FPGA学习笔记#8 Vitis HLS优化总结和案例程序的优化
本笔记使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,主要根据教程:跟Xilinx SAE 学HLS系列视频讲座-高亚军进行学习
学习笔记:《FPGA学习笔记》索引
FPGA学习笔记#1 HLS简介及相关概念
FPGA学习笔记#2 基本组件——CLB、SLICE、LUT、MUX、进位链、DRAM、存储单元、BRAM
FPGA学习笔记#3 Vitis HLS编程规范、数据类型、基本运算
FPGA学习笔记#4 Vitis HLS 入门的第一个工程
FPGA学习笔记#5 Vitis HLS For循环的优化(1)
FPGA学习笔记#6 Vitis HLS For循环的优化(2)
FPGA学习笔记#7 Vitis HLS 数组优化和函数优化
FPGA学习笔记#8 Vitis HLS优化总结和案例程序的优化
目录
1.HLS优化总结
对于函数,可以使用PIPELINE或DATAFLOW。
对于循环,可以使用PIPELINE(可选rewind)、UNROLL(可选factor)或DATAFLOW。
对于数组,可以使用ARRAY_PARTITION,有block、cyclic、complete三种优化方式。
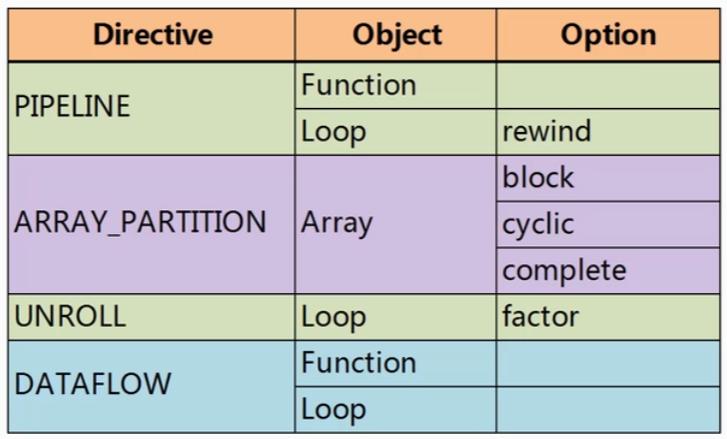
PIPELINE作用于函数和循环的情况如下,作用于循环时,两次循环之间会存在空档,被称为bubble,rewind可以解决这个问题。
对于latency,有专门的LATENCY约束用于函数和循环,可以指定min和max。
LOOP_MERGE用于合并多个循环
LOOP_FLATTEN用于perfect/semi-perfect循环

在区域中:
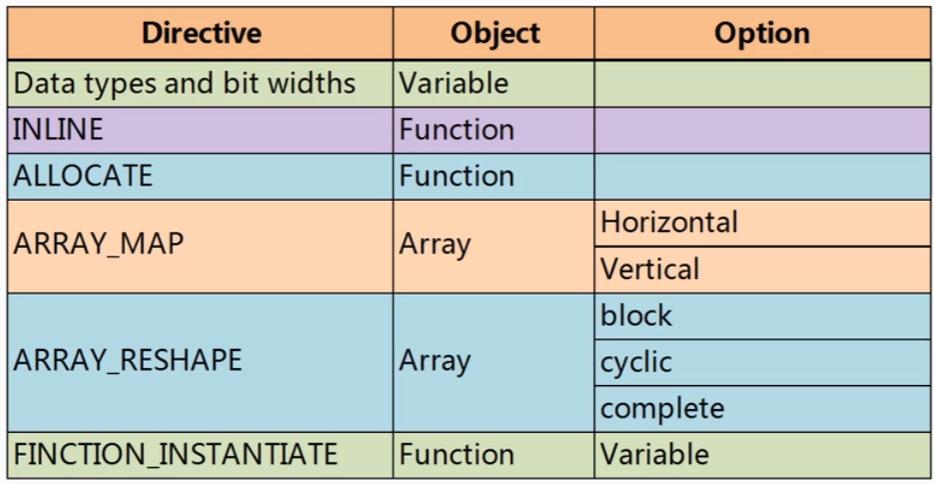
数据类型和位宽也是影响硬件效率和资源使用的原因
INLINE用于函数
ALLOCATION用于函数的实例化
ARRAY_MAP和ARRAY_RESHAPE用于数组
FUNCTION_INSTANTIATE用于函数
2.优化案例
2.1.案例程序
案例程序如下,请根据第四篇笔记进行项目的构建和仿真、综合、联合仿真。
Top.h:
#include <ap_int.h>
#include <ap_fixed.h>
#define WA 17
#define FA 14
#define WS 16
#define FS 14
typedef ap_fixed<WA,WA-FA> di_t;
typedef ap_fixed<WS,WS-FS> do_t;
typedef ap_uint<2> flag_t;
const do_t Kn = 0.607252935;
const di_t PI = 3.1415926;
void cir_cordic (di_t full_alpha, do_t &out_sin, do_t &out_cos);
Top.cpp:
#include "top.h"
void pre_cir_cordic (di_t full_alpha, di_t &alpha, flag_t &flag)
{
if (full_alpha > PI/2)
{
alpha = PI - full_alpha;
flag = 2;
}
else if (full_alpha < -PI/2)
{
alpha = -PI - full_alpha;
flag = 3;
}
else
{
alpha = full_alpha;
flag = 0;
}
}
void cir_cordic_calculate (di_t alpha, flag_t flag, do_t &mysin, do_t &mycos, flag_t &flag_delay)
{
const int N = 16;
do_t xi[N];
do_t yi[N];
di_t zi[N];
flag_t flag_delay_a[N];
xi[0] = Kn;
yi[0] = 0;
zi[0] = alpha;
flag_delay_a[0] = flag;
const di_t myarctan[16] = {
0.7853981633974483,
0.4636476090008061,
0.24497866312686414,
0.12435499454676144,
0.06241880999595735,
0.031239833430268277,
0.015623728620476831,
0.007812341060101111,
0.0039062301319669718,
0.0019531225164788188,
0.0009765621895593195,
0.0004882812111948983,
0.00024414062014936177,
0.00012207031189367021,
6.103515617420877e-05,
3.0517578115526096e-05
};
int m = 0;
loop:
for (m = 0; m < N; m++)
{
if (zi[m] >= 0)
{
xi[m+1] = xi[m] - (yi[m] >> m);
yi[m+1] = yi[m] + (xi[m] >> m);
zi[m+1] = zi[m] - myarctan[m];
}
else
{
xi[m+1] = xi[m] + (yi[m] >> m);
yi[m+1] = yi[m] - (xi[m] >> m);
zi[m+1] = zi[m] + myarctan[m];
}
flag_delay_a[m+1] = flag_delay_a[m];
}
mysin = yi[N-1];
mycos = xi[N-1];
flag_delay = flag_delay_a[N-1];
}
void post_cir_cordic (do_t mysin, do_t mycos, flag_t flag_delay, do_t &sin_out, do_t &cos_out)
{
switch(int(flag_delay))
{
case 2: sin_out = mysin; cos_out = -mycos; break;
case 3: sin_out = -mysin; cos_out = -mycos; break;
default: sin_out = mysin; cos_out = mycos; break;
}
}
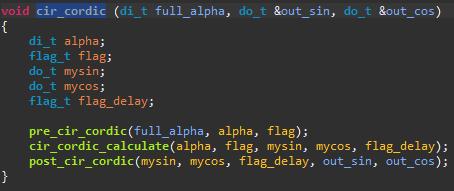
void cir_cordic (di_t full_alpha, do_t &out_sin, do_t &out_cos)
{
di_t alpha;
flag_t flag;
do_t mysin;
do_t mycos;
flag_t flag_delay;
pre_cir_cordic(full_alpha, alpha, flag);
cir_cordic_calculate(alpha, flag, mysin, mycos, flag_delay);
post_cir_cordic(mysin, mycos, flag_delay, out_sin, out_cos);
}
Test.cpp:
#include <iostream>
#include <iomanip>
#include <cmath>
#include <math.h>
#include "top.h"
using namespace std;
int main(){
const int N = 13;
di_t alpha[N] = {
3.01837,
3.02838,
3.03839,
3.0484,
3.05835,
3.06836,
3.07837,
3.08838,
3.09839,
3.1084,
3.11835,
3.12836,
3.13837
};
do_t sinRef[N] = {
0.122864,
0.112915,
0.102966,
0.0930176,
0.0830688,
0.0730591,
0.0631104,
0.0531006,
0.0431519,
0.0331421,
0.0231323,
0.0131836,
0.00317383
};
do_t cosRef[N] = {
-0.992432,
-0.993652,
-0.99469,
-0.995667,
-0.996582,
-0.997375,
-0.998047,
-0.998596,
-0.999084,
-0.999451,
-0.999756,
-0.999939,
-1.0
};
do_t sinres[N] = {0};
do_t cosres[N] = {0};
int ErrCntSin = 0;
int ErrCntCos = 0;
float precision = pow(2, -10);
int i;
for (i = 0; i < N; i++)
{
cir_cordic(alpha[i], sinres[i], cosres[i]);
}
cout << setfill('-') << setw(90) << "-" << endl;
cout << setfill(' ') << setw(18) << right << "Alpha";
cout << setfill(' ') << setw(18) << right << "sin";
cout << setfill(' ') << setw(18) << right << "sinRef";
cout << setfill(' ') << setw(18) << right << "cos";
cout << setfill(' ') << setw(18) << right << "cosRef" << endl;
cout << setfill('-') << setw(90) << "-" << endl;
for (i = 0; i < N; i++)
{
cout << setfill(' ') << setw(18) << right << alpha[i];
cout << setfill(' ') << setw(18) << right << sinres[i];
cout << setfill(' ') << setw(18) << right << sinRef[i];
cout << setfill(' ') << setw(18) << right << cosres[i];
cout << setfill(' ') << setw(18) << right << cosRef[i];
if (abs(float(sinres[i] - sinRef[i])) > precision)
{
ErrCntSin++;
cout << setfill(' ') << setw(18) << right << "(sin failed)";
}
if (abs(float(cosres[i] - cosRef[i])) > precision)
{
ErrCntCos++;
cout << setfill(' ') << setw(18) << right << "(cos failed)";
}
cout << endl;
}
cout << setfill('-') << setw(90) << "-" << endl;
if (ErrCntSin + ErrCntCos == 0)
{
cout << "Test passed!" << endl;
return 0;
}
else
{
cout << "Test failed!" << endl;
cout << "sin failed: " << ErrCntSin << endl;
cout << "cos failed: " << ErrCntCos << endl;
return 1;
}
}
2.2.案例优化
对案例程序进行综合,得到Performance结果,注意新版本的Vitis已经自动打上了PIPELINE,旧版本可能比这要慢:

现在创建一个新的solution,给代码中打了loop标签的循环设置PIPELINE或UNROLL。
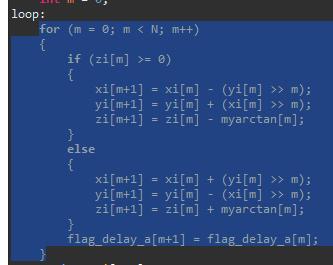
这里原教程是两个一块打开,我发现会报错冲突,因此我分别对这个循环测试了PIPELINE和UNROLL的优化结果。
单独开启PIPELINE的结果,因为默认也是打开的,所以没变化:

单独开启UNROLL的结果,latency大幅降低,同时很明显的LUT使用量也变高:

接下来我们在开启UNROLL的基础上创建新solution,在对循环UNROLL的同时,给top函数打上PIPELINE:
会发现interval进一步变为了1:

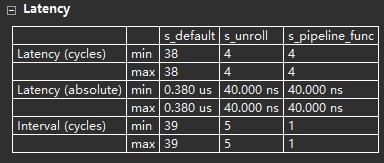
对比三次结果:
原文地址:https://blog.csdn.net/qq_38876396/article/details/143683331
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!