【Go】深入理解 Go map:赋值和扩容迁移 ①
文章目录
map底层实现
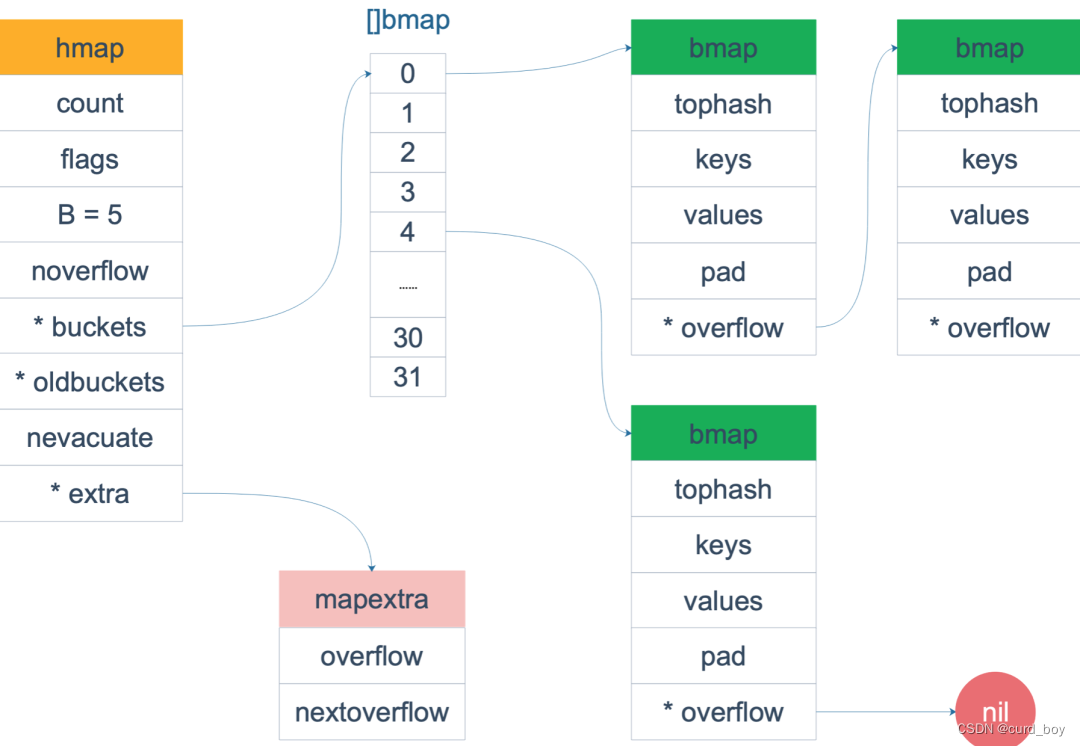
熟悉 map 结构体的读者应该知道,hmap 由很多 bmap(bucket) 构成,每个 bmap 都保存了 8 个 key/value 对:
hmap
有时落在同一个 bmap 中的 key/value 太多了,超过了 8 个,就会由溢出 bmap 来承接,即 overflow bmap(后面我们叫它 bucket)。溢出的 bucket 和原来的 bucket 形成一个“拉链”。
对于这些 overflow 的 bucket,在 hmap 结构体和 bmap 结构体里分别有一个 extra.overflow 和 overflow 字段指向它们。
hmap
// A header for a Go map.
type hmap struct {
count int // map内的元素个数,调用 len(map) 时,直接返回此值
flags uint8 // 标志位,例如表示map正在被写入或者被遍历
B uint8 // buckets 的对数 log_2,即含有 2^B 个buckets。这样的好处是方便用位操作实现取模
noverflow uint16 // 溢出桶的近似数
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 【指向 buckets数组(连续内存空间),数组的类型为[]bmap,大小为 2^B】
oldbuckets unsafe.Pointer // 扩容的时候,buckets 长度会是 oldbuckets 的两倍
nevacuate uintptr // 指示扩容进度,小于此地址的 buckets 迁移完成
extra *mapextra // optional fields
}

bmap
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。
hint 大于 8 又会怎么样?答案很明显,性能问题,其时间复杂度改变(也就是执行效率出现问题)
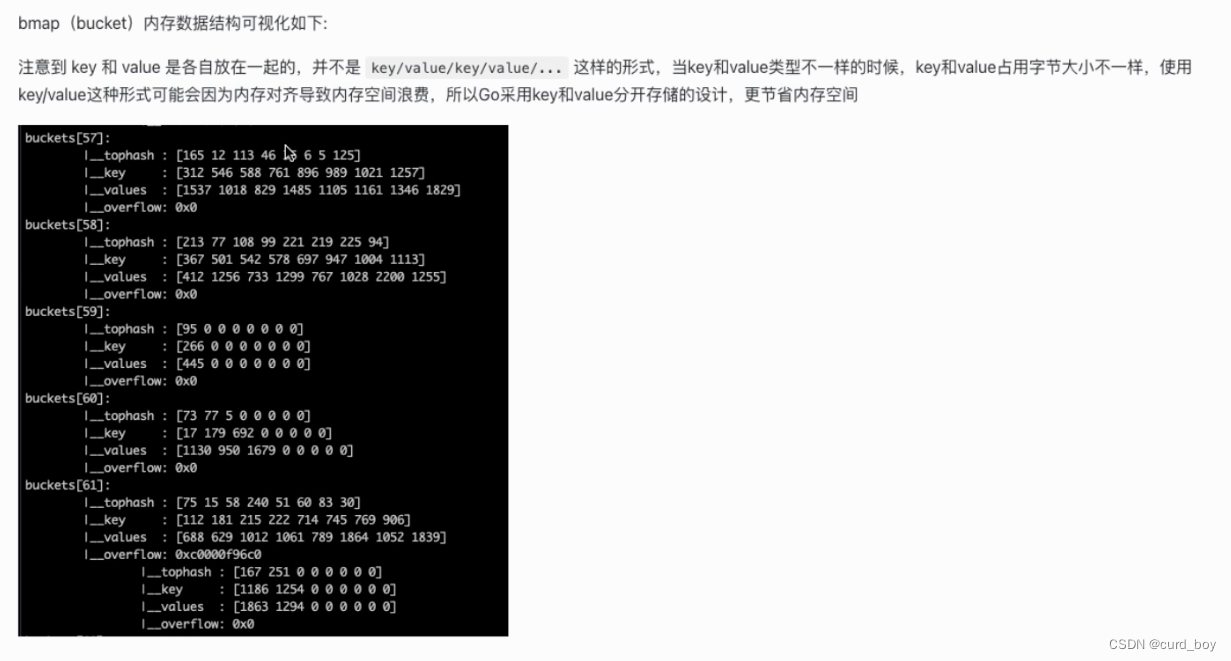
注意:在哈希桶中,键值之间并不是相邻排列的,而是键放在一起,值放在一起,来减少因为键值类型不同而产生的不必要的内存对齐
如果按照 key/value/key/value/… 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 key/key/…/value/value/…,则只需要在最后添加 padding。
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8 // 【bucketCnt在源码中被const为8, 每个bmap结构最多存放8组键值对】
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
//
}


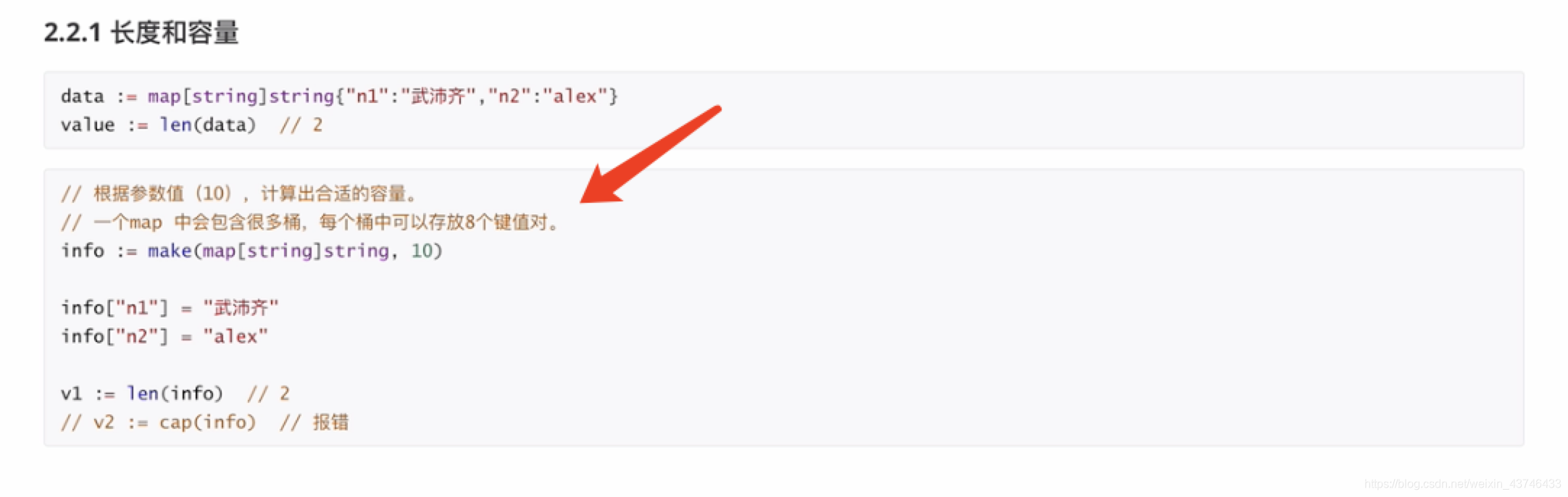
长度与容量
map hash冲突了怎么办?
Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突。
-
哈希函数
哈希函数,又称散列算法、散列函数。主要作用是通过特定算法将数据根据一定规则组合重新生成得到一个散列值
而在哈希表中,其生成的散列值常用于寻找其键映射到哪一个桶上。而一个好的哈希函数,应当尽量少的出现哈希冲突,以此保证操作哈希表的时间复杂度(但是哈希冲突在目前来讲,是无法避免的。我们需要 “解决” 它)
-
链地址法
在哈希操作中,相当核心的一个处理动作就是 “哈希冲突” 的解决。而在 Go map 中采用的就是 "链地址法 " 去解决哈希冲突,又称 “拉链法”。其主要做法是数组 + 链表的数据结构,其溢出节点的存储内存都是动态申请的,因此相对更灵活。而每一个元素都是一个链表。
map扩容
随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能
触发扩容时机
在特定条件的情况下且当前没有正在进行扩容动作(以判断 hmap.oldbuckets != nil 为基准)。哈希表在赋值、删除的动作下会触发扩容行为,条件如下:
- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
// 如果我们达到了最大负载因子,或者我们有太多的溢出桶,
// 并且我们还没有处于增长中,那么开始增长。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // 增长表格会使所有东西都失效,所以重新尝试
}
// growing 报告 h 是否正在扩容。扩容可能是到相同的大小或更大。
// 通过判断oldbuckets是否为nil来判断是否扩容完成
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
第一阶段:确定扩容容量规则
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
- 若不是负载因子 load factor 超过当前界限,也就是属于溢出桶 overflow buckets 过多的情况。因此本次扩容规则将是 sameSizeGrow,即是不改变大小的扩容动作。
bigger := uint8(1)
...
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
- 若是负载因子 load factor 达到当前界限,将会动态扩容当前大小的两倍作为其新容量大小
第二阶段:初始化、交换新旧 桶/溢出桶
主要是针对扩容的相关数据前置处理,涉及 buckets/oldbuckets、overflow/oldoverflow 之类与存储相关的字段
...
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
...
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
...
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
...
h.extra.nextOverflow = nextOverflow
}
这里注意到这段代码: newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)。第一反应是扩容的时候就马上申请并初始化内存了吗?假设涉及大量的内存分配,那挺耗费性能的…
然而并不,内部只会先进行预分配,当使用的时候才会真正的去初始化
第三阶段:扩容
在源码中,发现第三阶段的流转并没有显式展示。这是因为流转由底层去做控制了。但通过分析代码和注释,可得知由第三阶段涉及 growWork 和 evacuate 方法。如下:
func growWork(t *maptype, h *hmap, bucket uintptr) {
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
在该方法中,主要是两个 evacuate 函数的调用。他们在调用上又分别有什么区别呢?如下:
- evacuate(t, h, bucket&h.oldbucketmask()): 将 oldbucket 中的元素迁移 rehash 到扩容后的新 bucket
- evacuate(t, h, h.nevacuate): 如果当前正在进行扩容,则再进行多一次迁移
另外,在执行扩容动作的时候,可以发现都是以 bucket/oldbucket 为单位的,而不是传统的 buckets/oldbuckets。再结合代码分析,可得知在 Go map 中扩容是采取增量扩容的方式,并非一步到位
扩容小结
通过前面三个阶段的分析,可以得知扩容的大致过程。我们阶段性总结一下。主要如下:
- 根据需扩容的原因不同(overLoadFactor/tooManyOverflowBuckets),分为两类容量规则方向,为等量扩容(不改变原有大小)或双倍扩容
- 新申请的扩容空间(newbuckets/newoverflow)都是预分配,等真正使用的时候才会初始化
- 扩容完毕后(预分配),不会马上就进行迁移。而是采取增量扩容的方式,当有访问到具体 bukcet 时,才会逐渐的进行迁移(将 oldbucket 迁移到 bucket)
为什么map扩容选择增量(渐进式扩容)?
如果是全量扩容的话,那问题就来了。假设当前 hmap 的容量比较大,直接全量扩容的话,就会导致扩容要花费大量的时间和内存,导致系统卡顿,最直观的表现就是慢。显然,不能这么做
而增量扩容,就可以解决这个问题。它通过每一次的 map 操作行为去分摊总的一次性动作。因此有了 buckets/oldbuckets 的设计,它是逐步完成的,并且会在扩容完毕后才进行清空
原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。只有在插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil。
迁移是逐步进行的。那如果在途中又要扩容了,怎么办?
again:
bucket := hash & bucketMask(h.B)
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
在这里注意到 goto again 语句,结合上下文可得若正在进行扩容,就会不断地进行迁移。待迁移完毕后才会开始进行下一次的扩容动作
map翻倍扩容原理


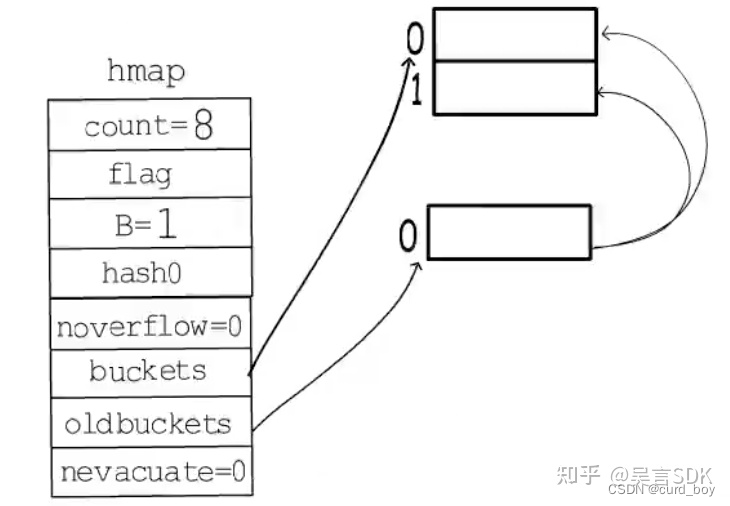
count/(2^B) > 6.5:当负载因子超过6.5时就会触发翻倍扩容。
如下图,原来 B = 0,只有一个桶,装满后触发翻倍扩容,B = 1,buckets 指向两个新桶,oldbuckets 指向旧桶,nevacuate 表示接下来要迁移编号为 0 的旧桶。旧桶的键值对会渐进式分流到两个新桶中。直到旧桶中的键值对全部搬迁完毕后,删除oldbuckets。
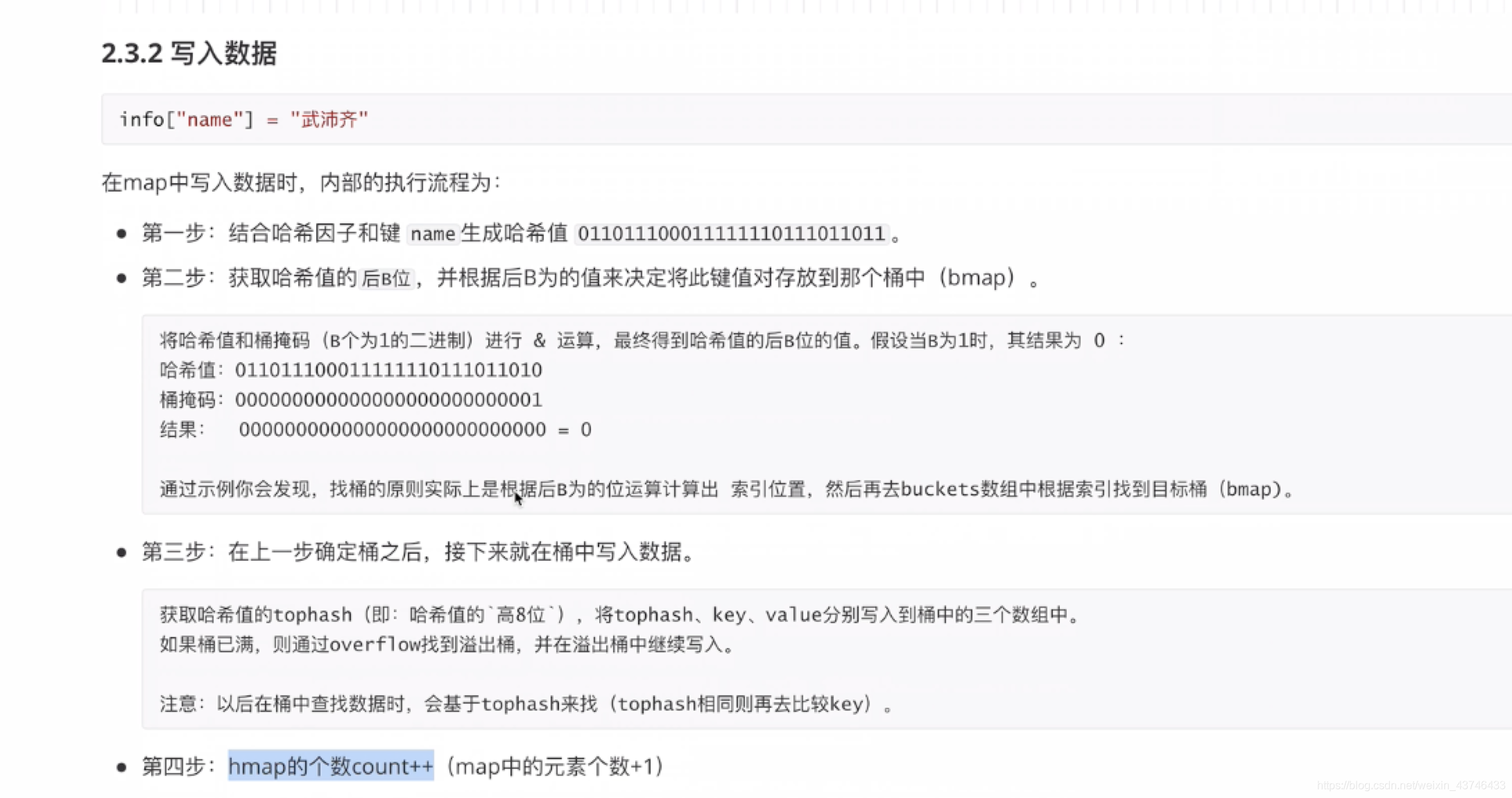
map写入数据内部执行流程
在Go语言中,Map的扩容过程非常关键,它决定了Map的性能和效率。一般来说,扩容会在以下几种情况中触发:
- 删除元素:当我们删除Map中的元素时,Go会检查是否正在进行扩容操作。如果是,那么扩容操作将针对被删除元素的bucket进行。
// 删除元素
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}
- 插入或更新元素:当我们向Map中插入新元素或更新现有元素时,Go会进行类似的检查。此时,如果Map正在扩容,那么扩容操作将针对被插入或更新元素的bucket进行。
// 插入或更新元素
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // 增长表格会使所有东西都失效,所以重新尝试
}
}
通过阅读源码,我们可以看到,如果Map正在扩容,那么在删除、插入或更新元素时都会执行一次迁移操作。这样可以确保扩容过程的平滑进行,而不会因为其他操作的干扰而中断。值得注意的是,查找元素并不会触发扩容操作。这是因为,查找操作只涉及到读取数据,而不会改变Map的结构,因此无需触发扩容。
写入数据
读取数据

map扩容总结
-
Map 的赋值难点在于数据的扩容和数据的搬迁操作。
-
扩容不是一定会新增空间,也有可能是只是做了内存整理。
-
tophash 的标志即可以判断是否为空,还会判断是否搬迁,以及搬迁的位置为X or Y。
-
delete map 中的key,有可能出现很多空的kv,会导致搬迁操作。如果可以避免,尽量避免。
map优化点
-
提前分配内存: 一切都和其他地方一样。初始化map时,指定其大小。
-
使用空结构作为值: struct{}什么都不是,因此例如对信号值使用这种方法是非常有益的。
-
及时清空map
map只能增长,不能缩小。我们需要控制这一点——完全而明确地重置map。因为删除其所有元素无济于事。 -
尽量不要在键和值中使用指针
如果 map 不包含指针,那么 GC 就不会在它上面浪费宝贵的时间。而且要知道字符串也是指针——使用[]byte而不是字符串作为键。
map gc优化手段
在 go 里,由于 GC STW(Stop the World) 的存在大的哈希表是非常要命的,看看 bigcache 开发团队的博客的测试数据:
With an empty cache, this endpoint had maximum responsiveness latency of 10ms for 10k rps. When the cache was filled, it had more than a second latency for 99th percentile. Metrics indicated that there were over 40 mln objects in the heap and GC mark and scan phase took over four seconds.
缓存塞满后,堆上有 4 千万个对象,GC 的扫描过程就超过了 4 秒钟,这就不能忍了。
主要的优化思路有:
-
offheap(堆外内存),GC 只会扫描堆上的对象,那就把对象都搞到栈上去,但是这样这个缓存库就高度依赖 offheap 的 malloc 和 free 操作了
-
参考 freecache 的思路,用 ringbuffer 存 entry,绕过了 map 里存指针,简单瞄了一下代码,后面有空再研究一下(继续挖坑
-
利用 Go 1.5+ 的特性:
当 map 中的 key 和 value 都是基础类型时,GC 就不会扫到 map 里的 key 和 value
如果我们仔细看 mapextra 结构体里对 overflow 字段的注释,会发现这里有“文章”。
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
意思是如果 map 的 key 和 value 都不包含指针的话,在 GC 期间就可以避免对它的扫描。在 map 非常大(几百万个 key)的场景下,能提升不少性能。
那具体是怎么实现“不扫描”的呢?
我们知道,bmap 这个结构体里有一个 overflow 指针,它指向溢出的 bucket。因为它是一个指针,所以 GC 的时候肯定要扫描它,也就要扫描所有的 bmap。
而当 map 的 key/value 都是非指针类型的话,扫描是可以避免的,直接标记整个 map 的颜色(三色标记法)就行了,不用去扫描每个 bmap 的 overflow 指针。
但是溢出的 bucket 总是可能存在的,这和 key/value 的类型无关。
于是就利用 hmap 里的 extra 结构体的 overflow 指针来 “hold” 这些 overflow 的 bucket,并把 bmap 结构体的 overflow 指针类型变成一个 unitptr 类型(这些是在编译期干的)。于是整个 bmap 就完全没有指针了,也就不会在 GC 期间被扫描。
tips:
uintptr是一个无符号的整型,它可以保存一个指针地址。
它可以进行指针运算。
uintptr无法持有对象, GC不把uintptr当指针, 所以uintptr类型的目标会被回收。
想取值需要转成unsafe.Pointer后, 需再转到相对应的指针类型。
overflow *[]*bmap
另一方面,当 GC 在扫描 hmap 时,通过 extra.overflow 这条路径(指针)就可以将 overflow 的 bucket 正常标记成黑色,从而不会被 GC 错误地回收。
当我们知道上面这些原理后,就可以利用它来对一些场景进行性能优化:
map[string]int -> map[[12]byte]int
因为 string 底层有指针,所以当 string 作为 map 的 key 时,GC 阶段会扫描整个 map;而数组 [12]byte 是一个值类型,不会被 GC 扫描。
利用bigcache优化全局map
-
可以通过 sharding 来降低资源竞争
-
可以用位运算来取余数做 sharding (需要是 2 的整数幂 - 1)
-
避免 map 中出现指针、使用 go 基础类型可以显著降低 GC 压力、提升性能
-
bigcache 底层存储是 bytes queue,初始化时设置合理的配置项可以减少 queue 扩容的次数,提升性能
https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/125325536
go-zero safemap 避免OOM分析
在 Golang 中的 map 结构,在删除键值对的时候,并不会真正的删除,而是标记。那么随着键值对越来越多,会不会造成大量内存浪费?
首先答案是会的,很有可能导致 OOM,而且针对这个还有一个讨论:https://github.com/golang/go/issues/20135。大致的意思就是在很大的 map 中,delete 操作没有真正释放内存而可能导致内存 OOM。
所以一般的做法:就是 重建 map。而 go-zero 中内置了 safemap 的容器组件。safemap 在一定程度上可以避免这种情况发生。
原生map删除key大致过程
-
写保护,防止并发写
-
查询要删除的 key 是否存在
-
存在则对其标志做删除标记
-
count–
所以你在大面积删除 key ,实际 map 存储的 key 是不会删除的,只是标记当前的 key 状态为 empty。
其实出发点,和 mysql 的标记删除类似,防止后续会有相同的 key 插入,省去了扩缩容的操作。
但是这个对有些场景是不妥的,如果开发者在未来时间内都不会再插入相同的 key ,很可能会导致 OOM。
所以针对以上情况,go-zero 开发了 safemap 。下面我们看看 safemap 是如何避免这个问题的?
设计实现
-
预设一个 删除阈值,如果触发会放到一个新预设好的 newmap 中
-
两个 map 是一个整体,所以 key 只能留一份
所以为什么要设置两个 map 就很清楚了:
-
dirtyOld 作为存储主体,如果 delete 操作达到阈值,则会触发迁移。
-
dirtyNew 作为暂存体,会在到达阈值时,存放部分 key/value
所以在迁移操作时,我们需要做的就是:将原先的 dirtyOld 清空,存储的 key/value 通过 for-range 重新存储到 dirtyNew,然后将 dirtyNew 指向 dirtyOld。
源码分析:
const (
copyThreshold = 1000
maxDeletion = 10000
)
// SafeMap provides a map alternative to avoid memory leak.
// This implementation is not needed until issue below fixed.
// https://github.com/golang/go/issues/20135
type SafeMap struct {
lock sync.RWMutex
deletionOld int
deletionNew int
dirtyOld map[interface{}]interface{}
dirtyNew map[interface{}]interface{}
}
// NewSafeMap returns a SafeMap.
func NewSafeMap() *SafeMap {
return &SafeMap{
dirtyOld: make(map[interface{}]interface{}),
dirtyNew: make(map[interface{}]interface{}),
}
}
// Get gets the value with the given key from m.
func (m *SafeMap) Get(key interface{}) (interface{}, bool) {
m.lock.RLock()
defer m.lock.RUnlock()
// 先判断老map
if val, ok := m.dirtyOld[key]; ok {
return val, true
}
val, ok := m.dirtyNew[key]
return val, ok
}
// Set sets the value into m with the given key.
func (m *SafeMap) Set(key, value interface{}) {
m.lock.Lock()
// 通过阈值判断,选择在哪个map中加key value
if m.deletionOld <= maxDeletion {
if _, ok := m.dirtyNew[key]; ok {
delete(m.dirtyNew, key)
m.deletionNew++
}
m.dirtyOld[key] = value
} else {
// 如果超过阈值,直接在dirtyNew map添加,后续则减少迁移成本
if _, ok := m.dirtyOld[key]; ok {
delete(m.dirtyOld, key)
m.deletionOld++
}
m.dirtyNew[key] = value
}
m.lock.Unlock()
}
// 迁移old map -> new map 操作是在删除key时触发
// Del deletes the value with the given key from m.
func (m *SafeMap) Del(key interface{}) {
m.lock.Lock()
// 先删除
if _, ok := m.dirtyOld[key]; ok {
delete(m.dirtyOld, key)
m.deletionOld++
} else if _, ok := m.dirtyNew[key]; ok {
delete(m.dirtyNew, key)
m.deletionNew++
}
// 判断两个map是否达到删除阈值,触发迁移
if m.deletionOld >= maxDeletion && len(m.dirtyOld) < copyThreshold {
for k, v := range m.dirtyOld {
m.dirtyNew[k] = v
}
// dirtyNew map地址指向dirtyOld
m.dirtyOld = m.dirtyNew
m.deletionOld = m.deletionNew
m.dirtyNew = make(map[interface{}]interface{})
m.deletionNew = 0
}
if m.deletionNew >= maxDeletion && len(m.dirtyNew) < copyThreshold {
for k, v := range m.dirtyNew {
m.dirtyOld[k] = v
}
m.dirtyNew = make(map[interface{}]interface{})
m.deletionNew = 0
}
m.lock.Unlock()
}
参考:
https://cloud.tencent.com/developer/article/1422373
原文地址:https://blog.csdn.net/weixin_43746433/article/details/135890427
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!