MYSQL数据库连接池 | C++ | 项目实战
MYSQL数据库连接池 | C++ | 项目实战
笔记通过施磊老师C++数据库连接池项目写出,供自己复习与大家参考
文章目录
1.项目可以实现什么
为了提高MySQL数据库(基于C/S设计)的访问瓶颈,除了在服务器端增加缓存服务器缓存常用的数据
之外(例如redis),还可以增加连接池,来提高MySQL Server的访问效率,在高并发情况下,大量的
TCP三次握手、MySQL Server连接认证、MySQL Server关闭连接回收资源和TCP四次挥手 所耗费的
性能时间也是很明显的,增加连接池就是为了减少这一部分的性能损耗。
2.项目技术点有哪些
MySQL数据库编程、单例模式、queue队列容器、C++11多线程编程、线程互斥、线程同步通信和
unique_lock、基于CAS的原子整形、智能指针shared_ptr、lambda表达式、生产者-消费者线程模型
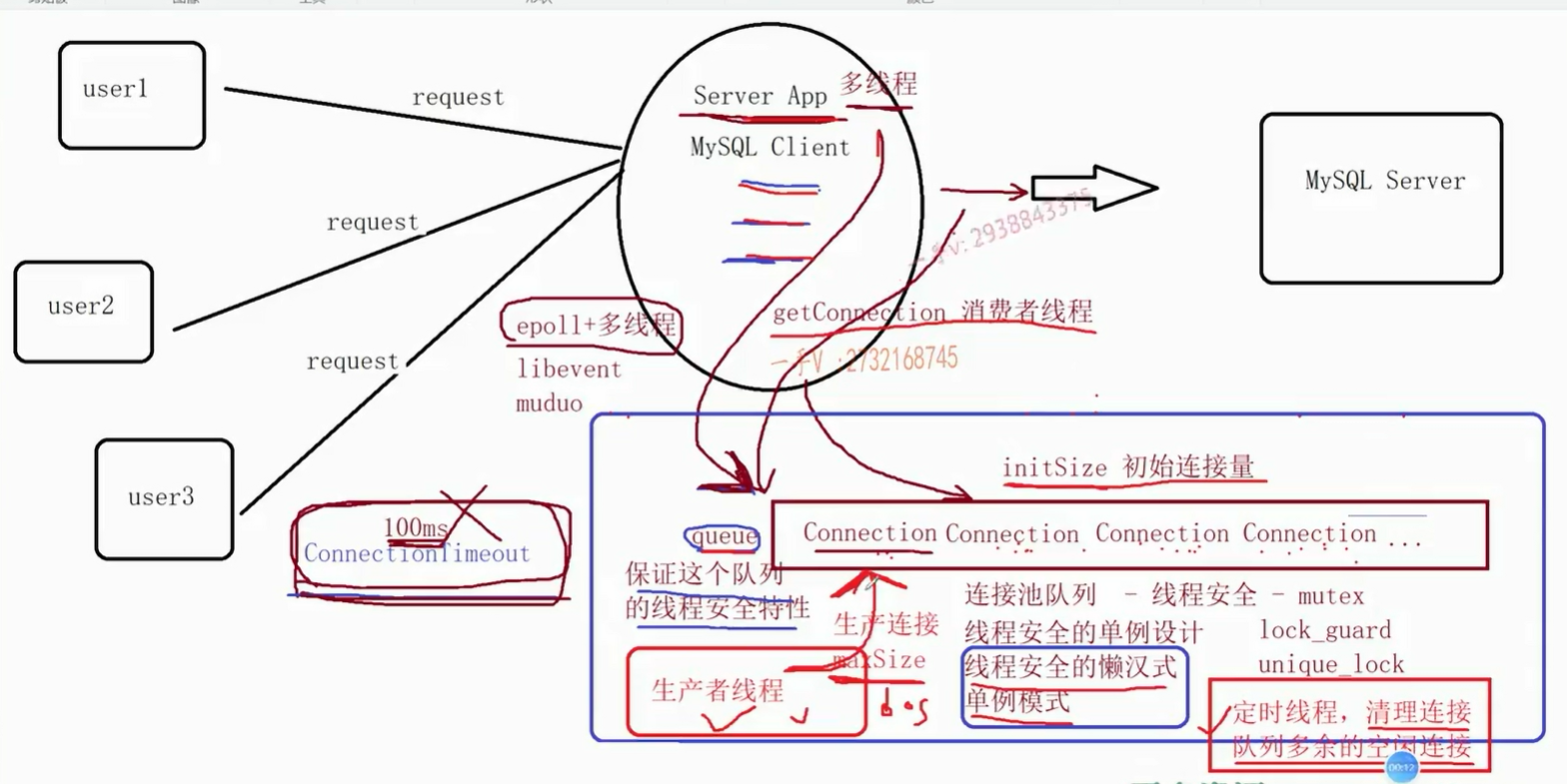
3.连接池功能点介绍
连接池科普
如果有人不太清楚数据库连接池的话可以简单科普一下:
连接池一般是在客户端而不是服务器端,在客户端复用已经创建的数据库连接,避免性能损耗。
有人可能疑惑:我就一个用户也就用一条连接也就够了吧?还用什么连接池
例子:QQ 客户端的并发场景
假设你在使用 QQ 时,虽然你是唯一的用户,但客户端会发起多个不同的操作:
- 线程 1:在后台更新聊天消息记录,向数据库读取历史消息。
- 线程 2:实时显示你在某个群中的聊天内容,同时写入数据库。
- 线程 3:正在处理你发送的一条语音消息,将其上传并存储到数据库中。
- 线程 4:后台任务正在从好友服务器同步最新的好友列表,并把数据写入数据库。
每个线程都可能需要独立的数据库连接来完成操作,所以连接池在这种场景下就会显得十分重要,它能有效管理多个并发连接,而不需要频繁创建和关闭连接。
具体功能点
连接池一般包含了数据库连接所用的ip地址、port端口号、用户名和密码以及其它的性能参数,例如初始连接量,最大连接量,最大空闲时间、连接超时时间等,该项目是基于C++语言实现的连接池,主要也是实现以上几个所有连接池都支持的通用基础功能。
初始连接量(initSize) :表示连接池事先会和MySQL Server创建initSize个数的connection连接,当应用发起MySQL访问时,不用再创建和MySQL Server新的连接,直接从连接池中获取一个可用的连接就可以,使用完成后,并不去释放connection,而是把当前connection再归还到连接池当中。
最大连接量(maxSize) :当并发访问MySQL Server的请求增多时,初始连接量已经不够使用了,此时会根据新的请求数量去创建更多的连接给应用去使用,但是创建的连接数量上限是maxSize,不能无限制的创建连接,因为每一个连接都会占用一个socket资源,一般连接池和服务器程序是部署在一台主机上的,如果连接池占用过多的socket资源,那么服务器就不能接收太多的客户端请求了。当这些连接使用完成后,再次归还到连接池当中来维护。
最大空闲时间(maxIdleTime) :当访问MySQL的并发请求多了以后,连接池里面的连接数量会动态增加,上限是maxSize个,当这些连接用完再次归还到连接池当中。如果在指定的maxIdleTime里面,这些新增加的连接都没有被再次使用过,那新增加的这些连接资源就要被回收掉,只需要保持初始连接量initSize个连接就可以了。
连接超时时间(connectionTimeout) :当MySQL的并发请求量过大,连接池中的连接数量已经到达maxSize了,而此时没有空闲的连接可供使用,那么此时应用从连接池获取连接无法成功,它通过阻塞的方式获取连接的时间如果超过connectionTimeout时间,那么获取连接失败,无法访问数据库。
该项目主要实现上述的连接池四大功能,其余连接池更多的扩展功能,可以自行实现。
4.MySQL Server参数介绍
mysql> show variables like ‘max_connections’;
该命令可以查看MySQL Server所支持的最大连接个数,超过max_connections数量的连接,MySQLServer会直接拒绝,所以在使用连接池增加连接数量的时候,MySQL Server的max_connections参数也要适当的进行调整,以适配连接池的连接上限。
5.功能实现设计
ConnectionPool.cpp和ConnectionPool.h:连接池代码实现
Connection.cpp和Connection.h:数据库操作代码、增删改查代码实现
连接池主要包含了以下功能点 :
1.连接池只需要一个实例,所以ConnectionPool以单例模式进行设计
2.从ConnectionPool中可以获取和MySQL的连接Connection
3.空闲连接Connection全部维护在一个线程安全的Connection队列中,使用线程互斥锁保证队列的线程安全
4.如果Connection队列为空,还需要再获取连接,此时需要动态创建连接,上限数量是maxSize
5.队列中空闲连接时间超过maxIdleTime的就要被释放掉,只保留初始的initSize个连接就可以了,这个功能点肯定需要放在独立的线程中去做
6.如果Connection队列为空,而此时连接的数量已达上限maxSize,那么等待connectionTimeout时间,如果还获取不到空闲的连接,那么获取连接失败,此处从Connection队列获取空闲连接,可以使用带超时时间的mutex互斥锁来实现连接超时时间(并且在这段时间内是一直在监听有没有连接,有能用的就用了)
7.用户获取的连接用shared_ptr智能指针来管理,用lambda表达式定制连接释放的功能(不真正释放连接,而是把连接归还到连接池中)
8.连接的生产和连接的消费采用生产者-消费者线程模型来设计,使用了线程间的同步通信机制条件变量和互斥锁
6.环境(准备工作)
mysql的安装和配置由读者自行完成
1.平台选择
有关MySQL数据库编程、多线程编程、线程互斥和同步通信操作、智能指针、设计模式、容器等等这些技术在C++语言层面都可以直接实现,因此该项目选择直接在windows平台上进行开发,当然放在Linux平台下用g++也可以直接编译运行。
2.数据库准备工作
启动mysql后,输入登录命令,输入密码登录数据库
mysql -u root -p
使用命令创建数据库chat和表user
#查看数据库
SHOW databases;
#创建数据库
CREATE DATABASE chat;
USE chat;
SHOW TABLES;
#创建表
CREATE TABLE USER (
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(50) ,
age INT,
sex ENUM('male','female')
);
SHOW TABLES;
DESC USER;
3.VS准备工作
这里的MySQL数据库编程直接采用oracle公司提供的MySQL C/C++客户端开发包,在VS上需要进行相应的头文件和库文件的配置,如下:
1.右键项目 - C/C++ - 常规 - 附加包含目录,填写mysql.h头文件的路径
2.右键项目 - 链接器 - 常规 - 附加库目录,填写libmysql.lib的路径
3.右键项目 - 链接器 - 输入 - 附加依赖项,填写libmysql.lib库的名字(记得写分号)
4.把libmysql.dll动态链接库(Linux下后缀名是.so库)放在工程目录下
注意VS上方debug后面那个要换成64位的而不是32位的

7.MYSQL API使用
转至这篇文章进行学习
8.连接类Connection的封装与实现
该模块主要作用是创建用户与数据库的联系,调用MYSQL的API接口实现数据库sql操作
本项目中只实现增删改查,感兴趣的读者可以参考这篇文章自行添加事务回滚等其他的操作
//Connection.h
#pragma once
//实现mysql数据库的增删改查操作
#include <mysql.h>
#include <string>
#include<ctime>
using namespace std;
#include "public.h"
// 数据库操作类
class Connection
{
public:
// 初始化数据库连接
Connection();
// 释放数据库连接资源
~Connection();
// 连接数据库
bool connect(string ip,
unsigned short port,
string username,
string password,
string dbname);
// 更新操作 insert、delete、update
bool update(string sql);
// 查询操作 select
MYSQL_RES* query(string sql);
//刷新一下连接的起始的空闲时间点
void refreshAlivetime() { _alivetime = clock(); }
//返回存活的时间
clock_t getAlivetime() const { return clock() - _alivetime; }
private:
MYSQL* _conn; // 表示和MySQL Server的一条连接
clock_t _alivetime;//记录进入空闲状态后的起始时间
};
#include"pch.h"
#include"public.h"
#include"Connection.h"
#include<iostream>
using namespace std;
// 初始化数据库连接
Connection::Connection()
{
_conn = mysql_init(nullptr);
}
// 释放数据库连接资源,关闭连接
Connection::~Connection()
{
if (_conn != nullptr)
mysql_close(_conn);
}
// 连接数据库
bool Connection::connect(string ip, unsigned short port, string username, string password,
string dbname)
{
//ip返回成char *类型
MYSQL* p = mysql_real_connect(_conn, ip.c_str(), username.c_str(),
password.c_str(), dbname.c_str(), port, nullptr, 0);
return p != nullptr;
}
// 更新操作 insert、delete、update
bool Connection::update(string sql)
{
if (mysql_query(_conn, sql.c_str()))
{
LOG("更新失败:" + sql);
return false;
}
return true;
}
// 查询操作 select
MYSQL_RES* Connection::query(string sql)
{
if (mysql_query(_conn, sql.c_str()))
{
LOG("查询失败:" + sql);
return nullptr;
}
return mysql_use_result(_conn);
}
这个模块与数据库连接池几乎没啥关系,写完以后可以调用main编写相应实例检查代码这模块功能是否实现了
#include <iostream>
#include"pch.h"
#include"Connection.h"
using namespace std;
int main()
{
Connection conn;
char sql[1024] = { 0 };
//插入一条信息
sprintf(sql, "insert into user(name,age,sex) values('%s','%d','%s')",
"zhang san", 20, "male");
conn.connect("127.0.0.1", 3306, "root", "040725ge", "chat");
conn.update(sql);
return 0;
}
在数据库中查找,发现有插入的该条记录,则成功
SELECT * FROM USER;
辨析:连接与会话
在MySQL中,连接(Connection)和会话(Session)是两个相关但不同的概念。
连接是一个物理的概念,它指的是一个通过网络建立的客户端和MySQL数据库服务器之间的网络连接。当客户端(如应用程序或数据库管理工具)与MySQL数据库服务器建立连接时,它们之间就建立了一条通信通道,用于传输数据和控制信息。
会话则是一个逻辑的概念,它存在于MySQL数据库实例中。每当一个连接被建立时,MySQL会为该连接创建一个会话。会话是用户与MySQL数据库之间互动的单位,它管理着与数据库的连接和交互。会话用于执行SQL语句、管理事务、处理错误等。会话在用户断开连接或会话因超时而关闭时结束。
因此,连接并不等同于会话,但它们之间存在紧密的关联。一个连接可以拥有一个或多个会话(尽管在大多数情况下,一个连接只对应一个会话),而会话则依赖于连接来与数据库进行通信。
在具体表现形式上,连接通常表现为一个网络连接对象,它包含了连接所需的所有信息,如IP地址、端口号、用户名、密码等。而会话则表现为MySQL数据库实例中的一个内部对象,它管理着与该连接相关的所有信息和状态,如当前数据库、用户权限、时区设置、事务状态等。
总的来说,连接是物理层面的通信通道,而会话是逻辑层面的交互单位。它们共同协作,使得客户端能够与MySQL数据库进行有效的通信和交互。
9.连接池类CommonConnectionPool实现
先看下头文件,看看我们要实现哪些功能
CommonConnectionPool.h
#pragma once
#include<string>
#include<queue>
#include<mutex>
#include<atomic>
#include<thread>
#include<memory>
#include<functional>
#include<condition_variable>
#include"Connection.h"
using namespace std;
//实现连接池功能模块
class ConnectionPool
{
public:
//获取连接对象池实例
static ConnectionPool* getConnectionPool();
//给外部提供接口,从连接池获取一个可用的空闲连接
//使用智能指针+自定义删除器来让释放的连接回到数据库连接池
//而不是重新定义一个backConnection函数,还要去调用这个来返回用完的连接,太麻烦了
shared_ptr<Connection> getConntection();
private:
//单例设计模式 构造函数私有化
ConnectionPool();
//从配置文件中加载配置项
bool loadConfigFile();
//运行在独立的线程中,专门负责生产新连接
void produceConnectionTask();
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
void scannerConnectionTask();
string _ip;//mysql的ip
unsigned _port;//mysql的端口号
string _username;//mysql登录用户名
string _password;//mysql登录密码
string _dbname;//连接的数据库名称
int _initSize;//连接池的初始连接量
int _maxIdleTime;//连接池最大空闲时间
int _connectionTimeout;//连接池获取连接的超时时间
int _maxSize;//连接池的最大连接量
queue<Connection*> _connectionQue;//存储mysql连接的队列
mutex _queueMutex;//维护连接队列的线程互斥锁
//它的++和--不一定是线程安全,所以用原子变量确保线程安全
atomic_int _connectionCnt;//记录连接所创建的connection连接的总数量,不能超过maxsize
condition_variable cv;//设置条件变量,用于连接生产线程和消费线程的通信
};
具体有:
//获取连接对象池实例
static ConnectionPool* getConnectionPool();
//给外部提供接口,从连接池获取一个可用的空闲连接
//使用智能指针+自定义删除器来让释放的连接回到数据库连接池
//而不是重新定义一个backConnection函数,还要去调用这个来返回用完的连接,太麻烦了
shared_ptr<Connection> getConntection();
//单例设计模式 构造函数私有化
ConnectionPool();
//从配置文件中加载配置项
bool loadConfigFile();
//运行在独立的线程中,专门负责生产新连接
void produceConnectionTask();
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
void scannerConnectionTask();
1.getConnectionPool()
//线程安全的懒汉单例函数接口
ConnectionPool* ConnectionPool::getConnectionPool()
{
static ConnectionPool pool;
return &pool;
}
这个就是单例模式的获得单例的函数接口
我们返回连接池的单例就行
2.loadConfigFile()和mysql.ini
这个是配置文件mysql.ini 进行相关的配置,一般都是手动配置的
#数据库连接池的配置文件 mysql.ini
ip=127.0.0.1
port=3306
username=root
password=040725ge
dbname=chat
initSize=10
maxSize=1024
#最大空闲时间默认单位是秒
maxIdleTime=60
#连接超时时间单位是毫秒
connectionTimeout=100
这个是从配置文件中加载配置项配置给数据库连接池那个单例的成员变量进行赋值
//从配置文件中加载配置项
bool ConnectionPool::loadConfigFile()
{
FILE* pf = fopen("mysql.ini", "r");
if (pf == nullptr)
{
LOG("mysql.ini file is not exist!");
return false;
}
while (!feof(pf))
{
char line[1024] = { 0 };
fgets(line, 1024, pf);
string str = line;
int idx = str.find('=', 0);
if (idx == -1)//无效的配置项
continue;
//password=123456\n每一行完了还有一个换行
int endidx = str.find('\n', idx);
string key = str.substr(0, idx);
string value = str.substr(idx + 1, endidx - idx - 1);
//赋值操作
if (key == "ip")
_ip = value;
else if (key == "port")
_port = atoi(value.c_str());
else if (key == "username")
_username = value;
else if (key == "password")
_password = value;
else if (key == "dbname")
_dbname = value;
else if (key == "initSize")
_initSize = atoi(value.c_str());
else if (key == "maxSize")
_maxSize = atoi(value.c_str());
else if (key == "maxIdleTime")
_maxIdleTime = atoi(value.c_str());
else if (key == "connectionTimeout")
_connectionTimeout = atoi(value.c_str());
}
return true;
}
3.ConnectionPool()
这个是连接池的构造函数,单例模式很多功能都会在这里实现
1.检查配置是否成功
2.初始化连接池,一开始有initsize个连接已经在池子里面了
3.启动生产者线程
4.启动定时器扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
这里要注意使用detach分离主线程和子线程,不然主线程结束而子线程还没有结束的话是一个很危险的行为。
关于为什么不用join请看具体的线程函数
//连接池的构造
ConnectionPool::ConnectionPool()
{
//配置失败
if (!loadConfigFile())
return;
//创建初始数量的连接
for (int i = 0; i < _initSize; i++)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}
//启动一个新的线程,作为连接的生产者
thread produce(std::bind(&ConnectionPool::produceConnectionTask,this));
produce.detach();//守护进程
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
thread scanner(std::bind(&ConnectionPool::scannerConnectionTask, this));
scanner.detach();//守护进程
}
4.produceConnectionTask()
//运行在独立的线程中,专门负责生产新连接,即生产者线程
void ConnectionPool::produceConnectionTask()
{
for (;;)
{
unique_lock<mutex> lock(_queueMutex);
while (!_connectionQue.empty())
{
cv.wait(lock);
}
//连接数量没有到达上限,继续创建新的连接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}
//通知消费者线程可以消费连接了
cv.notify_all();
}
}
如果主线程调用join阻塞等待生产者线程结束,但是我们这里的生产者线程是一个死循环,也就是说主线程在这里等死了生产者线程也不会结束,并且主线程很有可能还有其他功能要调用。
为什么用detach呢?因为这里主线程和子线程分离之后就各管各的,主线程会自动继续执行下去,去干它的事情,生产者线程也就去生产了,在主线程事情办完了以后,那就结束了,之后整个进程结束后会回收仍然处在死循环的生产者线程
大家肯定会觉得这样不太好,这里提供一种优化措施。
1.增加一个成员变量,_stop来控制是否要结束子线程线程
2.构造函数初始化为false
3.增加一个成员函数stop专门关闭生产者线程
void stop() {
{
std::lock_guard<std::mutex> lock(_queueMutex);
_stop = true; // 设置停止标志
}
cv.notify_all(); // 唤醒生产者线程,以便检测到退出条件
}
4.在生产者代码段添加
if (_stop)
{
std::cout << "生产者线程退出" << std::endl;
return; // 退出线程
}
5.在析构函数中调用stop成员函数即可
~ConnectionPool() {
stop(); // 在析构函数中调用 stop() 方法
if (_producerThread.joinable()) {
_producerThread.join(); // 等待生产者线程结束
}
}
5.getConntection()
实现消费者线程+回收机制
1.如果超过了最长等待时间还没有获得连接,说明此时连接的人太多了,获取连接失败了
2.使用智能指针+自定义删除器来完成回收机制
智能指针第二个参数是删除器,用lambda表达式,我们不希望它断开连接,而是重新回到连接池队列中,供下一次使用,而不用重新建立连接。
//给外部提供接口,从连接池获取一个可用的空闲连接
//使用智能指针+自定义删除器来让释放的连接回到数据库连接池
//而不是重新定义一个backConnection函数,还要去调用这个来返回用完的连接,太麻烦了
shared_ptr<Connection> ConnectionPool::getConntection()
{
unique_lock<mutex> lock(_queueMutex);
while (_connectionQue.empty())
{
//不要写sleep wait_for是在这个时间段内如果有可以获取的连接,那就直接拿走了
//超过了空闲时间还没有连接能用
if (cv_status::timeout == cv.wait_for(lock, chrono::milliseconds(_connectionTimeout)))
{
if (_connectionQue.empty())
{
LOG("获取空闲连接超时了...获取连接失败");
return nullptr;
}
}
}
/*shared_ptr析构会调用Connection析构,直接delete了,会关闭连接
而我们要归还资源,让连接回到队列,所以要自定义删除器*/
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon) {
unique_lock<mutex> lock(_queueMutex);
pcon->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(pcon);
});
_connectionQue.pop();
//消费完连接以后,通知生产者进程检查一下,如果队列为空了,赶紧生产
cv.notify_all();
return sp;
//return nullptr;
}
大家也不用担心内存泄漏的问题,在连接池最后析构的时候会对每一个对象调用析构函数进行内存释放
6.scannerConnectionTask()
//扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
void ConnectionPool::scannerConnectionTask()
{
for (;;)
{
//通过sleep模拟睡眠
this_thread::sleep_for(chrono::seconds(_maxIdleTime));
//扫描整个队列,释放多余的连接
unique_lock<mutex> lock(_queueMutex);
while (_connectionCnt > _initSize)
{
Connection* p = _connectionQue.front();
if (p->getAlivetime() > (_maxIdleTime * 1000))
{
_connectionQue.pop();
_connectionCnt--;
delete p;//调用~Connection()释放连接
}
else
{
//队头的连接没有超过_maxIdleTime,其他连接肯定没有
break;
}
}
}
}
这部分相关的变量和成员函数都在connection类中封装着,大家可能找不到
pubic:
//刷新一下连接的起始的空闲时间点
void refreshAlivetime() { _alivetime = clock(); }
//返回存活的时间
clock_t getAlivetime() const { return clock() - _alivetime; }
private:
MYSQL* _conn; // 表示和MySQL Server的一条连接
clock_t _alivetime;//记录进入空闲状态后的起始时间
在每次生产者生产完,和每次使用完连接析构的时候调用只能指针的删除器的时候会调用refreshAlivetime进行开始空闲的连接时间的刷新,就是说从这个点开始你是空闲的
然后返回存活时间就是从生产出来或者重新入队,到目前请求getAlivetime函数这一段时间
10.各个模块实现后的完整版
pch.h
#pragma once
#ifndef PCH_H
#define PCH_H
#endif
public.h
#pragma once
// 文件 行号 时间 信息
#define LOG(str) \
cout << __FILE__ << ":" << __LINE__ <<" " << \
__TIMESTAMP__ << " : " << str << endl;
Connection.h
#pragma once
//实现mysql数据库的增删改查操作
#include <mysql.h>
#include <string>
#include<ctime>
using namespace std;
#include "public.h"
// 数据库操作类
class Connection
{
public:
// 初始化数据库连接
Connection();
// 释放数据库连接资源
~Connection();
// 连接数据库
bool connect(string ip,
unsigned short port,
string username,
string password,
string dbname);
// 更新操作 insert、delete、update
bool update(string sql);
// 查询操作 select
MYSQL_RES* query(string sql);
//刷新一下连接的起始的空闲时间点
void refreshAlivetime() { _alivetime = clock(); }
//返回存活的时间
clock_t getAlivetime() const { return clock() - _alivetime; }
private:
MYSQL* _conn; // 表示和MySQL Server的一条连接
clock_t _alivetime;//记录进入空闲状态后的起始时间
};
CommonConnectionPool.h
#pragma once
#include<string>
#include<queue>
#include<mutex>
#include<atomic>
#include<thread>
#include<memory>
#include<functional>
#include<condition_variable>
#include"Connection.h"
using namespace std;
//实现连接池功能模块
class ConnectionPool
{
public:
//获取连接对象池实例
static ConnectionPool* getConnectionPool();
//给外部提供接口,从连接池获取一个可用的空闲连接
//使用智能指针+自定义删除器来让释放的连接回到数据库连接池
//而不是重新定义一个backConnection函数,还要去调用这个来返回用完的连接,太麻烦了
shared_ptr<Connection> getConntection();
private:
//单例设计模式 构造函数私有化
ConnectionPool();
//从配置文件中加载配置项
bool loadConfigFile();
//运行在独立的线程中,专门负责生产新连接
void produceConnectionTask();
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
void scannerConnectionTask();
string _ip;//mysql的ip
unsigned _port;//mysql的端口号
string _username;//mysql登录用户名
string _password;//mysql登录密码
string _dbname;//连接的数据库名称
int _initSize;//连接池的初始连接量
int _maxIdleTime;//连接池最大空闲时间
int _connectionTimeout;//连接池获取连接的超时时间
int _maxSize;//连接池的最大连接量
queue<Connection*> _connectionQue;//存储mysql连接的队列
mutex _queueMutex;//维护连接队列的线程互斥锁
//它的++和--不一定是线程安全,所以用原子变量确保线程安全
atomic_int _connectionCnt;//记录连接所创建的connection连接的总数量,不能超过maxsize
condition_variable cv;//设置条件变量,用于连接生产线程和消费线程的通信
};
Connection.cpp
#include"pch.h"
#include"public.h"
#include"Connection.h"
#include<iostream>
using namespace std;
// 初始化数据库连接
Connection::Connection()
{
_conn = mysql_init(nullptr);
}
// 释放数据库连接资源,关闭连接
Connection::~Connection()
{
if (_conn != nullptr)
mysql_close(_conn);
}
// 连接数据库
bool Connection::connect(string ip, unsigned short port, string username, string password,
string dbname)
{
//ip返回成char *类型
MYSQL* p = mysql_real_connect(_conn, ip.c_str(), username.c_str(),
password.c_str(), dbname.c_str(), port, nullptr, 0);
return p != nullptr;
}
// 更新操作 insert、delete、update
bool Connection::update(string sql)
{
if (mysql_query(_conn, sql.c_str()))
{
LOG("更新失败:" + sql);
return false;
}
return true;
}
// 查询操作 select
MYSQL_RES* Connection::query(string sql)
{
if (mysql_query(_conn, sql.c_str()))
{
LOG("查询失败:" + sql);
return nullptr;
}
return mysql_use_result(_conn);
}
CommonConnectionPool.cpp
#include"pch.h"
#include"public.h"
#include"CommonConnectionPool.h"
#include<iostream>
//线程安全的懒汉单例函数接口
ConnectionPool* ConnectionPool::getConnectionPool()
{
static ConnectionPool pool;
return &pool;
}
//从配置文件中加载配置项
bool ConnectionPool::loadConfigFile()
{
FILE* pf = fopen("mysql.ini", "r");
if (pf == nullptr)
{
LOG("mysql.ini file is not exist!");
return false;
}
while (!feof(pf))
{
char line[1024] = { 0 };
fgets(line, 1024, pf);
string str = line;
int idx = str.find('=', 0);
if (idx == -1)//无效的配置项
continue;
//password=123456\n每一行完了还有一个换行
int endidx = str.find('\n', idx);
string key = str.substr(0, idx);
string value = str.substr(idx + 1, endidx - idx - 1);
if (key == "ip")
_ip = value;
else if (key == "port")
_port = atoi(value.c_str());
else if (key == "username")
_username = value;
else if (key == "password")
_password = value;
else if (key == "dbname")
_dbname = value;
else if (key == "initSize")
_initSize = atoi(value.c_str());
else if (key == "maxSize")
_maxSize = atoi(value.c_str());
else if (key == "maxIdleTime")
_maxIdleTime = atoi(value.c_str());
else if (key == "connectionTimeout")
_connectionTimeout = atoi(value.c_str());
}
return true;
}
//连接池的构造
ConnectionPool::ConnectionPool()
{
//配置失败
if (!loadConfigFile())
return;
//创建初始数量的连接
for (int i = 0; i < _initSize; i++)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}
//启动一个新的线程,作为连接的生产者
thread produce(std::bind(&ConnectionPool::produceConnectionTask,this));
produce.detach();//守护进程
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
thread scanner(std::bind(&ConnectionPool::scannerConnectionTask, this));
scanner.detach();//守护进程
}
//运行在独立的线程中,专门负责生产新连接,即生产者线程
void ConnectionPool::produceConnectionTask()
{
for (;;)
{
unique_lock<mutex> lock(_queueMutex);
while (!_connectionQue.empty())
{
cv.wait(lock);
}
//连接数量没有到达上限,继续创建新的连接
if (_connectionCnt < _maxSize)
{
Connection* p = new Connection();
p->connect(_ip, _port, _username, _password, _dbname);
p->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(p);
_connectionCnt++;
}
//通知消费者线程可以消费连接了
cv.notify_all();
}
}
//给外部提供接口,从连接池获取一个可用的空闲连接
//使用智能指针+自定义删除器来让释放的连接回到数据库连接池
//而不是重新定义一个backConnection函数,还要去调用这个来返回用完的连接,太麻烦了
shared_ptr<Connection> ConnectionPool::getConntection()
{
unique_lock<mutex> lock(_queueMutex);
while (_connectionQue.empty())
{
//不要写sleep wait_for是在这个时间段内如果有可以获取的连接,那就直接拿走了
if (cv_status::timeout == cv.wait_for(lock, chrono::milliseconds(_connectionTimeout)))
{
if (_connectionQue.empty())
{
LOG("获取空闲连接超时了...获取连接失败");
return nullptr;
}
}
}
/*shared_ptr析构会调用Connection析构,直接delete了,会关闭连接
而我们要归还资源,让连接回到队列,所以要自定义删除器*/
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon) {
unique_lock<mutex> lock(_queueMutex);
pcon->refreshAlivetime();//刷新一下开始空闲的起始时间
_connectionQue.push(pcon);
});
_connectionQue.pop();
//消费完连接以后,通知生产者进程检查一下,如果队列为空了,赶紧生产
cv.notify_all();
return sp;
//return nullptr;
}
//扫描超过maxIdleTime时间的空闲连接,进行多余的空闲连接的回收
void ConnectionPool::scannerConnectionTask()
{
for (;;)
{
//通过sleep模拟睡眠
this_thread::sleep_for(chrono::seconds(_maxIdleTime));
//扫描整个队列,释放多余的连接
unique_lock<mutex> lock(_queueMutex);
while (_connectionCnt > _initSize)
{
Connection* p = _connectionQue.front();
if (p->getAlivetime() > (_maxIdleTime * 1000))
{
_connectionQue.pop();
_connectionCnt--;
delete p;//调用~Connection()释放连接
}
else
{
//队头的连接没有超过_maxIdleTime,其他连接肯定没有
break;
}
}
}
}
mysql.ini
#数据库连接池的配置文件
ip=127.0.0.1
port=3306
username=root
password=040725ge
dbname=chat
initSize=10
maxSize=1024
#最大空闲时间默认单位是秒
maxIdleTime=60
#连接超时时间单位是毫秒
connectionTimeout=100
pch.cpp
#include"pch.h"
11.个人觉得应该改进的地方
改进:生产者线程和检查超过最大空闲时间的线程应该加入一个自己结束的标志,在线程池对象析构的时候回收掉而不是detach后进入死循环等着整个应用程序进程结束之后才回收
在produceConnectionTask()部分有实现的代码,供大家参考
12.技术点问题的复习
1.锁的作用:
第一个锁
情景
假设有两个线程 T1 和 T2 同时在运行,并且它们都调用 produceConnectionTask() 方法。具体执行流程如下:
- T1 获取了
unique_lock,并检查_connectionQue是否为空。在这里,T1 发现队列为空,于是进入到if (_connectionCnt < _maxSize)的条件判断。 - 此时,T2 也几乎同时调用了
produceConnectionTask(),但由于没有获取锁,它可以在 T1 的操作未完成时同时访问_connectionQue和_connectionCnt。 - T2 也发现
_connectionQue为空,于是它也进入到if (_connectionCnt < _maxSize)条件判断,且在此刻它的_connectionCnt可能还没有增加,因为 T1 还未完成对连接的创建和队列的更新。
问题
由于没有使用锁来保护对 _connectionQue 和 _connectionCnt 的访问,T1 和 T2 都在认为可以创建连接的情况下独立执行,可能导致:
- 连接重复创建:假设
_maxSize的值为 10,那么 T1 和 T2 各自都创建了一个新的连接,_connectionCnt的值可能变成了 12(假设 T1 和 T2 同时完成创建),这超出了最大连接数的限制。 - 资源浪费和潜在崩溃:创建过多的连接会导致资源浪费,并可能导致数据库连接过载,最终可能导致程序崩溃或出现不稳定状态。
第2个锁 (unique_lock<mutex> lock(_queueMutex);):
- 作用:保护对连接队列
_connectionQue的访问,确保只有一个线程能够在任意时刻对队列进行操作(检查空闲连接、弹出连接等)。 - 场景:当线程调用
getConntection()时,它会首先尝试获取这个锁。只有在成功获得锁后,线程才能访问和修改_connectionQue。
第3个锁 (在 lambda 中的 unique_lock<mutex> lock(_queueMutex);):
- 作用:在自定义删除器的上下文中再次保护对
_queueMutex的访问,确保在归还连接时,线程能够安全地刷新连接的空闲时间并将连接推回到队列中。 - 场景:当
shared_ptr被销毁时,删除器会被调用,这时需要再一次确保对_queueMutex的安全访问,以避免数据竞争和不一致的状态。
如果缺少第一个锁
缺少第一个锁的后果:
- 情景:假设两个线程 T1 和 T2 同时调用
getConntection()方法。由于缺少第一个锁,T1 可能在检查_connectionQue.empty()时,T2 也进入了getConntection()方法并尝试检查同一队列。 - 问题:如果 T1 和 T2 同时读取
_connectionQue的状态,且在 T1 认为队列不为空的情况下,T2 也可能认为队列不为空。然后两者都试图从队列中获取连接并将其返回,这可能导致同一个连接被多个shared_ptr指向,造成连接资源的重复释放,最终引发未定义行为。
如果缺少第二个锁
缺少第二个锁的后果:
- 情景:假设 T1 调用了
getConntection()方法,并成功获取到连接,同时正在返回shared_ptr,在自定义删除器中缺少锁保护。 - 问题:在 T1 调用删除器时,T2 可能也同时调用
getConntection()。如果 T2 也在操作_connectionQue,它可以同时修改连接队列,甚至可能在 T1 还未完全完成对连接的返回时,试图再次修改同一连接。 - 后果:如果 T1 的删除器正在调用
refreshAlivetime(),而 T2 也在尝试将连接返回到队列中,两个线程之间可能会发生数据竞争,导致连接的状态不一致或引发程序崩溃。
2.生产者消费者模型
本项目中是生产者和消费者模型的运用,只不过是生产和消费的东西是数据库的连接罢了
3.原子整型
_connectionCnt;//记录连接所创建的connection连接的总数量,不能超过maxsize
对它的++和–操作必须是线程安全的,所以用原子整型
4.线程互斥
通过上面提到的三个锁完成了互斥,主要是对队列的操作需要线程互斥
5.线程通信和信号量
通过cv这个信号量实现了线程通信,即生产者生产完通知消费者来消费,消费者消费完通知生产者生产
6.智能指针和lambda表达式
lambda自定义智能指针删除器,使得用完的连接不用释放而是重新进入连接池队列
下面作者发疯大家不必理会
也是第一次做项目(说实话有视频带着做真好吧)并且写文档做总结,体会OPPO思想和C++11新特性的使用,有点小激动,一共是360-400行左右的代码
给我第一感觉就是什么都是指针,引用,值传递几乎没找到几个,或许项目就是这样,完了学一学git之后上传到github之后把地址贴到这里,大家一起加油。
原文地址:https://blog.csdn.net/m0_74795952/article/details/143026382
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!