整算力,从而在保持准确性和提供更强安全性的同时提高吞吐量。在应对广泛的 AI 和高性能计算 (HPC) 任务时,新一代 Tensor Core 的速度更胜以往。NVIDIA Tensor Core 可将万亿级参数生成式 AI 模型的训练速度提高 4 倍,将推理性能提升 30 倍,并加速现代 AI 工厂的所有工作负载。

由此可见,4090芯片在AI模型层面的重要性不言而喻了。既然如此,在这小编向大家推荐一款来自UCloud优刻得的一款4090云服务器,相比较于市面上的一些GPU共享算力平台的资源,不仅价格实惠,性价比高,性能强劲 的同时还拥有独立IP、预装主流大模型及环境镜像,支持7X24的小时的售后服务。同时,UCloud还推出了9.9元/天的4090特惠,方便大家体验使用 价格非常香,可以放心上车!
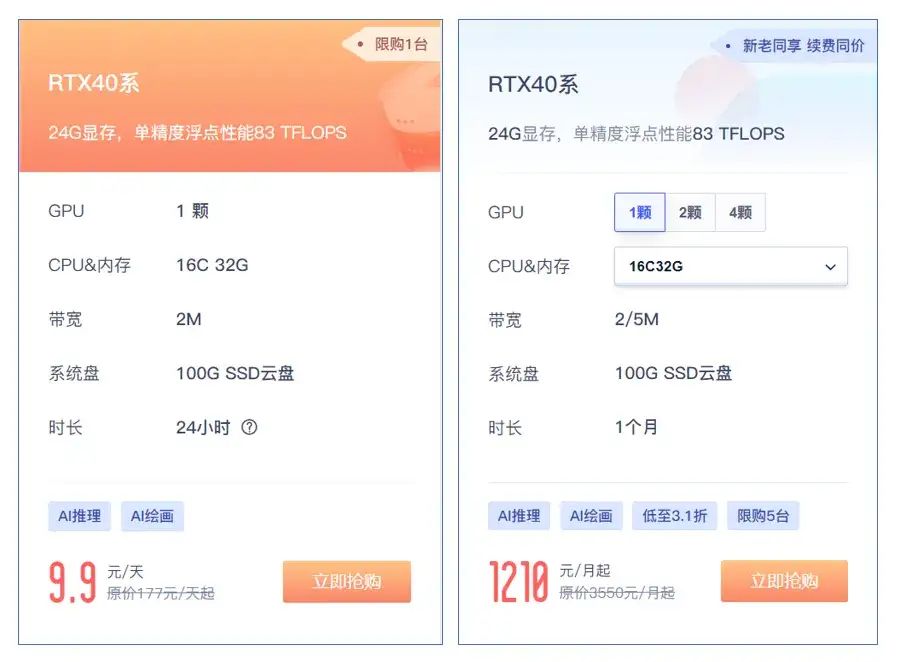
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0709_shemei
原文地址:https://blog.csdn.net/specssss/article/details/140303492
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!