MySQL 8.0 新特性之 Clone Plugin
个人感觉,主要还是为 Group Replication 服务。在 Group Replication 中,如果要添加一个新的节点,这个节点差异数据的补齐是通过分布式恢复( Distributed Recovery )来实现的。
在 MySQL 8.0.17 之前,只支持一种恢复方式,即 Binlog。如果新节点需要的 Binlog 在集群中不存在,这个时候,就只能借助于备份工具先做个全量数据的备份恢复,然后再通过分布式恢复同步增量数据。
这种方式,虽然也能达到添加节点的目的,但总归还是要借助外部工具,相对来说,有一定的使用门槛和工作量。
有了 Clone Plugin,只用一条命令,我们就能很方便地添加一个新的节点,无论是在 Group Replication 还是普通的主从环境中。
本章主要包括以下几部分:
-
Clone Plugin的安装
-
Clone Plugin的使用
-
如何查看克隆操作的进度
-
如何基于克隆数据搭建从库
-
Clone Plugin的实现细节
-
Clone Plugin的要求和限制
-
Clone Plugin与XtraBackup的异同
-
Clone Plugin的参数解析
一、Clone Plugin的安装
Clone Plugin 可通过以下两种方式安装:
(1)配置文件中指定:
[mysqld]
plugin-load-add=mysql_clone.so
(2)动态加载:
mysql> install plugin clone soname 'mysql_clone.so';
执行 show plugins 查看插件是否安装成功。
mysql> show plugins;
+---------------------------------+----------+--------------------+----------------+---------+
| Name | Status | Type | Library | License |
+---------------------------------+----------+--------------------+----------------+---------+
...
| clone | ACTIVE | CLONE | mysql_clone.so | GPL |
...
Status 为 ACTIVE 代表插件加载成功。
二、Clone Plugin的使用
Clone Plugin 支持两种克隆方式:本地克隆和远程克隆。
接下来我们看看本地克隆和远程克隆的使用方法。
本地克隆
本地克隆的原理图如下所示,它可将本地 MySQL 实例中的数据拷贝到本地服务器的一个目录中。本地克隆只能在实例本地发起。

本地克隆命令的语法如下:
CLONE LOCAL DATA DIRECTORY [=] 'clone_dir';
这里的 clone_dir 是克隆目录。
下面我们看下具体的使用步骤。
(1)创建克隆用户:
mysql> create user 'clone_user'@'%' identified by 'clone_pass';
mysql> grant backup_admin on *.* to 'clone_user'@'%';
这里的 backup_admin 是克隆操作必需权限,它允许用户执行 LOCK INSTANCE FOR BACKUP 命令。
(2)创建克隆目录:
# mkdir -p /data/backup
# chown -R mysql.mysql /data/backup/
(3)执行本地克隆操作:
# mysql -uclone_user -pclone_pass
mysql> clone local data directory='/data/backup/3307';这里的 /data/backup/3307 是克隆目录,它需满足以下几点要求:
-
克隆目录必须是路径。
-
/data/backup 必须存在,且 MySQL 对其有可写权限。
-
后一级目录 3307 不能存在。
(4)查看克隆目录的内容:
# ll /data/backup/3307
total 200644
drwxr-x--- 2 mysql mysql 89 Oct 23 22:09 #clone
-rw-r----- 1 mysql mysql 4049 Oct 23 22:09 ib_buffer_pool
-rw-r----- 1 mysql mysql 12582912 Oct 23 22:09 ibdata1
-rw-r----- 1 mysql mysql 50331648 Oct 23 22:09 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 Oct 23 22:09 ib_logfile1
drwxr-x--- 2 mysql mysql 6 Oct 23 22:09 mysql
-rw-r----- 1 mysql mysql 25165824 Oct 23 22:09 mysql.ibd
drwxr-x--- 2 mysql mysql 20 Oct 23 22:09 slowtech
drwxr-x--- 2 mysql mysql 28 Oct 23 22:09 sys
-rw-r----- 1 mysql mysql 33554432 Oct 23 22:09 undo_001
-rw-r----- 1 mysql mysql 16777216 Oct 23 22:09 undo_002
(5)可直接基于备份集启动实例:
# /usr/local/mysql/bin/mysqld --no-defaults --datadir=/data/backup/3307 --user mysql --port 3307 &
相对于 Xtrabackup ,Clone Plugin 无需 Prepare 阶段。
远程克隆
远程克隆的原理图如下所示,涉及两个实例。其中,被克隆的实例是 Donor ,接受克隆数据的实例是 Recipient 。克隆命令需在 Recipient 上发起。
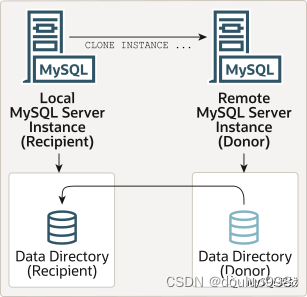
远程克隆命令的语法如下:
CLONE INSTANCE FROM 'user'@'host':port
IDENTIFIED BY 'password'
[DATA DIRECTORY [=] 'clone_dir']
[REQUIRE [NO] SSL];
这里面,
-
host,port:被克隆实例(Donor)的 IP 和端口。
-
user,password:Donor 上的克隆用户和密码,需要 backup_admin 权限。
-
DATA DIRECTORY:备份目录。不指定的话,则默认克隆到 Recipient 的数据目录下。
-
REQUIRE [NO] SSL:是否开启 SSL 通信。
下面我们看看具体的使用步骤:
(1)在 Donor 实例上创建克隆用户,加载 Clone Plugin :
mysql> create user 'donor_user'@'%' identified by 'donor_pass';
mysql> grant backup_admin on *.* to 'donor_user'@'%';
mysql> install plugin clone soname 'mysql_clone.so';
(2)在 Recipient 实例上创建克隆用户,加载 Clone Plugin :
mysql> create user 'recipient_user'@'%' identified by 'recipient_pass';
mysql> grant clone_admin on *.* to 'recipient_user'@'%';
mysql> install plugin clone soname 'mysql_clone.so';
这里的 clone_admin ,隐式含有 backup_admin 和 shutdown(重启实例)权限。
(3)在 Recipient 实例上设置 Donor 白名单,Recipient 只能克隆白名单中的实例:
mysql> set global clone_valid_donor_list = '192.168.244.10:3306';
设置该参数需要 SYSTEM_VARIABLES_ADMIN 权限。
(4)在 Recipient 上发起克隆命令:
# mysql -urecipient_user -precipient_pass
mysql> clone instance from 'donor_user'@'192.168.244.10':3306 identified by 'donor_pass';
远程克隆会依次执行以下操作:
-
获取备份锁 (Backup Lock)。备份锁和 DDL 互斥。注意,获取的不仅仅的是 Recipient 上的备份锁,Donor 上的同样也要获取。
-
Drop 用户表空间。注意,Drop 的只是用户表空间,不是数据目录,也不包括 ib_buffer_pool、ibdata 等系统文件。
-
从 Donor 实例拷贝数据。对于用户表空间,会直接拷贝。对于系统文件 ,则会重命名为 xxx.#clone,不会直接替代原文件。如,
# ll /data/mysql/3306/data/ ... -rw-r----- 1 mysql mysql 4049 Oct 24 09:11 ib_buffer_pool -rw-r----- 1 mysql mysql 4049 Oct 24 10:54 ib_buffer_pool.#clone -rw-r----- 1 mysql mysql 12582912 Oct 24 10:55 ibdata1 -rw-r----- 1 mysql mysql 12582912 Oct 24 10:55 ibdata1.#clone ... -rw-r----- 1 mysql mysql 25165824 Oct 24 10:55 mysql.ibd -rw-r----- 1 mysql mysql Oct 24 10:54 mysql.ibd.#clone ... -
重启实例。在启动的过程中,会用 xxx.#clone 替换掉原来的系统文件。
三、如何查看克隆操作的进度
查看克隆操作的进度,主要依托于 performance_schema 中的两张表:clone_status 和 clone_progress 。
下面我们具体看看这两张表的作用及各字段的含义。
首先看看 clone_status 表,该表记录了克隆操作的状态信息。
mysql> select * from performance_schema.clone_status\G
*************************** 1. row ***************************
ID: 1
PID:
STATE: Completed
BEGIN_TIME: 2021-10-24 10:54:35.565
END_TIME: 2021-10-24 10:57:02.382
SOURCE: 192.168.244.10:3306
DESTINATION: LOCAL INSTANCE
ERROR_NO:
ERROR_MESSAGE:
BINLOG_FILE: mysql-bin.000004
BINLOG_POSITION: 139952824
GTID_EXECUTED: 453a5124-020e-11ec-8719-000c29f66609:1-17674
1 row in set (0.49 sec)
其中,
-
PID:Processlist ID。对应 show processlist 中的 Id ,如果要终止当前的克隆操作,可执行 KILL QUERY processlist_id 。
-
STATE:克隆操作的状态,包括:Not Started(克隆尚未开始),In Progress(克隆中),Completed(克隆成功),Failed(克隆失败)。如果是 Failed 状态,ERROR_MESSAGE 会给出具体的报错信息。
-
BEGIN_TIME,END_TIME:克隆操作开始、结束时间。
-
SOURCE:Donor 实例的地址。
-
DESTINATION:克隆目录。LOCAL INSTANCE 代表当前实例的数据目录。
-
GTID_EXECUTED,BINLOG_FILE(BINLOG_POSITION):克隆操作对应的一致性位置点信息。可利用这些信息搭建从库。
接下来看看 clone_progress 表,该表记录了克隆操作的进度信息。
mysql> select * from performance_schema.clone_progress;
+------+-----------+-----------+----------------------------+----------------------------+---------+-----------+-----------+-----------+------------+---------------+
| ID | STAGE | STATE | BEGIN_TIME | END_TIME | THREADS | ESTIMATE | DATA | NETWORK | DATA_SPEED | NETWORK_SPEED |
+------+-----------+-----------+----------------------------+----------------------------+---------+-----------+-----------+-----------+------------+---------------+
| 1 | DROP DATA | Completed | 2021-10-24 10:54:48.395548 | 2021-10-24 10:54:58.352278 | 1 | | | | | |
| 1 | FILE COPY | Completed | 2021-10-24 10:54:58.352527 | 2021-10-24 10:55:35.908919 | 2 | 616681425 | 616681425 | 616722587 | | |
| 1 | PAGE COPY | Completed | 2021-10-24 10:55:35.958036 | 2021-10-24 10:55:36.670272 | 2 | 7077888 | 7077888 | 7102277 | | |
| 1 | REDO COPY | Completed | 2021-10-24 10:55:36.671544 | 2021-10-24 10:55:37.160154 | 2 | 4372992 | 4372992 | 4373841 | | |
| 1 | FILE SYNC | Completed | 2021-10-24 10:55:37.160412 | 2021-10-24 10:55:39.724808 | 2 | | | | | |
| 1 | RESTART | Completed | 2021-10-24 10:55:39.724808 | 2021-10-24 10:56:55.207049 | | | | | | |
| 1 | RECOVERY | Completed | 2021-10-24 10:56:55.207049 | 2021-10-24 10:57:02.382057 | | | | | | |
+------+-----------+-----------+----------------------------+----------------------------+---------+-----------+-----------+-----------+------------+---------------+
7 rows in set (.00 sec)
其中,
-
STAGE:一个克隆操作需经过 DROP DATA,FILE COPY,PAGE COPY,REDO COPY,FILE SYNC,RESTART,RECOVERY 这 7 个阶段。当前阶段结束了才会开始下个阶段。
-
STATE:当前阶段的状态,包括:Not Started,In Progress,Completed。
-
BEGIN_TIME,END_TIME:当前阶段的开始时间和结束时间。
-
THREADS:当前阶段使用的并发线程数。
-
ESTIMATE:预估的数据量。
-
DATA:已经拷贝的数据量。
-
NETWORK:通过网络传输的数据量。如果是本地克隆,该列的值为 0。
-
DATA_SPEED,NETWORK_SPEED:当前数据拷贝速率和网络传输速率。注意,是当前值。
四、如何基于克隆数据搭建从库
这里,区分两种场景:GTID 复制和基于位置点的复制。
GTID复制
对于 GTID 复制,无需关心具体的位置点信息,直接设置 MASTER_AUTO_POSITION = 1 即可。具体命令如下:
mysql> CHANGE MASTER TO MASTER_HOST = 'master_host_name', MASTER_PORT = master_port_num,
...
MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;
在 MySQL 5.6,5.7中,通过 Xtrabackup 搭建从库,在建立复制之前,必须执行 SET GLOBAL GTID_PURGED 操作。注意,在 MySQL 8.0 中不要执行。
在 Clone Plugin 中则无需执行。通过克隆数据启动的实例,GTID_PURGED 和 GTID_EXECUTED 默认已初始正确。
基于位置点的复制
具体命令如下:
mysql> SELECT BINLOG_FILE, BINLOG_POSITION FROM performance_schema.clone_status;
mysql> CHANGE MASTER TO MASTER_HOST = 'master_host_name', MASTER_PORT = master_port_num,
...
MASTER_LOG_FILE = 'master_log_name',
MASTER_LOG_POS = master_log_pos;
mysql> START SLAVE;
其中,master_host_name,master_port_num 是 Donor 实例的 IP 和端口。
master_log_name,master_log_pos 分别取自 performance_schema.clone_status 中的 BINLOG_FILE 和 BINLOG_POSITION 。
五、Clone Plugin的实现细节
克隆操作可细分为以下 5 个阶段:
[INIT] ---> [FILE COPY] ---> [PAGE COPY] ---> [REDO COPY] -> [Done]
下面我们看看各个阶段的具体作用:
-
INIT:初始化一个克隆对象。
-
FILE COPY:拷贝数据文件。
在拷贝之前,会将当前 CHECKPOINT 的 LSN 记为 CLONE START LSN ,同时启动 Page Tracking 。
Page Tracking 会跟踪 CLONE START LSN 之后发生修改的页,记录这些页的 tablespace ID 和 page ID 。数据文件拷贝结束后,会将当前 CHECKPOINT 的 LSN 记为 CLONE FILE END LSN 。
-
PAGE COPY:拷贝 Page Tracking 中记录的页。在拷贝之前,会基于 tablespace ID 和 page ID 对这些页进行排序,避免拷贝过程中的随机读写。同时,开启 Redo Archiving 。
Redo Archiving 会在后台开启一个归档线程将 Redo log 的内容按 Chunk 拷贝到归档文件中。通常来说,归档线程的拷贝速度会快于Redo 日志的生成速度。即使慢于,在写入新的 Redo 日志时,也会等待归档线程完成拷贝,不会覆盖还未拷贝的 Redo 日志。
Page Tracking 中的页拷贝完毕后,会获取实例的一致性位置点信息,同时将此时的 LSN 记为 CLONE LSN 。
-
REDO COPY:拷贝归档文件中 CLONE FILE END LSN 与 CLONE LSN 之间的 Redo 日志。
-
Done:调用 snapshot_end() 销毁克隆对象。
六、Clone Plugin的要求和限制
在使用 Clone Plugin 时,注意以下限制:
-
克隆期间,会阻塞 DDL 。同样,DDL 也会阻塞克隆命令的执行。不过从 MySQL 8.0.27 开始,克隆命令不会阻塞 Donor 上的 DDL 。
-
Clone Plugin 不会拷贝 Donor 的配置参数。
-
Clone Plugin 不会拷贝 Donor 的 Binlog。
-
Clone Plugin 只会拷贝 InnoDB 表的数据,对于其它存储引擎的表,只会拷贝表结构。
-
Donor 实例中如果有表通过 DATA DIRECTORY 子句设置了路径,在进行本地克隆时,会提示文件已存在。在进行远程克隆时,路径必须存在且有可写权限。
-
不允许通过 MySQL Router 连接 Donor 实例。
-
执行 CLONE INSTANCE 操作时,指定的 Donor 端口不能为 X Protocol 端口。
除此之外,在进行远程克隆时,还有如下要求:
-
MySQL 版本(包括小版本)必须一致。
-
主机的操作系统和位数(32 位,64 位)必须一致。两者可基于参数 version_compile_os,version_compile_machine 获取。
-
Recipient 必须有足够的磁盘空间存储克隆数据。
-
字符集相关参数必须一致,具体包括:character_set_server(字符集),collation_server(校验集)和 character_set_filesystem。
-
参数 innodb_page_size 必须一致。
-
无论是 Donor ,还是 Recipient ,同一时间,只能执行一个克隆操作。
-
Recipient 需要重启,所以其必须通过 mysqld_safe 或 systemd 等进程管理工具进行管理,否则的话,实例关闭后,需手动拉起。
七、Clone Plugin与XtraBackup的异同
下面看看 Clone Plugin 和 XtraBackup 的异同点:
-
在实现上,两者都有 FILE COPY 和 REDO COPY 阶段,但 Clone Plugin 比 XtraBackup 多了一个 PAGE COPY 阶段。由此带来的好处是,Clone Plugin 的恢复速度比 XtraBackup 快。
-
XtraBackup 没有 Redo Archiving 特性,有可能出现未拷贝的 Redo 日志被覆盖的情况。
-
GTID 下建立复制, Clone Plugin 无需额外执行 SET GLOBAL GTID_PURGED 操作。
八、Clone Plugin的参数解析
clone_autotune_concurrency
是否自动调节克隆过程中并发线程数的数量,默认为 ON ,此时,大线程数由参数 clone_max_concurrency 控制。若设置为 OFF ,并发线程数将是固定的,等于 clone_max_concurrency 。后者的默认值为 16 。
clone_block_ddl
克隆过程中是否对 Donor 实例加备份锁。如果加了,则会阻塞 DDL。默认为 OFF,不加。该参数是 MySQL 8.0.27 引入的。
clone_delay_after_data_drop
Drop 完用户表空间,等待多久才执行数据拷贝操作。引入该参数的初衷是某些文件系统(如 VxFS)是异步释放空间的。如果 Drop 完用户表空间,就马上执行数据拷贝操作,有可能会因为空间不足而导致克隆失败。该参数是 MySQL 8.0.29 引入的,默认为 0,不等待。
clone_buffer_size
本地克隆时,中转缓冲区的大小,默认 4M 。缓冲区越大,备份速度越快,相应地,对磁盘 IO 的压力也越大。
clone_ddl_timeout
克隆操作需要获取备份锁。在执行 CLONE 命令时,如果有 DDL 正在执行,则 CLONE 命令会被阻塞,等待获取备份锁(Waiting for backup lock)。等待的大时长由 Recipient 实例上的 clone_ddl_timeout 决定,该参数默认为 300s。如果在这个时间内还没获取到备份锁,CLONE 命令会失败,且提示 ERROR 3862 (HY000): Clone Donor Error: 1205 : Lock wait timeout exceeded; try restarting transaction.
需要注意的是,在执行 DDL 时,如果有 CLONE 命令在执行,DDL 同样也会因为备份锁而阻塞,只不过,DDL 操作的等待时长由lock_wait_timeout 决定,该参数默认为 31536000s,即 365 天。
clone_donor_timeout_after_network_failure
远程克隆时,如果出现了网络错误,克隆操作不会马上终止,而是会等待一段时间。如果在这个时间内,网络恢复了,操作会继续进行。在 MySQL 8.0.24 之前,等待时间是固定的 5 min。从 MySQL 8.0.24 开始,可通过 clone_donor_timeout_after_network_failure 设置这个时间,默认是 5 min。
clone_enable_compression
远程克隆传输数据时,是否开启压缩。默认为 OFF 。开启压缩能节省网络带宽,但相应地,会增加 CPU 消耗。
clone_max_data_bandwidth
远程克隆时,可允许的大数据拷贝速率,单位 MB/s 。默认为 0,不限制。如果 Donor 的磁盘 IO 存在瓶颈,可通过该参数来限速。
注意,这里限制的只是单个线程的拷贝速率。如果是多个线程并行拷贝,实际大拷贝速率 = clone_max_data_bandwidth * 线程数。
clone_max_network_bandwidth
远程克隆时,可允许的大网络传输速率,单位 MiB/s 。默认为 0,不限制。如果网络带宽存在瓶颈,可通过该参数来限速。
clone_valid_donor_list
在 Recipient 上设置 Donor 白名单,Recipient 只能克隆白名单中指定的实例。在执行克隆操作之前,必须设置该参数。
clone_ssl_ca,clone_ssl_cert,clone_ssl_key
SSL 相关。
原文地址:https://blog.csdn.net/douluo998/article/details/137940623
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!