Spring中Bean的循环依赖
目录
定义:
一个或多个Bean之间存在相互调用关系就会产生循环依赖。即:A调用B,B调用C,C调用A,这样会导致创建对象时依赖链过长,栈溢出。

循环依赖的后果:
环依赖可能会导致程序出现各种问题,比如编译错误、运行时错误、死锁等。因此,避免循环依赖是编写高质量软件的重要方面之一。
Spring为了解决循环依赖问题,引入了三级缓存,Bean的生命周期中我们可以知道Bean在实例化的时候会通过Bean的构造函数来实例化Bean和进行属性填充,所以就要在这一步之前对Bean进行一些操作。
一:三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解,要不然后面看代码会蒙圈。
第一级缓存 :singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例;
第二级缓存 :earlySingletonObjects,用于保存实例化完成的 bean 实例;
第三级缓存 :singletonFactories,用于保存 bean 创建工厂,以便后面有机会创建代理对象。
这是最核心
执行逻辑为:
1、先从“第一级缓存”找对象a,有就返回,没有就找“二级缓存”;
2、找“二级缓存”,有就返回,没有就找“三级缓存”;
3、找“三级缓存”,a找到了,就获取对象,放到“二级缓存”,并把a从“三级缓存”移除。
下面是Bean中的三级缓存的过程源码:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
// 从一级缓存中获取
// 如果一级缓存里没有,且 Bean 正在创建中
// 就从二级缓存里获取
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存没有,就从三级缓存获取一个工厂
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full sin
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 能获取到工厂则创建 Bean
singletonObject = singletonFactory.getObject();
// 把实例存入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 把工厂从三级缓存移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
1、大概的思路:
当我们需要创建 A 的的时候,会首先通过 Java 反射创建出来一个原始的 A,这个原始 A 可以简单理解为刚刚 new 出来还没设置任何属性的 A,此时,我们把这个 A 先存入到一个缓存池中。接下来给 A 的属性设置值和解决A A 的依赖,这时我们发现 A 依赖 B,那么就去创建 B 对象,结果创建 B 的时候,发现 B 依赖 A,那么此时就先从缓存池中取出来 A(半成品A,啥属性也没有) 先用着,然后继续 B 创建的后续流程,直到 B 创建完成后,将之赋值给 A,此时 A 和 B 就都创建完成了。
如下图:
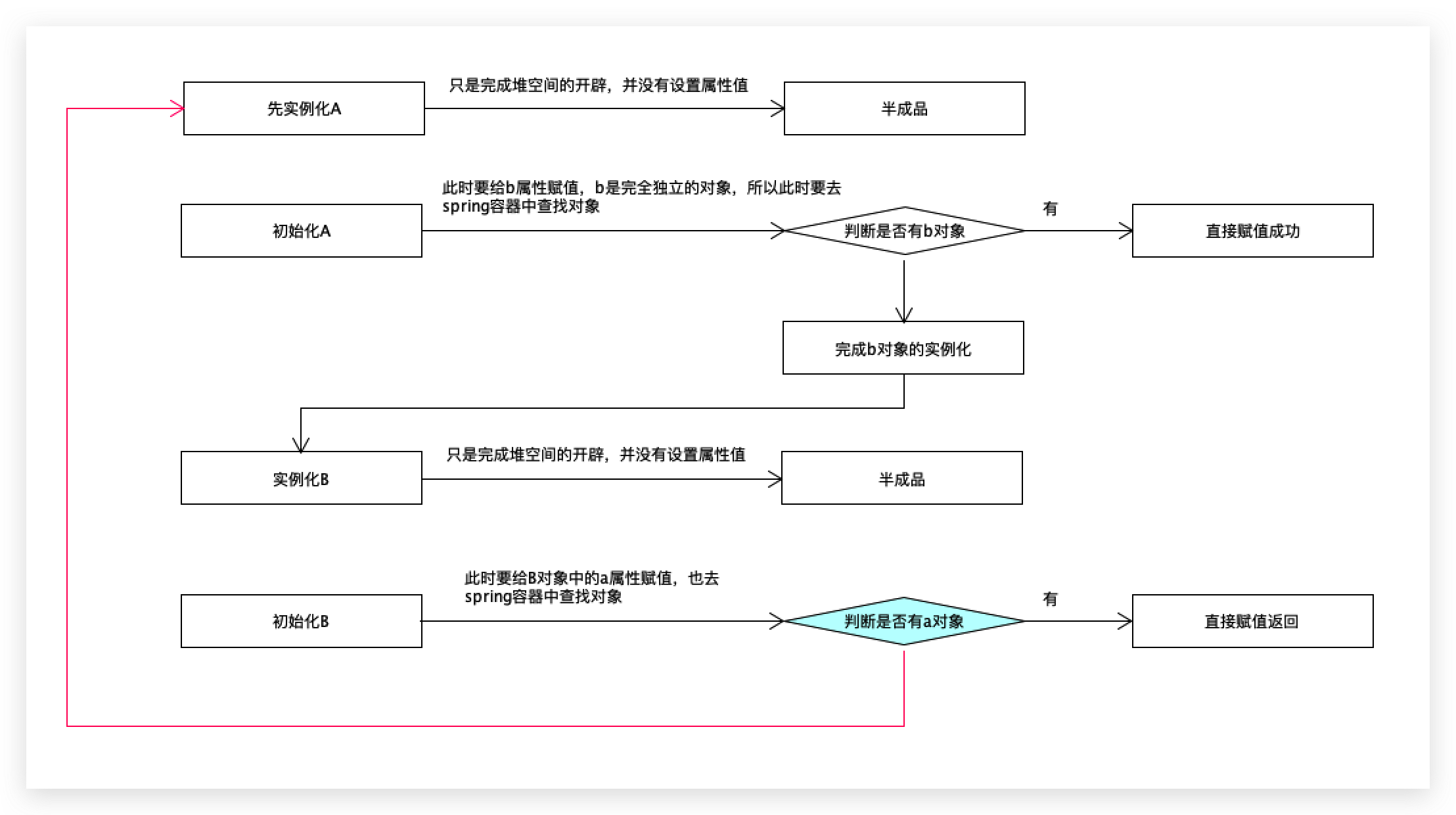
注意:
这里拿到的半成品A是个引用对象,也就是说它是个地址,所以即使里面的属性赋值都没有做也没关系,后面运行调用时拿到的就是完整的A
2、执行过程:
A半完成:
我们在创建A的时候,会通过反射创建出原始的A,接下来检查一缓存中有没有Bean,如果没有,则首先向三级缓存中添加一条记录,记录的 key 就是当前 Bean 的 beanName,value 则是一个 Lambda 表达式 ObjectFactory,通过执行这个 Lambda 可以给当前 A 生成代理对象。然后如果二级缓存中存在当前 A Bean,则移除掉。
B完成:
这样,A的前半部分就完成了,接下来给A的各个属性赋值,赋值时发现需要B,就去创建B,B和A一样,经历到给属性赋值的阶段,发现需要A,就去一级缓存找A,找不到就去二级缓存,再去三级缓存,找到A的ObjectFactory,然后执行这里的 getObject 方法,这个方法在执行的过程中,会去判断是否需要生成一个代理对象,如果需要就生成代理对象返回,如果不需要生成代理对象,则将原始对象返回即可。
最后,把拿到手的对象存入到二级缓存中以备下次使用,同时删除掉三级缓存中对应的数据。这样 A 所依赖的 B 就创建好了。
A完成:
再去完善B,属性赋值,A也就完成了。
注:
这里的解决思路需要在有AOP的情况下才可以,这里的Bean有ObjectFactory对象,否则就只能用二级缓存来解决。
二级缓存的解决大体思路是一样的,不过要把A的半成品存放在二级缓存中,这样可以更早的被调用。
二:@Lazy
延迟加载可以通过将 bean 的依赖关系运行时进行注入,而不是在初始化阶段
@Service
public class AserviceImpl implements Aservice {
@Autowired
@Lazy
private Bservice bservice;
@Async
public void test(){
}
}
Lazy 延迟加载打破循环依赖,他会通过其它途径生成bservice 的lazy 的代理对象,不会去走创建B 的代理 对象 然后注入A 这套流程。这样创建A 的单例对象并放入到单例池中,B 的bean 在实例化后,注入A bean 属性就可以从单例池中加载到A 的真正的bean ,而不会出现bean 对象不一致的问题。
原文地址:https://blog.csdn.net/qq_64669006/article/details/140595476
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!