数据库 和 SQL 和 索引事务 和 Java数据库编程(JDBC)
一、初识数据库
![]() 什么是数据库?和数据结构有什么关系?
什么是数据库?和数据结构有什么关系?
数据库是“一类软件”,能够针对数据进行管理。数据结构,也是针对数据进行管理。所以,数据库其实就是一个“基于数据结构”实现出来的软件。
![]() 有哪些常用数据库?
有哪些常用数据库?
数据库分为关系型数据库和非关系型数据库。
关系型数据库:对于存储的数据,格式上有严格的要求。
MySQL(免费)
Oracle(最好的数据库)
SQL Server(学校经常使用)
SQLite(非常轻,嵌入在安卓系统内部,只有一个可执行文件,大小是500多kb)
非关系型数据库:存储方式比较灵活,相比关系型数据库功能更少,但性能更快,也更好的适应分布式环境。
Redis、MongoDB、HBase
![]() 选取MySQL进行学习:MySQL是 客户端服务器 结构的软件。
选取MySQL进行学习:MySQL是 客户端服务器 结构的软件。
MySQL/Oracle/SQL Server是软件,SQL是运行在软件上的编程语言(结构化的查询语言)。
选取了MySQL进行学习。
MySQL是 客户端服务器 结构的软件。下图左边是客户端,右边是服务器
客户端(client):主动发送数据的一方。 服务器(server):被动接收数据的一方。 客户端给服务器发送的数据,叫做请求(request)。 服务器给客户端返回的数据,叫做响应(response)。 正常情况下,一个服务器可以同时给多个客户端提供服务。多个客户端可以同时给一个服务器发送请求,服务器进行对应的响应。特殊情况下,一个服务器只给特定的一个客户端提供服务,这种情况一般出现在分布式系统,各个节点之间的通信。
客户端和服务器可以安装在不同主机上,也可以安装在同一台主机上。无论是不是在同一个主机上,客户端和服务器之间都是通过网络进行通信的。当客户端和服务器安装在同一台主机上,通过电脑上的环回网卡,可以自己发送自己接收,所以不联网也可以进行通信。
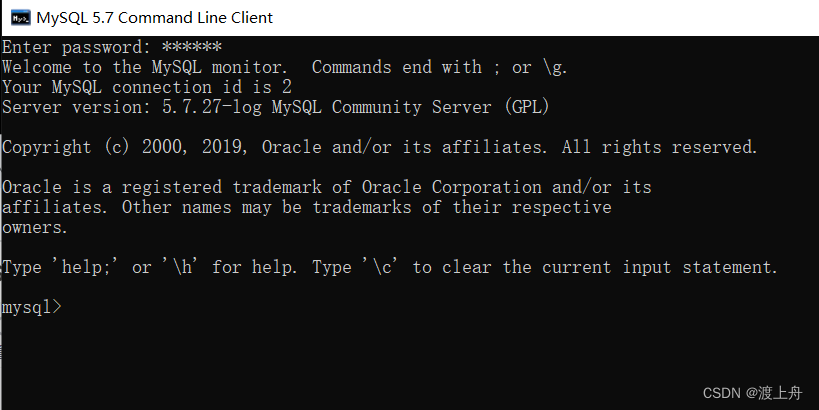
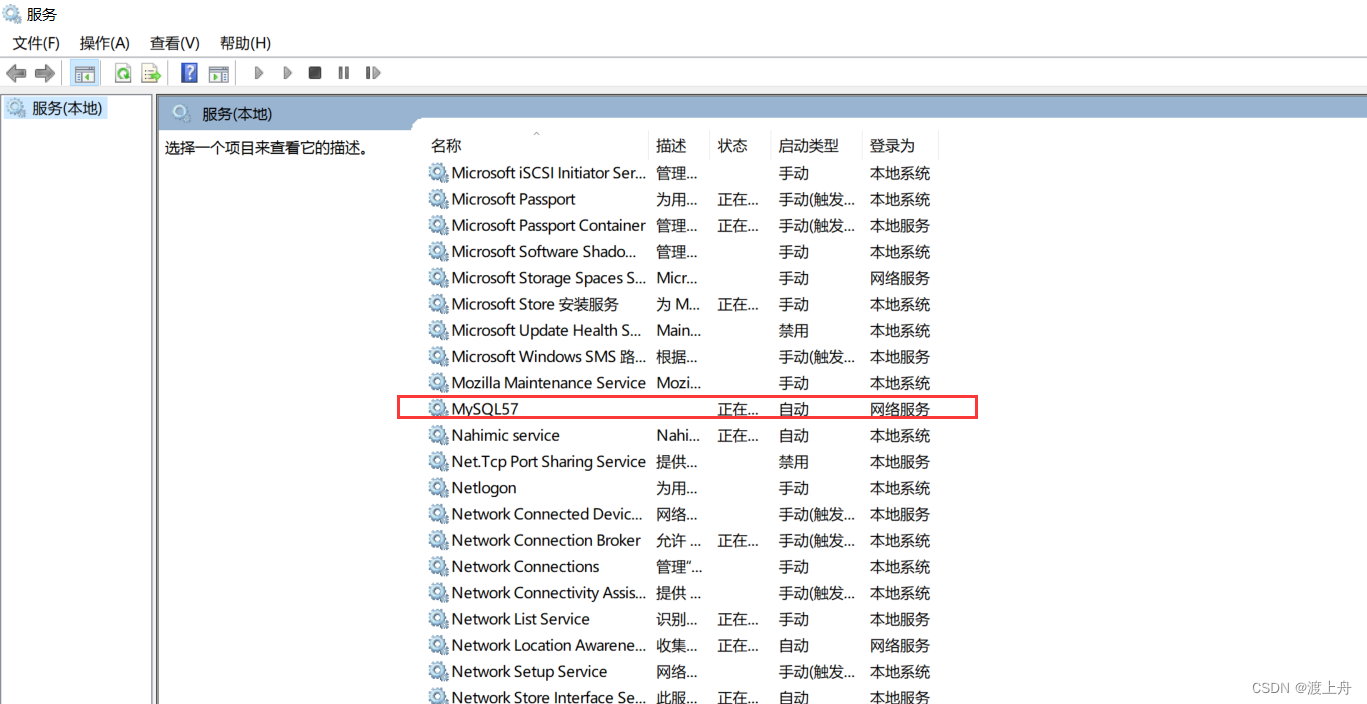
![]() 服务器是存储数据的本体,数据存储在主机的硬盘中
服务器是存储数据的本体,数据存储在主机的硬盘中
在客户端上输入SQL语句,服务器返回执行结果。
客户端是和用户交互的部分,服务器是存储数据的本体。数据存储在主机的硬盘中,数据库是在操作硬盘。硬盘属于外存。所以数据库存储的数据,存储空间大,且能持久化保存。
mysql默认的用户名是root,localhost是主机名,表示你自己当前的电脑
![]() 内存和外存的区别:
内存和外存的区别:
- 内存读写数据的速度快,外存读写速度慢(能差三四个数量级,几千~几万倍)
- 内存存储空间小,外存存储空间大
- 内存比外存贵
- 内存的数据“易失”,断电后数据就会丢失;外存的数据是“持久的”,断电之后,数据还在。
![]() SQL是通过 数据库的 SQL解析执行引擎来执行的,MySQL的存储引擎是 InnoDB
SQL是通过 数据库的 SQL解析执行引擎来执行的,MySQL的存储引擎是 InnoDB
MySQL中有多个引擎,如:SQL解析执行引擎,存储引擎
SQL是通过 数据库的 SQL解析执行引擎 来执行的,这里涉及到一些优化。执行引擎会自动评估,哪种方案成本最低,速度最快。具体这次查询,走不走索引,怎么走的,都不好预期。
存储引擎,实现了 数据库如何在硬盘上组织数据,MySQL的存储引擎是 InnoDB
二、SQL
接下来我们来学习SQL这个编程语言。
 一个数据库服务器上,可以有多个数据库(这里的数据库指逻辑上用来存储数据的集合,不是软件),一个数据库里,可以有多个数据表。表中,每一行是一条数据,称为记录(record),每一列是一个字段(field)。对于关系型数据库,要求表中每一列的数目和列中的类型要保持一致。
一个数据库服务器上,可以有多个数据库(这里的数据库指逻辑上用来存储数据的集合,不是软件),一个数据库里,可以有多个数据表。表中,每一行是一条数据,称为记录(record),每一列是一个字段(field)。对于关系型数据库,要求表中每一列的数目和列中的类型要保持一致。
字符集:一般创建数据库的时候要指定字符集。对于GBK和unicode编码,汉字占2个字节(0~65535)。对于utf-8/utf8/UTF-8/UTF8,汉字占3个字节
1、关于数据库的操作
create database if not exists 数据库名 charset utf8;
show databases;
use 数据库名;
drop database 数据库名;
 创建数据库
创建数据库
(1)create database xxx charset utf8;
(2)create database if not exists xxx charset utf8;
下面进行详细介绍:

create database xxx charset utf8;
这是创建一个数据库。
如:创建一个数据库test,字符编码是utf8

create database create charset utf-8;
create database `create` charset utf-8;

create database if not exists xxx charset utf8;
如:又创建一个数据库test,该数据库已经存在,就不会在创建。

我们可以通过 show warnings; 来查看警告详情。
show warnings;
如果不加 if not exists,当此数据库已经存在时,就会报错(error),后续SQL语句直接无法执行

查看所有数据库
show databases;
show databases;选中指定的数据库
use xxx;
use xxx;
如:选中数据库test

删除数据库
drop database xxx;
drop database xxx;如:删除数据库test

2、关于数据表的操作
create table if not exists 表名(列名 类型,列名 类型, 列名 类型......);
show tables;
desc 表名;
drop table 表名;数据库中的表,每一列的数据都是有类型的。
下面介绍一下 mysql 的数据类型,标红为常用数据类型
数值类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| bit(M) | M指定位数,默认值是1 | 二进制数,M的范围是1~64,存储数据的范围是0~2^M-1,M为1时,存储数据为0和1,一共2个 | M为1时,对应Boolean |
| tinyint | 1字节 | Byte | |
| smallint | 2字节 | Short | |
| int | 4字节 | Integer | |
| bigint | 8字节 | Long | |
| float(M,D) | 4字节 | 单精度浮点数,M表示有效数字的位数 (第一个非0数字开始,到最后一个数字的位数,就是有效数字的位数,如:12.34、0.001234 都有4位有效数字,3.00、3.0000分别有3位和5位有效数字)。 D表示小数点后保留几位,不适合保存精确的数据 是 IEEE 754 标准 | Float |
| double(M,D) | 8字节 | 双精度浮点数,M表示有效数字的位数(第一个非0数字开始,到最后一个数字的位数,就是有效数字的位数,如:12.34、0.001234 都有4位有效数字,3.00、3.0000分别有3位和5位有效数字)。 D表示小数点后保留几位,不适合保存精确的数据 | Double |
| decimal(M,D) | M/D最大值+2 | 精确表示浮点数,牺牲了存储空间运算速度,换来更精确的表示方式 | BigDecimal |
| numeric(M,D) | M/D最大值+2 | 和decimal一样 | BigDecimal |
字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| varchar(size) | 0~65535字节 | 最常用的表示字符串的类型,带有一个参数, 约定了存储的最大空间。 如:varchar(128)表示这个列最多存128个字符(不是字节)。 当然,并不是你写了128就会真分配这么多, 会动态适应,避免空间的浪费, 且内存最大不会超过你分配的128个字符 所以,我们最好根据实际需求,设置个适合的长度 | String |
| text | 0~65535字节 (约64KB) 64K=2^6*2^10 =2^16=65536 | 适合于更长的字符串(很少见) 假如一篇文章1w字,utf8编码的话,就是3w字节 1B=1/1024KB,3wB约等于30KB,64KB足够用了 | String |
| mediumtext | 0~16777215字节 | 适合于更长的字符串(很少见) | String |
| blob | 0~65535字节 | 主要存二进制数据, 像word .docx excel .xlsx 是二进制存储的 用记事本打开发现根本看不懂,是二进制 | byte[] |
日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| datetime | 8字节 | 范围从1000到9999年, 不会进行时区的检索及转换 | java.util.Date、java.sql.Timestamp |
| timestamp | 4字节 (42亿9千万) | 范围从1970到2038年, 自动检索当前时区并进行转换 | java.util.Date、java.sql.Timestamp |
时间戳:以 1970年1月1日0时0分0秒,为基准时间,计算当前时间和基准时间的秒数/毫秒数/微秒数 之差,这个很大的整数就是时间戳。
创建表
(1)create table 表名(列名 类型,列名 类型, 列名 类型......);
(2)create table if not exists 表名(列名 类型,列名 类型, 列名 类型......);
下面进行详细介绍:
如:在数据库test中创建一个学生表
use test;
create table student(id int,name varchar(20));
create table if not exists student(id int,name varchar(20));
查看指定数据库下的所有表
show tables;
show tables;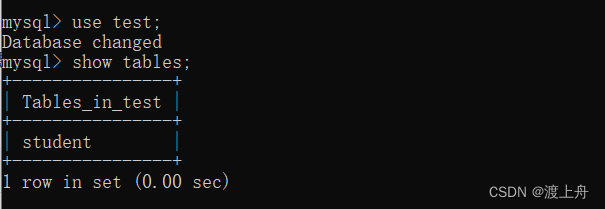
查看指定表的结构
desc 表名;
desc student;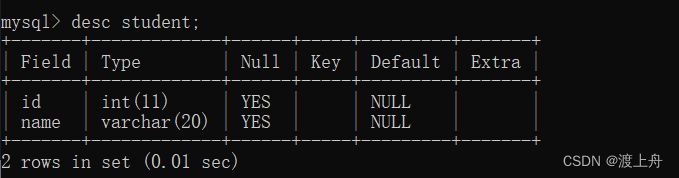
Field:字段,student表中有id和name两个字段,就是2个列名
Type:类型,列名对应的类型。int(11),11表示显示的宽度,不影响存储;varchar(20),20表示最大的长度是20个字符。
Null:是否允许为空,YES表示这个字段允许为空
Key:和列的约束有关,主键外键等啥的
Default:默认值,这两列默认值是NULL
Extra:额外的描述
删除表
drop table 表名;
drop table student;3、增(insert into 表名)
insert into 表名 values(列值,列值,列值......);
insert into 表名 (列名,列名) values(列值,列值);
insert into 表名 values(列值,列值......),(列值,列值......),(列值,列值......)......; 新增一行完整的数据
insert into 表名 values(列值,列值,列值......);
比如,在学生表中新增2个学生
insert into student values(1,"zhangsan");
insert into student values(2,'lisi');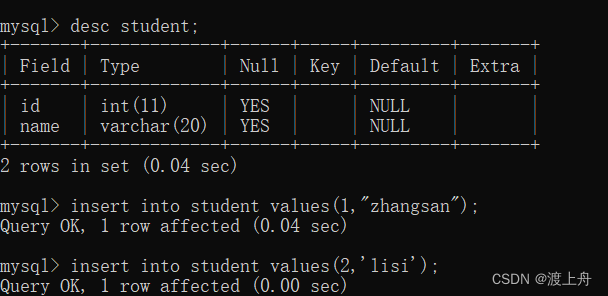
指定列新增一行数据
insert into 表名 (列名,列名) values(列值,列值);
比如,在学生表中指定 id 这一列新增一行数据
insert into student (id) values(3);
一次新增多行数据
insert into 表名 values(列值,列值......),(列值,列值......),(列值,列值......)......;
比如,在学生表中一次新增多行数据
insert into student values(4,'张三'),(5,'李四'),(6,'王五');
4、查(select...from 表名)
select * from 表名;
select 列名,列名... from 表名;
select 列名,表达式...from 表名;
select 列名 as 别名,表达式 as 别名...from 表名;
select distinct 列名,列名......from 表名;
select * from 表名 order by 列名 asc/desc;
select 列名,表达式 as 别名 from 表名 order by 表达式/别名 asc/desc;
select * from 表名 order by 列名 asc/desc,列名 asc/desc;
select 列名 from 表名 where 条件;
select * from 表名 limit n;
select * from 表名 limit n offset m;
select * from 表名 limit m,n;
全列查询,查询表里的所有列
select * from 表名;
比如,查询学生表中所有列
select * from student;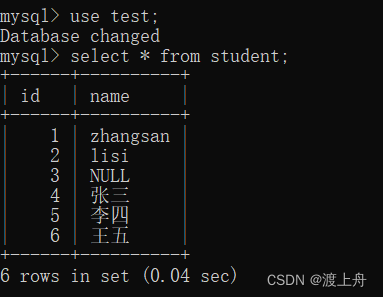
指定列查询
select 列名,列名... from 表名;
比如,查询学生成绩表中的name和chinese列
select name,chinese from student_name; 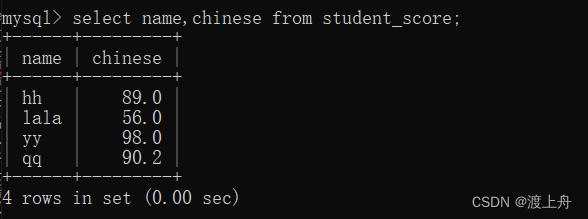
查询列为“表达式”
select 列名,表达式...from 表名;
“表达式”指对列进行的一些运算。
比如,查询学生成绩表中的name列和所有同学的语文成绩都加10的结果(chinese+10)
select name,chinese+10 from student_name;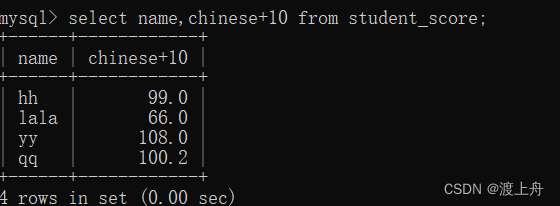
给查询的列指定别名
select 列名 as 别名,表达式 as 别名...from 表名;
比如,给学生成绩表中的name起个别名student_name,或者给chinese+maths起个别名total
select name as student_name from student_score;
select name,chinese+maths as total from student_score;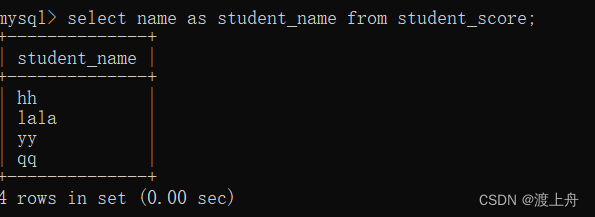

查询的时候,针对列去重
select distinct 列名,列名......from 表名;
比如,去重查询学生成绩表中的maths,或去重查询学生成绩表中的chinese和maths
select distinct maths from student_score;
select distinct chinese,maths from student_score; 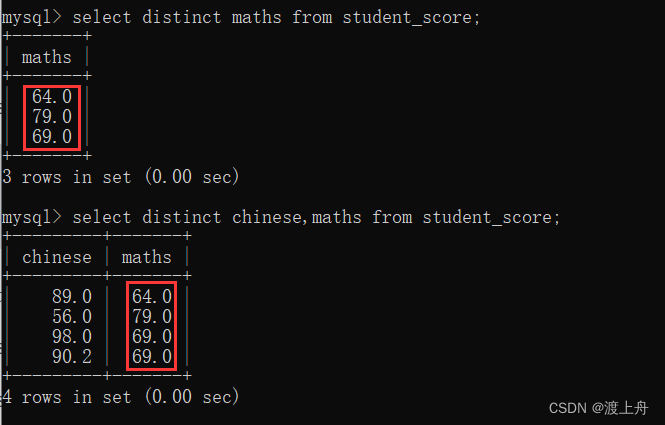
针对查询结果进行排序
(1)select * from 表名 order by 列名 asc/desc;
(2)select 列名,表达式 as 别名 from 表名 order by 表达式/别名 asc/desc;
(3)select * from 表名 order by 列名 asc/desc,列名 asc/desc;
如:按chinese进行排序并全列查询
或 按chinese+maths进行排序并指定列查询
或 指定多个列进行排序并查询
select * from student_score order by chinese;
select * from student_score order by chinese desc;

select name,chinese+maths as score from student_score order by score;
select * from student_score order by maths,chinese desc;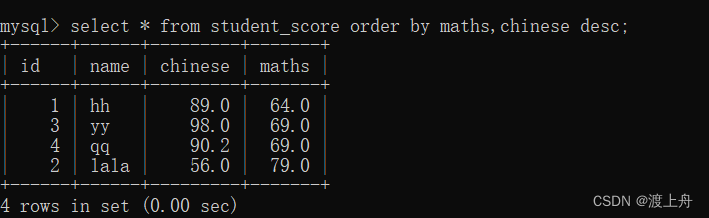
条件查询,针对查询结果,按照一定条件进行筛选
select 列名 from 表名 where 条件;
如:查询学生成绩表中chinese>90或maths>70 的记录
查询学生成绩表中 chinese>maths 的记录
查询学生成绩表中 chinese+maths>140 的记录
查询学生成绩表中 chinese 在[80,90] 之间的记录
查询学生成绩表中 chinese 是 58或59或98或99 的记录
查询学生成绩表中 模糊匹配 % 或 _ 的记录
select * from student_score where chinese>90 or maths>70;
select * from student_score where chinese>maths; 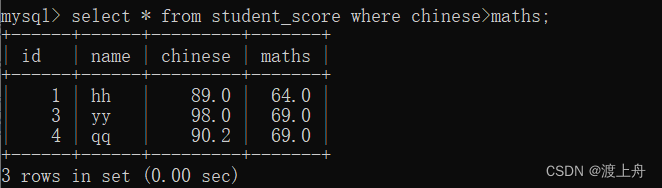
select name,chinese+maths as score from student_score where score>140;
select name,chinese+maths as score from student_score where chinese+maths>140;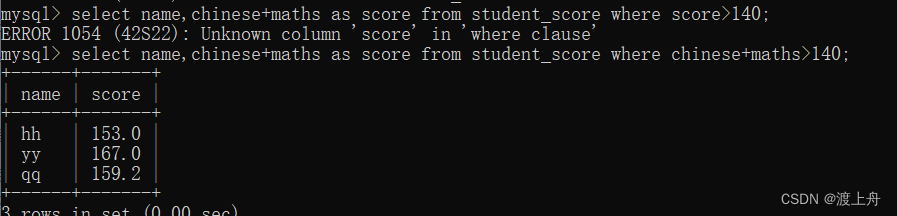
为什么别名不能出现在where条件中呢?
select * from student_score where chinese between 80 and 90;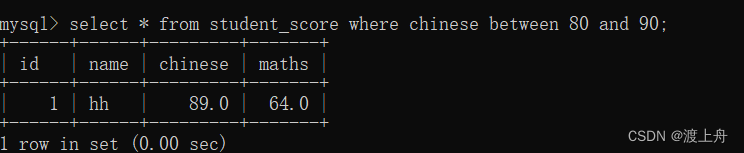
select * from student_score where chinese in(58,59,98,99);
select * from student_score where name like 'y_';
select * from student_score where name like '%y%';
select * from student_score where name like '_y_';

通过limit限制查询结果的数量
(1)select * from 表名 limit n;
(2)select * from 表名 limit n offset m;
(3)select * from 表名 limit m,n;
limit 搭配 offset 就可以指定从第几条开始筛选了(imit 是从1开始,offset的值是从0开始的)
limit n:查到的是前 n 条的记录
limit n offset m:查到的是从 m条开始的 n条记录
limit m,n:查到的是从 m条开始的 n条记录
如:查询学生成绩表中的记录,最多3条
查询从 第0条数据开始的 3条记录
查询从 第3条数据开始的 3条记录
select * from student_score limit 3;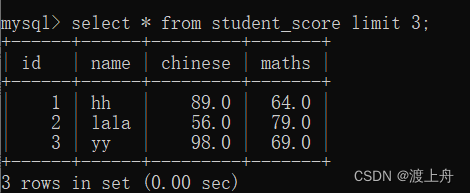
select * from student_score limit 3 offset 0;
select * from student_score limit 3 offset 3;
select * from student_score limit 0,3;
select * from student_score limit 3,3;
5、改(update 表名)
update 表名 set 列名 = 列值 where 条件;
update 表名 set 列名 = 表达式;
update 表名 set 列名 = 列值,列名 = 列值......where 条件;
update 表名 set 列名 = 列值 order by 列名/表达式 limit n;
修改列值
update 表名 set 列名 = 列值 where 条件;
如:将学生成绩表中,maths = 69的记录 的 chinese成绩 设置成 80
update student_score set chinese = 80 where maths = 69;
通过表达式修改列值
update 表名 set 列名 = 表达式;
如:将学生成绩表中,chinese成绩都+5
update student_score set chinese = chinese+5;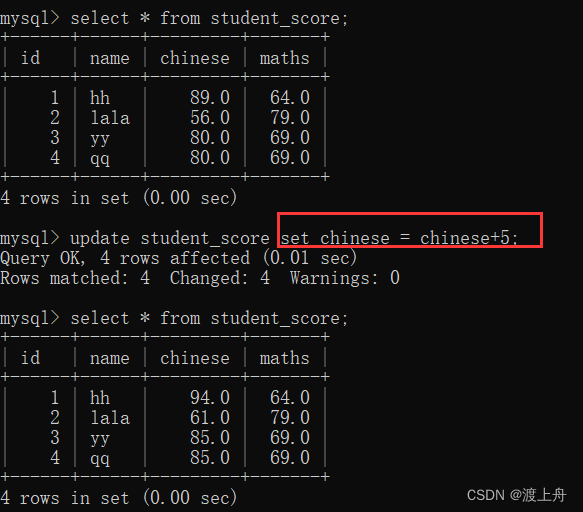
同时修改多个列
update 表名 set 列名 = 列值,列名 = 列值......where 条件;
update student_score set chinese = 92,maths = 64 where name like "y_";
搭配 order by/limit 等子句
update 表名 set 列名 = 列值 order by 列名/表达式 limit n;
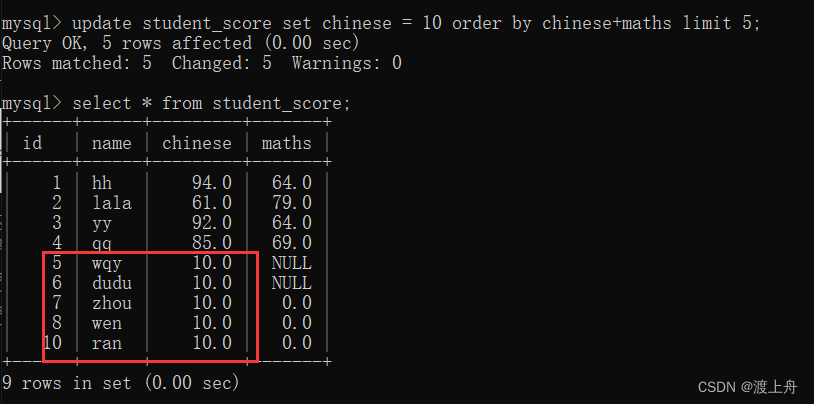
如: 将学生成绩表中,总成绩倒数5名的同学,语文成绩设置成 10
首先 算出 chinese+maths的总和,然后 通过 order by 根据总成绩 进行升序,通过 limit 限制修改数量为5,最后把 chinese 设置成10
update student_score set chinese = 10 order by chinese+maths limit 5;![]() (1)向学生成绩表中增加数据
(1)向学生成绩表中增加数据
![]()



![]() (2) 查询学生成绩表中总成绩倒数5名的记录
(2) 查询学生成绩表中总成绩倒数5名的记录

![]() (3)将总成绩倒数5名的同学的chinese设置成10
(3)将总成绩倒数5名的同学的chinese设置成10
6、删(delete from 表名)
delete from 表名;
delete from 表名 where 条件;
delete from 表名 order by 列名/表达式 limit n;
删除表中所有的数据
delete from 表名;
搭配where
delete from 表名 where 条件;
如:删除学生成绩表中 name="ran" 的记录
delete from student_score where name = "ran";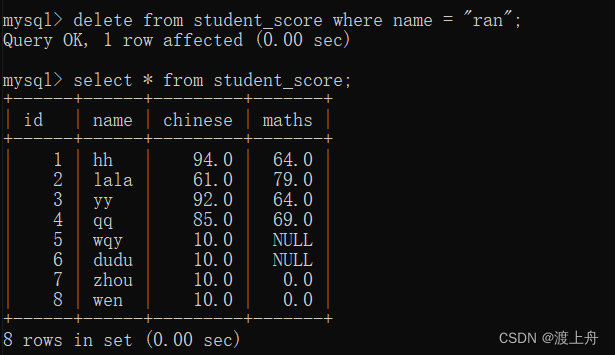
搭配 order by/limit 等子句
delete from 表名 order by 列名/表达式 limit n;
如:删除学生成绩表中 总成绩最小的2名学生的记录
delete from student_score order by chinese+maths limit 2; 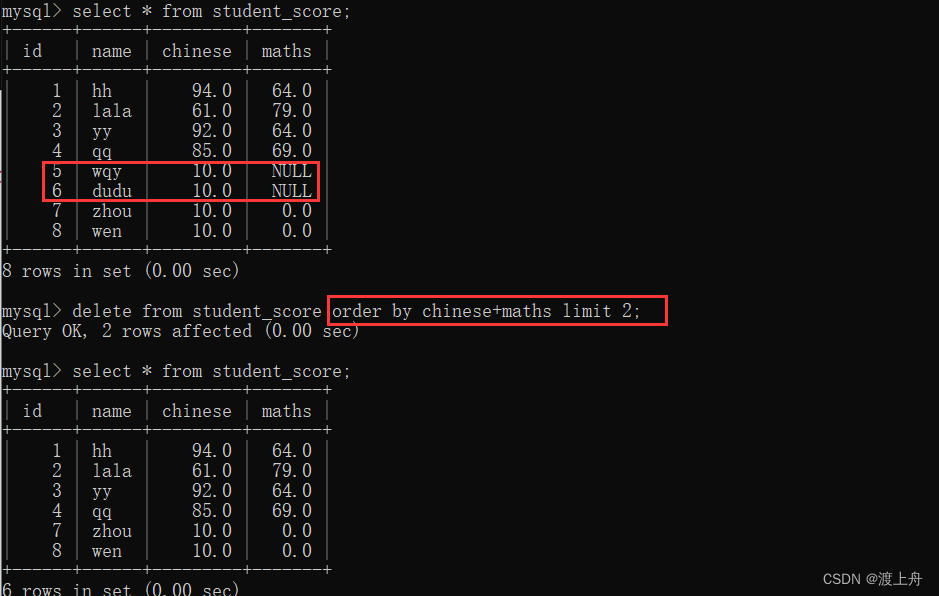
7、数据库约束
not null
如:
create table student (id int not null,name varchar(15));
insert into student values(null,'wqy');//报错了
insert into student values(1,null);//可以

unique
如:
create table student (id int unique,name varchar(15));
insert into student values(1,'wqy');
insert into student values(1,null);//报错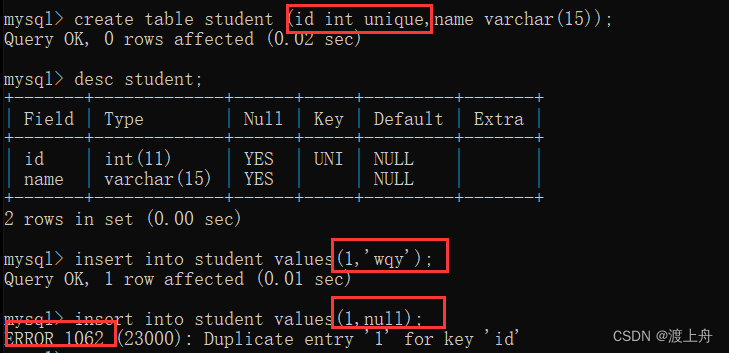
primary key
如:
create table student(id int primary key,name varchar(15));
insert into student values(null,null);//报错
insert into student values(1,null);
insert into student values(1,'wqy');//报错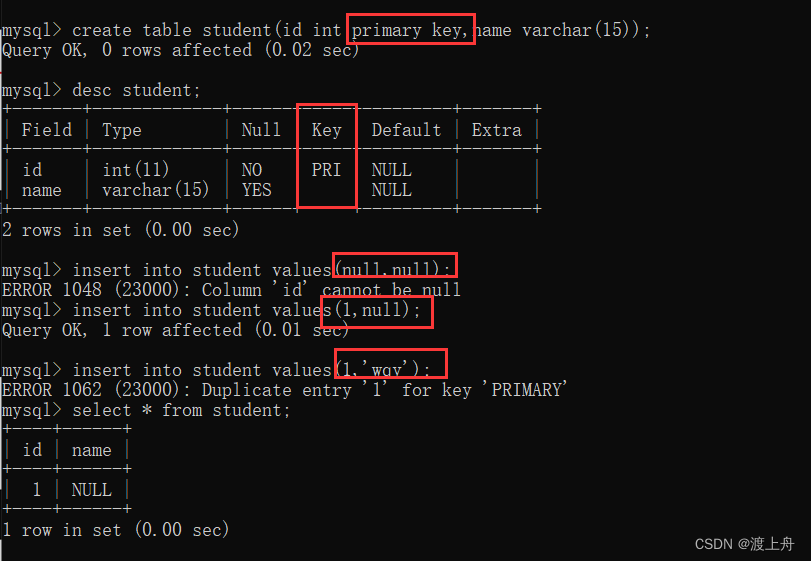
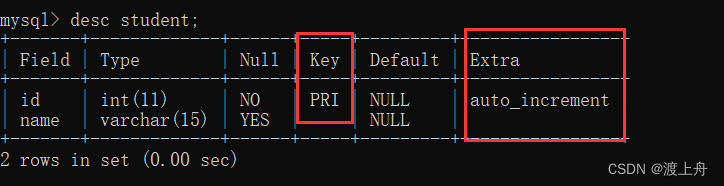
![]() 自增主键:auto_increment
自增主键:auto_increment
这里的null 是交给mysql自增的意思,不是说数据是null
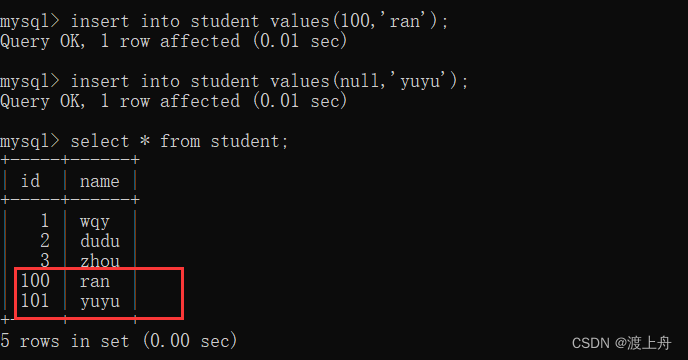
如:
create table student(id int primary key anto_increment,name varchar(15));
insert into student values(null,'wqy');
insert into student values(null,'dudu');
insert into student values(null,'zhou');
insert into student values(100,'ran');
insert into student values(null,'yuyu');![]()

default
如:
create table student(id int,name varchar(15) default '无名氏');
insert into student values(1,'wqy');
insert into student values(2,null);
insert into student(id) values(3);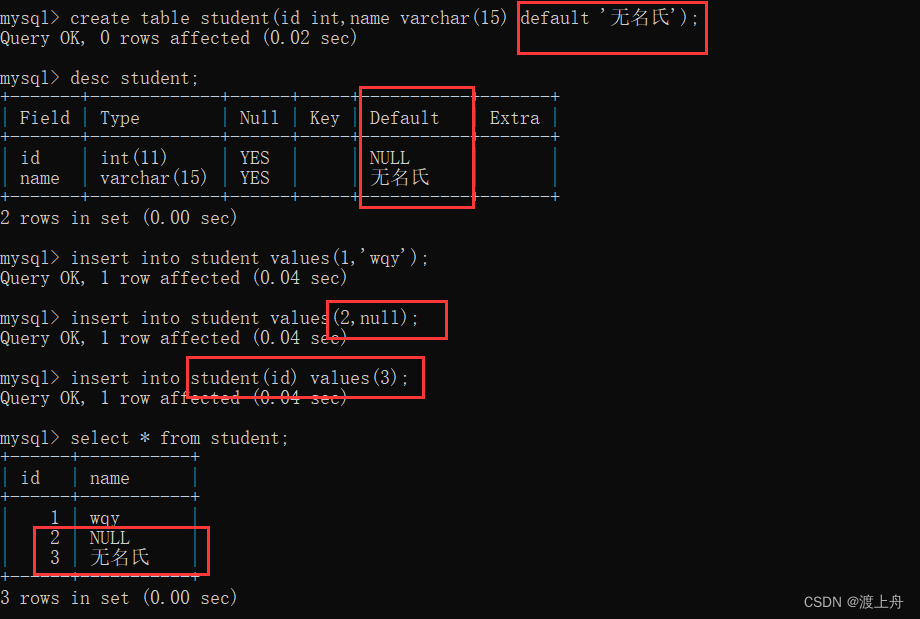
foreign key
如: 有一个学生表(student) 和一个班级表(class) ,要求学生表中学生的班级必须在班级表中存在
分析可知:
学生表和班级表中的数据有了相互约束,1、学生表中的班级必须在班级表中存在,2、班级表中被学生表使用了的班级不能被删除
create table class (id int primary key,name varchar(15));
create table student (id int primary key,name varchar(15),classId int,
foreign key (classId) references class(id));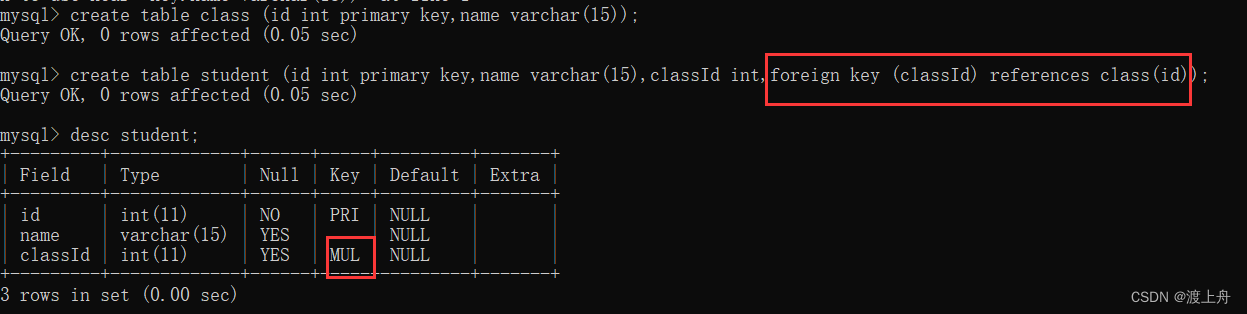
![]() 外键约束对 insert into 有作用:
外键约束对 insert into 有作用:
学生表中无法新增 班级 在班级表中不存在的记录。
insert into student values (1,'wqy',1);
insert into student values (2,'dudu',1);
insert into student values (3,'haha',4);

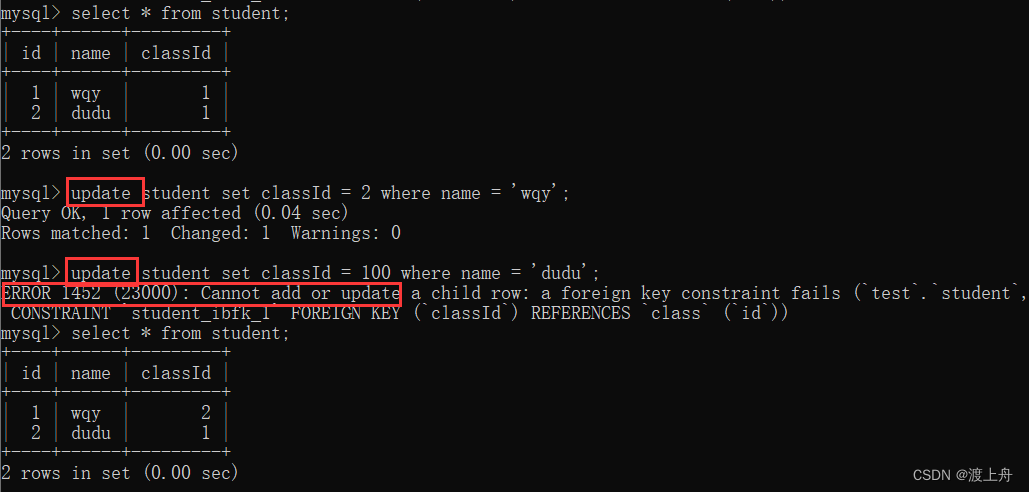
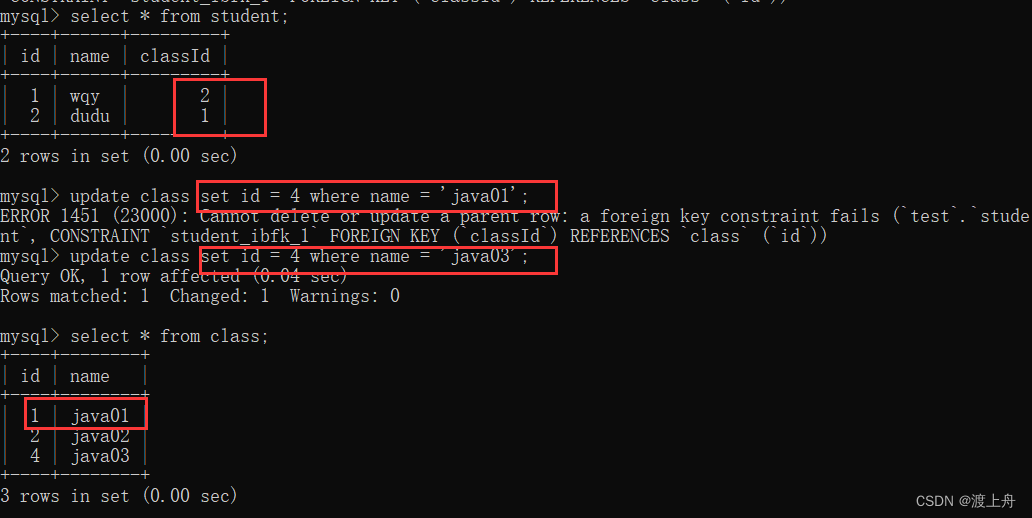
![]() 外键约束对 update 有作用:
外键约束对 update 有作用:
学生表中无法 将班级 修改成班级表中不存在的班级。
班级表中无法 将已在学生表中引用的班级修改成别的。
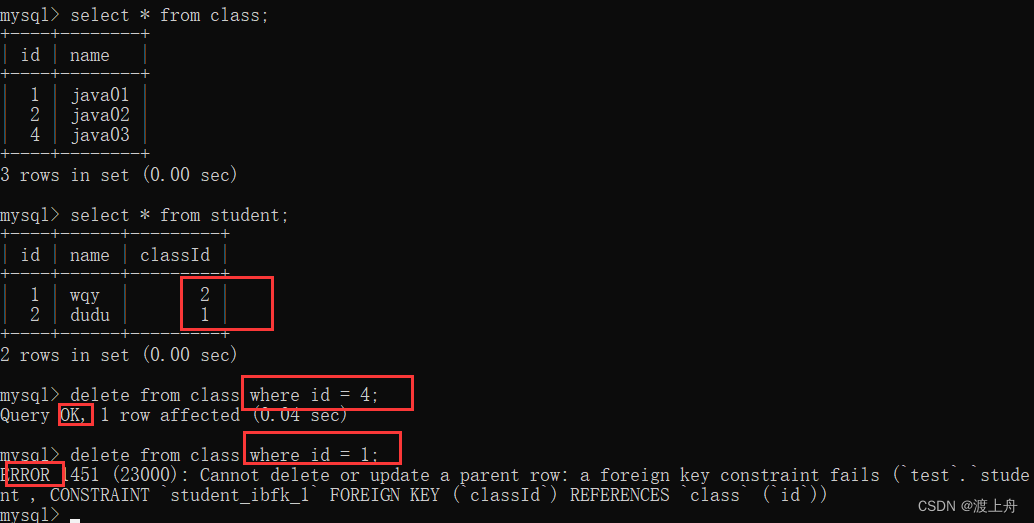
![]() 外键约束对 delete from 有作用:
外键约束对 delete from 有作用:
班级表中 无法删除已在学生表中引用的班级。
若 班级表中的某些班级已被学生表引用,那么也不能删除班级表或班级表中的所有数据。
要想成功删除班级表:1、先删除学生表(子表),再删除班级表(父表)2、删库

8、更复杂的查询
把查询的结果 替代values 新增到另一个表中
如:把student表中 全列查询的结果,新增到student2表中
insert into student2 select * from student;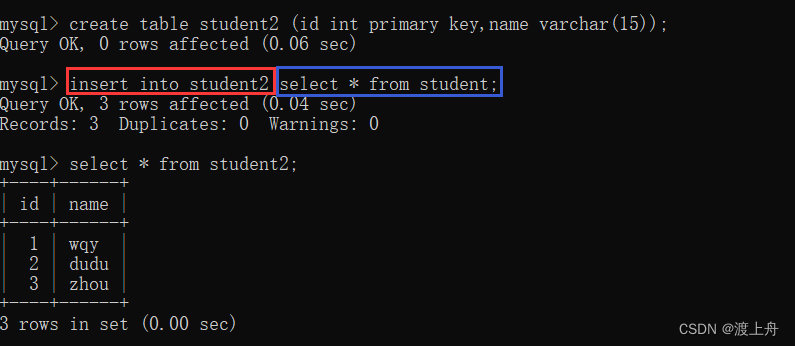
聚合查询
- count():求查询到的结果的 数量
- sum():求这个列所有值的 总和,这个列必须得是数字
- avg():求这个列所有值的 平均值,这个列必须得是数字
- max():求这个列所有值的 最大值,这个列必须得是数字
- min():求这个列所有值的 最小值,这个列必须得是数字
![]() count()
count()
如:
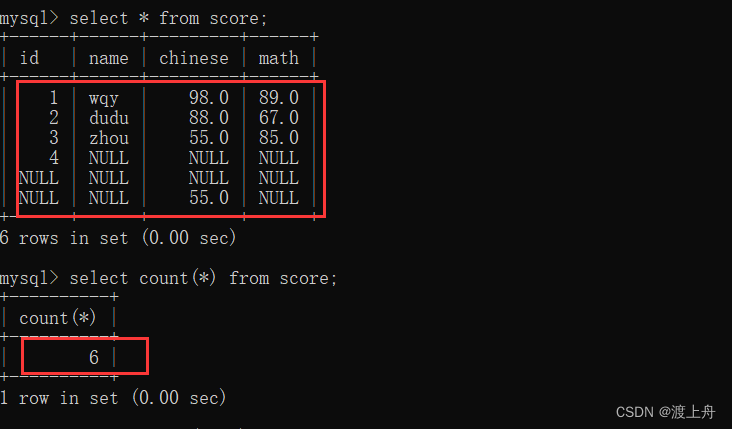
select count(*) from score;
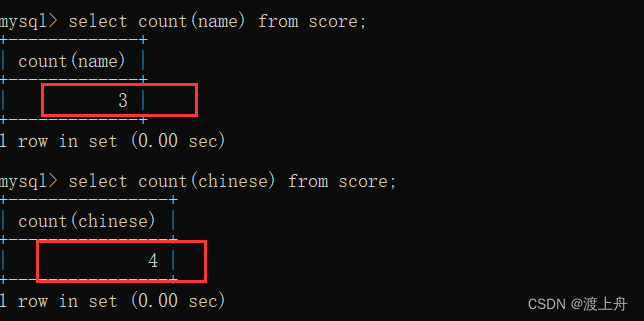
select count(name) from score;
select count(chinese) from score;
select count(chinese+math) from score;
select count(name+1) from score;
select count(chinese+1) from score;
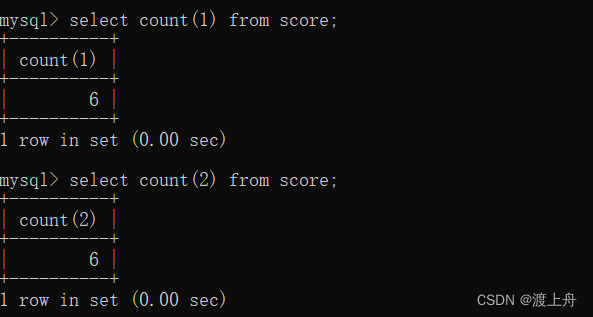
select count(1) from score;
select count(2) from score;

![]() sum() ,avg(),max(),min()
sum() ,avg(),max(),min()
- sum(常量)相当于 常量×count(*),
- avg(常量)相当于 常量×count(*)÷count(*),结果就是该常量
- max(常量),min(常量),结果就是该常量
![]()
select sum(chinese) from score;
select sum(chinese+math) from score;
select sum(chinese+1) from score;
select sum(1) from score;
select sum(2) from score;
![]()
select avg(chinese) from score;
select avg(chinese+math) from score;
select avg(chinese+1) from score;
select avg(1) from score;
select avg(2) from score;
![]()
select max(chinese),min(chinese) from score;
select max(chinese+math),min(chinese+math) from score;
select max(chinese+1),min(chinese+1) from score;
select max(1),min(1) from score;
select max(2),min(2) from score;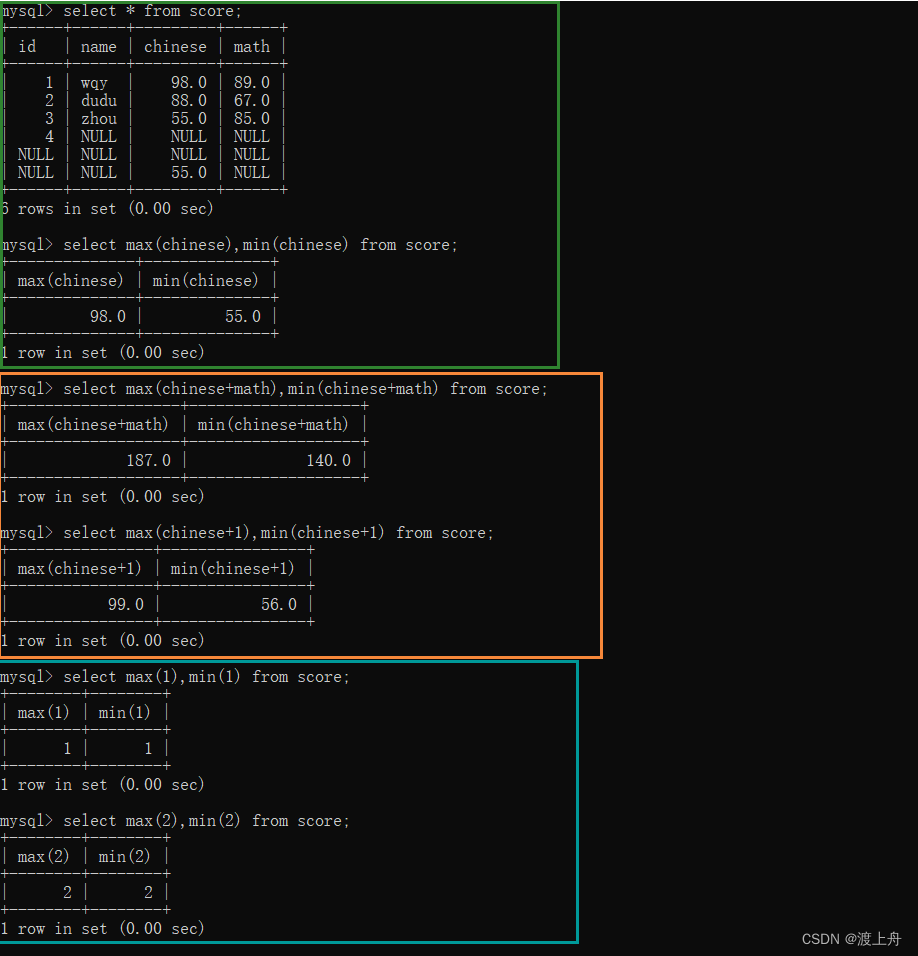
使用 group by 进行分组查询
如:
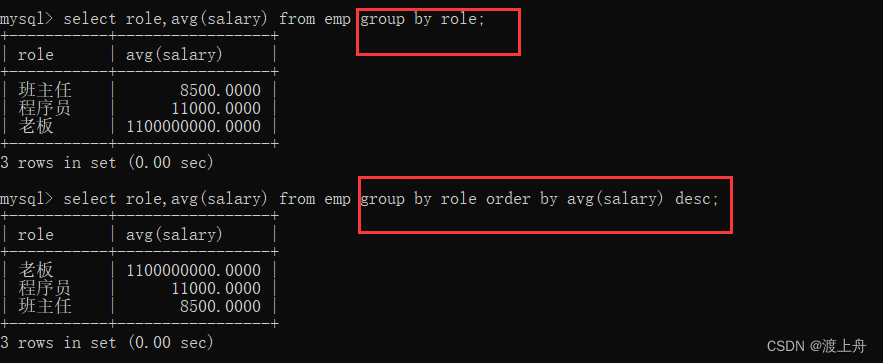
1、统计每个岗位的平均薪资
2、统计每个岗位的平均薪资 并倒序
3、去掉马云的数据后,统计每个岗位的平均薪资
4、统计每个岗位的平均薪资,但是不要平均薪资在10w之上的
5、去掉马云的数据后,统计每个岗位的平均薪资,但是不要平均薪资在10w之上的
6、去掉马云的数据后,统计每个岗位的平均薪资,但是不要平均薪资在10w之上的,并倒序
7、去掉马云的数据后,统计每个岗位的平均薪资,但是不要平均薪资在10w之上的,并倒序,并限制查询结果的最大数量是1



联合查询(多表查询)
![]() 内连接
内连接
如:有3张表,学生表,课程表,和成绩表。3表查询并显示学生和他选的课程的成绩
select student.name as 学生姓名,course.name as 课程名称,score as 成绩
from student,score,course
where student.id = score.student_id and course.id = score.course_id;
select student.name as 学生姓名,course.name as 课程名称,score as 成绩
from student
inner join score on student.id = score.student_id
inner join course on course.id = score.course_id;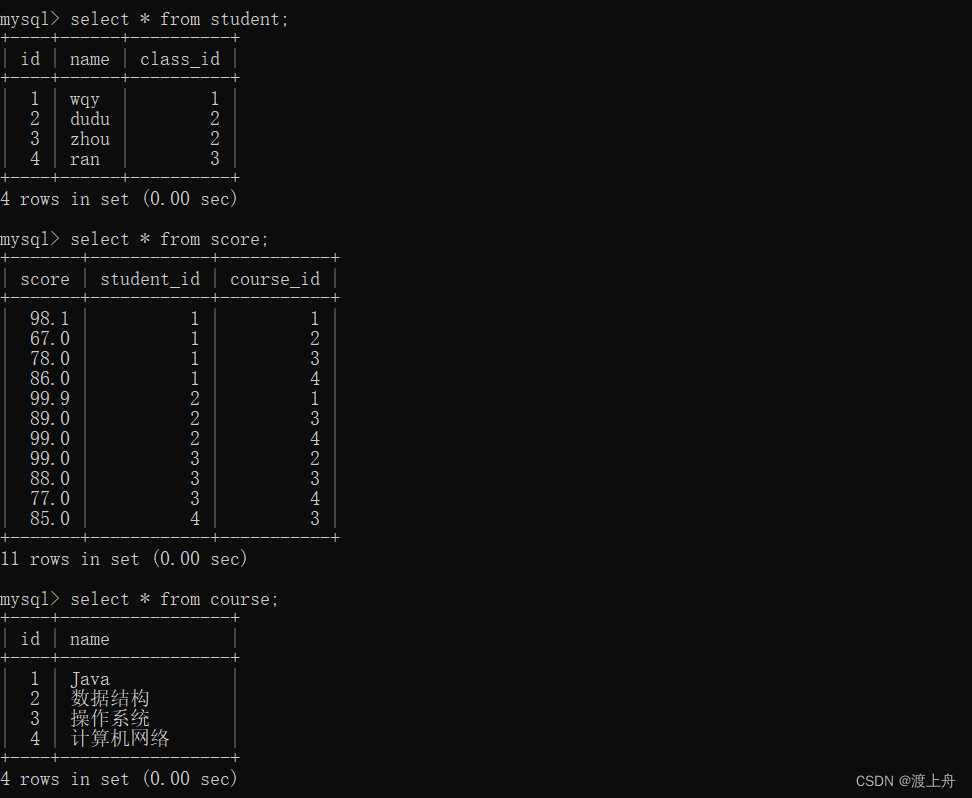

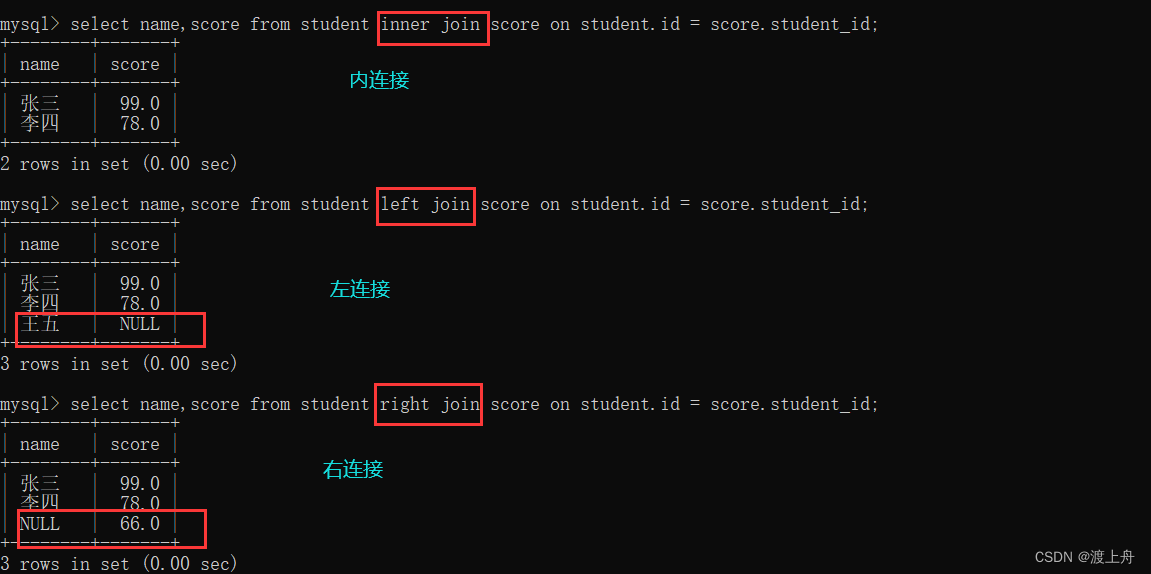
![]() 外连接
外连接
select name,score from student inner join score on student.id = score.student_id;
select name,score from student left join score on student.id = score.student_id;
select name,score from student right join score on student.id = score.student_id;
![]() 自连接
自连接
如:查询成绩表中 这个学生的 操作系统成绩 比 计算机网络成绩 高的
操作系统id是3,计算机网络id是4
select * from score as s1,score as s2
where s1.student_id = s2.student_id
and s1.course_id = 3 and s2.course_id = 4
and s1.score > s2.score;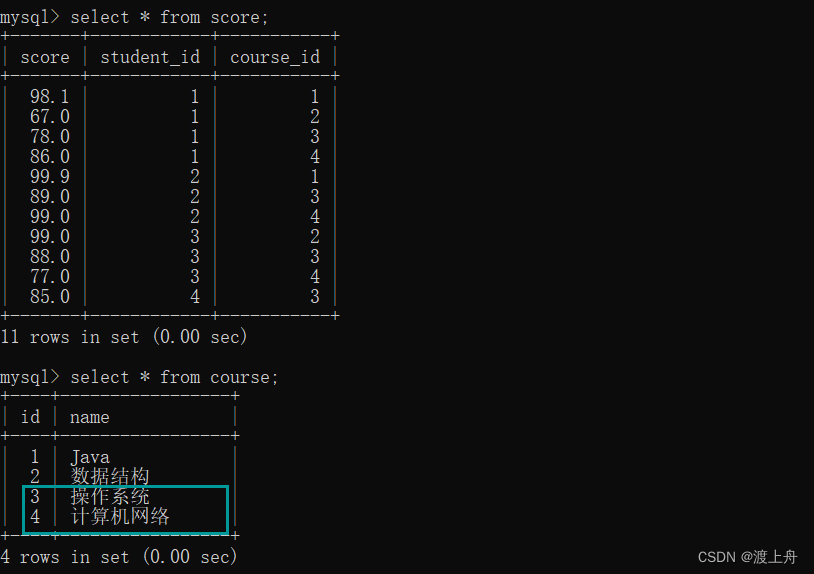

子查询
如:
查询学生 zhou 的同班同学
查询 数据结构 以及 操作系统 这两门课程的所有成绩
select name from student
where class_id = (select class_id from student where name = 'zhou')
and name != 'zhou';
select * from score
where course_id in(select id from course where name = '数据结构' or name = '操作系统');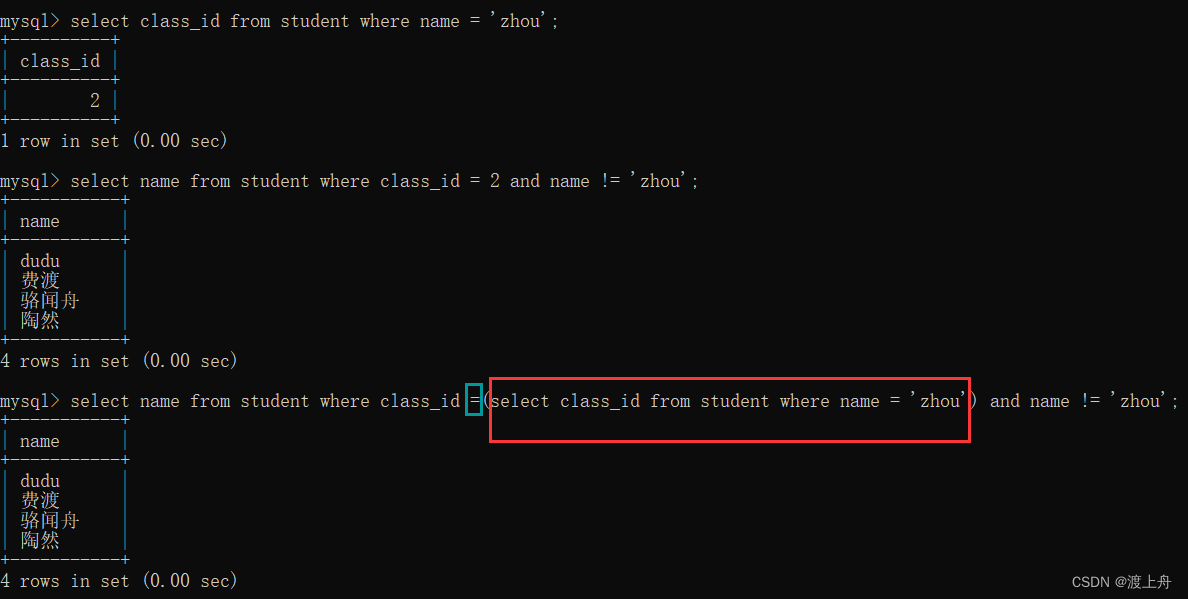

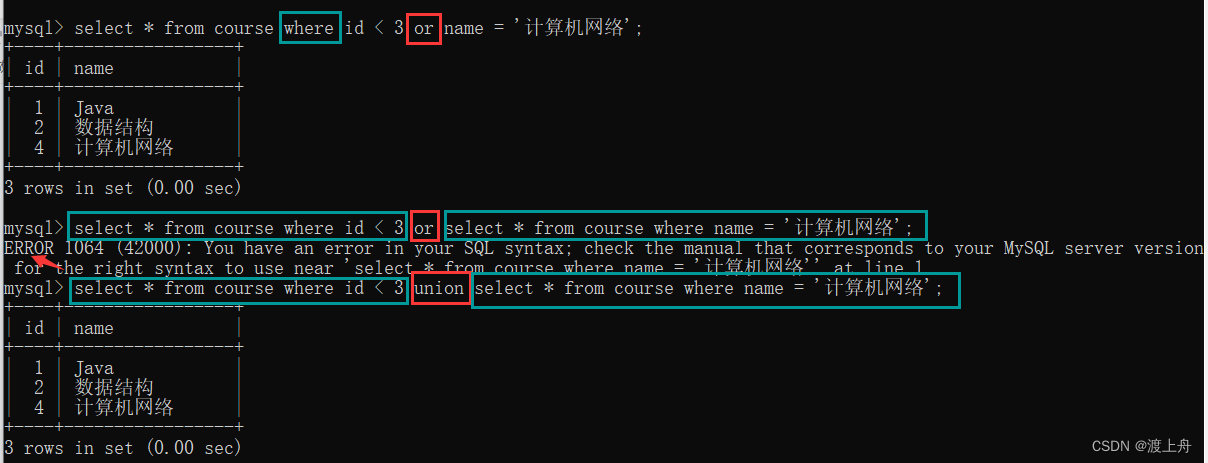
合并查询
- union:会去重,把重复的行只保留一行
- union all:不去重,可以保留多分
- or 只能把查询条件合并,查询结果只能来自同一个表
- union 能把查询语句合并,查询结果可以来自不同的表
如:
查询 id<3 或者 名称是 计算机网络 的课程
查询 id<3的课程 或者 id<3 的学生
select * from course where id < 3
or
name = '计算机网络';
select * from course where id < 3
union
select * from course where name = '计算机网络';
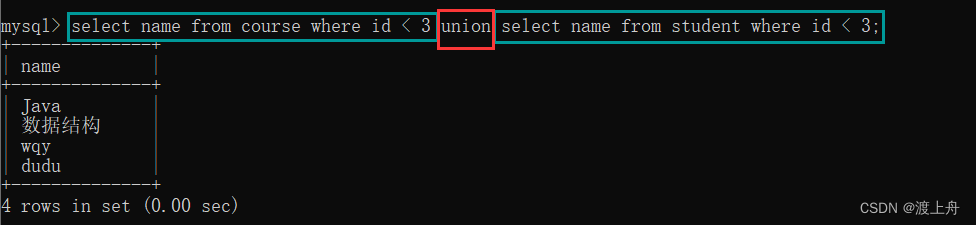
select name from course where id < 3
union
select name from student where id < 3;
三、索引和事务
1、索引
show index from 表名;
create index 索引名 on 表名(列名);
drop index 索引名 on 表名;
索引 是一种数据结构,相当于“书的目录”,能够快速的查找数据。
优点:加快了查找的速度
缺点:
- 提高了 增删改 的开销。因为进行增删改时,需要调整已经创建好的索引。
- 也提高了空间的开销。因为构建索引,需要额外的磁盘(就是硬盘)空间来保存
- 某列如果被 primary key (主键)或 unique (唯一)或 foreign key (外键)约束,那么这一列会自动创建索引
- 如果该表中没有索引,而经常按照某一列来查找,就可以针对这一列创建索引。
- 创建索引最好是创建表时就创建好,因为一旦表中已经有大量数据了,这时候再进行创建索引,就会占用大量的硬盘IO,花很长时间,会影响数据库的正常使用。删除索引也有可能会占用大量的磁盘IO,也是危险操作。
- 并不是所有情况都需要加上索引,如果这一列的重复数据非常多,虽然加了索引,但并不能提高查询速度。比如,给性别列加上索引,性别只有固定的几个,重复数据非常多,加上索引并不能提高查询速度
MySQL的存储引擎InnoDB 的索引的数据结构是啥
 索引 的主要目的是为了加快数据的查找速度,哪些数据结构可以加快查找速度呢?
索引 的主要目的是为了加快数据的查找速度,哪些数据结构可以加快查找速度呢?
但是,哈希表并不适合做数据库的索引,因为哈希表只能比较相等,无法进行大于小于这样的范围查询,而数据库中经常会用到范围查询。不是哈希表
但是,数据库使用的也不是二叉搜索树,因为虽然二叉搜索树可以查起点,查终点,而且树里的元素是有序的,也就是说可以范围查询,但是二叉意味着当元素个数多的时候,树的高度就会比较高,由于数据库的数据 存储在主机的硬盘中,查询元素需要读取硬盘,读取硬盘会很慢,树的高度决定了查询时,硬盘读写的次数,树的高度越高,读写硬盘的次数就越多,查的就越慢。不是二叉搜索树
N叉搜索树,每个节点上有多个值,同时又有多个分叉。树的高度 表示最多的 I/O次数。分叉多了,意味着保存相同元素的时候,树的高度就降低了。查找元素时速度就快了。
对于B树来说,每个节点上的值 可以视为一次磁盘I/O,树的高度 表示最多的 I/O次数。虽然比较的次数没怎么减少(一个节点上可能有多个值,一个节点上可能需要比较多次),但是读写硬盘的次数减少了(树的高度降低了)。树的高度决定了查询时,硬盘读写的次数,在相同数量的总元素个数下,每个节点的元素个数越多,分叉越多,那么 树的高度就越低,查询 所需的磁盘I/O次数就越少。
B+树是对 B树 进一步的改进,B+树 是给 索引 量身定做的 数据结构。B+树 也是 N叉搜索树,但又有一些新的特点。
所以, MySQL的存储引擎InnoDB的 索引的数据结构是 B+树
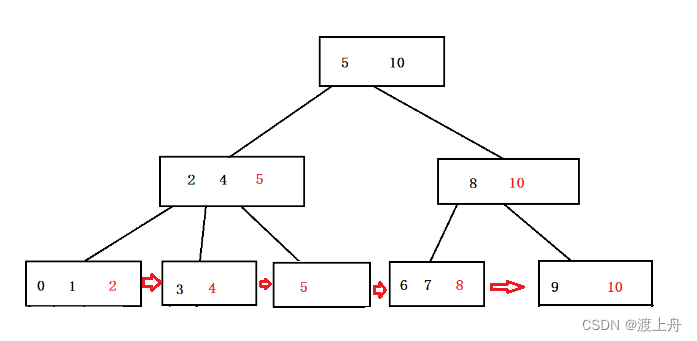
如下图,就是一个B+树:
那么, B+树 有什么特点呢?
使用 B+树 作为MySQL的索引,有什么好处?
- 作为一个 N叉搜索树,高度降低了,比较时 磁盘IO的次数就少了(和B树一样),查的速度就快了。
- 更适合进行范围查询,效率非常高。比如我想查 id>3 and id<10的元素,找到3,找到10,因为叶子节点之间进行了相互连接,很容易就找到了3和10之间的元素。
- 所有的查询,都是要落在叶子节点上的。无论查询哪个元素,中间比较的次数都差不多,查询操作比较均衡。由于都是查叶子节点,所以磁盘I/O的次数是一样的,大家的查询的速度都是一样的。对比B树,对于B树来说,在根节点或者不深的位置时,磁盘I/O的次数就少,查的就快;位置深时,磁盘I/O的次数就多,查的就慢。
- 由于所有的key都会在叶子节点中出现,所以,非叶子结点,不需要存表的真实记录(不需要存数据行),只需要存索引列的值(比如存个id),把真实的一行记录放到叶子节点上。
- 由于非叶子节点只需要存索引列的值,不需要存一整行,这大大降低了非叶子节点占用的空间。那么,非叶子节点就有可能被放进内存进行缓存,这些非叶子节点不在硬盘中,不需要磁盘I/O,进一步降低了硬盘IO的次数,提高了查询速度。
B+树的叶子节点中存的是啥?
有的表,不只有 主键索引,别的非主键列,也有索引。那么这个表就会有2个B+树。
主键索引的B+树,非叶子节点存的是索引列的值,叶子节点存的是数据行;
非主键索引的B+树,非叶子节点存的是索引列的值,叶子节点存的是主键的值。
使用主键索引查询,叶子节点里存的就是 我们要查的整行数据,因此只需要查一次B+树;
使用非主键索引查询,叶子节点里存的是 主键的值,需要先查一遍索引列的B+树,查到主键的值,再查一遍主键列的B+树,查到需要的数据。 即:使用主键索引查询只会查一次,而使用非主键索引查询,还需要回表查询。
索引的总结
索引是为了提高查询速度,提高查询速度,本质上就是在减少磁盘I/O的次数。
树的高度决定了查询时,磁盘I/O的次数。树的高度越低,磁盘I/O的次数越少。
非叶子节点只存索引列的值,叶子节点存数据行/主键的值。
叶子节点之间用类似链表的方式相互连接。
所有的查询,都是落在叶子节点上的。
主键索引,查询只会查一次;非主键索引,查询还需要回表查询。
查看索引
show index from 表名;
如:查看学生表的索引
show index from student;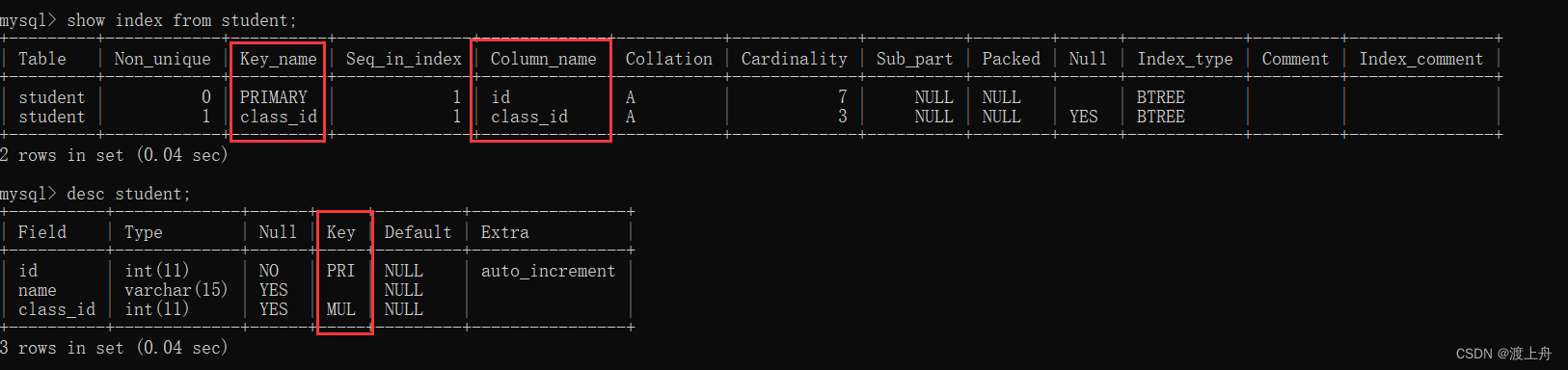
创建索引
create index 索引名 on 表名(列名);
如:给学生表 name 这一列添加索引
create index idx_student_name on student(name);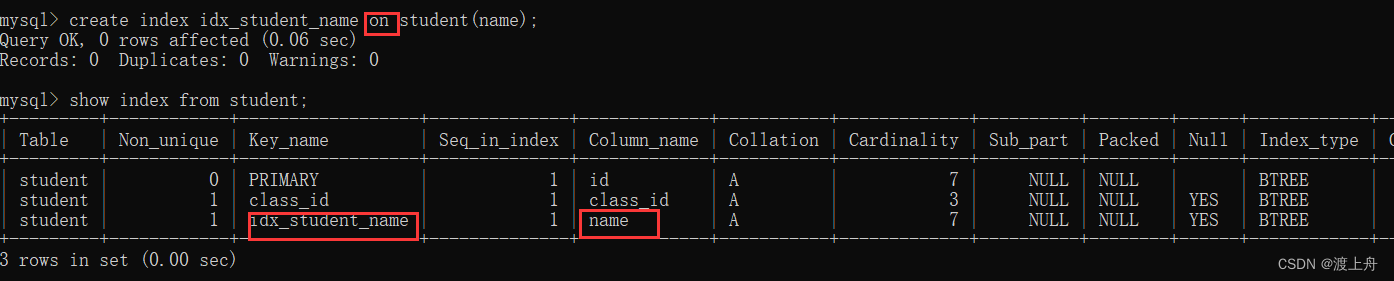
删除索引
drop index 索引名 on 表名;
如:删除 学生表 中索引名为 idx_student_name 的 索引
drop index idx_student_name on student;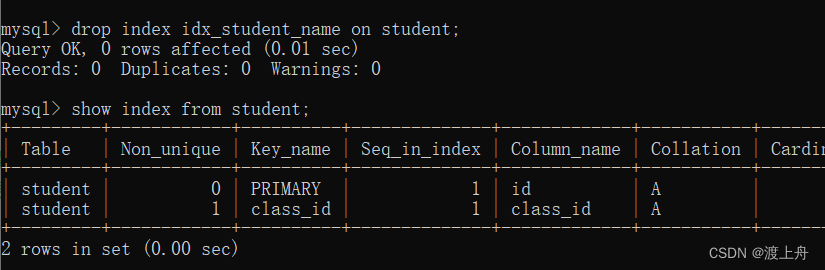
2、事务
把多个SQL打包到一起,变成一个整体,要么全都执行完,要么一个都不执行。
这里的一个都不执行,并不是真的不执行,而是会自动恢复到执行之前的样子,看起来就好像一个都没执行一样。数据库会把执行的每个操作记录下来,如果事务中的某个操作出错,就会把事务中前面的操作进行回滚(回滚:把执行过的操作逆向恢复回去,类似于 ctrl+z)根据之前的操作进行逆操作(如:前面是插入,现在就删除;前面是删除,现在就插入;前面是修改,现在就修改回去)
并不是,删库删表还是危险操作。因为记录是需要占据空间的。我们不可能花费比数据占得空间还大的空间 来记录 数据库中的所有数据是怎么来的。这就本末倒置,得不偿失了。于是,实际上,最多只会把正在执行的几个事务的每个操作保存下来,其他操作并不会记录。所以如果删库或者删表,是不能回滚成功的。
(1)原子性:原子性是事务最核心的特性,是事务的初心。打包成整体这个操作,就称为“原子性”,原子性是事务最核心的特性
(2)一致性:事务执行前/执行后,都得是数据合法的状态。(比如,转账,不能出现转账过程中出错,钱转丢的情况,转账前后数据都得合法)通过原子性,保证了一致性。
(3)持久性:事务产生的修改,都是会写入硬盘的。修改具有持久性。
(4)隔离性:一个数据库服务器,同时执行多个事务的时候,事务之间的“相互影响程度”。
一个数据库服务器,同时可以给多个客户端提供服务,这多个客户端彼此之间,是“并发执行”的关系,多个客户端可能会同时发起事务。尤其是多个事务在操作同一个数据库的同一个表时,有可能会出现问题。
也就是说,
隔离性越高,意味着事务之间的并发程度越低,执行效率就越慢,但是数据的准确性越高;
隔离性越低,意味着事务之间的并发程度越高,执行效率就越快,但是数据的准确性越低;
MySQL给我们提供了不同的档位,也就是隔离级别,使我们可以控制隔离性的高低。
MySQL提供了哪四个隔离级别,有什么区别呢?
- read uncommitted:不做任何限制,并发程度最高,隔离性最低,会产生脏读+不可重复读+幻读问题,但执行速度是最快的
- read committed:对写操作加锁,并发程度降低了,隔离性提高了,解决了脏读问题,会产生不可重复读+幻读问题
- repeatable read:对写操作和读操作都进行加锁,并发程度又降低了,隔离性又提高了,解决了脏读+不可重复读问题,会产生幻读问题
- serializable:严格串行化,并发程度最低(串行执行),隔离性最高,解决了脏读+不可重复读+幻读问题,但执行速度是最慢的
举个例子来说明,
事务A想读一份文件数据,与此同时,事务B想修改同一份文件数据。如果不做任何限制,事务A和事务B就是完全并发执行的。
可能会出现以下问题:
问题1:事务B修改的过程中,事务A去读数据。事务A读完数据走了,事务B把那个数据改了。事务A就读了个有问题的数据,称为“脏读问题”。
如何解决问题1?
对修改操作进行加锁,事务B修改数据时,事务A别去读。事务B修改完,事务A才能去读。
问题2:已经对修改操作进行加锁,事务B修改时,不允许事务A去读。但是,事务A读的过程中,事务B又跑去修改了。导致事务A读数据读到一半,数据突然变了。称为“不可重复读”问题。
如何解决问题2?
对读操作也进行加锁,事务A在读的过程中,不允许事务B再去修改。
问题3:现在已经对读操作和修改操作都进行加锁了,事务B修改数据时,不允许事务A去读;事务A读数据时,也不允许事务B去修改。(同一份文件数据)但是,事务A读的过程中,事务B可以去修改其他文件数据呀(比如新增或删除一个其他文件)。事务A在读的过程中,虽然读的数据是正确的,但是它发现文件的数量变了,一会多一个,一会少一个。两次读到的结果集不同,称为“幻读”问题。
如何解决问题3?
舍弃并发,完全串行化,只要事务A在读数据,事务B就啥都不能干,就等着。
事务的使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)提交:commit;
开启事务之后,中间的这些SQL并不会立即执行,而是得commit之后一起执行,这是为了保证原子性
(4)rollback; 主动进行回滚
四、Java数据库编程
实际开发中,SQL很少是在数据库客户端里手动输入的,而是通过代码,自动执行。那么就需要让其他编程语言来操作数据库服务器。
其他编程语言如何操作数据库服务器呢?
数据库会提供各个语言版本的API(一组类或方法),通过这组API,其他编程语言就可以操作数据库,完成各种增删查改的操作。
像 Oracle,MySQL,SQL Server,SQLite等数据库,都有API,而且不同的数据库,提供的API都是不同的。想要操作不同的数据库服务器,就得学好几套不同的API,学习成本非常大。
能不能把这些不同数据库提供的API统一成一套,只需要学习一套API呢?
Java这个编程语言做到了。
Java如何操作数据库服务器?
通过JDBC(Java Database Connection,Java数据库连接,是一套用来执行SQL语句的Java API),使用同一套API 规范所有数据库的编程操作(JDBC只提供了接口,由各个数据库厂商来进行实现),各个数据库厂商都提供了适应JDBC相关的“驱动包”(相当于API的具体实现)。此时,只要掌握了JDBC这套API,无论操作哪个数据库,操作的代码都是不变的。
Java如何操作数据库服务器的过程如下:
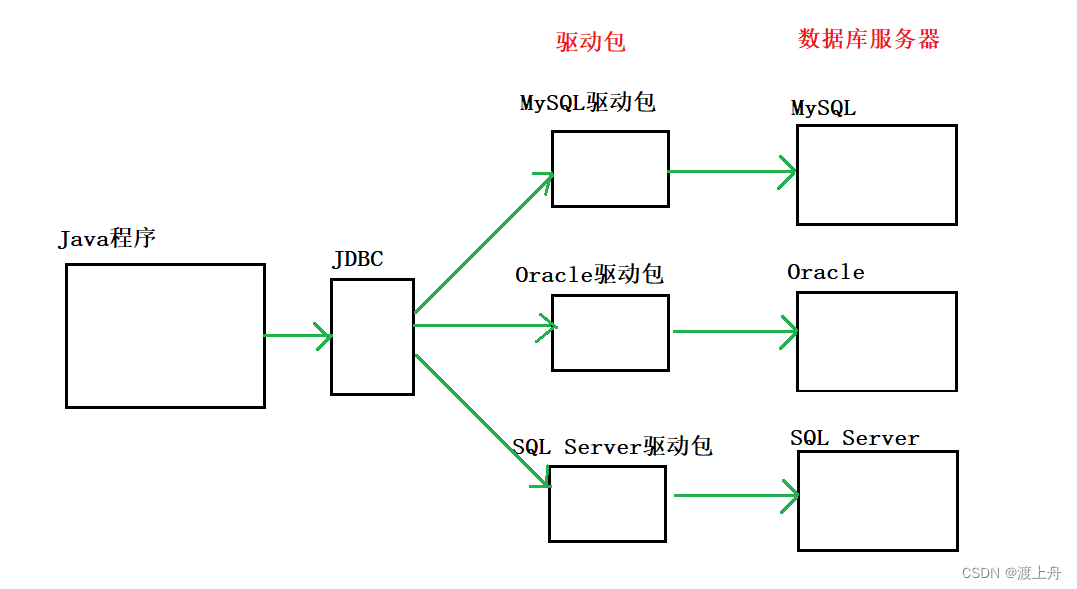
由于JDBC这套API已经成为Java标准库的一部分了(在java.sql或javax.sql包底下),所以Java想要操作数据库服务器,只要安装对应数据库的驱动包就可以了。然后把驱动包(Java中,是jar包)导入到项目中,作为库使用。
Java数据库编程——通过代码,自动执行SQL
1、URL:统一资源地址符,描述了互联网上唯一的一个资源的位置,也就是我们平时所说的“网址”。如:
jdbc:mysql://127.0.0.1:3306/java?characterEncoding=utf8&useSSL=falsejdbc:mysql 代表 这个URL是给jdbc中的 mysql 使用的
127.0.0.1 代表 IP地址,这是一个“环回IP”,使用IP地址来确定是哪台主机
3306 代表端口号,使用端口号来确定是主机上的哪个程序
java 代表访问的数据库名
characterEncoding=utf8 描述了请求的字符编码方式
useSSL=false 代表关闭加密功能
2、执行 SQL语句,针对 增,删,改,都是使用 executeUpdate()来执行,针对查是使用
executeQuery() 来执行。
代码:
增加(insert):
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Scanner;
public class JDBCInsert {
public static void main(String[] args) throws SQLException {
//1、创建DataSource数据源,描述 MySQL服务器 在哪
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
//2、和数据库建立连接
Connection connection = dataSource.getConnection();
//3、构造 SQL 语句
Scanner scanner = new Scanner(System.in);
int studentId = scanner.nextInt();
String studentName = scanner.next();
String sql = "insert into student values(?,?)";
//PreparedStatement 背后会做很多事,比如会对 sql语句 进行一些预处理(对语法进行解析),减轻服务器的负担
PreparedStatement statement = connection.prepareStatement(sql);
//把studentId里的值替换到 第一个 占位符(?)里
//把studentName里的值替换到 第二个 占位符里
//这里占位符是从1开始的,第一个参数是几就代表替换的是第几个占位符
statement.setInt(1,studentId);
statement.setString(2,studentName);
System.out.println("sql:"+statement);
//4、执行 SQL 语句
int ret = statement.executeUpdate();
//5、断开连接,释放资源
statement.close();
connection.close();
}
}
查找(select):
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class JDBCSelect {
public static void main(String[] args) throws SQLException {
//1、创建数据源,描述数据库在哪儿
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java?characterEnding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
//2、与数据库建立连接
Connection connection = dataSource.getConnection();
//3、构造sql语句,对sql语句进行预处理
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
//4、执行sql语句
ResultSet resultSet = statement.executeQuery();
//resultSet.next():移动一下光标,让光标指向下一行,并判断此时是否还有元素,没元素了就返回false
//初始情况下,光标指在第一行的前面
//使用 getXX方法获取到每一项,参数就是数据表的列名
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(id+":"+name);
}
//5、断开连接,释放资源
resultSet.close();
statement.close();
connection.close();
}
}
原文地址:https://blog.csdn.net/m0_61731585/article/details/135562652
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!