大语言模型周报

01
最弱环节定律:大型语言模型的交叉能力
图1 图像识别、推理和相应交叉能力的分类可视化。最终的分类描述了图像识别和推理能力,需要使用两种能力来实现。
Meta人工智能团队和伊利诺伊大学香槟分校的研究人员共同探索了大型语言模型在处理需要多种能力结合的复杂任务时的表现。他们提出了“交叉能力”(cross capabilities)的概念,并建立了一个包含1400个经人类标注的提示的基准测试(CrossEval)。研究发现,当前的LLMs在这些交叉任务中的表现受到最弱能力的显著限制,即遵循“最弱环节法则”(Law of the Weakest Link)。
论文链接:https://arxiv.org/pdf/2409.19951
02
多模态 LLM 增强型跨语言跨模态检索
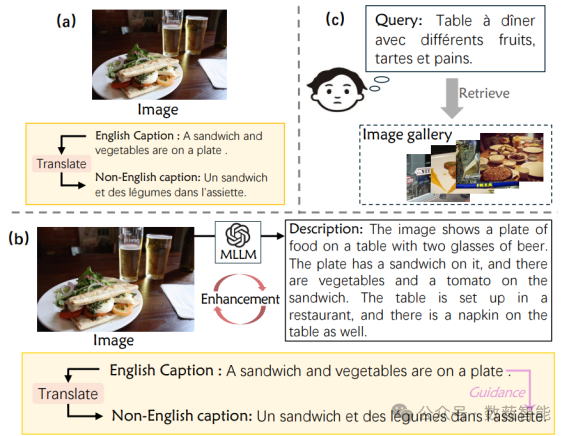
图 2 先前方法与本文提出的CCR方法之间的比较。(a) 以前的方法通常在由图像/视频与英文字幕及其相应的非英文翻译组成的集合上进行训练。(b) 本文方法利用MLLM生成详细的视觉描述,并将其用作内部表示来增强视觉表示。此外,本文利用英语特征作为指导,以提高视觉特征和非英语特征之间的一致性。(c) 在推断过程中,会给出一个非英语查询来检索相关的视觉内容。
西安交通大学国际人工智能研究院与INF Tech有限公司的研究人员提出了一种名为LECCR(Multimodal LLM Enhanced Cross-lingual Cross-modal Retrieval)的新方法,旨在提升跨语言和跨模态检索的性能。该方法利用大型语言模型(MLLM)生成详细的视觉内容描述来增强视觉特征的语义信息,并通过引入软化匹配和英语指导来提高非英语特征的对齐质量。
论文链接:https://arxiv.org/pdf/2409.19961
03
华拓GPT-Vision,将医学视觉知识大规模注入多模态 LLM
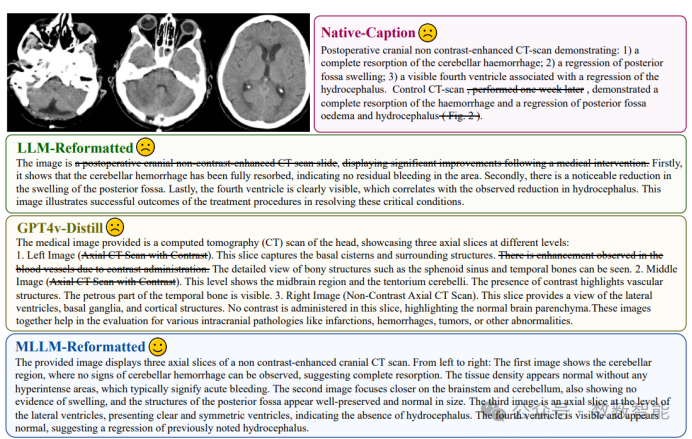
图 3 用各种方法构建图像字幕。本文使用gpt-4作为LLM,gpt-4V作为MLLM。划格文字表示错误的描述或与图像无关的描述。
深圳大数据研究院和香港中文大学(深圳)的研究人员开发了一种名为HuatuoGPT-Vision的多模态大型语言模型(MLLM),旨在将医学视觉知识注入到大规模模型中。该模型通过改进PubMed上的医学图像-文本对,并使用MLLMs(如GPT-4V)进行去噪和重新格式化数据。验证表明,PubMedVision能显著提升当前MLLMs在医学多模态能力方面的性能。
论文链接:https://arxiv.org/pdf/2406.19280
04
Visual Context窗口扩展:长视频理解的新视角
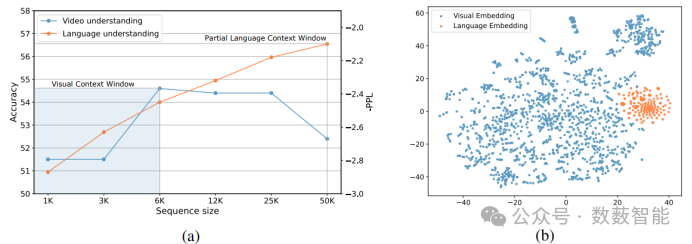
图 4 (a) 的蓝色曲线说明了LongVideoBench(180s-600s)上不同视频序列长度的精度比较(Wu等人,2024)。黄色曲线显示了10个128k校对堆文件的滑动窗口困惑度(S=256),为了比较,我们取了困惑度的负值。使用t-SNE在语言解码器中可视化视觉嵌入(模态投影层的输出)和语言嵌入。视觉嵌入和语言嵌入形成了两个不同的集群。
武汉大学的研究人员提出了一种新方法,通过扩展视觉上下文窗口和采用渐进式池化策略,有效提升了大型多模态模型在长视频理解任务中的表现,减少了内存消耗,并在多个基准测试中取得了优异的成绩。
论文链接:https://arxiv.org/pdf/2409.20018
05
超越分数:基于 RAG 的模块化系统,用于带反馈的自动简答评分
图 5 使用DSPy的模块化ASAS-F-Z和ASAS-F-RAG系统的实施概述
九州大学的研究人员提出了一种基于检索增强生成(RAG)的自动短答案评分系统,旨在解决教育评估中的自动评分和反馈问题。该系统能够在零样本和少样本学习场景下,为学生答案提供准确的评分和详细的反馈。研究结果表明,与基于微调的方法相比,该系统在未见过的问题上评分准确率提高了9%。
论文链接:https://arxiv.org/pdf/2409.20042
06
减轻推荐系统大型语言模型的倾向偏差
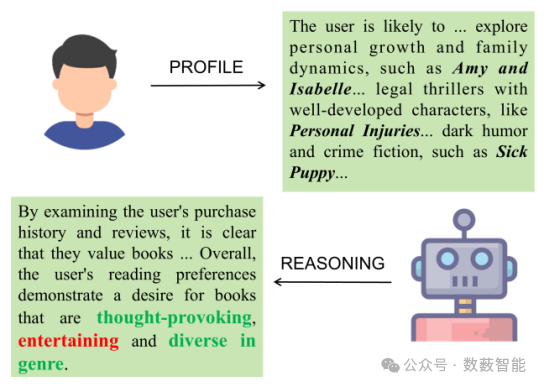
图 6 一个例子说明了在使用LLM生成亚马逊数据集中用户5596的配置文件和推理时引入倾向偏差。
中国矿业大学和南澳大学等单位的研究人员提出了一种名为"Counterfactual LLM Recommendation"(CLLMR)的新框架,旨在减轻大型语言模型(LLMs)在推荐系统中的倾向性偏见。该框架通过引入基于频谱的侧信息编码器,隐式地将历史互动的结构信息嵌入到侧信息表示中,从而避免了维度崩溃的风险。
论文链接:https://arxiv.org/pdf/2409.20052
07
GUNDAM:将大型语言模型与图形理解对齐
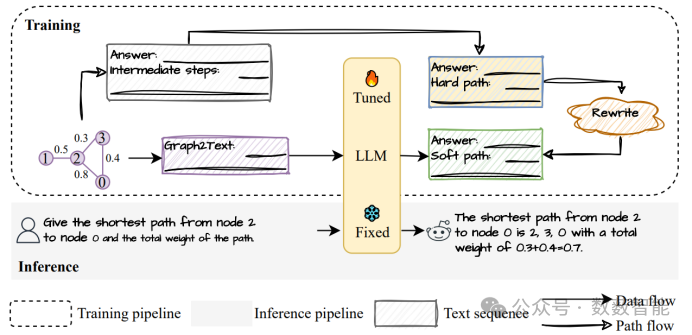
图 7 GUNDAM的框架概述
中国人民大学和中国科学院大学的研究人员提出了一种名为"GUNDAM"的模型,旨在提升大型语言模型(LLMs)理解和处理图结构数据的能力。GUNDAM通过将图结构编码为文本序列,利用图算法生成高质量的图推理数据,并采用对齐调整方法来优化模型的图推理性能。在多个图推理任务上的实验结果表明,GUNDAM不仅超越了现有的最先进模型,还揭示了影响LLMs图推理能力的关键因素。此外,研究还提供了理论分析,阐释了推理路径如何增强LLMs的推理能力。
论文链接:https://arxiv.org/pdf/2409.20053
08
TongGu:用基于知识的大型语言模型掌握古典汉语理解
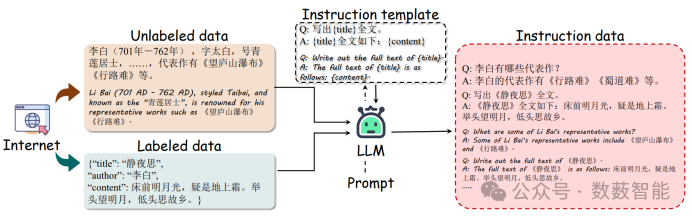
图 8 从标记和未标记文本生成CCU指令数据管道的概述。
华南理工大学和Intsig信息有限公司等单位的研究人员提出了一种名为“TongGu”的大型语言模型,专门针对文言文理解任务。该模型通过构建两阶段指令调整数据集ACCN-INS,提出了一种防止灾难性遗忘的冗余感知调整(RAT)方法,并引入了一种基于知识的检索增强生成(CCU-RAG)技术,以减少幻觉现象。
论文链接:https://arxiv.org/pdf/2407.03937
09
FoodieQA:用于细粒度理解中国饮食文化的多模态数据集

图 9 中国火锅地区食物差异的一个例子。所描绘的汤和餐具在视觉上反映了食材、口味和这些地区的传统:北部的北京,西南部的四川,南部沿海的广东。
哥本哈根大学和滑铁卢大学等单位的研究人员创建了一个名为"FoodieQA"的多模态数据集,旨在通过多图像、单图像和仅文本的多项选择问题,评估对中国文化中食品的细粒度理解。该数据集专注于中国不同地区食品文化的复杂特征,包括14种不同的菜系。
论文链接:https://arxiv.org/abs/2406.11030
10
MultiPragEval:大型语言模型的多语言语用评估
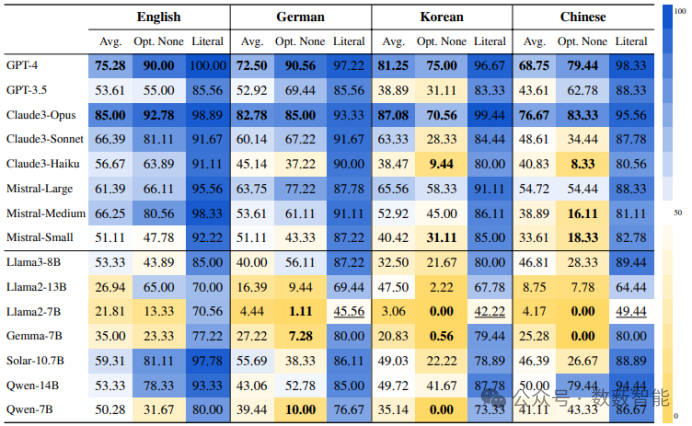
图 10 四种语言的“无正确答案”和字面意思测试的法学硕士分数细分;这个热图使用两种颜色——蓝色表示得分较高,黄色表示得分较低。
首尔大学、成均馆大学等单位的研究人员开发了首个多语言的实用语言评价测试(MultiPragEval),用于评估大型语言模型(LLMs)在英语、德语、韩语和中文方面的语言理解能力。通过分析语言推理,研究提供了对AI系统进行高级语言理解所必需的能力的深刻见解。该测试套件已在GitHub仓库公开提供。
论文链接:https://arxiv.org/pdf/2406.07736
11
VMAD:用于异常检测的视觉增强多模态大型语言模型
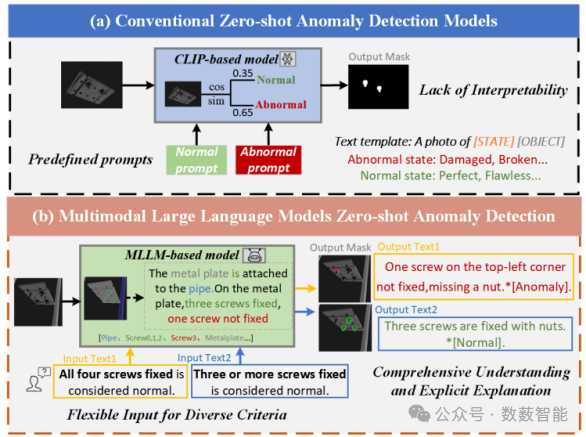
图 11 MTLLM支持多说话者场景中的多样化ASR指令。给定一个多说话者重叠语音输入(a)和一个文本指令提示(b),所提出的MTLLM©预计会自回归地生成相应的目标转录(d)。对于涉及多个说话者的任务,MTLLM遵循顺序输出,按说话者的开始时间转录多个说话者的发言,用""表示“说话者变更”。
中国科学技术大学和东北大学的研究人员提出了一种名为"VMAD"(Visual-enhanced Multimodal Large Language Model for Zero-Shot Anomaly Detection)的新框架,用于提高零样本异常检测(ZSAD)的性能。该框架通过增强多模态大型语言模型(MLLMs)与视觉知识,提高了对异常的识别和定位能力。实验结果表明,VMAD在多个零样本基准测试中的表现优于现有技术。代码和数据集将很快公开提供。
论文链接:https://arxiv.org/pdf/2409.20146
12
GravMAD:用于广义 3D 操作的接地空间值映射引导动作扩散
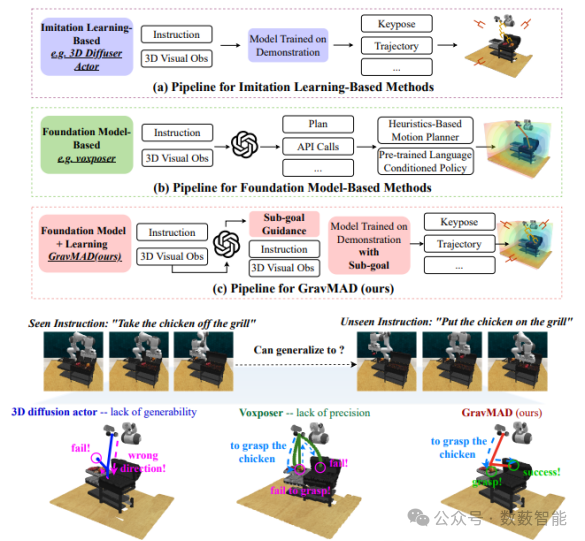
图 12 管道比较。(a) 基于模仿学习的方法学习端到端策略将语言和3D观察映射到动作以进行精确操作。(b) 基于基础模型的方法使用LLM/VLM来处理输入、生成计划并执行预定义的操作用于任务泛化的原语。(c) (d)GravMAD将两者结合起来,使用子目标指导利用基础模型的语言理解和模仿的政策学习学习精确和广义操作。
南京大学和上海大学研究人员研发了一个子目标驱动的、语言条件化的动作扩散框架,它结合了模仿学习和基础模型的优势。对 RLBench 的实证评估表明,GravMAD 的性能明显优于最先进的方法,新任务提高了 28.63%,训练期间遇到的任务提高了 13.36%。这些结果表明 GravMAD 在 3D 操作中具有很强的多任务学习和泛化能力。
论文链接:https://arxiv.org/pdf/2409.20154
13
使用大型语言模型生成迭代数据,用于基于方面的情感分析
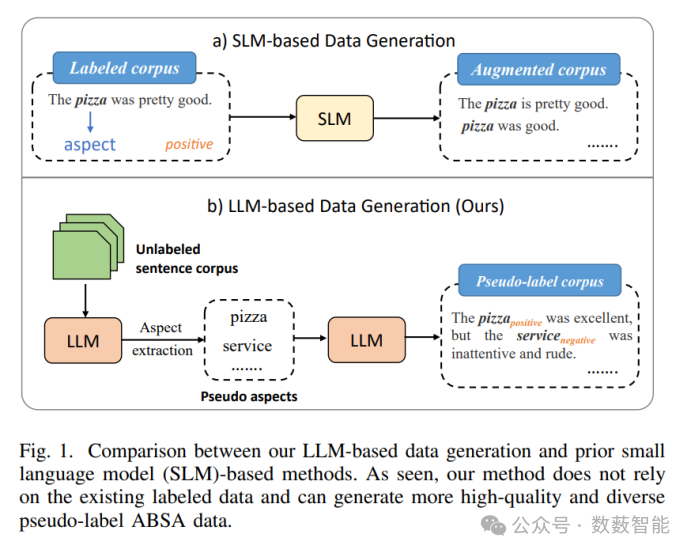
图 13 基于LLM的数据生成与之前的小型数据生成之间的比较基于语言模(SLM)的方法。如图所示,我们的方法不依赖于基于现有的标记数据,可以生成更高质量和多样化的数据伪标签ABSA数据
武汉大学、国家多媒体软件新技术国家重点实验室、人工智能研究所以及湖北省多媒体与网络通信工程重点实验室的研究人员提出了一种名为“迭代数据生成”(IDG)的系统性框架,旨在提升基于方面的文本情感分析(ABSA)的性能。该框架充分利用了大型语言模型(Large Language Models, LLMs)的强大能力,通过迭代方式生成更流畅且多样化的伪标签数据。解决了由于幻觉导致的数据生成意外的问题。IDG在五个基线ABSA模型中带来了一致且显著的性能提升。
论文链接:https://arxiv.org/pdf/2407.00341
14
参考可信解码:大型语言模型的免训练增强范式
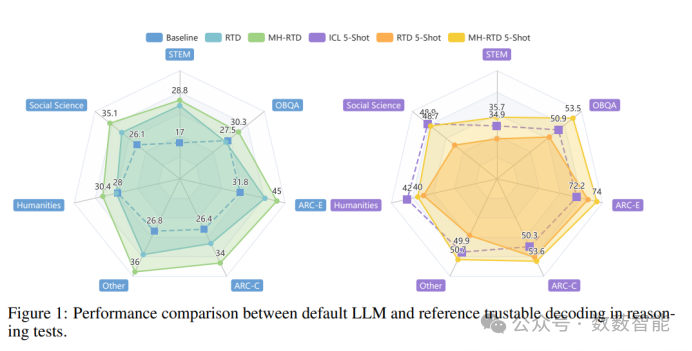
图 14 推理测试中默认LLM和参考可信解码的性能比较
武汉大学、上海交通大学的研究人员提出了一种名为“参考可信解码”(Reference Trustable Decoding, RTD)的新范式,旨在无需训练即可增强大型语言模型(LLMs)在下游任务中的应用。RTD通过从给定的训练样本构建参考数据存储,并根据输入灵活选择适当的参考,优化了LLM的最终词汇分布,从而在保持低推理成本的同时,使模型能够快速适应新任务。
论文链接:https://arxiv.org/abs/2409.08738
15
JobFair:大型语言模型中性别招聘偏见基准测试的框架
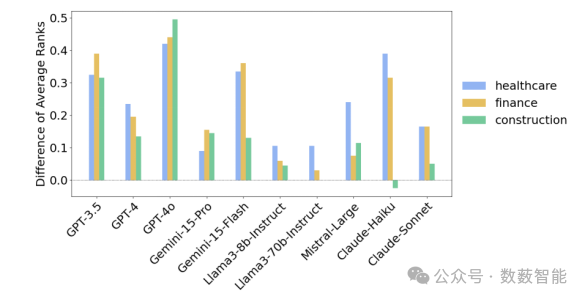
图 15 男性和女性群体之间的排名差距每个LLM和行业。根据计算,更大的差异表明男性的排名低于女性从男性中减去女性的平均排名平均排名。
伦敦大学学院和加州大学伯克利分校等机构的研究人员开发了一个名为JobFair的框架,用于评估大型语言模型(LLMs)在简历评分中的性别招聘偏见。该研究揭示了在对简历进行评分时,存在显著的反向性别招聘偏见和过度去偏见问题。研究团队提出了一个新的基于劳动经济学、法律原则和当前偏见基准测试的批评的构建层次结构:招聘偏见可以分为水平偏见(不同人群之间平均结果的差异)和分布偏见(不同人群之间结果差异的差异)。
论文链接:https://arxiv.org/abs/2406.15484
16
AmbigNLG:解决 NLG 教学中的任务歧义

图 16 AmbigNLG任务的缓解方法概述。我们通过在初始指令中加入额外的指令来解决任务模糊问题,从而细化任务定义,提高生成的输出与用户期望的一致性。
东京梅加贡实验室和Recruit有限公司的研究人员提出AmbigNLG,旨在解决自然语言生成(NLG)任务指令中的任务歧义问题。研究者们引入了一个包含2,500个实例的数据集AmbigSNINLG,并开发了一个歧义分类法,用于对指令歧义进行分类和注释。他们的方法显著提高了文本生成质量,突出了清晰和特定指令在提高LLMs在NLG任务中的性能中的关键作用。
论文链接:https://arxiv.org/pdf/2402.17717
17
基于大语言模型的材料知识图谱在多学科材料科学中的构建与应用
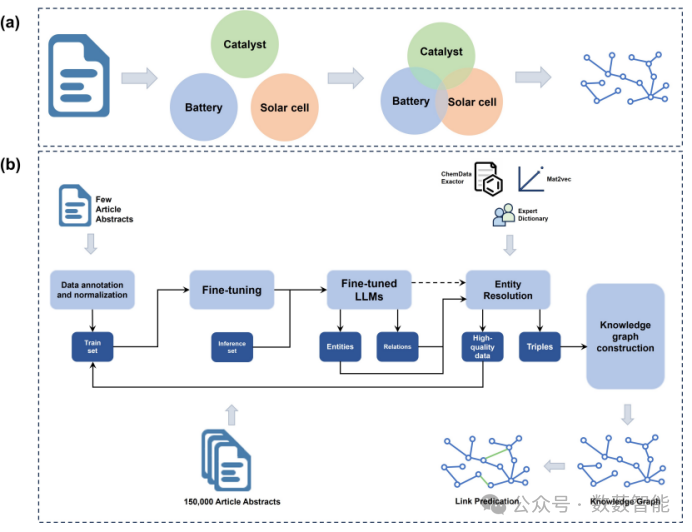
图 17 (a) 工作流程和(b)用于知识图任务的微调LLM的管道。
新南威尔士大学、绿色动力有限公司等单位的研究人员开发了一种功能性材料知识图谱(FMKG),为加速功能性材料的开发提供了强大的催化剂,并为使用全文构建更全面的材料知识图谱奠定了基础。此外,该研究为基于文本挖掘的知识管理系统奠定了基础,不仅适用于复杂的材料系统,也适用于其他专业领域。
论文链接:https://arxiv.org/pdf/2404.03080
18
大型语言模型的标记比对远程基因表达预测
图 18 GTA概述
加州大学洛杉矶分校和雪松-西奈医疗中心的研究人员开发了一种名为遗传序列标记对齐(Genetic sequence Token Alignment, GTA)的新型基因表达预测方法。该方法通过将遗传序列特征与自然语言标记对齐,利用预训练的大型语言模型进行基因表达预测。
论文链接:https://arxiv.org/abs/2410.01858
19
使用生成式人工智能进行因果表示学习:作为处理应用于文本
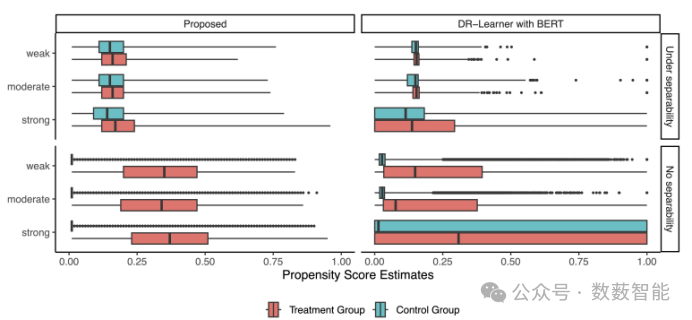
图 19 治疗组(红色)和对照组(蓝色)的估计倾向评分分布。本文展示了在可分性假设(顶部)和无可分性(底部)下,所提出的估计器(左)和具有BERT的DR学习器(右)的结果。在每种情况下,本文根据三种不同的混杂强度呈现结果;虚弱、温和、强壮。对于所提出的方法,在可分离性假设下,估计的倾向得分在不同的混杂场景中分布相似。相比之下,对于具有BERT的DR学习者,在强混杂情景下,分布严重向右倾斜。当违反可分离性假设时,很明显,所提出的方法对对照组的估计倾向得分极小。
哈佛大学的研究人员使用深度生成模型来有效生成处理,并使用其内部表示来估计随后的因果效应。研究表明,了解这种真正的内部表示有助于将感兴趣的处理特征(如特定情感和主题)与可能未知的混杂特征分开,从而产生更准确和高效的估计。
论文链接:https://arxiv.org/abs/2410.00903
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
原文地址:https://blog.csdn.net/2401_85375298/article/details/143002375
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!