Seata
分布式事务
分布式事务是指存在多个跨库事务的事务一致性问题。或者在分布式架构里面有多个应用节点组成的多个事务之间的事务一致性的问题。
目前主流的分布式事务解决方案有两种
- 基于 XA 协议的强一致性事务方案(两阶段提交)。
- 比如说:Atomikos、Seata 里面的 XA 事务模型
- 基于 CP 理论我们知道,如果要保证分布式事务的强一致性,就必然会带来性能上的影响,从而影响到可用性。所以强一致性的性能会比较低。
- 基于 Base 理论下的最终一致性解决方案。
- 比如说:TCC 事务模型,以及基于可靠消息的最终一致性方案。Seata 的 Saga 事务模型等等
- 最终一致性事务,损失了数据的强一致性,然后通过异步补偿的方式,去达到数据的最终一致性。因此在性能上会比强一致性事务要好很多。它适合用在一些并发比较高的场景里。
通常情况以下,传统的数据库只能保证单个数据库里面多个数据表的事务的 ACID 特性,一旦多个 SQL 操作涉及到多个数据库。这类事务是无法解决跨库事务的问题的。
比如在电商的系统中的支付功能:在微服务架构里,应用会被拆分成多个以业务模块为单元的微服务。并且每个服务,会有自己的数据库。当用户发起支付的时候,它就会涉及到多个事物操作,比如:创建支付订单,从资金服务去扣除余额、从红包服务去扣除余额,再去更新支付结果。这是四个典型的事物操作。而且这些操作又分别属于不同的数据库。最终期望的结果是:这四个服务对应的数据是完全一致的。很显然传统的事物无法解决这个问题。因此就产生了分布式这样的问题。
所谓分布式事务:就是事务具有分布式这样的一个特征。简单理解就是:如何实现多个跨库的小事务,组成了大事务的 ACID 特性。
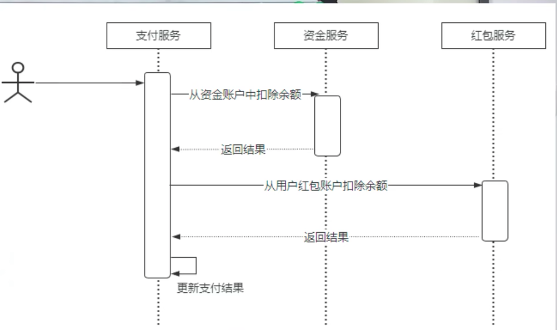
不建议在项目中使用分布式事务中间件:
原因:引入分布式事务中间件会造成系统大规模耦合的情况。
Seata
概述
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
比如在电商的系统中:在微服务架构里,应用会被拆分成多个以业务模块为单元的微服务。并且每个服务,会有自己的数据库。当用户发起支付的时候,它就会涉及到多个事物操作,比如:创建支付订单,增加积分、扣除库存。这是三个典型的事物操作。而且这些操作又分别属于不同的数据库。最终期望的结果是:这三个服务对应的数据是完全一致的。很显然传统的事物无法解决这个问题。因此就产生了分布式这样的问题。
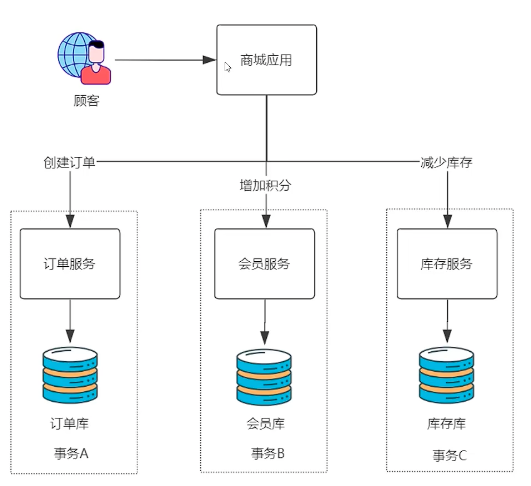
要想统筹分散在各个微服务中的事务,需要一个事务协调者。
事务协调者的职责就是,向各个微服务下达通知:
- 请求提交
- 请求回滚。
过程:
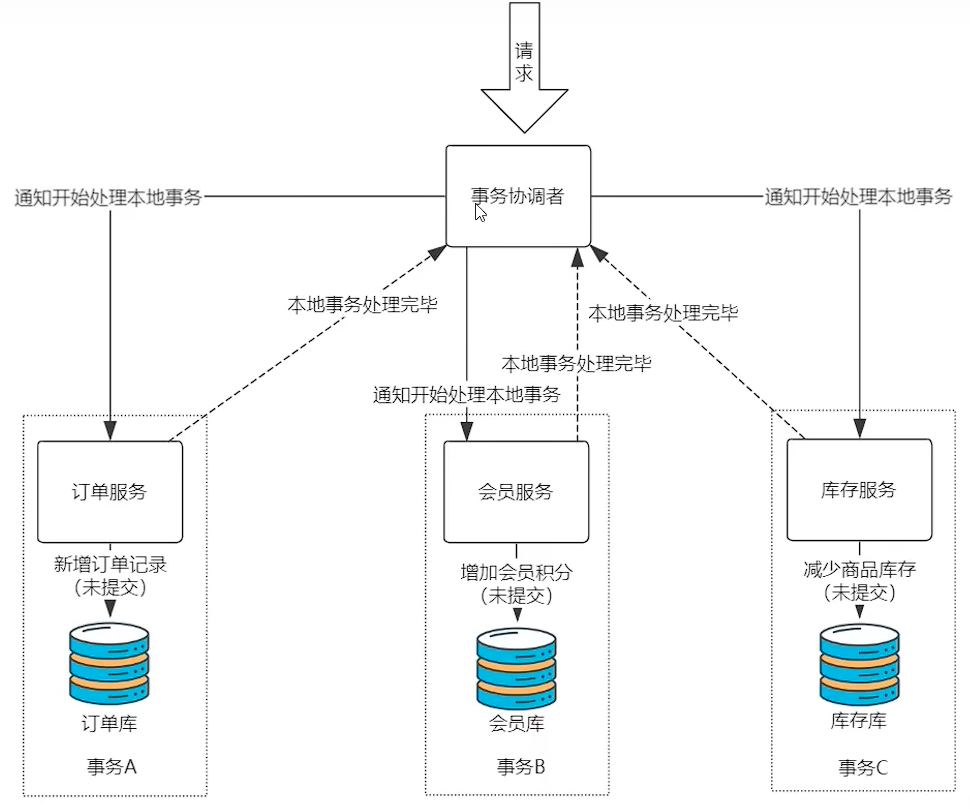
- 一个请求过来,事务协调者通知各个微服务开始处理事务。
- 微服务接到通知后,处理各自的服务,处理完毕后,但是还未提交。会向知事务协调者是否提交?
- 事务协调者收集到所有确认,如果没有问题,就发送提交消息,如果有一个有问题,发送回滚消息。
- 微服务收到提交或者回滚的通知,进行后续的处理。
上述整个过程,包含两个阶段:
- 阶段一:微服务处理业务不提交
- 阶段二:微服务提交或者回滚。
这种需要两个阶段处理的事务,成为二阶段提交。Seata 也是采用而二阶段提交的方案。
Seata
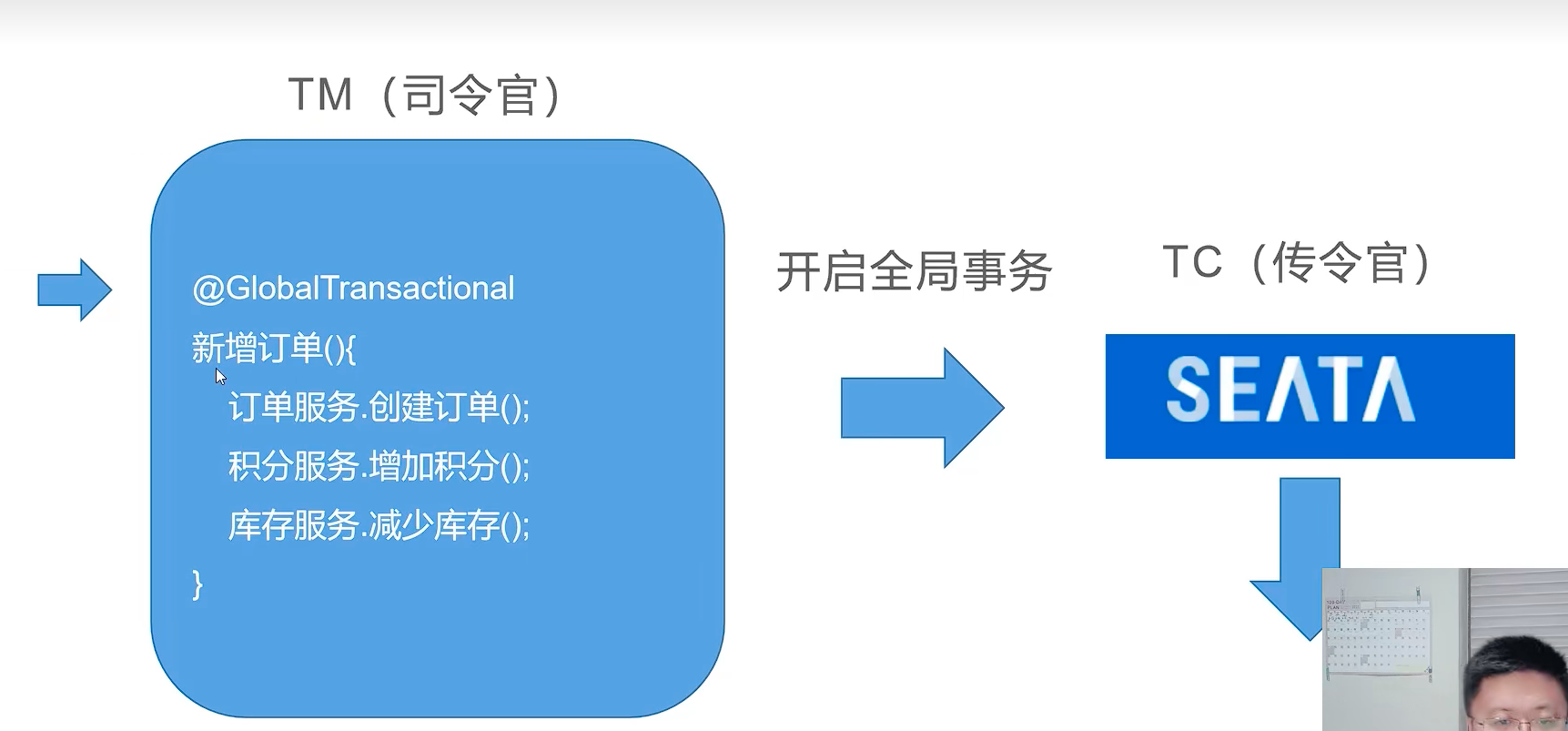
三个角色
- 事务管理器(TM):决定什么时候全局提交/回滚。
- 事务协调者(TC):负责通知命令的中间件 Seata-Server
- 资源管理器(RM):做具体事儿的工具人
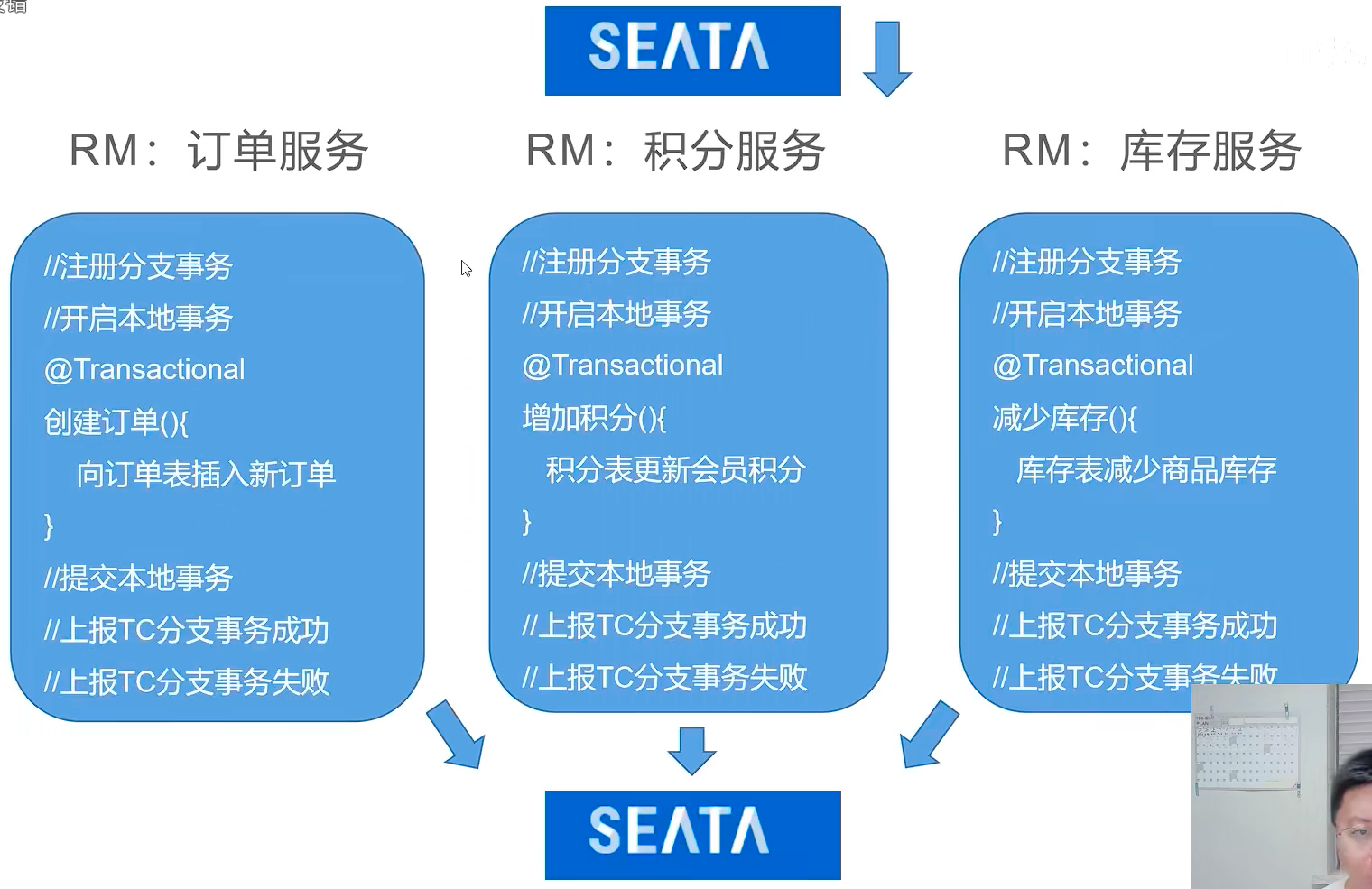
在下图架构中,商城应用就是:事务管理器(TM)。它定义了事务的边界。
在商城应用的项目中,凡是有 @GlobalTransactional 注解的方法都是:开启分布式事务的方法。
图中 事务协调者(TC)是需要独立部署的服务。
在RM 中(具体微服务),凡是 @Transactional 注解的方法,都是开启本地事务的方法。当方法执行成功,@Transactional 会默认向 TM 发送确认通知。
所有子事务都执行成功了,TM 就会想 TC下达提交全局事务的命令或者全局回滚的命令。
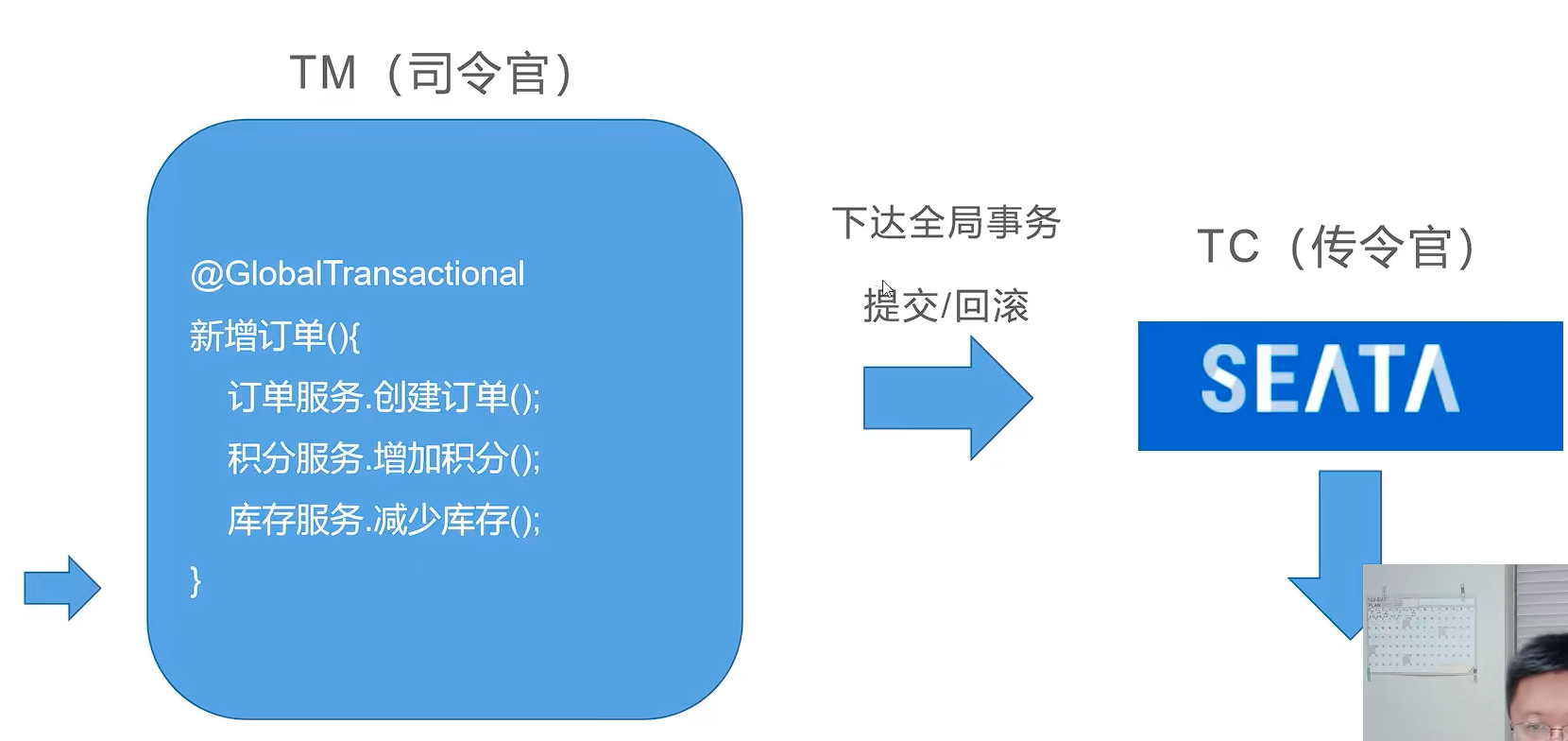
TC 向所有微服务下达提交事务或者回滚事务。

注意:上述步骤中微服务已经提交过了,如果 TM 要求回滚,怎么回滚?

解决方法:seata 要求,在每个微服务的数据库中,创建一个 UNDO_LOG 表。seata 自动在 UNDO_LOG 表中添加相反操作的SQL,用来回归。底层 seata 使用 sql-parse 解析执行的SQL,创建相反操作的SQL,插入UNDO_LOG 表 中。

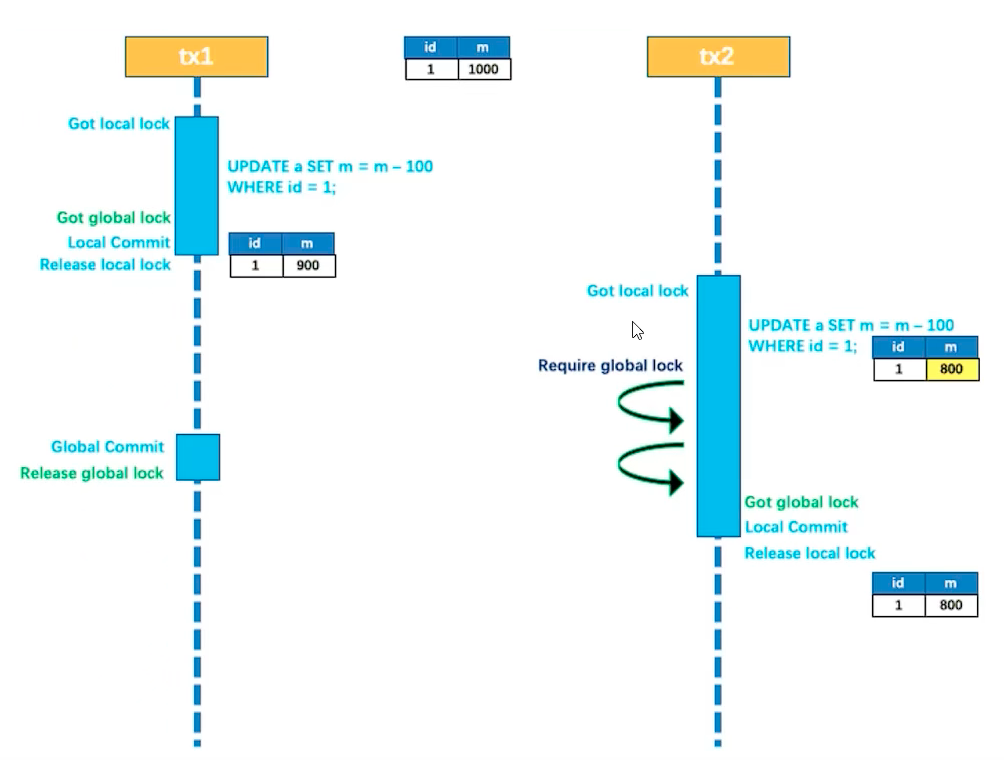
Seata 如何避免并发场景下的脏读和脏写呢?
脏写:通过分布式锁,对资源锁定,完成并发写的操作。
TC 通过分布式锁, tx1 事务持有锁,如果 tx2 要对同一条数据进行操作时,只能等待。直到获取到锁。

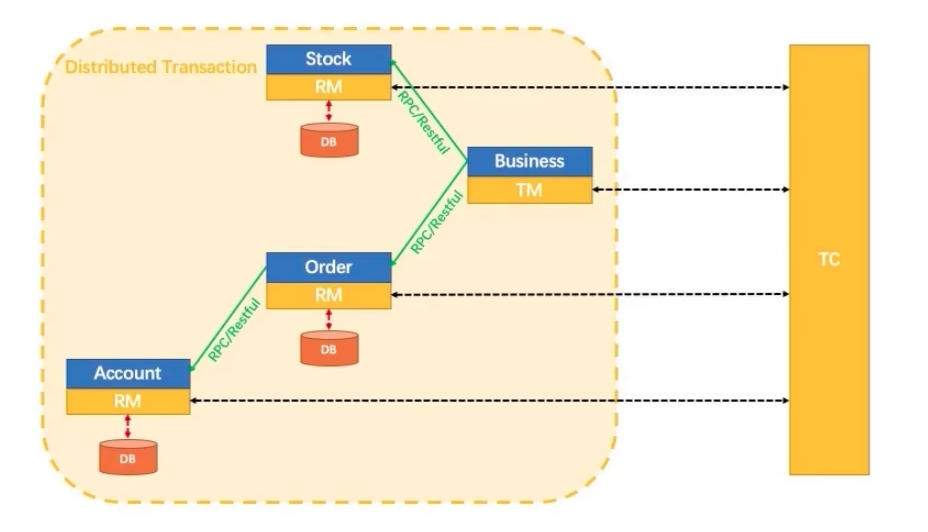
Seata 为用户提供了 AT、TCC、SAGA、XA 等事务模式
AT 模式
实现原理:
阿里 Seata 独有的模式,通过反向生成 SQL 实现数据的回滚,需要在每个微服务的数据库中额外添加 UNDO_LOG 表
insert into 订单 value(10001,....)
update 仓储 set num = 200 where gid = 100 // 原库存 210
自动生成 UNDO_LOG 回滚日志
delete form 订单 where id = 10001
update 仓储 set num = 210 where gid = 100
特点
-
性能高
-
模式:AP (可用性),存在数据不一致的中间状态。
-
难易程度:简单,靠 Seata 自己解析反向 SQL 并回滚。
-
使用要求:
- 所有服务和数据库必须要自己拥有管理权限,引用要创建 UNDO_LOG 表
- 最好都是 MySQL
-
应用场景:
- 高并发互联网应用,允许数据出现短时不一致,可通过对账程序或者补录来保证最终一致性。
TCC 模式
TCC 是 Try-尝试、Comfirm-确认、Cancel-取消。
- try 尝试阶段,对资源进行锁定。
- Comfirm-确认阶段:对资源进行确认
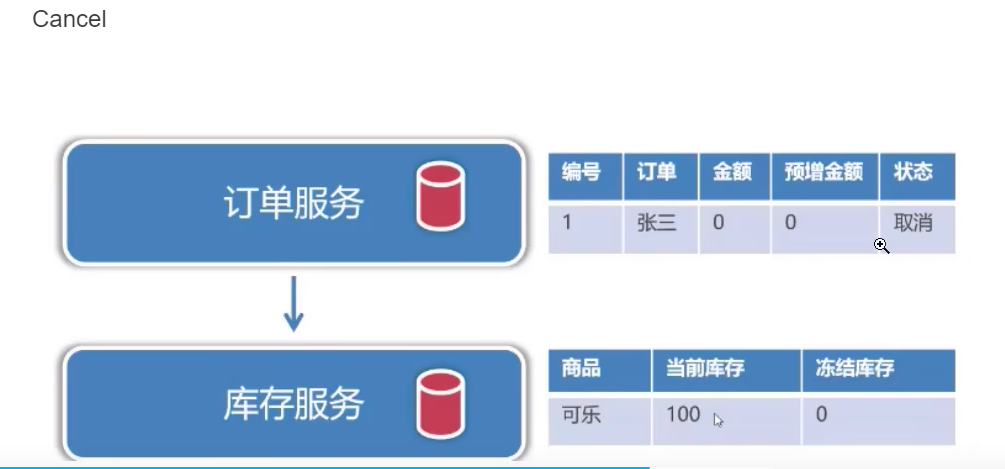
- Cancel-取消阶段:对资源进行还原或者取消。
实现原理
在代码与数据表中扩展字段,实现对数据库资源的锁定。
在 Try 阶段,会将需要增加或者减少的数据,存在:“预增金额”和“冻结库存” 字段中。
如果所有微服务操作成功,需要提交时,再去修改正在的字段。同时情况预留列。
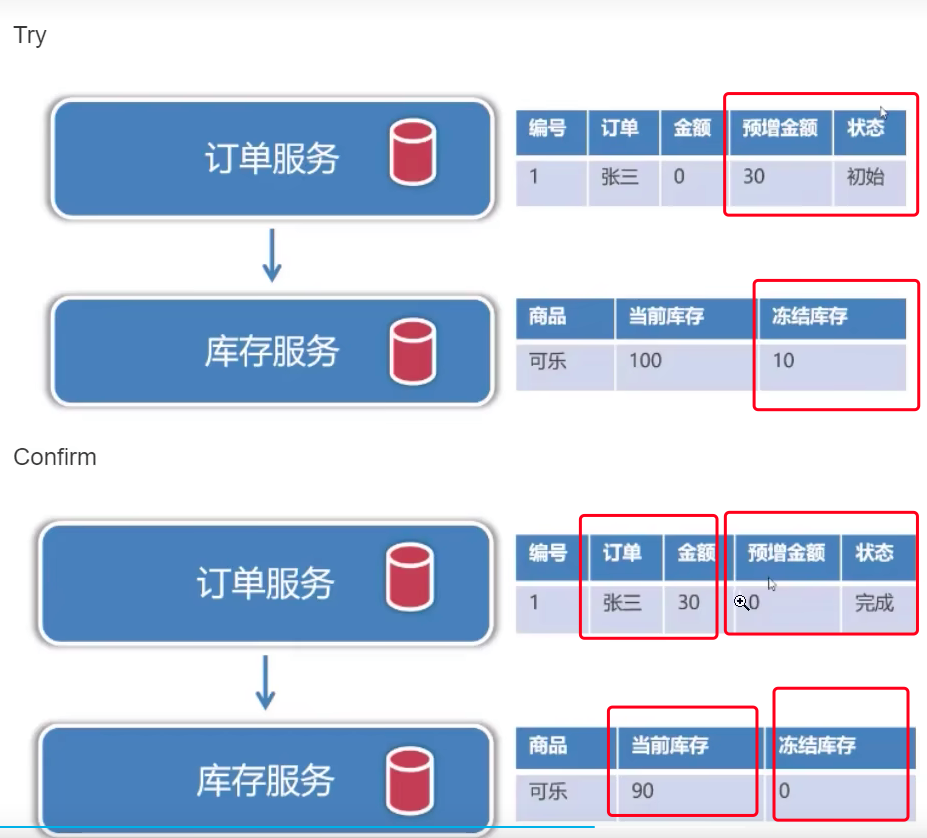
如果出现问题,需要取消的话,只需要将“预增金额”和“冻结库存” 字段中 清空即可。
特点
-
性能高
-
模式:AP (可用性),存在数据不一致的中间状态。
-
难易程度:复杂, Seata 只负责全局事务的提交和回滚指令,具体的回滚处理全靠程序员自己实现。
-
使用要求:
- 所有服务和数据库必须要自己拥有管理权限
- 支持已购数据库,可以使用不同类型实现。反正都是自己写的提交和回滚的逻辑。
-
应用场景:
- 高并发互联网应用,允许数据出现短时不一致,可通过对账程序或者补录来保证最终一致性。
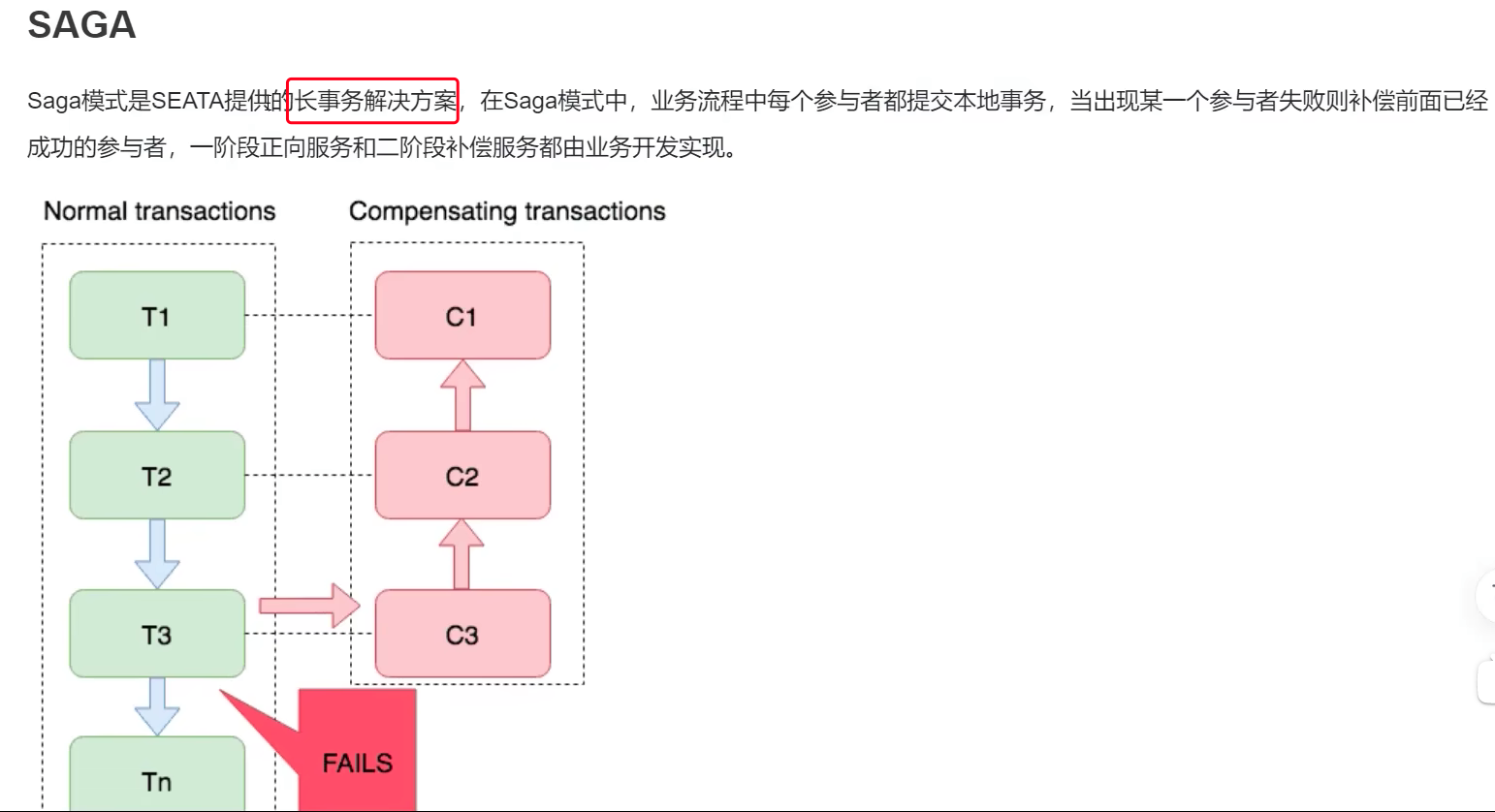
SAGA 模式
比如在使用第三方支付系统业务中。我们不能支付宝或者微信的支付系统添加 UNDO_LOG 表或者添加字段。
下图绿色是事务的正常流程:
T1:创建订单
T2:微信支付
T3:减库存
红色方块是逆向操作:
C1:删除订单
C2:微信退款
C3:增加库存
特点
-
性能:不一定,取决于第三方服务。
-
模式:AP (可用性),存在数据不一致的中间状态。
-
难易程度:复杂,提交于回滚流程全靠程序员开发。
-
使用要求:
- 在当前架构引入状态机机制,类似于工作流。
- 无法保证隔离性
-
应用场景:
- 需要与第三方交互是才会考虑,例如:调用支付宝接口 -> 出库失败 -> 调用支付宝接口退款。
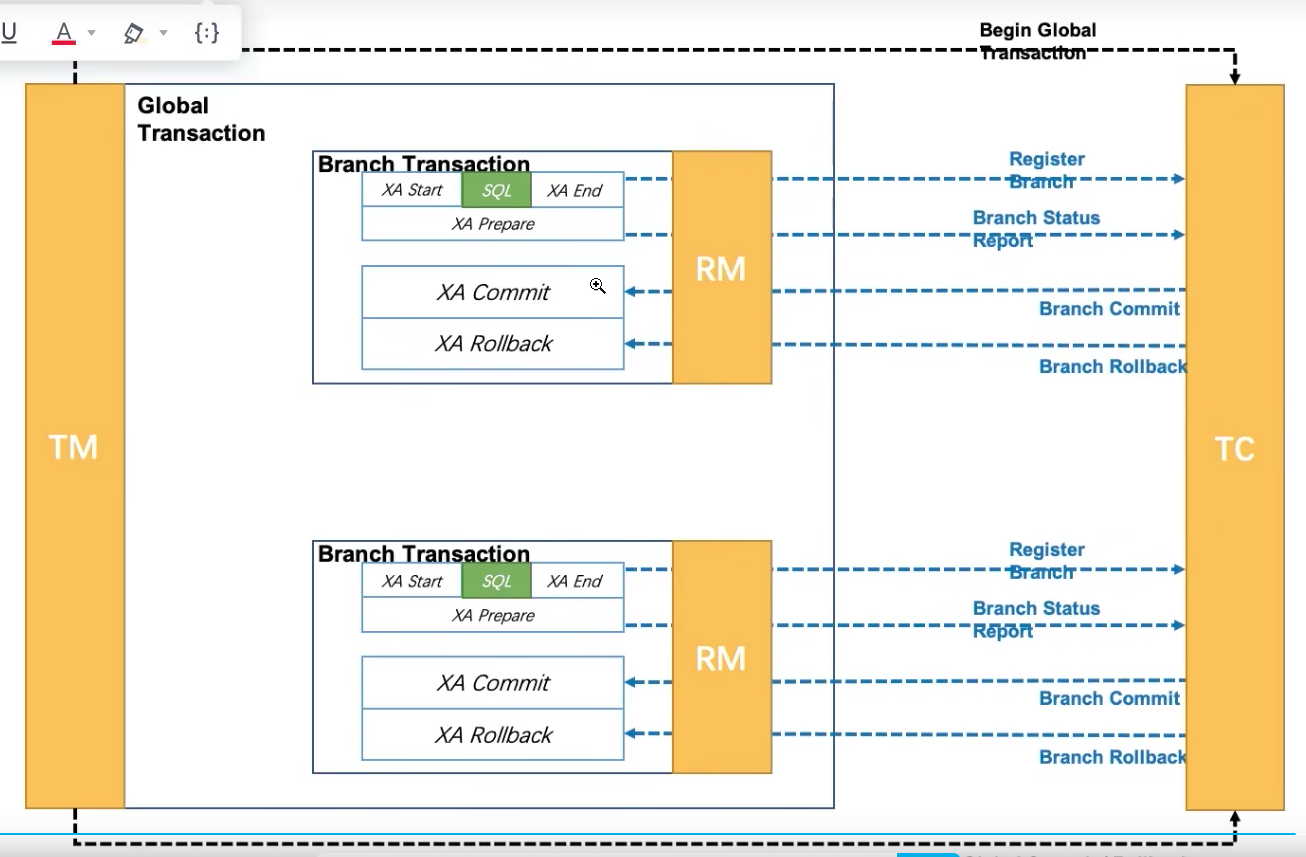
XA 模式
实现原理:基于数据库 XA 协议来实现 2PC 又称 XA 方案。
XA 模式最简单,最粗暴。原理就是:每个微服务的 SQL 只执行,不提交。数据库对堵塞,等待提交。当 TC 服务下单了提交命令后,微服务才会执行 SQL 的提交。
特点
-
性能:低。
-
模式:CP (强一致性),一个SQL 执行未提交,其他SQL 被阻塞。
-
难易程度:简单,基于数据库自带特性实现,无需该表。
-
使用要求:
- 使用支持 XA 方案的关系型数据库(主流都支持)
-
应用场景:
- 金融行业,并发量不大,但是数据很重要的项目。
原文地址:https://blog.csdn.net/junxinsiwo/article/details/142797843
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!