Bert基础(四)--解码器(上)
1 理解解码器
假设我们想把英语句子I am good(原句)翻译成法语句子Je vais bien(目标句)。首先,将原句I am good送入编码器,使编码器学习原句,并计算特征值。在前文中,我们学习了编码器是如何计算原句的特征值的。然后,我们把从编码器求得的特征值送入解码器。解码器将特征值作为输入,并生成目标句Je vais bien,如下图所示。
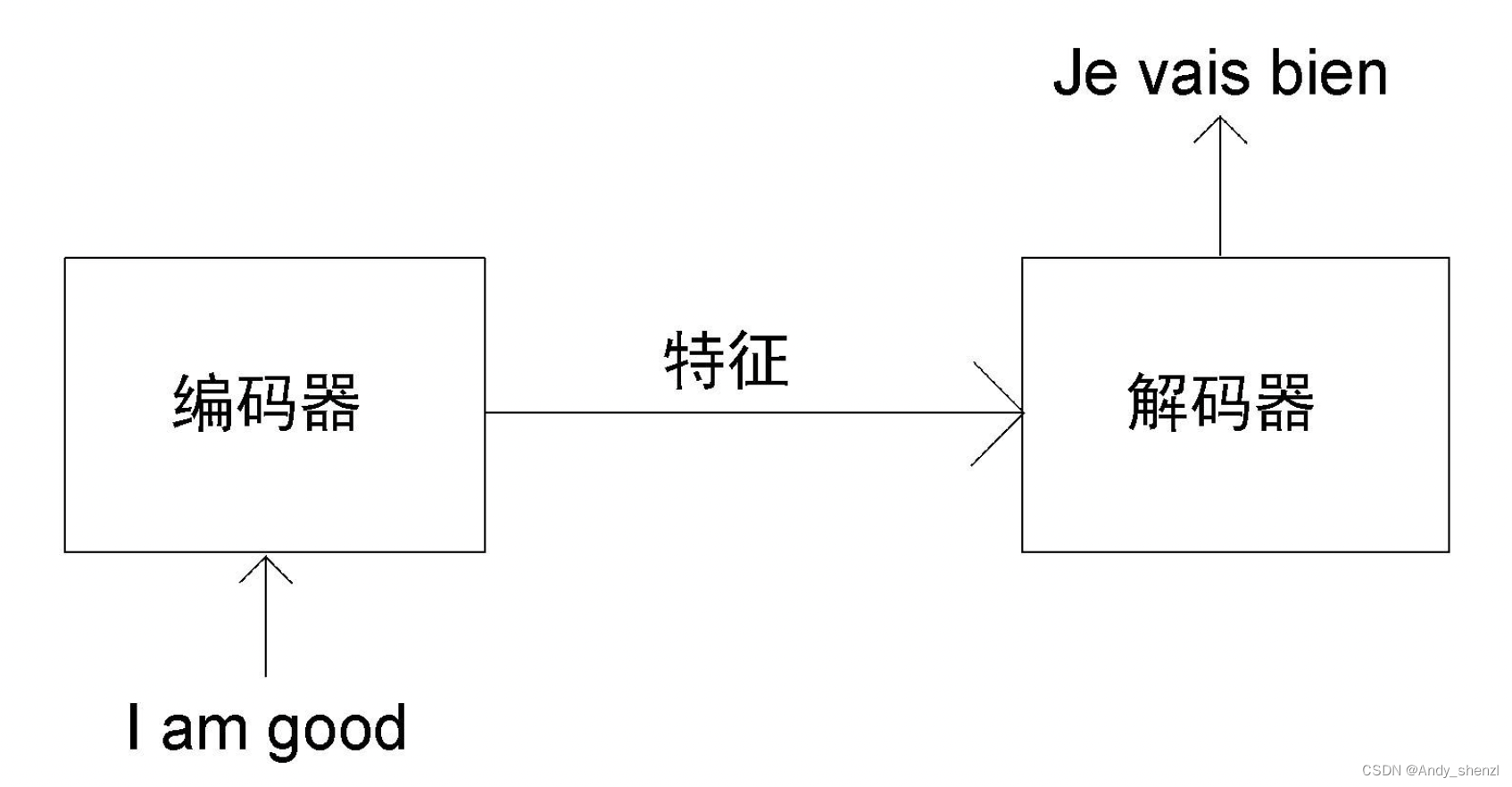
在编码器部分,我们了解到可以叠加N个编码器。同理,解码器也可以有N个叠加在一起。为简化说明,我们设定N=2。如图所示,一个解码器的输出会被作为输入传入下一个解码器。我们还可以看到,编码器将原句的特征值(编码器的输出)作为输入传给所有解码器,而非只给第一个解码器。因此,一个解码器(第一个除外)将有两个输入:一个是来自前一个解码器的输出,另一个是编码器输出的特征值。

2 工作步骤
接下来,我们学习解码器究竟是如何生成目标句的。当
t
=
1
t=1
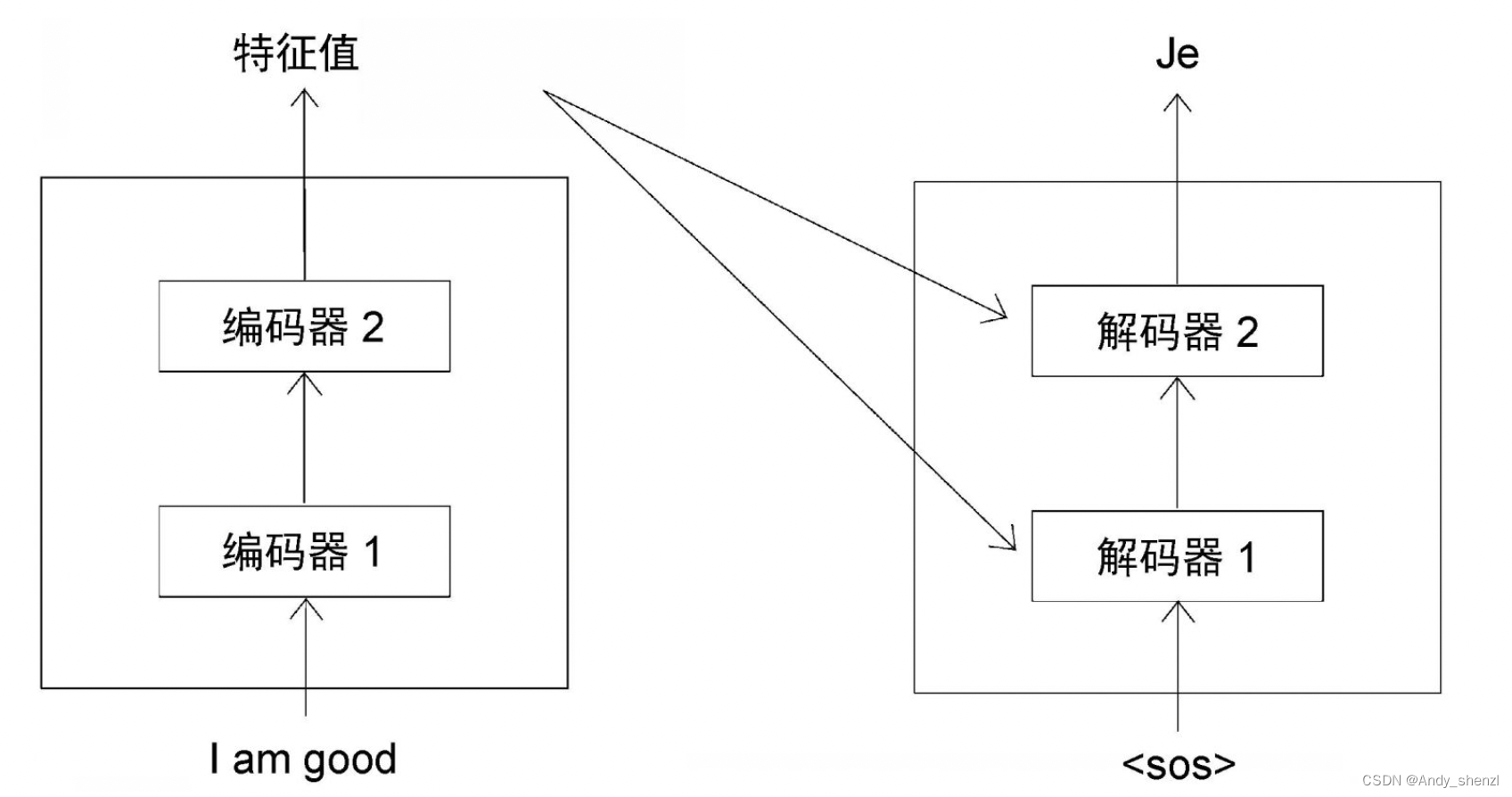
t=1时(t表示时间步),解码器的输入是<sos>,这表示句子的开始。解码器收到<sos>作为输入,生成目标句中的第一个词,即Je,如图所示。
当
t
=
2
t=2
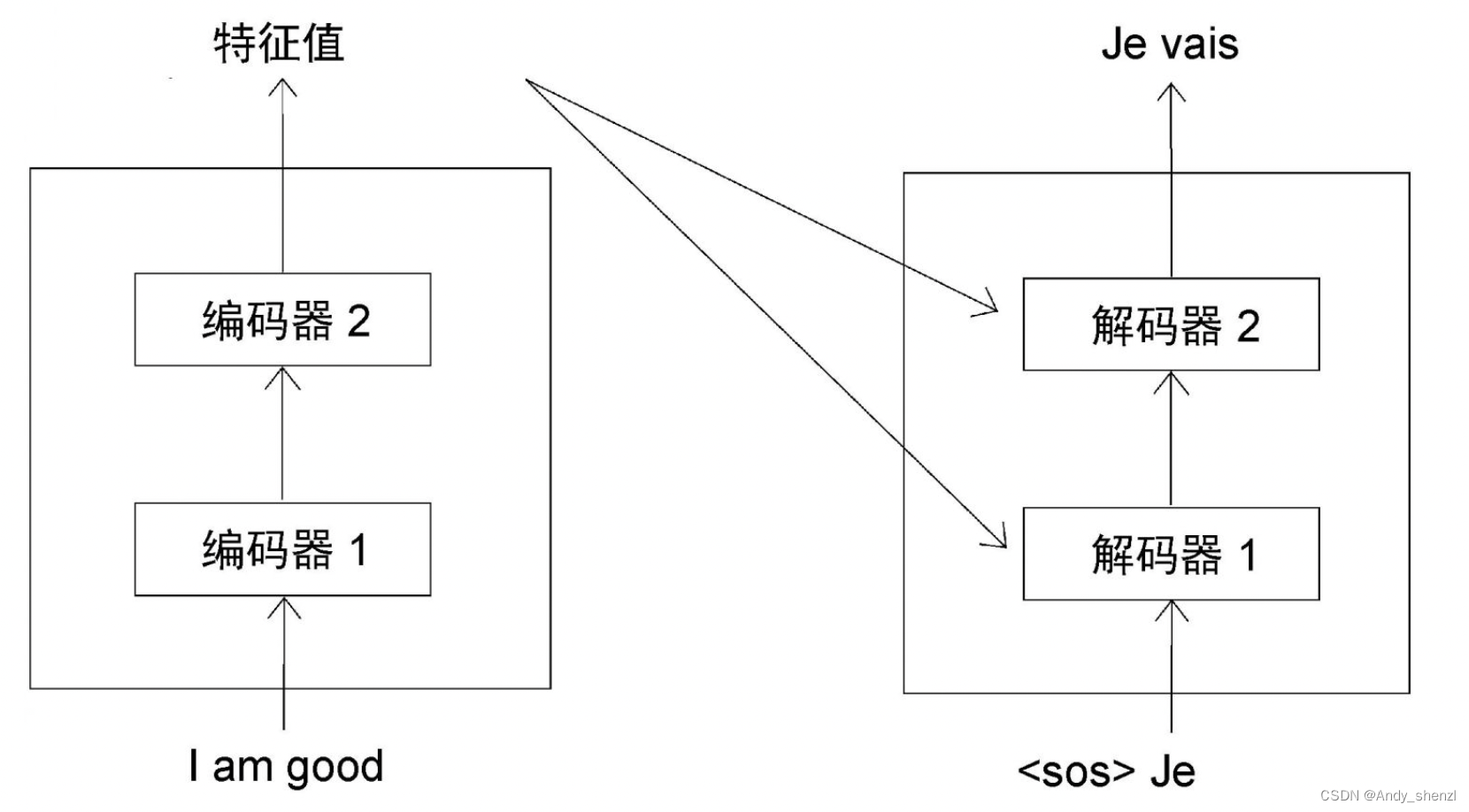
t=2时,解码器使用当前的输入和在上一步(
t
=
1
t=1
t=1)生成的单词,预测句子中的下一个单词。在本例中,解码器将<sos>和Je(来自上一步)作为输入,并试图生成目标句中的下一个单词,如图所示。
同理,可以推断出解码器在
t
=
3
t=3
t=3时的预测结果。此时,解码器将<sos>、Je和vais(来自上一步)作为输入,并试图生成句子中的下一个单词,如图所示

在每一步中,解码器都将上一步新生成的单词与输入的词结合起来,并预测下一个单词。因此,在最后一步(
t
=
4
t=4
t=4),解码器将<sos>、Je、vais和bien作为输入,并试图生成句子中的下一个单词,如图所示。
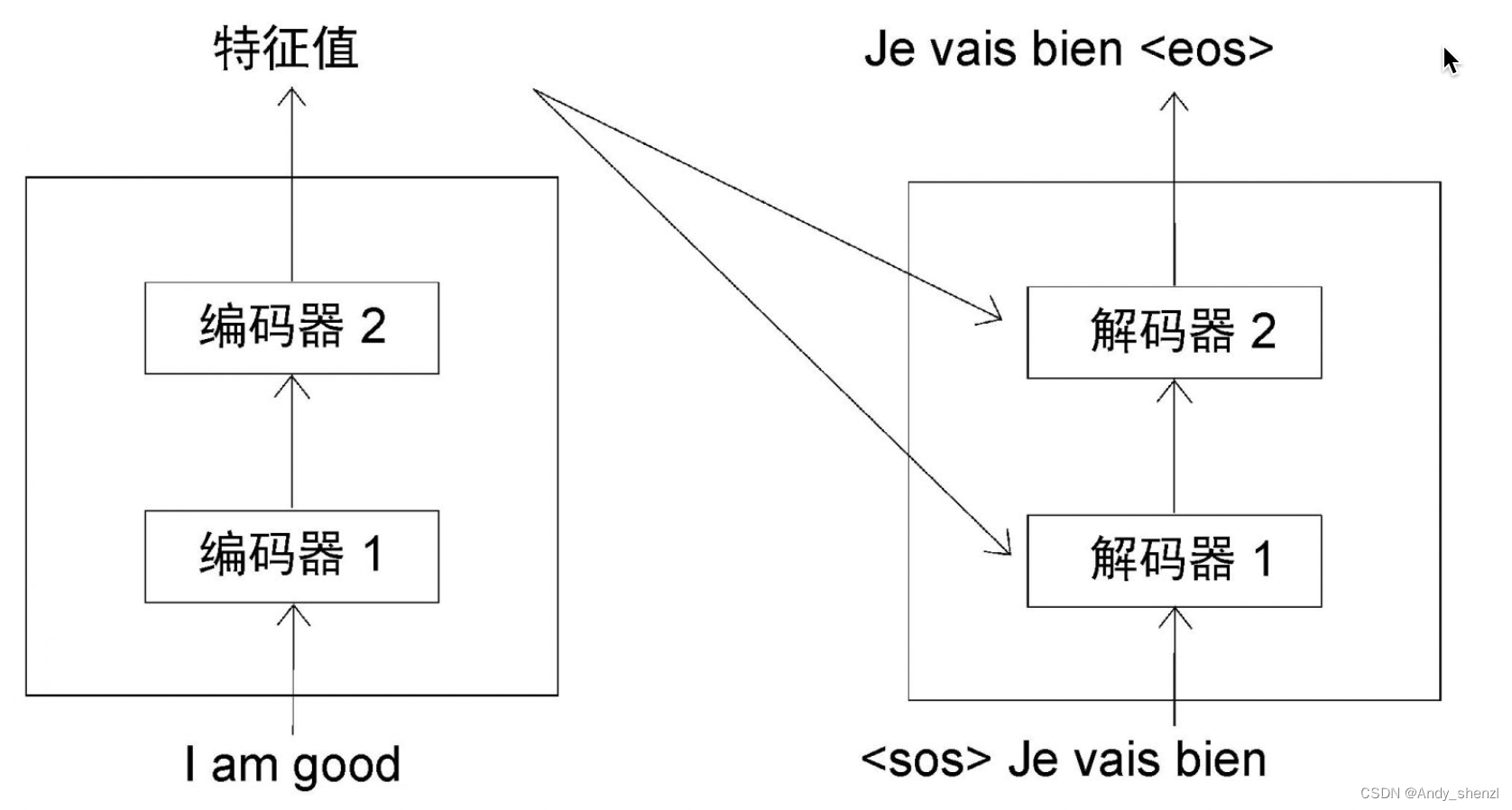
从上图中可以看到,一旦生成表示句子结束的<eos>标记,就意味着解码器已经完成了对目标句的生成工作。
3 位置编码
在编码器部分,我们将输入转换为嵌入矩阵,并将位置编码添加到其中,然后将其作为输入送入编码器。同理,我们也不是将输入直接送入解码器,而是将其转换为嵌入矩阵,为其添加位置编码,然后再送入解码器。
如下图所示,假设在时间步
t
=
2
t=2
t=2,我们将输入转换为嵌入(我们称之为嵌入值输出,因为这里计算的是解码器在以前的步骤中生成的词的嵌入),将位置编码加入其中,然后将其送入解码器。

接下来,让我们深入了解解码器的工作原理。一个解码器模块及其所有的组件如图:
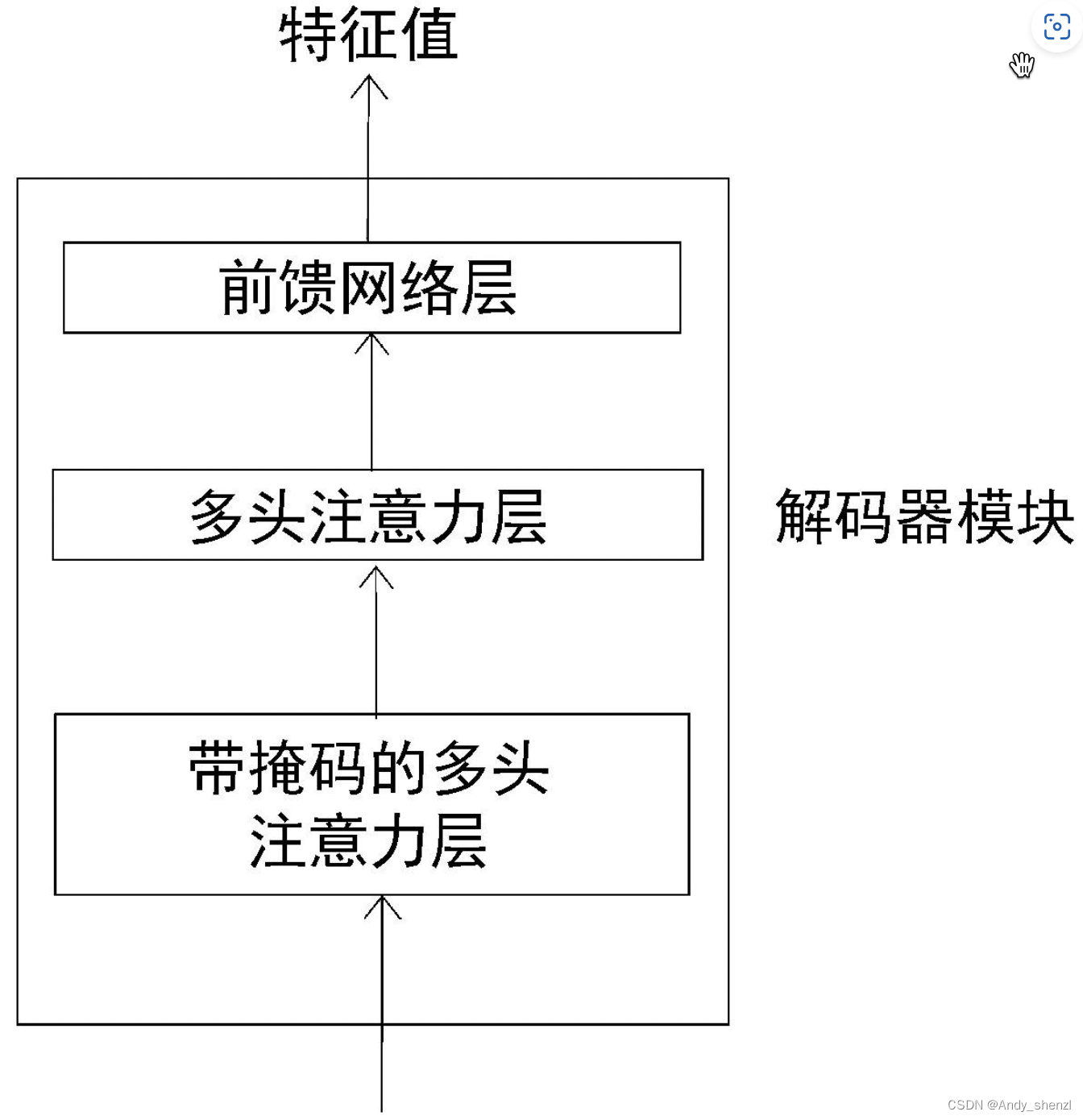
从图中可以看到,解码器内部有3个子层。
- 带掩码的多头注意力层
- 多头注意力层
- 前馈网络层
与编码器模块相似,解码器模块也有多头注意力层和前馈网络层,但多了带掩码的多头注意力层。现在,我们对解码器有了基本的认识。接下来,让我们先详细了解解码器的每个组成部分,然后从整体上了解它的工作原理。
4 带掩码的多头注意力层
以英法翻译任务为例,假设训练数据集样本如图所示

数据集由两部分组成:原句和目标句。在前面,我们学习了解码器在测试期间是如何在每个步骤中逐字预测目标句的。
在训练期间,由于有正确的目标句,解码器可以直接将整个目标句稍作修改作为输入。解码器将输入的<sos>作为第一个标记,并在每一步将下一个预测词与输入结合起来,以预测目标句,直到遇到<eos>标记为止。因此,我们只需将<sos>标记添加到目标句的开头,再将整体作为输入发送给解码器。
比如要把英语句子I am good转换成法语句子Je vais bien。我们只需在目标句的开头加上<sos>标记,并将<sos>Je vais bien作为输入发送给解码器。解码器将预测输出为Je vais bien<eos>,如图所示。

为什么我们需要输入整个目标句,让解码器预测位移后的目标句呢?下面来解答。
首先,我们不是将输入直接送入解码器,而是将其转换为嵌入矩阵(输出嵌入矩阵)并添加位置编码,然后再送入解码器。假设添加输出嵌入矩阵和位置编码后得到图所示的矩阵X。

然后,将矩阵X送入解码器。解码器中的第一层是带掩码的多头注意力层。这与编码器中的多头注意力层的工作原理相似,但有一点不同。
为了运行自注意力机制,我们需要创建三个新矩阵,即查询矩阵Q、键矩阵K和值矩阵V。由于使用多头注意力层,因此我们创建了h个查询矩阵、键矩阵和值矩阵。对于注意力头 i i i的查询矩阵 Q i Q_i Qi、键矩阵 K i K_i Ki和值矩阵 V i V_i Vi,可以通过将X分别乘以权重矩阵 W i Q , W i K , W i V W_i^Q, W_i^K, W_i^V WiQ,WiK,WiV而得。
下面,让我们看看带掩码的多头注意力层是如何工作的。假设传给解码器的输入句是<sos>Je vais bien。我们知道,自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。但这里有一个小问题。在测试期间,解码器只将上一步生成的词作为输入。
比如,在测试期间,当
t
=
2
t=2
t=2时,解码器的输入中只有[<sos>, Je],并没有任何其他词。因此,我们也需要以同样的方式来训练模型。模型的注意力机制应该只与该词之前的单词有关,而不是其后的单词。要做到这一点,我们可以掩盖后边所有还没有被模型预测的词。
比如,我们想预测与<sos>相邻的单词。在这种情况下,模型应该只看到<sos>,所以我们应该掩盖<sos>后边的所有词。再比如,我们想预测Je后边的词。在这种情况下,模型应该只看到Je之前的词,所以我们应该掩盖Je后边的所有词。其他行同理,如图所示。

像这样的掩码有助于自注意力机制只注意模型在测试期间可以使用的词。但我们究竟如何才能实现掩码呢?我们学习过对于一个注意力头
Z
1
Z_1
Z1的注意力矩阵[插图]的计算方法,公式如下。
Z
i
=
s
o
f
t
m
a
x
(
Q
i
⋅
K
i
T
d
k
)
V
i
Z_i = softmax(\frac{Q_i·K_i^T}{\sqrt{d_k}})V_i
Zi=softmax(dkQi⋅KiT)Vi
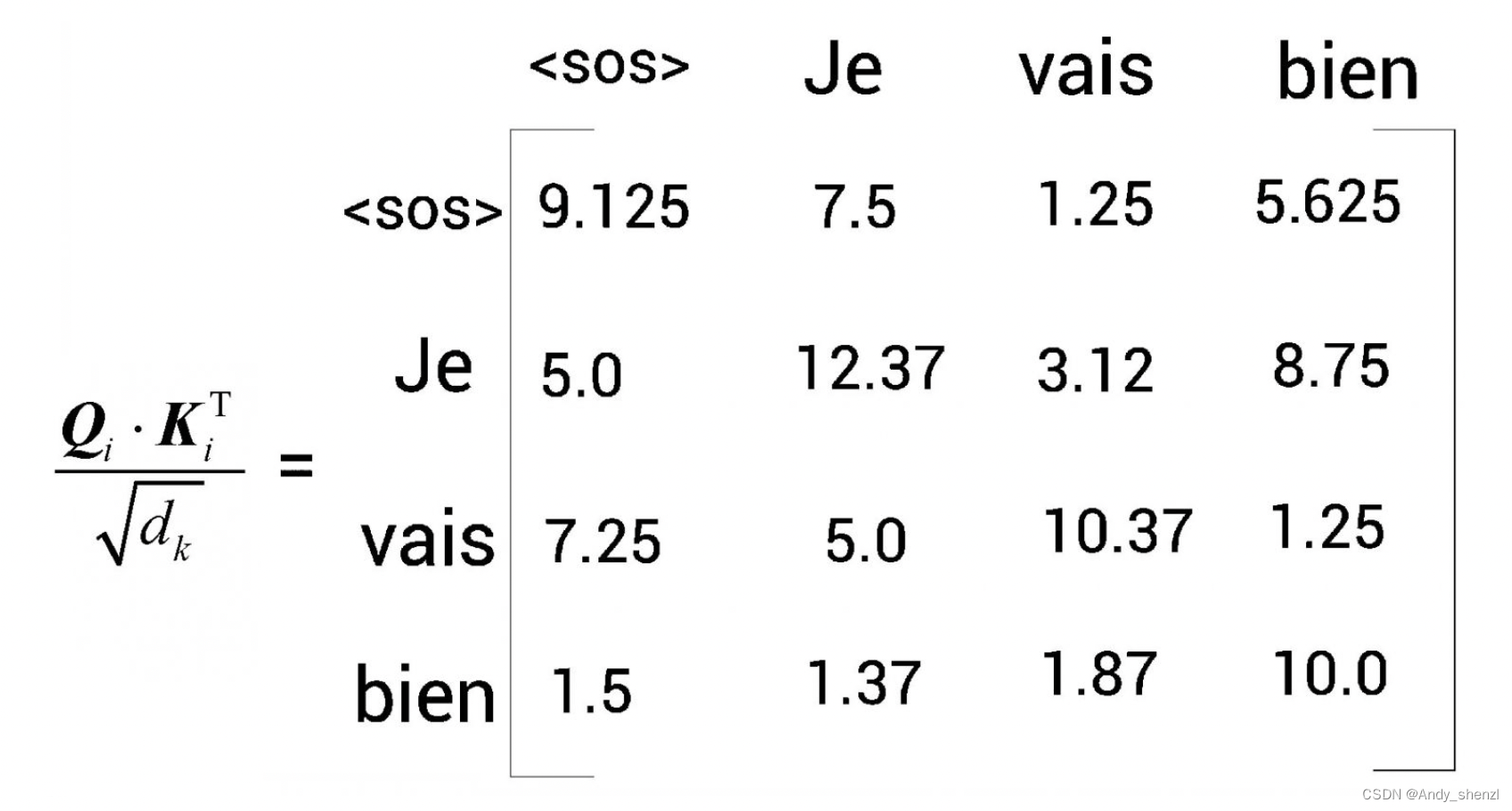
计算注意力矩阵的第1步是计算查询矩阵与键矩阵的点积。下图显示了点积结果。需要注意的是,这里使用的数值是随机的,只是为了方便理解。

第二步是将
Q
i
⋅
K
i
T
Q_i·K_i^T
Qi⋅KiT矩阵除以键向量维度的平方根
d
k
\sqrt{d_k}
dk。假设下图是
Q
i
⋅
K
i
T
/
d
k
Q_i·K_i^T/\sqrt{d_k}
Qi⋅KiT/dk的结果。
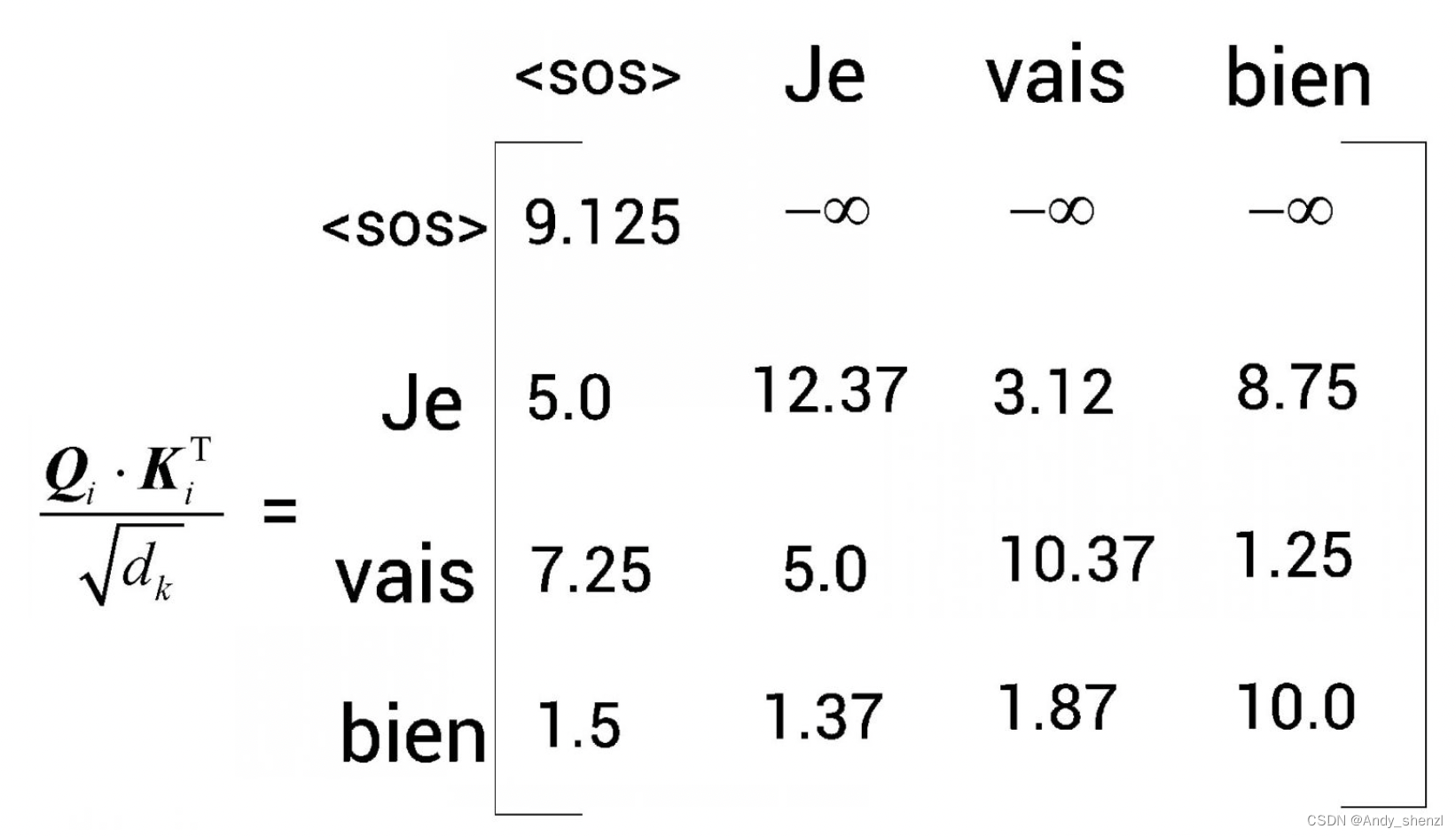
第3步,我们对上图所得的矩阵应用softmax函数,并将分值归一化。但在应用softmax函数之前,我们需要对数值进行掩码转换。以矩阵的第1行为例,为了预测<sos>后边的词,模型不应该知道<sos>右边的所有词(因为在测试时不会有这些词)。因此,我们可以用
−
∞
- \infty
−∞掩盖<sos>右边的所有词,如图所示。
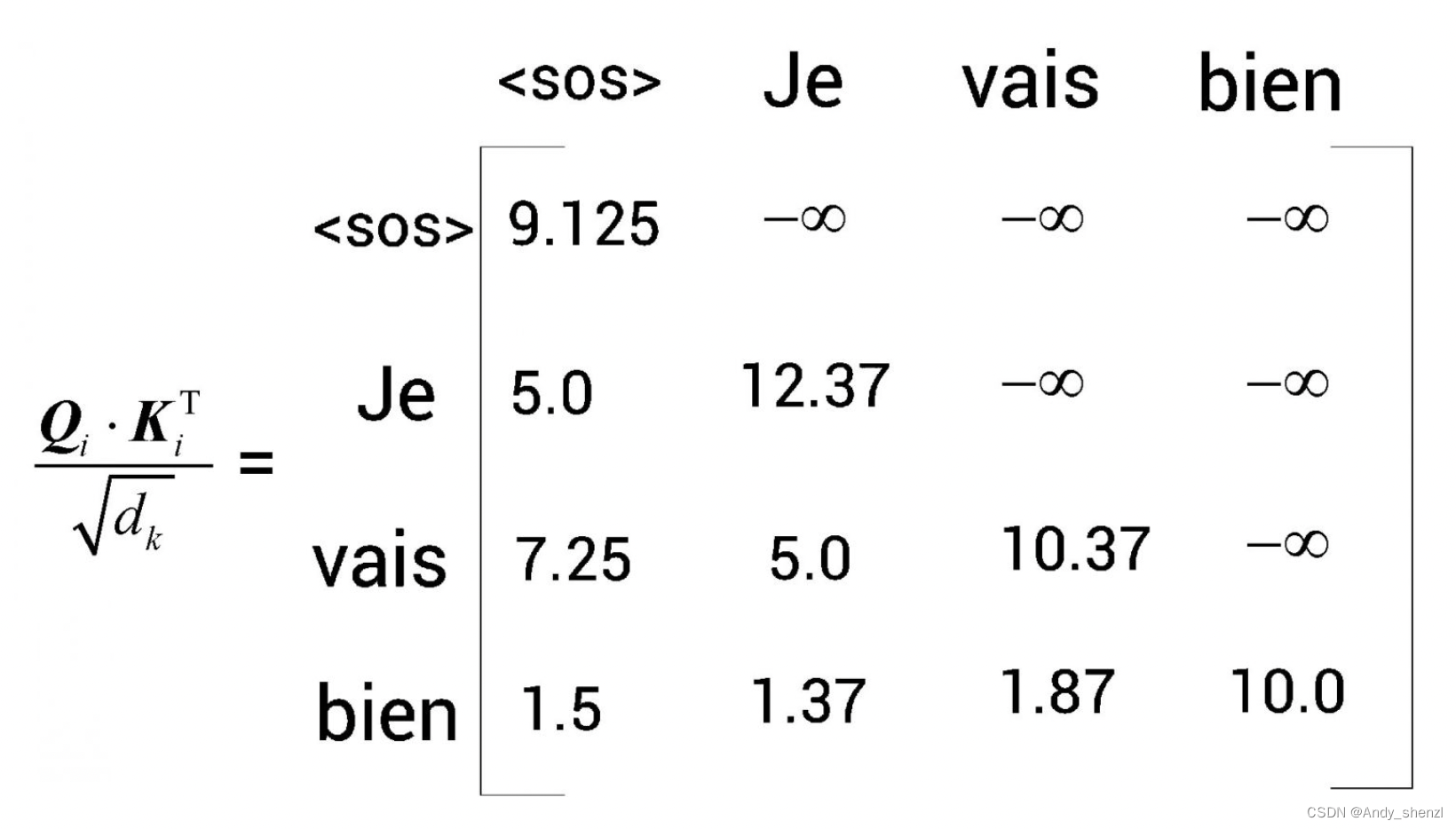
接下来,让我们看矩阵的第2行。为了预测Je后边的词,模型不应该知道Je右边的所有词(因为在测试时不会有这些词)。因此,我们可以用
−
∞
- \infty
−∞掩盖Je右边的所有词,如图所示。

同理,我们可以用
−
∞
- \infty
−∞掩盖vais右边的所有词,如图所示。
现在,我们可以将softmax函数应用于前面的矩阵,并将结果与值矩阵
V
i
V_i
Vi相乘,得到最终的注意力矩阵
Z
i
Z_i
Zi。同样,我们可以计算h个注意力矩阵,将它们串联起来,并将结果乘以新的权重矩阵
W
0
W_0
W0,即可得到最终的注意力矩阵M,如下所示
M
=
C
o
n
c
a
t
e
n
a
t
e
(
Z
1
,
Z
2
,
…
…
,
Z
h
)
W
0
M = Concatenate(Z_1, Z_2,……,Z_h)W_0
M=Concatenate(Z1,Z2,……,Zh)W0
最后,我们把注意力矩阵M送到解码器的下一个子层,也就是另一个多头注意力层。
待更。。。
原文地址:https://blog.csdn.net/Andy_shenzl/article/details/136215383
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!