即插即用的涨点模块之变体卷积(深度可分离卷积)详解及代码,可应用于检测、分割、分类等各种算法领域
目录
前言
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
来源:CVPR2017
官方代码:GitHub - kuan-wang/pytorch-mobilenet-v3: MobileNetV3 in pytorch and ImageNet pretrained models
深度可分离卷积(Depthwise Separable Convolution)是一种有效的卷积神经网络(CNN)中的卷积操作,主要用于减少模型的计算量和参数数量,同时尽量保持相同的网络性能。这种卷积操作在移动和嵌入式设备上的应用尤为重要,因为这些设备的计算资源有限。深度可分离卷积有mobileNets提出,用于模型的轻量化。
一、深度可分离卷积结构
深度可分离卷积是由Depthwise Convolution(深度卷积)和Pointwise Convolution(逐点卷积)构成,结构如图1所示。图中(a)为标准卷积,(b)为深度卷积,(c)为逐点卷积。
深度卷积(Depthwise Convolution):在这一步,每个输入通道分别被一个单独的卷积核处理。这意味着如果输入数据的通道数为C,且使用的卷积核大小为K×K,则总共会有 C个卷积核,每个卷积核仅在相应的单个输入通道上进行卷积操作。因此,这一步主要进行特征提取。
逐点卷积(Pointwise Convolution,也称为1x1卷积):经过深度卷积后,输出的每个通道都是独立处理的,接下来使用1x1的卷积核将这些通道的输出合并,这一步可以看作是特征组合。逐点卷积主要负责调整通道的维度和组合来自不同通道的信息,具有显著减少计算和模型大小的效果。
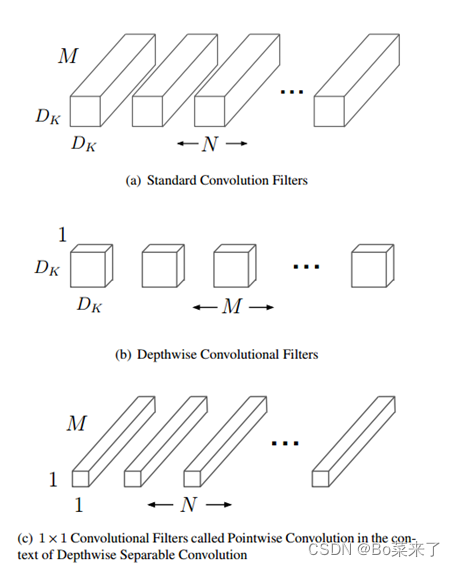
图1 (a)为标准卷积,(b)为深度卷积,(c)为逐点卷积

图2 深度可分离卷积结构
二、计算流程
如图2深度可分离卷积结构可知,深度可分离卷积先进行深度卷积在进行逐点卷积,下面分别计算深度卷积和逐点卷积的参数量和计算量:
给定一个输入![]() (其中C为通道数,H为高度,W为宽度),经过
(其中C为通道数,H为高度,W为宽度),经过![]() 的卷积核,得到特征图
的卷积核,得到特征图![]() 。
。
深度卷积的参数量:每个输入通道使用一个独立的 K×K 卷积核,所以参数总数为:![]()
深度卷积的计算量: 每个卷积核只处理一个通道,所以计算量为:![]()
逐点卷积的参数量:由于是1×1 卷积,每个输入通道对应![]() 个输出通道,参数总数为:
个输出通道,参数总数为:![]()
逐点卷积的计算量:![]()
深度可分离卷积的参数量为:![]() ,计算量为:
,计算量为:![]() +
+![]()
普通卷积的参数量为:![]() ,计算量为:H'×W'×C×C'×K×K
,计算量为:H'×W'×C×C'×K×K![]()
深度可分离卷积与普通卷积的计算量比值为:
![]() =
=![]()
即深度可分离卷积的计算量大约为普通卷积计算量的![]()
三、深度可分离卷积参数
利用thop库的profile函数计算FLOPs和Param。Input:(64,32,32),卷积核(128,3,3)
| Module | FLOPs | Param |
| DSConv | 8978432 | 8960 |
| 标准卷积 | 75497472 | 73856 |
四、代码详解
import torch
import torch.nn as nn
class DepthwiseSeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(DepthwiseSeparableConv2d, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=in_channels) #深度卷积
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1) #逐点卷积
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class stardard_conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(stardard_conv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
def forward(self, x):
x = self.conv(x)
return x
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = DepthwiseSeparableConv2d(64, 128, 3, 1, 1)
model1 = stardard_conv(64, 128, 3, 1, 1)
flops, params = profile(model, inputs=(torch.randn(1, 64, 32, 32),))
flops1, params1 = profile(model1, inputs=(torch.randn(1, 64, 32, 32),))
print(f"FLOPs: {flops}, Params: {params}")
print(f"FLOPs: {flops1}, Params: {params1}")原文地址:https://blog.csdn.net/qq_51511878/article/details/138029159
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!