《MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images》阅读笔记
论文地址:https://arxiv.org/pdf/2403.14627
项目地址:https://github.com/donydchen/mvsplat
--------------------------------------------------------------------------------------------------------------------------------
任务:
通过稀疏(即少至两张)图像进行3D场景重建和新视图合成
挑战:
从单张图像重建3D场景本质上是不定式且模糊的,当应用于更一般且较大的场景时,这成为了一个显著的挑战
贡献:
1. 准确定位3D高斯中心:在3D空间中通过平面扫描构建代价体积(cost volume)表示。通过2D网络将构建的多视角代价体积估计出的多视角一致性深度反投影获得3D高斯中。
代价体积:
(1). 存储了所有潜在深度候选的跨视角特征相似性,这些相似性可以为3D表面的定位提供有价值的几何线索(即高相似性更可能表示一个表面点)。
(2). 通过代价体积表示,任务被表述为学习执行特征匹配以识别高斯中心,而不是像以前的工作那样基于图像特征进行数据驱动的3D回归。
(3). 降低了任务的学习难度,使该方法能够在轻量化模型规模和快速速度下实现最先进的性能
2. 与深度一起预测其他高斯属性(协方差、不透明度和球谐函数系数)。这使得可以使用预测的3D高斯分布和可微分的投影操作渲染新的视图图像。
核心过程:
1. 为了准确定位 3D 高斯中心,通过在 3D 空间中通过平面扫描构建成本体积(cost volume)表示。
2. 为了改善几何重建结果,需要缓慢的深度微调和额外的深度正则化损失。

本文提出了 一个基于高斯分布的前馈模型MVSplat,用于新视角合成。开发了一个高效的多视角深度估计模型,能够通过预测的深度图反投影为高斯分布的中心 ,同时在另一个分支中预测其他高斯参数(
)
特征提取:首先,MVSplat 使用 Transformer 从输入的多视图图像中提取特征。
构建视图成本体积:然后,利用平面扫描(plane sweeping)技术,基于每个视图构建成本体积(cost volumes)。这些成本体积反映了不同深度下的视图间特征相似性。
特征融合:Transformer 提取的图像特征与每个视图的成本体积被拼接在一起,作为输入,送入带有跨视图注意力机制的 2D U-Net 中。U-Net 负责对成本体积进行细化,并预测每个视图的深度图。
3D 高斯中心点计算:每个视图的深度图通过反投影(unprojection)映射到3D空间,所有视图的深度信息通过一个简单的确定性联合操作(deterministic union operation)结合起来,得到3D高斯分布的中心。
高斯参数预测:在预测深度图的同时,MVSplat 还会联合预测 3D 高斯分布的其他参数,包括不透明度、协方差和颜色。
新视角渲染:最后,利用光栅化(rasterization)操作,通过预测的 3D 高斯分布对新视角的图像进行渲染。
细节过程:
输入:K 张稀疏视角图像 , 其中图像为
对应的相机投影矩阵 , 其中
,分别为相机内参矩阵
、旋转矩阵
、位移矩阵
.
目标:学习从图像到 3D 高斯参数的映射 ,其中
为网络可学习参数
预测:高斯参数包括位置 、不透明度
、协方差
和颜色
(用球谐函数表示),并且这些参数以像素对齐的方式进行预测。对于具有分辨率
的
张输入图像,总共需要预测
个 3D 高斯分布
为了实现高质量的渲染和重建,精确预测位置 是至关重要的,因为它定义了 3D 高斯分布的中心。
深度模型包括以下几个步骤:多视角特征提取、代价体构建、代价体优化、深度估计和深度优化,具体介绍如下。
多视角特征提取
通过卷积神经网络(CNN)和Transformer架构提取多视角图像特征
输入: 不同视角图片; 输出:每个图片特征
首先,使用一个浅层的类似ResNet的CNN来提取每个视角4倍下采样的图像特征
然后,使用包含自注意力和交叉注意力层的多视角Transformer在不同视角之间交换信息。
最后,通过此操作得到跨视角感知的Transformer特征
代价体构建
通过平面扫描立体视觉方法,在不同深度候选值下建模跨视角特征匹配信息。
输入: 每个图片特征; 输出:代价体
为 K 个输入视角构建 K 个代价体积来预测 K 张深度图
以视角 i 的代价体积构建为例,给定近距离和远距离的深度范围,首先在逆深度域内均匀采样 D 个深度候选值 ,然后利用相机投影矩阵
、
和每个深度候选值
,将视角 j 的特征
变换到视角 i,以获得 D 个变换后的特征。
代价体积优化
由于在无纹理区域代价体积可能存在歧义,提出使用额外的轻量级2D U-Net进一步优化代价体积。
输入:Cat( Transformer特征 和 代价体积
)
输出: 残差 将其加到初始代价体积
上,得到优化后的代价体积
为了在不同视角的代价体积之间交换信息,在U-Net架构的最低分辨率上注入了三层跨视角注意力层。这种设计确保了模型能够接受任意数量的视角输入,因为它对每个视角执行与其他所有视角的交叉注意力计算,这一操作不依赖于视角的数量。
深度估计
使用 softmax 操作来获得每个视角的深度预测。
输入:优化后的代价体
输出:深度预测
首先,在深度维度上对优化后的代价体积 进行归一化
然后,对所有深度候选值 执行加权平均计算,得到最终的深度估计
。
深度优化
引入了一个额外的深度优化步骤,以增强预测深度的质量。
输入:多视角图像、特征和当前的深度预测
输出:每个视角的残差深度
该优化通过一个非常轻量级的 2D U-Net 实现,输入为多视角图像、特征和当前的深度预测,并输出每个视角的残差深度。残差深度随后与当前的深度预测相加,作为最终的深度输出。也在最低分辨率处引入了跨视角注意力层,以便在各个视角之间交换信息。
高斯参数预测
高斯中心 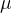
在获得多视角深度预测后,直接通过相机参数将这些深度值反投影到 3D 点云中。
将每个视图的点云转换为对齐的世界坐标系,并将它们直接组合成 3D 高斯的中心。
不透明度 
通过 softmax (优化后的代价体积 ) 操作获得的匹配分布,可以得到匹配置信度,即 softmax 输出的最大值。
这种匹配置信度在物理意义上与不透明度相似(具有更高匹配置信度的点更可能位于表面上),因此使用两个卷积层从匹配置信度输入中预测不透明度。
协方差 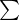 和颜色
和颜色 
这两个参数通过两个卷积层进行预测,这些卷积层的输入是拼接后的图像特征、经过精炼的成本体积以及原始多视图图像。
与其他 3D 高斯表示方法类似,协方差矩阵 由一个缩放矩阵
和一个用四元数表示的旋转矩阵
组成,而颜色
则是从预测的球谐系数中计算得到的。
训练损失
完整模型使用真实 RGB 图像作为监督进行训练。
训练损失作为 ℓ2 损失和 LPIPS 损失的线性组合计算,损失权重分别为 1 和 0.05。
模型预测一组 3D 高斯参数 这些参数随后用于在新视点下渲染图像。
--------------------------------------------------------------------------------------------------------------------------------
平面扫描:
平面扫描(Plane-sweeping)介绍_平面扫描算法-CSDN博客
原文地址:https://blog.csdn.net/programmer_A/article/details/142910202
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!