[阅读笔记21][RA-CM3]Retrieval-Augmented Multimodal Language Modeling

这篇论文是meta联合斯坦福在23年4月发表的论文,提出了一个使用外部知识检索增强的多模态模型。
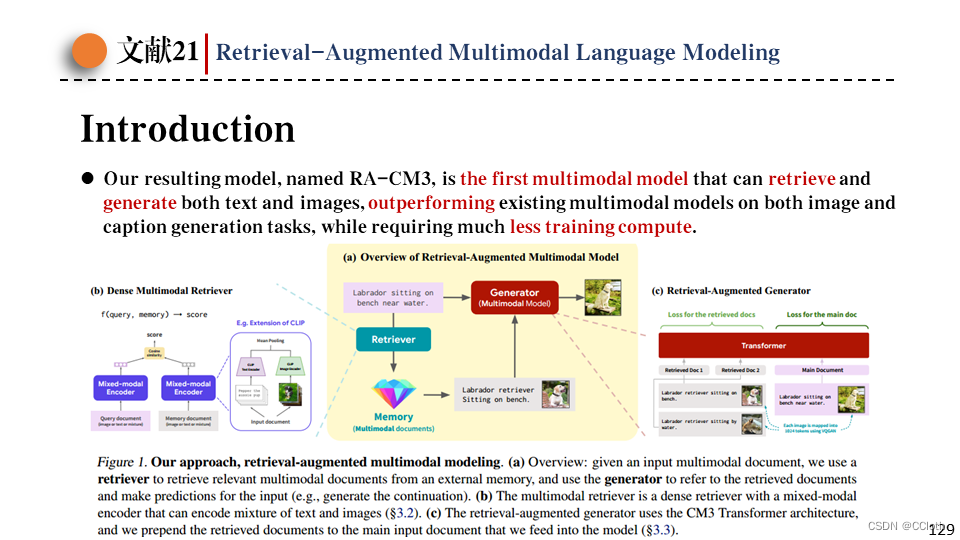
这篇模型提出的RA-CM3模型是第一个能够检索并生成图像文本的多模态模型,在图像文本生成任务上优于现有的多模态模型,同时使用更少的训练量。
RA-CM3从结构上可以分为两大块,一块是检索器,一块是生成器。下图是整体的流程,对于一个给定的caption,要生成它对应的图像,可以先使用多模态检索器从外部存储中检索出若干相似的图文对,然后把这些图文对和一开始的caption输入生成器中,由生成器生成预测出来的图像。

第一部分是检索器的结构,对于一个询问q和候选文档m(其实就是图文对),用下面的公式计算它们的相关性得分,其中Eq是q的编码器,Em是m的编码器。由于这里的询问和文档都是多模态信息,所以编码器也应该是多模态编码器,这里作者选用冻结的CLIP,然后再平均一下这两个向量,并缩放至向量长度为1,这时候该向量就是多模态信息的表示向量了。
然后使用最大内积搜索,获得按照相关性得分排序的候选文档列表,然后在该列表中采样k个文档。
接下来作者讨论了一下检索过程中最关键的三个因素:相关性、多模态、多样性。
相关性指的是检索结果要和输入序列相关,不然检索出来的信息是没有用的。
多模态指的是这里检索出来的是多模态信息,与以往只检索单模态不太一样,通过消融实验证明多模态信息对后续生成器有正向帮助,毕竟这里文本和图像是关联的,多模态文档的信息量更大。
多样性指的是检索出来的信息应该尽量不重复,如果简单取topk相关的k个文档,那么多样性就很很差,导致生成器性能也很差。作者对此有两个改进,第一个改进是跳过跟query或已检索到的文档相似度特别高的候选文档,这个改进称之为Avoid Redundancy。第二个改进是Query Dropout,顾名思义就是对query进行dropout,随机丢弃query中20%的token。这样query转为向量后,即使取最相似的几个文档也跟原始的query没那么相似了。

接下来是第二部分,生成器的设计。作者沿用了CM3作为生成器,然后输入的时候之前检索到的文档作为上下文拼接起来一起输入,然后损失函数分两部分,一部分是当前样本的,还有一部分是检索出来的文档的,文档那部分有个系数可以调,论文里说一般取0.1。目前的检索增强模型都只计算当前样本的损失,作者这里加入检索样本的损失是因为反正都会被算一遍,不如顺手加上,而且这还相当于扩大了batchsize,又不需要引入太多额外的计算。

接下来是训练过程,训练用的数据集来自LAION的一个子集,经过清洗后得到150M文本对,然后沿用CM3中数据的格式,将图文对转成html文档,然后外部知识库同样使用这150M的数据。训练时在检索的时候要么用图像,要么用文本,如果直接用图文对那对于模型来说预测可能会变得很容易,另外这和推理时行为也不一致。
然后是RA-CM3的结果展示,左图是在COCO数据集上图像生成的性能对比,可以看到基本上优于大部分自回归的模型,并且参数量非常少。右边是图像生成质量和训练计算量的图,RA-CM3在自回归模型中取得了更好的训练效率。

左边是文生图的结果,右边是涉及一些罕见的或者说是不存在的场景生成。例如法国国旗插在月球上,没有检索能力的模型很难生成符合要求的图像。
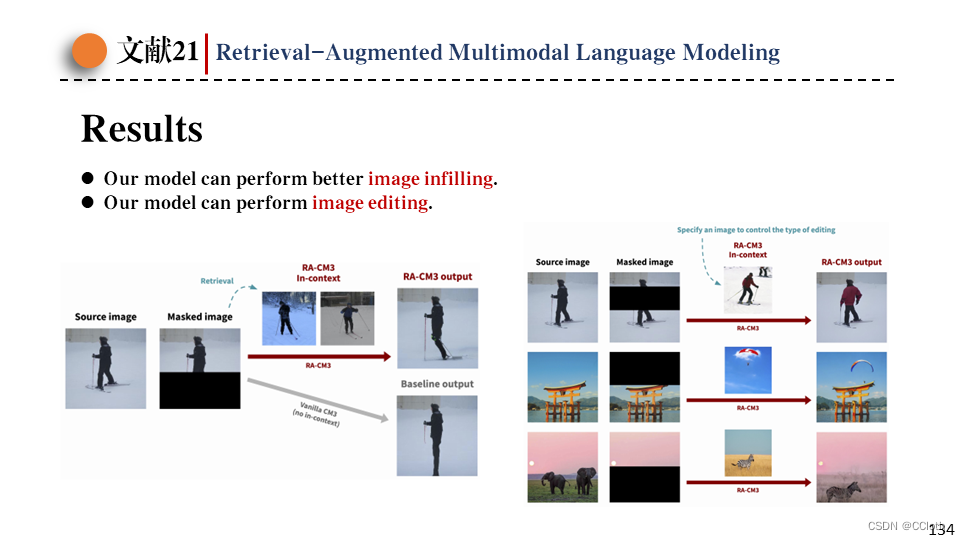
接下来是图像填充的结果,左图预测的时候使用检索出来的样本作为上下文,直观感受上要比baseline好不少。右图预测的时候没用检索,因为检索出来的也是放到prompt里,所以自然可以手动把需要的图放到prompt中,代替检索的结果,这样就能达到一种图像编辑的效果。
原文地址:https://blog.csdn.net/m0_55982600/article/details/138010394
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!