OpenCV书签 #余弦相似度的原理与相似图片/相似文件搜索实验
1. 介绍
余弦相似度(Cosine Similarity),又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度仅仅与向量的指向方向相关,与向量的长度无关,它将向量根据坐标值绘制到向量空间中,如最常见的二维空间。因此,万物皆向量,我们可以使用余弦相似度来进行相似图片查找、相似文件搜索等工作。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:
给定两个属性向量,A 和 B,其余弦相似性 θ 由点积和向量长度给出,如下所示:
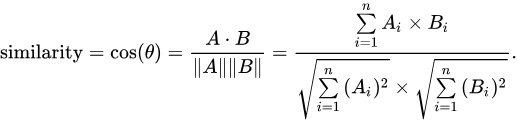
原理
余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
- 当两个向量的夹角为0°,即余弦值为1,则两个向量有相同的指向,相当于相似度最高(其他任何角度的余弦值都不大于1)。
- 当两个向量的夹角为90°,即余弦值为0,则两个向量垂直。
- 当两个向量的夹角为180°,即余弦值为-1,则两个向量指向完全相反的方向,相当于完全不是同类。
余弦相似度而非算法,求出余弦相似度后,到底阈值如何界定(值大于多少认为是样本的相似同类),往往需要依次用不同的阈值数值对全部数据集进行测试,挑选效果最好的数值作为阈值。
余弦相似度通常用于正空间。余弦值的范围在-1到1之间,因为包含负值,有时不便于使用。改进方法有:
- 将余弦相似度用于正空间,对于各个维度均为正的向量,可以保证余弦相似度非负(该空间的夹角被限定在 0-90,或者根据公式,内积恒为正),所以可以转为 [0, 1] 上的有界相似性。
- 用1减余弦相似度,此时结果范围为 [0, 2],且值越小表示越接近(类似欧氏距离)。
2. 实验一:查找相似图像
2.1.1 魔法
- 图像加载和预处理: 读取目标图像。预处理图像,例如转换为灰度图像、调整大小等。
- 特征提取: 选择图像特征,这里通常使用直方图,对每张图像计算所选特征,得到特征向量。
- 相似度计算: 使用余弦相似度计算两个特征向量之间的相似性。相似度的计算通常在 [0, 1] 范围,越接近1表示越相似。
- 排序和筛选: 对相似图像按照相似度降序排序。根据需求,可以选择保留相似度高于某个阈值的图像。
- 结果展示: 展示相似度高的图像作为结果。可以通过图形界面、命令行输出或其他方式呈现结果。
2.1.2 实验
第一步:图像加载和预处理
读取目标图像。预处理图像,例如转换为灰度图像、调整大小等。
"""
以图搜图:余弦相似度(Cosine Similarity)查找相似图像的原理与实现
实验环境:Win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1 | Matplotlib 3.7.1
实验时间:2023-11-30
实例名称:imgCosineSimilarity_v1.0_show.py
"""
import os
import cv2
import matplotlib.pyplot as plt
# 目标图像素材库文件夹路径
database_dir = '../../P0_Doc/img_data/'
# 读取查询图像和数据库中的图像
img1_path = database_dir + 'car-101.jpg'
img2_path = database_dir + 'car-102.jpg'
img3_path = database_dir + 'car-103.jpg'
img4_path = database_dir + 'car-106.jpg'
img5_path = database_dir + 'car-109.jpg'
# 读取图像
img1 = cv2.imread(img1_path)
img2 = cv2.imread(img2_path)
img3 = cv2.imread(img3_path)
img4 = cv2.imread(img4_path)
img5 = cv2.imread(img5_path)
# 将图像转换为灰度图像
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
img3_gray = cv2.cvtColor(img3, cv2.COLOR_BGR2GRAY)
img4_gray = cv2.cvtColor(img4, cv2.COLOR_BGR2GRAY)
img5_gray = cv2.cvtColor(img5, cv2.COLOR_BGR2GRAY)
# 绘制子图
plt.figure(figsize=(12, 4))
# 绘制灰度图像
plt.subplot(1, 5, 1)
plt.imshow(img1_gray, cmap='gray')
plt.title(os.path.basename(img1_path))
plt.subplot(1, 5, 2)
plt.imshow(img2_gray, cmap='gray')
plt.title(os.path.basename(img2_path))
plt.subplot(1, 5, 3)
plt.imshow(img3_gray, cmap='gray')
plt.title(os.path.basename(img3_path))
plt.subplot(1, 5, 4)
plt.imshow(img4_gray, cmap='gray')
plt.title(os.path.basename(img4_path))
plt.subplot(1, 5, 5)
plt.imshow(img5_gray, cmap='gray')
plt.title(os.path.basename(img5_path))
plt.tight_layout()
# 显示灰度图像
plt.show()
灰度图像:

第二步:特征提取
选择图像特征,这里通常使用直方图,对每张图像计算所选特征,得到特征向量。
# 计算图像的直方图
img1_hist = cv2.calcHist([img1_gray], [0], None, [256], [0, 256])
img2_hist = cv2.calcHist([img2_gray], [0], None, [256], [0, 256])
img3_hist = cv2.calcHist([img3_gray], [0], None, [256], [0, 256])
img4_hist = cv2.calcHist([img4_gray], [0], None, [256], [0, 256])
img5_hist = cv2.calcHist([img5_gray], [0], None, [256], [0, 256])
# 获取图像的特征向量
vector1 = img1_hist.flatten()
vector2 = img2_hist.flatten()
vector3 = img3_hist.flatten()
vector4 = img4_hist.flatten()
vector5 = img5_hist.flatten()
# 使用垂直线(stem lines)绘制向量
plt.figure(figsize=(8, 4))
# 绘制向量1
plt.subplot(1, 5, 1)
plt.stem(vector1)
plt.title('Vector 1')
# 绘制向量2
plt.subplot(1, 5, 2)
plt.stem(vector2)
plt.title('Vector 2')
# 绘制向量3
plt.subplot(1, 5, 3)
plt.stem(vector3)
plt.title('Vector 3')
# 绘制向量4
plt.subplot(1, 5, 4)
plt.stem(vector4)
plt.title('Vector 4')
# 绘制向量5
plt.subplot(1, 5, 5)
plt.stem(vector5)
plt.title('Vector 5')
# 图像向量可视化
plt.tight_layout()
plt.show()
图像特征向量可视化,横向对比:
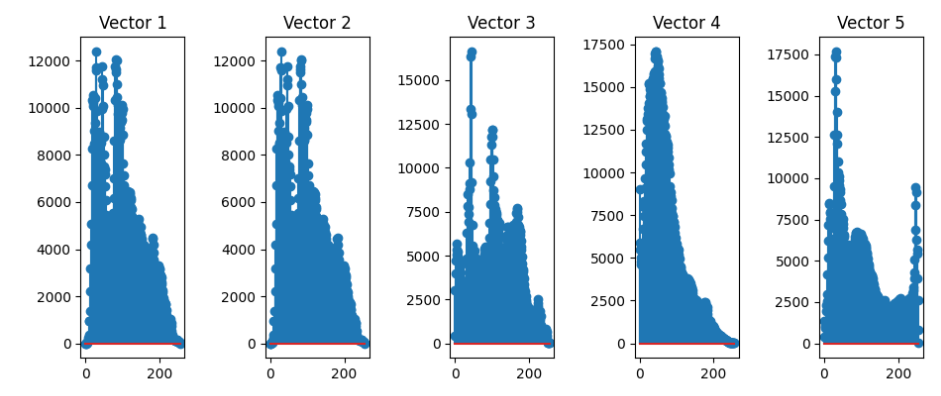
使用散点图绘制特征向量:
# 使用散点图绘制向量
plt.figure(figsize=(8, 4))
# 绘制散点图
plt.scatter(range(len(vector1)), vector1, label='Vector 1', marker='o', s=10)
plt.scatter(range(len(vector2)), vector2, label='Vector 2', marker='x', s=10)
plt.scatter(range(len(vector3)), vector3, label='Vector 3', marker='o', s=10)
plt.scatter(range(len(vector4)), vector4, label='Vector 4', marker='o', s=10)
plt.scatter(range(len(vector5)), vector5, label='Vector 5', marker='o', s=10)
plt.title('Scatter Plot of Vectors')
plt.xlabel('Index')
plt.ylabel('Value')
# 添加图例
plt.legend()
# 图像向量可视化
plt.show()
图像特征向量散点图可视化:
通过可视化纵向对比测试图像的特征向量,不难发现,图像1与图像2的特征向量完全重合,即完全相似。
第三步:相似度计算
使用余弦相似度计算两个特征向量之间的相似性。相似度的计算通常在 [0, 1] 范围,越接近1表示越相似。
# 归一化直方图:将特征表示成一维向量
vector1 = img1_hist.flatten()
vector2 = img2_hist.flatten()
# 计算向量 vector1 和 vector2 的点积,即对应元素相乘后相加得到的标量值
dot_product = np.dot(vector1, vector2)
# 计算向量 vector1 的 L2 范数,即向量各元素平方和的平方根
norm_vector1 = np.linalg.norm(vector1)
# 计算向量 vector2 的 L2 范数
norm_vector2 = np.linalg.norm(vector2)
# 利用余弦相似度公式计算相似度,即两个向量的点积除以它们的 L2 范数之积
similarity = dot_product / (norm_vector1 * norm_vector2)
print(f"图像名称:{img2_path},与目标图像 {img1_path} 的近似值:{similarity}")
输出打印:
图像名称:img_test/car-102.jpg,与目标图像 img_test/car-101.jpg 的近似值:1.0
第四步:排序和筛选
对相似图像按照相似度降序排序。根据需求,可以选择保留相似度高于某个阈值的图像。
if (similarity > 0.8):
print(f"图像名称:{img2_path},与目标图像 {img1_path} 的近似值:{similarity}")
或者,如下为多图相似实验部分代码(完整代码可参见下文 2.1.3 实验代码):
def image_search(query_path, database_paths):
# 提取查询图像的特征
query_feature = extract_features(query_path)
# 遍历数据库图像并比较相似度
similaritys = []
for database_path in database_paths:
# 提取数据库图像的特征
database_feature = extract_features(database_path)
# 计算余弦相似度
similarity = cosine_similarity(query_feature, database_feature)
# 将结果保存到列表中
if (similarity > 0.8):
similaritys.append((database_path, similarity))
# 按相似度降序排序
similaritys.sort(key=lambda x: x[1], reverse=True)
return similaritys
第五步:结果展示
展示相似度高的图像作为结果。可以通过图形界面、命令行输出或其他方式呈现结果。
具体可见如下测试代码。
2.1.3 测试
实验场景
通过 opencv,使用余弦相似度查找目标图像素材库中所有相似图像,要求相似值大于等于 0.65(余弦相似度通常在 [-1, 1] 范围,越接近1表示越相似)。
实验素材
实验代码
"""
以图搜图:余弦相似度(Cosine Similarity)查找相似图像的原理与实现
实验环境:Win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1 | Matplotlib 3.7.1
实验时间:2023-11-30
实例名称:imgCosineSimilarity_v1.2.py
"""
import os
import time
import cv2
import numpy as np
import matplotlib.pyplot as plt
def extract_features(image_path):
# 读取图像并将其转换为灰度
image = cv2.imread(image_path, cv2.COLOR_BGR2GRAY)
# 计算直方图
hist = cv2.calcHist([image], [0], None, [256], [0, 256])
# 归一化直方图
# cv2.normalize(hist, hist): 这一步是将直方图进行归一化,确保其数值范围在 [0, 1] 之间。归一化是为了消除图像的大小或强度的差异,使得直方图更具有通用性
# .flatten(): 这一步将归一化后的直方图展平成一维数组。在余弦相似度计算中,我们需要将特征表示成一维向量,以便进行向量之间的相似度比较
hist = cv2.normalize(hist, hist).flatten()
return hist
def cosine_similarity(vector1, vector2):
# 算向量 vector1 和 vector2 的点积,即对应元素相乘后相加得到的标量值
dot_product = np.dot(vector1, vector2)
# 计算向量 vector1 的 L2 范数,即向量各元素平方和的平方根
norm_vector1 = np.linalg.norm(vector1)
# 计算向量 vector2 的 L2 范数
norm_vector2 = np.linalg.norm(vector2)
# 利用余弦相似度公式计算相似度,即两个向量的点积除以它们的 L2 范数之积
similarity = dot_product / (norm_vector1 * norm_vector2)
return similarity
def image_search(query_path, database_paths):
# 提取查询图像的特征
query_feature = extract_features(query_path)
# 遍历数据库图像并比较相似度
similaritys = []
for database_path in database_paths:
# 提取数据库图像的特征
database_feature = extract_features(database_path)
# 计算余弦相似度
similarity = cosine_similarity(query_feature, database_feature)
# 将结果保存到列表中(仅保留相似值大于等于 0.8 的图像)
if (similarity >= 0.65):
similaritys.append((database_path, similarity))
# 按相似度降序排序
similaritys.sort(key=lambda x: x[1], reverse=True)
return similaritys
def show_similar_images(similar_images, images_per_column=3):
# 计算总共的图片数量
num_images = len(similar_images)
# 计算所需的行数
num_rows = (num_images + images_per_column - 1) // images_per_column
# 创建一个子图,每行显示 images_per_column 张图片
fig, axes = plt.subplots(num_rows, images_per_column, figsize=(12, 15), squeeze=False)
# 遍历每一行
for row in range(num_rows):
# 遍历每一列
for col in range(images_per_column):
# 计算当前图片在列表中的索引
index = row * images_per_column + col
# 检查索引是否越界
if index < num_images:
# 获取当前相似图片的路径和相似度
image_path = similar_images[index][0]
similarity = similar_images[index][1]
# 读取图片并转换颜色通道
image = cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB)
# 在子图中显示图片
axes[row, col].imshow(image)
# 设置子图标题,包括图片路径和相似度
axes[row, col].set_title(f"Similar Image: {os.path.basename(image_path)} \n Similar Score: {similarity:.4f}")
# 关闭坐标轴
axes[row, col].axis('off')
# 显示整个图
plt.show()
if __name__ == "__main__":
time_start = time.time()
# 目标图像素材库文件夹路径
database_folder_path = '../../P0_Doc/img_data/'
# 指定测试图像文件扩展名
img_suffix = ['.jpg', '.jpeg', '.png', '.bmp', '.gif']
# 目标查询图像路径
query_image_path = database_folder_path + 'apple-101.jpg'
query_image_path = database_folder_path + 'X3-01.jpg'
query_image_path = database_folder_path + 'Q3-01.jpg'
query_image_path = database_folder_path + 'car-101.jpg'
# 获取目标图像素材库文件夹中所有图像的路径
all_files = [os.path.join(database_folder_path, filename) for filename in os.listdir(database_folder_path)]
# 筛选出指定后缀的图像文件
img_files = [file for file in all_files if any(file.endswith(suffix) for suffix in img_suffix)]
# 进行相似图像搜索
search_results = image_search(query_image_path, img_files)
# 打印结果
for similarity in search_results:
print(f"图像名称:{similarity[0]},与目标图像 {os.path.basename(query_image_path)} 的近似值:{similarity[1]}")
time_end = time.time()
print(f"耗时:{time_end - time_start}")
# 显示目标相似图像
show_similar_images(search_results)
输出打印:
图像名称:../../P0_Doc/img_data/car-101.jpg,与目标图像 car-101.jpg 的近似值:1.0
图像名称:../../P0_Doc/img_data/car-102.jpg,与目标图像 car-101.jpg 的近似值:1.0
图像名称:../../P0_Doc/img_data/car-103.jpg,与目标图像 car-101.jpg 的近似值:0.8792840838432312
图像名称:../../P0_Doc/img_data/car-106.jpg,与目标图像 car-101.jpg 的近似值:0.8591960668563843
图像名称:../../P0_Doc/img_data/car-109.jpg,与目标图像 car-101.jpg 的近似值:0.8135514259338379
图像名称:../../P0_Doc/img_data/Q3-07.jpg,与目标图像 car-101.jpg 的近似值:0.7921913266181946
图像名称:../../P0_Doc/img_data/car-104.jpg,与目标图像 car-101.jpg 的近似值:0.7479972839355469
图像名称:../../P0_Doc/img_data/car-105.jpg,与目标图像 car-101.jpg 的近似值:0.7401522397994995
图像名称:../../P0_Doc/img_data/X3-01.jpg,与目标图像 car-101.jpg 的近似值:0.718971848487854
图像名称:../../P0_Doc/img_data/X3-10.jpg,与目标图像 car-101.jpg 的近似值:0.718971848487854
图像名称:../../P0_Doc/img_data/X3-07.jpg,与目标图像 car-101.jpg 的近似值:0.6954472661018372
图像名称:../../P0_Doc/img_data/Q3-11.jpg,与目标图像 car-101.jpg 的近似值:0.6589514017105103
图像名称:../../P0_Doc/img_data/X3-05.jpg,与目标图像 car-101.jpg 的近似值:0.6564251184463501
图像名称:../../P0_Doc/img_data/X3-02.jpg,与目标图像 car-101.jpg 的近似值:0.6537510752677917
耗时:0.9245285987854004
多图相似查找结果显示:

2.1.4 实验总结
经过多组目标测试图像的相似图查找,对于旋转、倒置的相似图像查找非常准确。对于相似值在 0.8 ~ 0.65 之间的相似图像查找效果差强人意。
优点
- 简单直观:余弦相似度是一种简单且直观的相似性度量方法,易于理解和实现。
- 计算速度较快:在一些小规模的图像数据库中,余弦相似度的计算速度相对较快,适用于实时性要求不高的场景。
- 适用于高维度特征:余弦相似度对于高维度特征空间的相似性度量效果较好,适用于图像的特征向量较长的情况。
缺点
- 不考虑空间结构:余弦相似度只关注特征向量的方向,而不考虑特征在空间中的分布结构。对于图像中的空间信息,余弦相似度并未进行有效的建模。
- 不考虑像素间的相对位置:余弦相似度不考虑像素在图像中的相对位置,对于图像内容的排列顺序不敏感,这在一些场景中可能并不符合实际需求。
- 对图像噪声敏感:如果图像中存在噪声,余弦相似度可能会受到噪声的影响,导致相似度计算不准确。
- 不适用于大规模数据库:在大规模图像数据库中,计算余弦相似度可能会变得相对较慢,不太适用于对实时性要求较高的场景。
2. 实验二:查找相似文本
在相似文件查找场景中,余弦相似性将文件表示为向量,向量的每个维度代表文件的某个特征,比如文件的内容、词频、TF-IDF值等。然后,通过计算文件向量之间的余弦相似度,可以评估它们之间的相似程度。
由于一个词的频率不能为负数,所以这两个文件的余弦相似性范围是从0到1。即,两个词的频率向量之间的角度不能大于90°。
2.2.1 魔法
- 文件读取和预处理: 读取目标文本文件,对目标文本进行预处理,包括分词、去停用词、移除标点符号和数字等。
- 提取文件特征: 将目标文本表示为特征向量。这可以通过不同的方法,比如文本文件可以使用词袋模型、TF-IDF等。
- 计算余弦相似度: 遍历测试库中的文本文件,对每个文件执行相似度计算。
- 获取相似文本: 根据需求设定一个阈值,将相似度大于阈值的文件视为相似文件,并按相似度结果排序,得到相似度最高的文本文件。
2.2.2 核心
- 分词: 将一段文本切分成一个个有意义的词语
- 构建词汇表: 列出所有的词,将所有文档中出现的词语构建为一个词汇表,该词汇表包含了所有可能的词语
- 计算词频: 对应单词在文本中出现的次数
- 词频向量化: 将文本表示为词频向量,以便计算文本之间的相似度
2.2.3 实验
第一步:文件读取和预处理
读取目标文本文件,对目标文本进行预处理,包括分词、去停用词、移除标点符号和数字等。
"""
以图搜图:余弦相似度(Cosine Similarity)查找相似文本的原理与实现
实验目的:文件读取和预处理
实验环境:Win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1 | Matplotlib 3.7.1 | jieba 0.42.1
实验时间:2023-11-30
实例名称:txtConsineSimilarity_v1.0.py
"""
import re
import jieba
# 预处理目标文本
def preprocess_text(text):
print(f"文本文件内容:{text}")
# 将文本转换为小写
text = text.lower()
print(f"将文本转为小写:{text}")
# 移除标点符号、数字和中文标点符号
text = re.sub(r'[^a-z\u4e00-\u9fa5\s]', '', text)
print(f"移除标点符号后:{text}")
# 使用 jieba 进行中文分词
text_words = jieba.cut(text)
# 将分词结果拼接成字符串
processed_text = ' '.join(text_words)
print(f"将分词结果拼接成字符串:{processed_text}")
return processed_text
if __name__ == "__main__":
# 本地测试文本素材库
test_dir_path = '../../P0_Doc/txt_data/'
# 本地测试文本素材路径
origin_file = test_dir_path + 'CosineSimilarity_定义_org.txt'
# 读取目标文本
with open(origin_file, 'r', encoding='utf-8') as file:
origin_text = file.read()
# 预处理目标文本
origin_context = preprocess_text(origin_text)
输出打印:
文本文件原内容:余弦相似度(Cosine Similarity),是通过计算两个向量的夹角余弦值来评估他们的相似度。
将文本转为小写:余弦相似度(cosine similarity),是通过计算两个向量的夹角余弦值来评估他们的相似度。
移除标点符号后:余弦相似度cosine similarity是通过计算两个向量的夹角余弦值来评估他们的相似度
将分词结果拼接成字符串:余弦 相似 度 cosine similarity 是 通过 计算 两个 向量 的 夹角 余弦 值来 评估 他们 的 相似 度
文本向量化的核心之一是文本分词。分词是将一段文本切分成一个个有意义的词语或标记的过程。在文本处理中,分词是一个关键的预处理步骤,因为它决定了最终文本向量的特征。
对于英文文本,一般可以使用空格进行简单的分词。而对于中文文本,由于汉字没有空格,需要使用中文分词工具进行切分。
比如测试案例中
文本文件原内容:
余弦相似度(Cosine Similarity),是通过计算两个向量的夹角余弦值来评估他们的相似度。
将文本转为小写:
余弦相似度cosine similarity是通过计算两个向量的夹角余弦值来评估他们的相似度
移除标点符号后:
余弦相似度cosine similarity是通过计算两个向量的夹角余弦值来评估他们的相似度
分词:
余弦 相似 度 cosine similarity 是 通过 计算 两个 向量 的 夹角 余弦 值来 评估 他们 的 相似 度
常见的中文分词工具包括 jieba、pkuseg、THULAC 等。其中,jieba 是一个简单而强大的中文分词工具,广泛应用于中文文本处理任务。
为什么要移除标点符号和数字?
移除标点符号和数字是因为在某些文本相似度计算中,这些字符通常不包含太多语义信息,但会增加文本的复杂性。在文本预处理阶段,通过移除这些字符,可以减小词汇量,使得计算的文本向量更加简洁,聚焦于包含主要语义的单词。
例如,标点符号和数字通常不对文本的整体语义产生太大影响,而且在不同文本中的使用方式可能会有很大差异。如果保留这些字符,可能会导致文本表示中包含大量的噪声,降低相似度计算的准确性。
当然,在一些特殊的应用场景中,保留标点符号和数字可能是有意义的,这取决于具体的文本相似度任务和需求。在本实验中,简单地移除了标点符号和数字,但实际应用中可以根据任务的要求进行定制化的预处理。
第二步:提取文件特征
将目标文本表示为特征向量。这可以通过不同的方法,比如文本文件可以使用词袋模型、TF-IDF等。
def get_vectorizer(origin_context):
# 构建文本向量:使用词袋模型表示文本,过滤停用词
origin_vectorizer = CountVectorizer(stop_words='english')
# 使用 CountVectorizer 将原始文本 origin_context 转换为词袋模型的向量表示
origin_vector = origin_vectorizer.fit_transform([origin_context])
print(f"文本词频矩阵:\n{origin_vector}")
# 获取特征单词列表
feature_names = origin_vectorizer.get_feature_names_out()
print(f"文本特征单词列表:\n{feature_names}")
print(f"文本词频向量:\n{origin_vector.toarray()}")
总体而言,CountVectorizer(stop_words='english') 的作用是将文本数据转换为词频矩阵,同时忽略英语停用词。这是文本挖掘和自然语言处理中常用的预处理步骤。
- CountVectorizer 类:
CountVectorizer是scikit-learn中用于将文本数据转换为词频(term frequency)矩阵的类。它将文本数据转换为一个矩阵,其中每一行代表一个文本样本,每一列代表一个不同的单词,而矩阵的元素是对应单词在文本样本中出现的次数。 - stop_words=‘english’ 参数:
stop_words参数用于指定停用词(stop words)的处理方式。停用词是在文本分析中通常被忽略的常见词汇,因为它们通常不包含有用的信息。在这里,‘english’ 表示使用英语停用词列表,这些词会在文本向量化时被忽略 - fit_transform 的过程:
- 构建词汇表:词汇表是所有文本中出现的独特单词的集合。
- 将文本转换为词频矩阵:对于每个文本,统计词汇表中每个单词的出现次数,将其转换为向量表示。
最终,origin_vector 是一个稀疏矩阵,其中每一行对应于一个单词,每一列对应于原始文本中对应单词的出现次数。
输出打印:
文本词频矩阵:
(0, 4) 2
(0, 8) 2
(0, 0) 1
(0, 1) 1
(0, 11) 1
(0, 9) 1
(0, 2) 1
(0, 6) 1
(0, 7) 1
(0, 5) 1
(0, 10) 1
(0, 3) 1
文本特征单词列表:
['cosine' 'similarity' '两个' '他们' '余弦' '值来' '向量' '夹角' '相似' '计算' '评估' '通过']
文本词频向量:
[[1 1 1 1 2 1 1 1 2 1 1 1]]
第三步:计算余弦相似度
读取目标文本文件,对文件执行相似度计算。
注:多个测试素材时,遍历测试库中的文本文件,对每个文件执行相似度计算。可见下文实验代码。
第四步:获取相似文本
根据需求设定一个阈值,将相似度大于阈值的文件视为相似文件,并按相似度结果排序,得到相似度最高的文本文件。可见下文实验代码。
2.2.4 测试
实验素材:
场景1:比较2个文件相似性
实验场景: 使用余弦相似度比较2个文件相似性,并可视化词频相似向量
实验代码:
"""
以图搜图:余弦相似度(Cosine Similarity)查找相似文本的原理与实现
实验目的:比较2个文件相似性
实验环境:Win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1 | Matplotlib 3.7.1 | jieba 0.42.1
实验时间:2023-11-30
实例名称:txtConsineSimilarity_v1.3.py
"""
import re
import numpy as np
import jieba
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.feature_extraction.text import CountVectorizer
# 预处理目标文本
def preprocess_text(text):
print(f"文本文件内容:{text}")
# 将文本转换为小写
text = text.lower()
print(f"将文本转为小写:{text}")
# 移除标点符号、数字和中文标点符号
text = re.sub(r'[^a-z\u4e00-\u9fa5\s]', '', text)
print(f"移除标点符号后:{text}")
# 使用 jieba 进行中文分词
text_words = jieba.cut(text)
# 将分词结果拼接成字符串
processed_text = ' '.join(text_words)
print(f"将分词结果拼接成字符串:{processed_text}")
return processed_text
def cosine_similarity(vector1, vector2):
# 将二维列向量转换为一维数组
vector1 = vector1.flatten()
vector2 = vector2.flatten()
# 算向量 vector1 和 vector2 的点积,即对应元素相乘后相加得到的标量值
dot_product = np.dot(vector1, vector2)
# 计算向量 vector1 的 L2 范数,即向量各元素平方和的平方根
norm_vector1 = np.linalg.norm(vector1)
# 计算向量 vector2 的 L2 范数
norm_vector2 = np.linalg.norm(vector2)
# 避免除零错误
if norm_vector1 == 0 or norm_vector2 == 0:
return 0
# 利用余弦相似度公式计算相似度,即两个向量的点积除以它们的 L2 范数之积
similarity = dot_product / (norm_vector1 * norm_vector2)
return similarity
# 获取文件余弦相似度
def get_cosine_similarity(origin_file, target_file):
# 读取原始文本
with open(origin_file, 'r', encoding='utf-8') as file:
origin_text = file.read()
# 预处理原始文本
origin_context = preprocess_text(origin_text)
print(f"预处理原始文本:{origin_context}")
# 构建文本向量:使用词袋模型表示文本,过滤停用词
origin_vectorizer = CountVectorizer(stop_words='english')
# 使用 CountVectorizer 将原始文本 origin_context 转换为词袋模型的向量表示
origin_vector = origin_vectorizer.fit_transform([origin_context])
print(f"原文件词频矩阵:\n{origin_vector}")
# 转置矩阵,确保维度相同
origin_vector = origin_vector.T
# 获取特征单词列表
feature_names = origin_vectorizer.get_feature_names_out()
print(f"原文件特征单词列表:{feature_names}")
print(f"原文件词频向量:\n{origin_vector.toarray()}")
with open(target_file, 'r', encoding='utf-8') as file:
target_text = file.read()
target_context = preprocess_text(target_text)
print(f"预处理目标文本:{target_context}")
# 构建文本向量:使用词袋模型表示文本,过滤停用词,并确保与查找源的向量维度一致
target_vectorizer = CountVectorizer(stop_words='english', vocabulary=feature_names)
target_vector = target_vectorizer.fit_transform([target_context])
print(f"目标文件词频矩阵:\n{target_vector}")
# 转置矩阵,确保维度相同
target_vector = target_vector.T
print(f"目标文件转置矩阵:\n{target_vector}")
print(f"目标文件词频向量:\n{target_vector.toarray()}")
# 计算余弦相似度
similarity = cosine_similarity(origin_vector.toarray(), target_vector.toarray())
print(f"文件 {target_file},与原文件 {origin_file} 的相似值:{similarity}")
# 可视化文本向量
show_text_vectors(origin_vector.toarray(), target_vector.toarray(), feature_names)
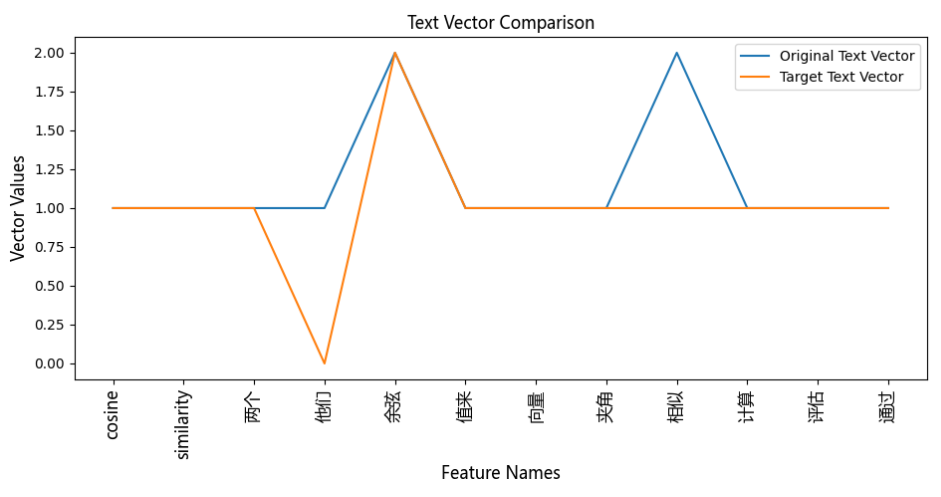
def show_text_vectors(origin_vector, target_vector, feature_names):
# 设置中文字体
font = FontProperties(fname="../../P0_Doc/fonts/msyh.ttc", size=12)
plt.figure(figsize=(10, 5))
plt.plot(feature_names, origin_vector, label='Original Text Vector')
plt.plot(feature_names, target_vector, label='Target Text Vector')
plt.title('Text Vector Comparison', fontproperties=font)
plt.xlabel('Feature Names', fontproperties=font)
plt.ylabel('Vector Values', fontproperties=font)
plt.xticks(rotation=90, fontproperties=font)
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == "__main__":
# 本地测试文本素材库
test_dir_path = '../../P0_Doc/txt_data/'
# 本地测试文本素材路径
origin_file = test_dir_path + 'CosineSimilarity_定义_org.txt'
target_file = test_dir_path + 'CosineSimilarity_定义_v1.0.txt'
# 获取文件余弦相似度
get_cosine_similarity(origin_file, target_file)
输出打印:
文件 ../../P0_Doc/txt_data/CosineSimilarity_定义_v1.0.txt,与原文件 ../../P0_Doc/txt_data/CosineSimilarity_定义_org.txt 的相似值:0.9449111825230682
场景2:素材库中查找文件相似性
实验场景: 使用余弦相似度在目标素材库中查找相似文件
实验代码:
"""
以图搜图:余弦相似度(Cosine Similarity)查找相似文本的原理与实现
实验目的:使用余弦相似度在目标素材库中查找相似文件
实验环境:Win10 | python 3.9.13 | OpenCV 4.4.0 | numpy 1.21.1 | Matplotlib 3.7.1 | jieba 0.42.1
实验时间:2023-11-30
实例名称:txtConsineSimilarity_v1.4.py
"""
import os
import re
import time
import numpy as np
import jieba
from sklearn.feature_extraction.text import CountVectorizer
# 预处理目标文本
def preprocess_text(text):
# 将文本转换为小写
text = text.lower()
# 移除标点符号、数字和中文标点符号
text = re.sub(r'[^a-z\u4e00-\u9fa5\s]', '', text)
# 使用 jieba 进行中文分词
text_words = jieba.cut(text)
# 将分词结果拼接成字符串
processed_text = ' '.join(text_words)
return processed_text
def cosine_similarity(vector1, vector2):
# 将二维列向量转换为一维数组
vector1 = vector1.flatten()
vector2 = vector2.flatten()
# 算向量 vector1 和 vector2 的点积,即对应元素相乘后相加得到的标量值
dot_product = np.dot(vector1, vector2)
# 计算向量 vector1 的 L2 范数,即向量各元素平方和的平方根
norm_vector1 = np.linalg.norm(vector1)
# 计算向量 vector2 的 L2 范数
norm_vector2 = np.linalg.norm(vector2)
# 避免除零错误
if norm_vector1 == 0 or norm_vector2 == 0:
return 0
# 利用余弦相似度公式计算相似度,即两个向量的点积除以它们的 L2 范数之积
similarity = dot_product / (norm_vector1 * norm_vector2)
return similarity
# 获取文件余弦相似度
def get_cosine_similarity(origin_file, test_files):
# 读取原始文本
with open(origin_file, 'r', encoding='utf-8') as file:
origin_text = file.read()
# 预处理原始文本
origin_context = preprocess_text(origin_text)
# 构建文本向量:使用词袋模型表示文本,过滤停用词
origin_vectorizer = CountVectorizer(stop_words='english')
# 使用 CountVectorizer 将原始文本 origin_context 转换为词袋模型的向量表示
origin_vector = origin_vectorizer.fit_transform([origin_context])
# 转置矩阵,确保维度相同
origin_vector = origin_vector.T
# 获取特征单词列表
feature_names = origin_vectorizer.get_feature_names_out()
# 遍历测试库中的文本文件,获取文件余弦相似度
for filename in test_files:
with open(filename, 'r', encoding='utf-8') as file:
target_text = file.read()
target_context = preprocess_text(target_text)
# 构建文本向量:使用词袋模型表示文本,过滤停用词,并确保与查找源的向量维度一致
target_vectorizer = CountVectorizer(stop_words='english', vocabulary=feature_names)
target_vector = target_vectorizer.fit_transform([target_context])
# 转置矩阵,确保维度相同
target_vector = target_vector.T
# 计算余弦相似度
similarity = cosine_similarity(origin_vector.toarray(), target_vector.toarray())
print(f"文件 {os.path.basename(filename)},与原文件 {os.path.basename(origin_file)} 的相似值:{similarity}")
# 根据需求设定一个阈值,将相似度大于阈值的文件视为相似文件,并按相似度结果排序,得到相似度最高的文本文件
if (similarity >= 0.9):
text_similarities.append((filename, similarity))
if __name__ == "__main__":
time_start = time.time()
# 本地测试文本素材库
test_dir_path = '../../P0_Doc/txt_data/'
# 本地测试文本素材路径
origin_file = test_dir_path + 'CosineSimilarity_org.txt'
# 指定测试文本文件扩展名
txt_suffix = ['.txt', '.doc', '.md']
# 获取素材库文件夹中所有文件路径
all_files = [os.path.join(test_dir_path, filename) for filename in os.listdir(test_dir_path)]
# 筛选出指定后缀的文件
test_files = [file for file in all_files if any(file.endswith(suffix) for suffix in txt_suffix)]
# 获取素材库文件夹中文件余弦相似度
text_similarities = []
get_cosine_similarity(origin_file, test_files)
# 按相似度降序排序
text_similarities.sort(key=lambda item: item[1], reverse=True)
print(f"按相似度降序排序:{text_similarities}")
# 打印相似度最高的文本文件
print(f"相似度最高的文本文件: {text_similarities[0][0]}, 相似度: {float(text_similarities[0][1]):.4f}")
time_end = time.time()
print(f"耗时:{time_end - time_start}")
输出打印:
文件 CosineSimilarity_org.txt,与原文件 CosineSimilarity_org.txt 的相似值:1.0
文件 CosineSimilarity_v1.0_拷贝版.doc,与原文件 CosineSimilarity_org.txt 的相似值:1.0
文件 CosineSimilarity_v1.1_位置调换版.md,与原文件 CosineSimilarity_org.txt 的相似值:1.0
文件 CosineSimilarity_v1.2_纯代码版.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.6402964041311439
文件 CosineSimilarity_v1.3_删减版.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.9704511815935536
文件 CosineSimilarity_v1.4_删减版2.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.4919253465224834
文件 CosineSimilarity_v1.5_无可视化版.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.9811481821202109
文件 CosineSimilarity_v1.6_复杂版.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.8590656537770545
文件 CosineSimilarity_定义_org.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.3587392083132991
文件 CosineSimilarity_定义_v1.0.txt,与原文件 CosineSimilarity_org.txt 的相似值:0.3311241245802555
按相似度降序排序:[('../../P0_Doc/txt_data/CosineSimilarity_org.txt', 1.0), ('../../P0_Doc/txt_data/CosineSimilarity_v1.0_拷贝版.doc', 1.0), ('../../P0_Doc/txt_data/CosineSimilarity_v1.1_位置调换版.md', 1.0), ('../../P0_Doc/txt_data/CosineSimilarity_v1.5_无可视化版.txt', 0.9811481821202109), ('../../P0_Doc/txt_data/CosineSimilarity_v1.3_删减版.txt', 0.9704511815935536)]
相似度最高的文本文件: ../../P0_Doc/txt_data/CosineSimilarity_org.txt, 相似度: 1.0000
耗时:0.6692209243774414
2.2.5 实验总结
余弦相似度通常在处理大规模文本数据时具有较好的性能,但对于一些需要考虑语法和语义信息的任务,可能需要使用更复杂的模型或度量方法。
优点
- 简单有效:余弦相似度的计算方法相对简单,容易理解和实现。这使得它成为许多文本相似性比较任务的首选方法之一。
- 不受文本长度影响: 余弦相似度不受文本长度的影响,只受文本向量的方向角度影响。因此,对于不同长度的文本,余弦相似度可以更公正地评估它们之间的相似性。
- 适用于高维空间: 在高维空间中,余弦相似度的性能通常比欧几里德距离等其他相似性度量更好。这使其在自然语言处理中处理文本向量时非常有用。
缺点
- 不考虑词序信息: 余弦相似度只考虑文本中词汇的出现频率,而不考虑它们的顺序。这意味着它可能无法捕捉到语法结构或上下文信息,对于语义上相似但词序不同的文本可能判断不准确。
- 对稀疏向量不敏感: 当文本表示为稀疏向量时(比如使用词袋模型),余弦相似度可能对于共享少量相同词汇的文本给出相似性度量过高的结果,因为它只关注共同出现的词,而不考虑它们的重要性。
- 无法处理一词多义: 余弦相似度在处理一词多义时存在问题,因为它只基于词汇的出现频率而不考虑语境。同一个词在不同的上下文中可能有不同的含义,但余弦相似度无法捕捉这种语义信息。
2.2.6 实验异常
异常现象1
Traceback (most recent call last):
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\imgCosine_v2.1.py", line 56, in <module>
text_similarities = get_cosine_similarity(test_dir_path)
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\imgCosine_v2.1.py", line 34, in get_cosine_similarity
similarity = cosine_similarity(origin_vector.toarray(), target_vector.toarray())
File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\sklearn\metrics\pairwise.py", line 1393, in cosine_similarity
X, Y = check_pairwise_arrays(X, Y)
File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\sklearn\metrics\pairwise.py", line 180, in check_pairwise_arrays
raise ValueError(
ValueError: Incompatible dimension for X and Y matrices: X.shape[1] == 107 while Y.shape[1] == 100
异常原因: 2个向量维度不一致。
问题出现在 cosine_similarity 函数的调用上。cosine_similarity 函数的参数 X 和 Y 应该是形状相同的矩阵,但是在测试代码中,origin_vector 和 target_vector 的维度不一致。即,2个测试文件的行数不对等。
在这里,origin_vector 是由原始文本构建的文本向量,而 target_vector 是由目标文本构建的文本向量。这两个向量的维度应该是相同的,以便进行余弦相似度的计算。
注: from sklearn.metrics.pairwise import cosine_similarity,scikit-learn 的 cosine_similarity 函数的输入是两个形状相同的矩阵。
异常现象2
文件名称 CosineSimilarity_v2.1.txt,与目标文件 ../../P0_Doc/txt_data/CosineSimilarity_org.txt 的相似值:[[1. 1. 1. ... 1. 1. 1.]
[1. 1. 1. ... 1. 1. 1.]
[1. 1. 1. ... 1. 1. 1.]
...
[1. 1. 1. ... 1. 1. 1.]
[1. 1. 1. ... 1. 1. 1.]
[1. 1. 1. ... 1. 1. 1.]]
Traceback (most recent call last):
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\imgCosine_v2.1.py", line 74, in <module>
text_similarities.sort(key=lambda item: item[1], reverse=True)
ValueError: operands could not be broadcast together with shapes (101,34) (101,31)
异常原因: 2个向量维度不一致。
注:错误的信息显示两个数组的形状分别是 (107, 37) 和 (107, 34),这说明两个数组的列数不同,元素的形状 (shape) 不匹配,导致无法进行排序。
这个问题可能是由于某些文本文件的长度(词的数量)与其他文件不同,导致余弦相似度计算时形状不一致。你可以在计算余弦相似度之前,将向量长度调整为一致的。
异常现象3
similarity = cosine_similarity(origin_vector.toarray(), target_vector.toarray())
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\imgCosine_v2.1.py", line 23, in cosine_similarity
dot_product = np.dot(vector1, vector2)
File "<__array_function__ internals>", line 5, in dot
ValueError: shapes (101,1) and (101,1) not aligned: 1 (dim 1) != 101 (dim 0)
异常原因: 2个向量维度不一致。
解决方案:可参考上述实验二完整代码。
注:可以将 origin_vector 和 target_vector 转置后再计算余弦相似度。目的是确保目标文本向量与原始文本向量具有相同的维度。
在使用 OpenCV 进行余弦相似度计算时,可能会遇到目标文本向量与原始文本向量维度不一致的问题。这可能是因为在构建文本向量时,使用的文本处理方法或者参数不同导致的。可以通过以下方法尝试解决维度不一致的问题:
- 检查文本内容是否正确:确保你读取的文本文件中的内容没有问题。你可以打印出原始文本和目标文本,检查是否包含了无效字符或者其他异常。
- 检查文本向量的维度:在构建文本向量后,使用 .shape 属性检查它们的维度。确保它们的维度是相同的。
异常现象4
Traceback (most recent call last):
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\txtCosine_v2.1 copy.py", line 102, in <module>
get_cosine_similarity(origin_file, target_file)
File "d:\Ct_ iSpace\Wei\Python\iPython\T30_Algorithm\P2_Algo\02_CosineSimilarity\txtCosine_v2.1 copy.py", line 50, in get_cosine_similarity
origin_vector = origin_vectorizer.fit_transform([origin_context])
File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\sklearn\feature_extraction\text.py", line 1388, in fit_transform
vocabulary, X = self._count_vocab(raw_documents, self.fixed_vocabulary_)
File "D:\Tp_Mylocal\20_Install\python-3.9.13\lib\site-packages\sklearn\feature_extraction\text.py", line 1294, in _count_vocab
raise ValueError(
ValueError: empty vocabulary; perhaps the documents only contain stop words
异常原因: 这个错误表明在文本预处理过程中,由于某些原因导致词汇表为空。这通常发生在文本中只包含停用词或特定的无效文本内容,导致无法构建有效的词汇表。
3. 环境依赖
如果 Matplotlib 库没有安装,可以使用以下命令安装:
pip install matplotlib
查看 Matplotlib 版本号:
import matplotlib
print("matplotlib 版本号:", matplotlib.__version__)
如果 jieba 库没有安装,可以使用以下命令安装:
pip install jieba
查看 jieba 版本号:
import jieba
print("jieba 版本号:", jieba.__version__)
4. 系列书签
均值哈希算法: OpenCV书签 #均值哈希算法的原理与相似图片搜索实验
感知哈希算法: OpenCV书签 #感知哈希算法的原理与相似图片搜索实验
差值哈希算法: OpenCV书签 #差值哈希算法的原理与相似图片搜索实验
直方图算法: OpenCV书签 #直方图算法的原理与相似图片搜索实验
余弦相似度: OpenCV书签 #余弦相似度的原理与相似图片/相似文件搜索实验
原文地址:https://blog.csdn.net/itanping/article/details/135296697
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!