万卡集群:字节搭建12288块GPU的单一集群
论文
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs

论文链接:https://arxiv.org/abs/2402.15627
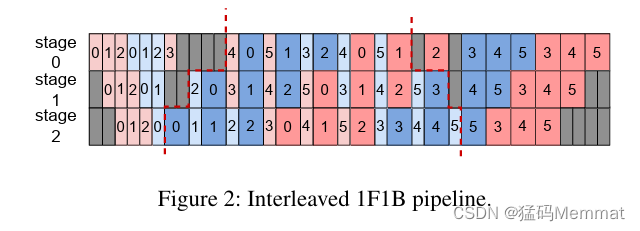
从结构上讲,网络是基于Clos的“胖树”结构。其中一个改进是在顶层交换机上把上行与下行链路分开,有效降低冲突率。
以下内容转载自道明实验室
这可能是一段时间以来,我看到的写的最好的来自国内公司的论文:
非常客观,非常细节,非常实战,非常诚实也非常自信。
我推荐所有对AI训练集群感兴趣的朋友认真阅读。
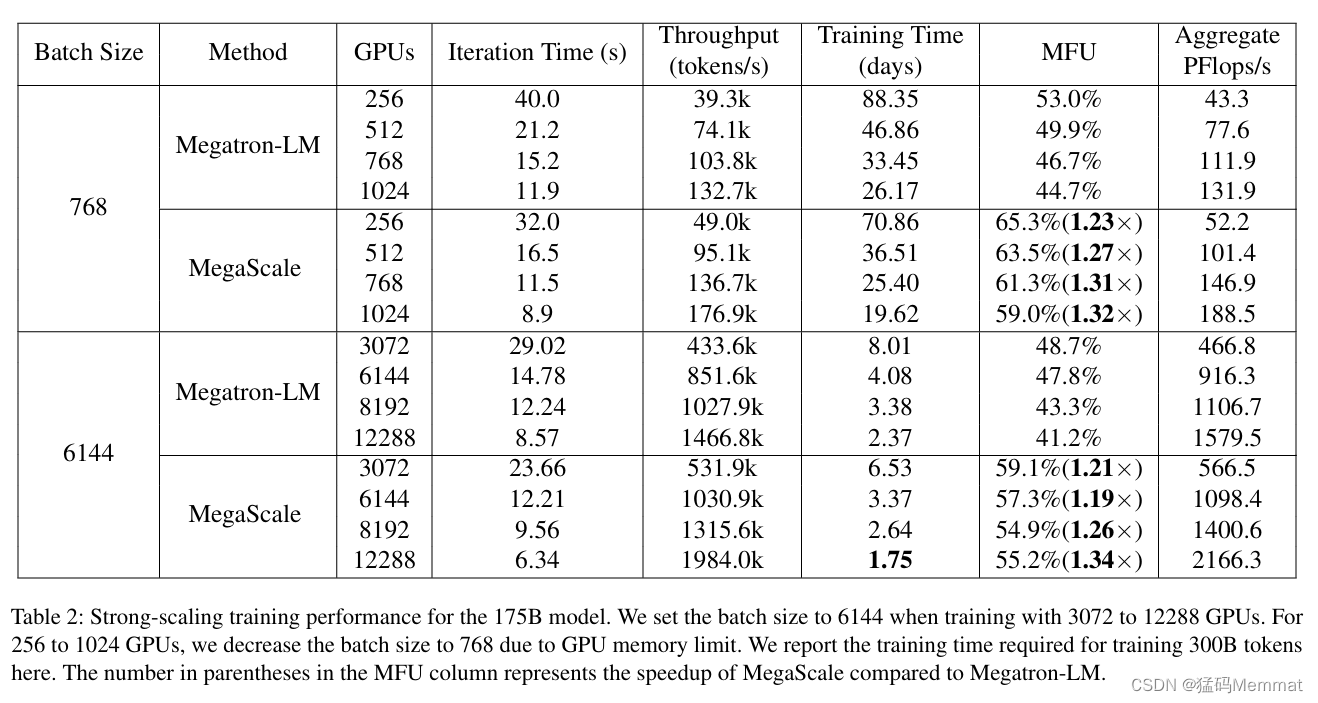
因为只是短评,我就略过细节挑一些重点,怎么部署集群过于技术化,就不涉及了。至于GPU与光模块的配比关系也不涉及,国内公司因为芯片限制,网络部分只要做到匹配即可,算力利用率(MFU)高不代表算力高,从规模上讲,这个集群是最高规格之一,但是从性能而言,一定不能算顶级的了。
重点反而是在集群规模达到万卡以上,会碰到的问题,以及字节的解决方案,重点在于,如果论文是真实的(很大概率),那么我们对于下一阶段国产模型能力的大幅提升应该有足够的信心。
1、大幅优化的初始化时间,在没经过优化的情况下,2048张GPU的集群初始化时间是1047秒,经过各种优化后,初始化时间下降到5秒以下,10000张GPU集群的初始化时间降到30秒以下;
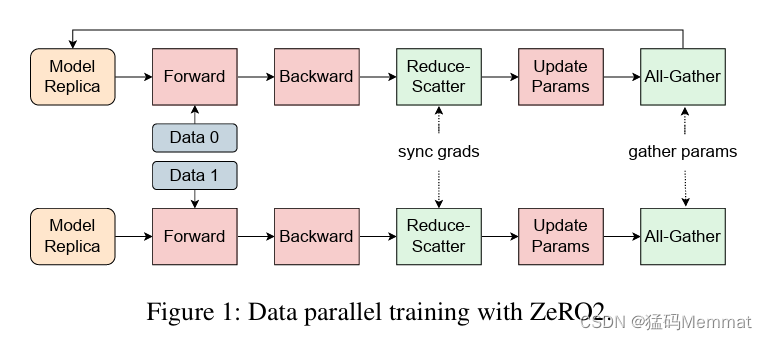
2、错误后快速恢复能力。论文里把这个叫做容错能力(Fault Tolerance),我认为不是非常准确,因为正如论文中的表述,万卡集群会不可避免的随时随地发生软硬件故障,这些都要导致训练进程停下,再开始(GPU其实是很脆弱的,CUDA经常会有BUG,硬盘很容易坏,数据里出现一个奇怪的字符,也可能导致程序错误,等等,反正,只要集群超过上百个节点,各种奇奇怪怪的故障都会有可能发生)。所以第一层保障机制是Checkpointing,也就是高频的把训练进程保存下来,一旦宕机,快速重启后,就加载上一次存档,继续训练。为了加快这种经常发生的读写速度,论文介绍了文件系统的优化,技术细节略过。同样的,上一节提到的初始化时间的大幅缩减,在这里也起到了巨大的作用,毕竟重启是家常便饭。第三层保障,就是建立完整的系统状态监控及自动检测机制,对超过90%的故障都能自动检测,定位,并快速恢复。
3、截止2023年9月,字节建立起了超过一万张Ampere架构GPU(A100和A800)的集群,目前正在建设Hopper架构的集群(H100和H800)。
4、那些被简单描述的“血泪教训”。GPU的个性(同样的卡,就是有那么几张会慢一点,奇怪一点),网络闪断,不必要的等待,等等。这些问题,不是一直跟几百台以上规模的集群打交道,是不可能有认知的。所以,大模型训练本质上是一个工程问题。
5、显然,字节花了接近一年时间去“搞定”基础设施,这,或许是模型研发生命周期里最重要的一步。
Reference
https://mp.weixin.qq.com/s/xSE_7TKPMcJjlxywbFyL2g
原文地址:https://blog.csdn.net/JishuFengyang/article/details/136387264
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!