如何使用 Puppeteer 和 Browserless 抓取亚马逊产品数据?

您可以在亚马逊上找到所有有关产品、卖家、评论、评分、特价、新闻等的相关且有价值的信息。无论是卖家进行市场调研还是个人收集数据,使用高质量、便捷且快速的工具将极大地帮助您准确地抓取亚马逊上的各种信息。
为什么抓取亚马逊产品数据很重要?
亚马逊将有价值的信息集中在一个地方:产品、评论、评分、独家优惠、新闻等。因此,在亚马逊上进行数据抓取将在很大程度上避免耗时且费力的难题。作为一家企业,使用亚马逊产品抓取器至少可以为您带来以下 4 大优势:
- 了解本地甚至全球市场的定价情况并进行价格比较
- 分析与竞争对手的差异
- 识别目标群体
- 改善产品形象
- 预测用户需求
- 收集客户信息
抓取亚马逊产品的典型原因
- 监控竞争对手的定价和产品
- 了解市场趋势
- 优化营销策略
- 改善产品列表
- 价格优化
- 增强产品研究
- 跟踪客户情绪
Browserless 有助于构建亚马逊产品抓取器吗?
无头浏览器在执行自动化工作方面表现出色?没错,我们将使用 Nstbrowser 最强大的无头浏览器服务:Browserless 来抓取亚马逊产品信息。
在抓取亚马逊产品数据时,我们总是遇到一系列严峻的挑战,例如机器人检测、验证码识别和 IP 封锁。使用 Browserless 可以完全避免这些头痛!
Nstbrowser 的 Browserless 提供真实的浏览器用户指纹,每个指纹都是唯一的。此外,参与我们的订阅计划可以实现全面的验证码绕过,护航您畅通无阻的访问体验。
加入 Nstbrowser 的 Discord 推介计划,现在分享 1,500 美元的现金!
我们如何抓取亚马逊产品数据?
话不多说,现在正式开始使用 Browserless 进行数据抓取!
先决条件
在开始之前,我们需要连接到 Browserless 服务。使用 Browserless 可以解决复杂的网页抓取和大型自动化任务,您也可以真正享受完全托管的云部署。
Browserless 采用以浏览器为中心的理念,提供强大的无头部署功能,并提供更高的性能和可靠性。有关 Browserless 的更多信息,您可以参考Nstbrowser 的文档。
获取 API KEY 并进入 Nstbrowser 客户端的 Browserless 菜单页面。
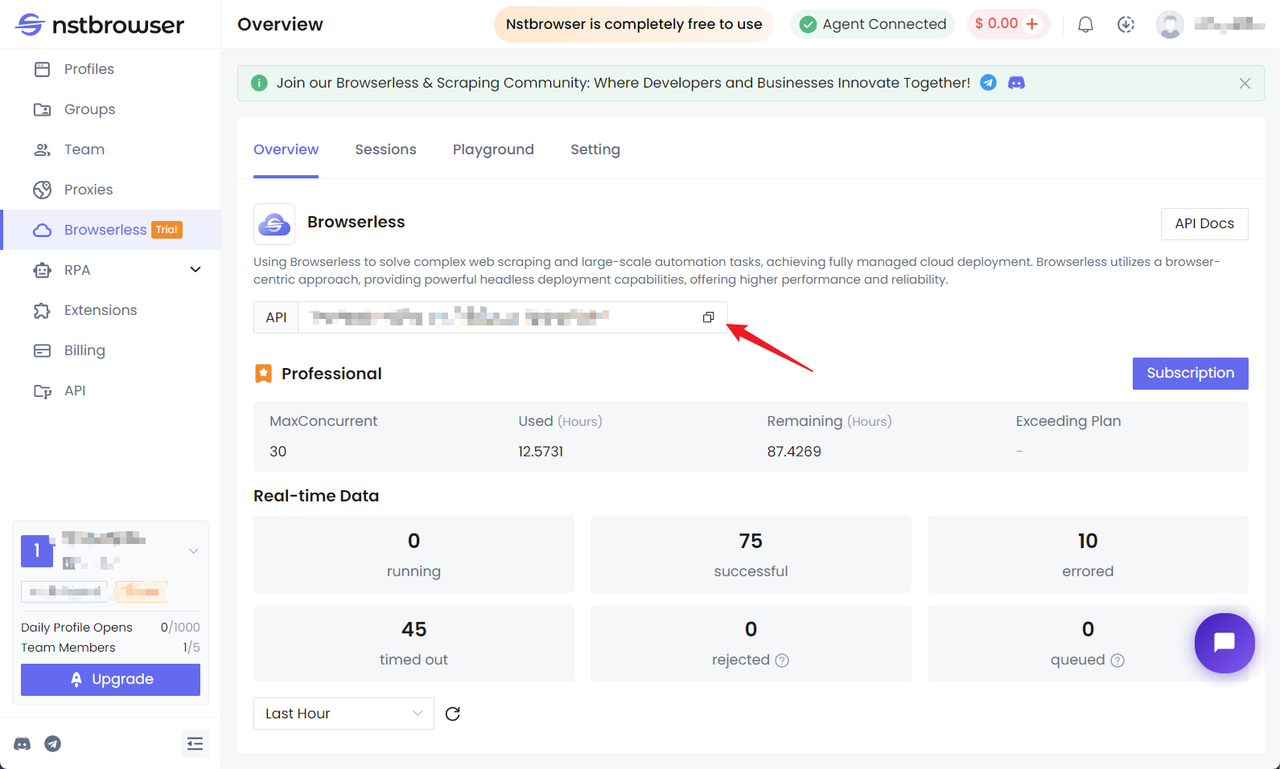
安装 Puppeteer 并连接到 Browserless
- 安装 Puppeteer。更轻的 puppeteer-core 是更好的选择。
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- 我们已准备好了调用 Browserless 的代码。您只需要填写 apiKey 和 proxy 即可开始后续的亚马逊产品抓取操作:
const apiKey = "your ApiKey"; // 必需
const config = {
proxy: 'your proxy', // 必需;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080
// platform: 'windows', // 支持:windows、mac、linux
// kernel: 'chromium', // 仅支持:chromium
// kernelMilestone: '128', // 支持:128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // 浏览器参数
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始
// },
};
const query = new URLSearchParams({
token: apiKey, // 必需
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;开始抓取
第一步:检查目标页面
在抓取之前,我们可以尝试访问 Amazon.com。如果是第一次访问,很有可能会出现验证码:
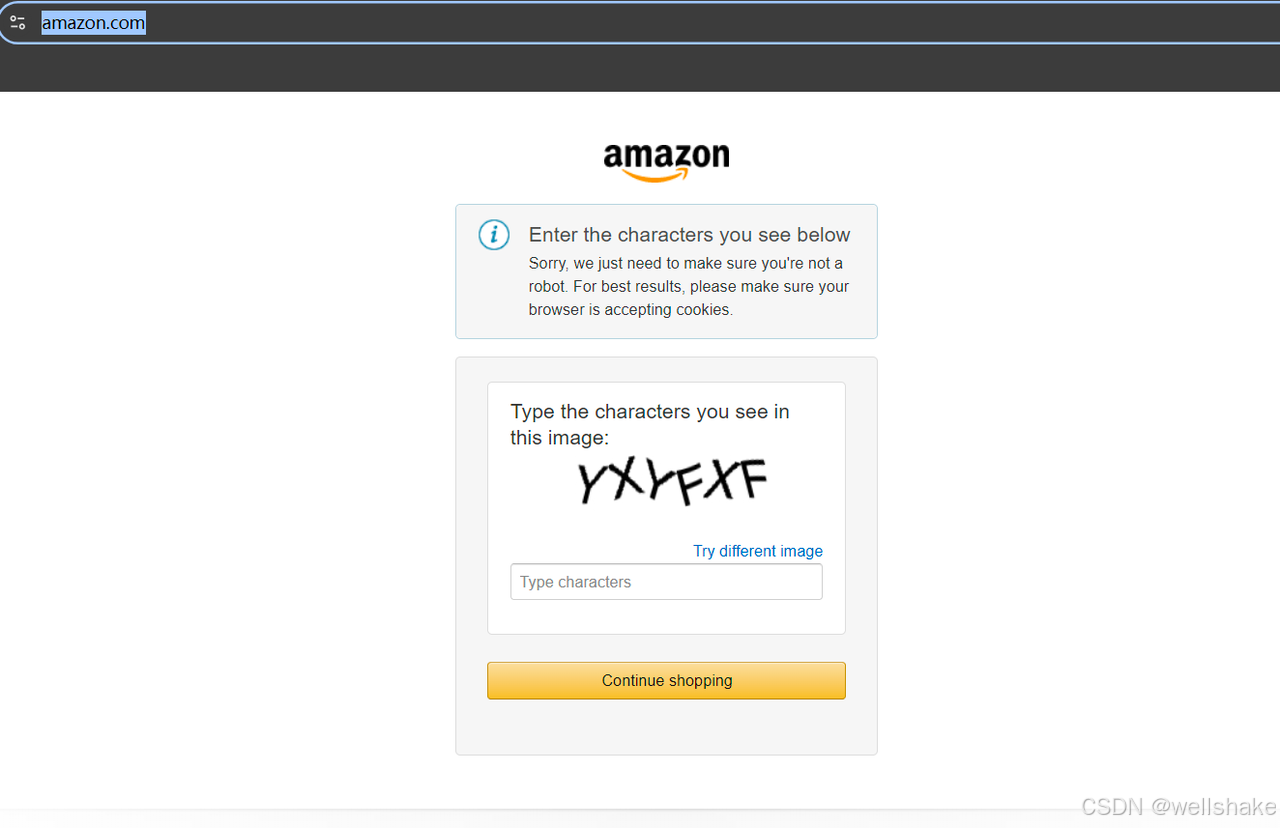
但没关系,我们不必费尽心思地寻找验证码解码工具。此时,您只需访问您所在区域或代理所在区域的亚马逊域名,就不会触发验证码。
例如,让我们访问:https://www.amazon.co.uk/: 英国的亚马逊域名。我们可以看到页面流畅地显示,然后尝试在顶部的搜索栏中输入我们想要的商品关键词,或者直接通过 URL 访问,例如:
https://www.amazon.co.uk/s?k=shirtURL 中 /s?k= 后面的值是产品的关键词。通过访问上面的 URL,您将在亚马逊上看到与衬衫相关的产品。现在您可以打开“开发者工具”(F12)检查页面的 HTML 结构,并通过定位光标确认我们稍后需要抓取的数据。
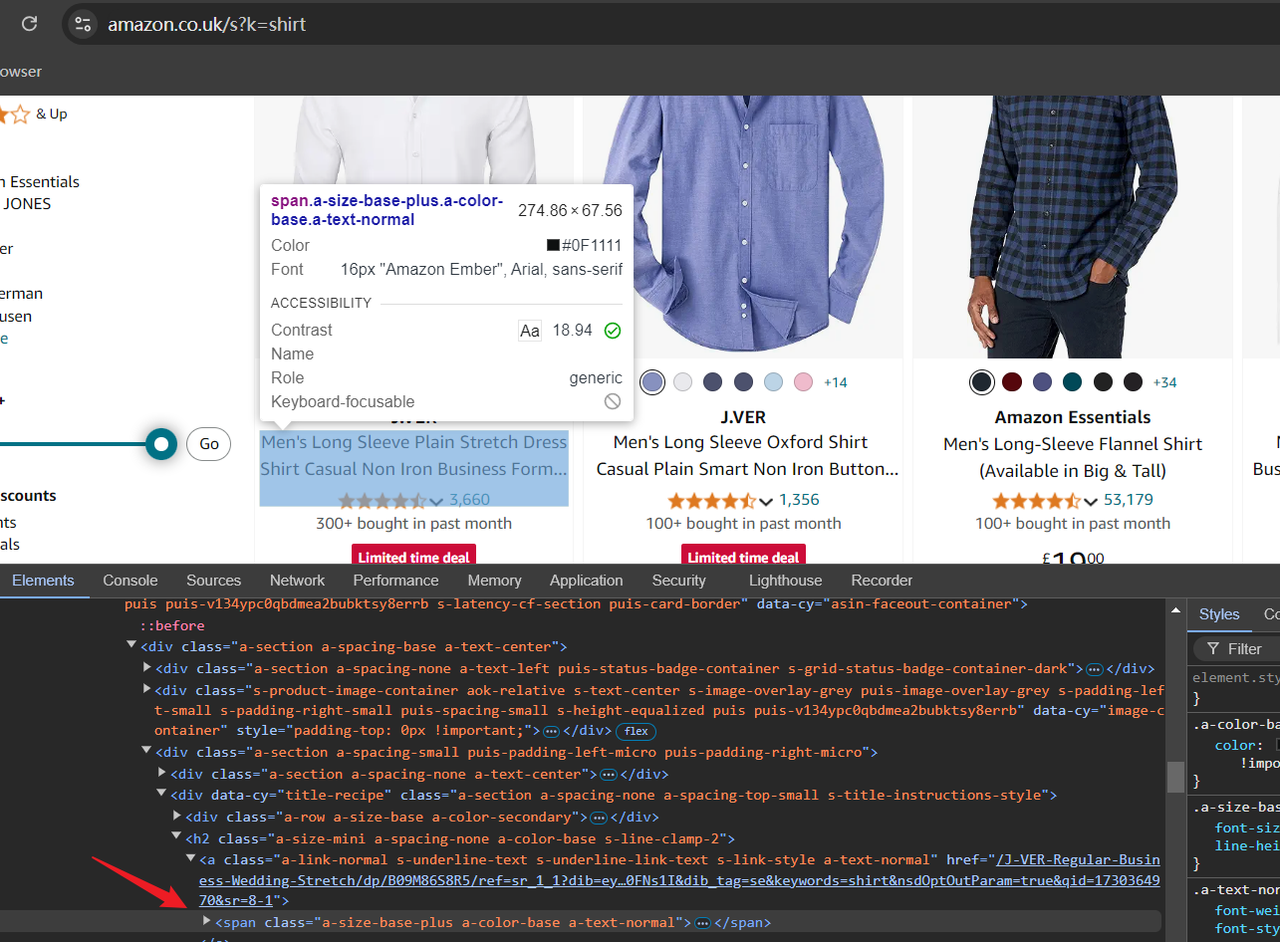
第二步:编写脚本
首先,我在脚本顶部添加了一串代码。以下代码使用第一个脚本参数作为亚马逊产品关键词,后续脚本也会使用该参数进行抓取:
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}接下来,我们需要:
- 导入 Puppeteer 并连接到 Browserless
- 进入对应亚马逊的商品查询结果页面
- 添加截图以验证访问是否成功
import puppeteer from "puppeteer-core";
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// 添加截图以方便后续排查
await page.screenshot({ path: 'amazon_page.png' })现在我们使用 page.$$ 获取所有产品的列表,遍历产品列表,并在循环中逐一获取相关数据。然后将这些数据收集到 productDataList 数组中并打印出来:
// 获取所有搜索结果的容器元素
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 获取产品的各种信息:标题、评分、图片链接、价格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
await browser.close();运行脚本:
node amazon.mjs shirt如果成功,将在控制台中打印以下内容:
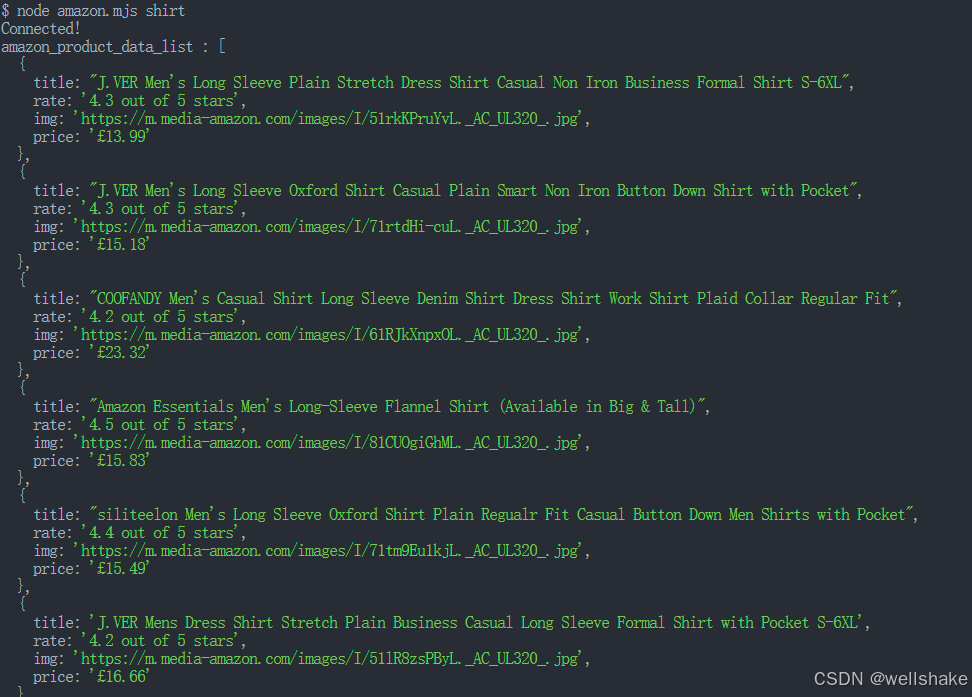
第四步:将抓取的数据输出为 JSON 文件
显然,为了更好地分析数据,仅仅在控制台中打印数据是不够的。这里提供一个简单的示例:通过 fs 模块 快速将 JS 对象转换为 JSON 文件:
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')好了,让我们看看我们的完整代码:
import puppeteer from "puppeteer-core";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const apiKey = "your ApiKey"; // 'your proxy'
const config = {
proxy: 'your proxy', // 必需;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080
// platform: 'windows', // 支持:windows、mac、linux
// kernel: 'chromium', // 仅支持:chromium
// kernelMilestone: '128', // 支持:128
// args: {
// "--proxy-bypass-list": "detect.nstbrowser.io"
// }, // 浏览器参数
// fingerprint: {
// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始
// },
};
const query = new URLSearchParams({
token: apiKey, // 必需
config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessWSEndpoint,
defaultViewport: null,
})
console.info('Connected!');
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// 添加截图以方便后续排查
await page.screenshot({ path: 'amazon_page.png' })
// 获取所有搜索结果的容器元素
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 获取产品的各种信息:标题、评分、图片链接、价格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
console.log(`Error fetching ${selector}:`, e);
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
console.log('amazon_product_data_list :', productDataList);
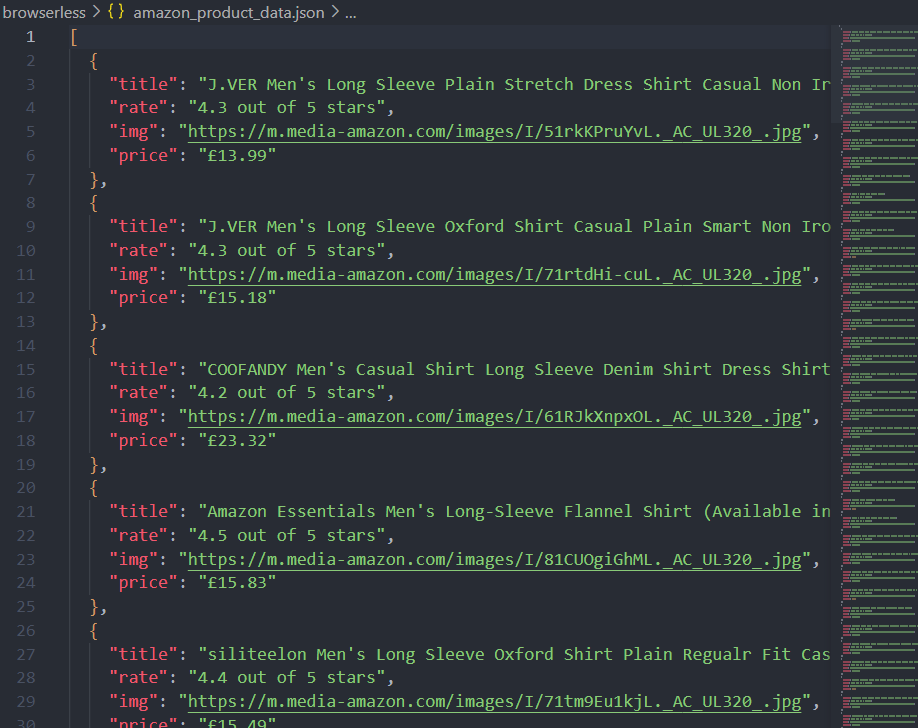
await browser.close();现在,运行脚本后,您不仅可以看到控制台的打印,还会在当前路径下写入 theamazon_product_data.json 文件。
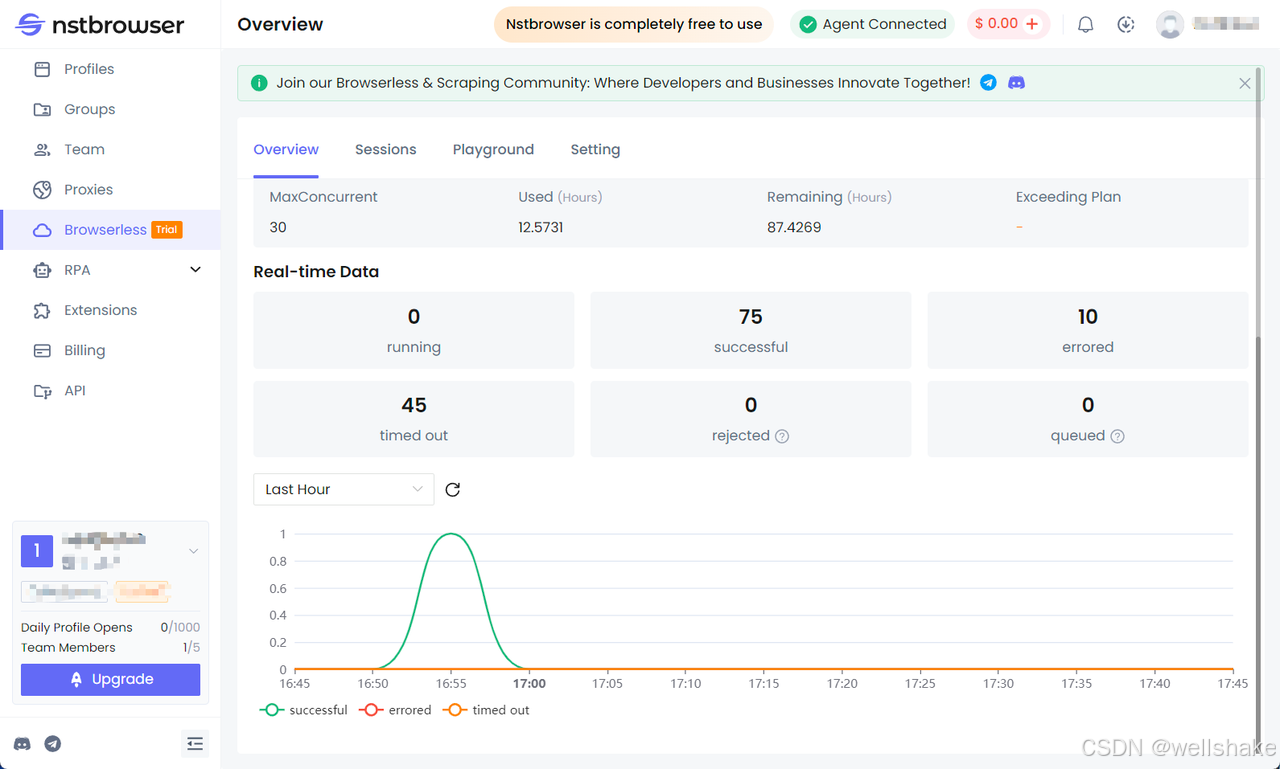
检查 Browserless 仪表盘
您可以在 Nstbrowser 客户端的 Browserless 菜单中查看最近请求的统计信息和剩余的会话时间。
Nstbrowser RPA:构建亚马逊抓取器的更轻松方式
使用 RPA 工具来抓取网络数据是一种常见的数据收集方法。使用 RPA 工具可以极大地提高数据收集的效率,降低收集成本。Nstbrowser RPA 功能可以为您提供最佳的 RPA 体验和最佳的工作效率。
阅读完本教程后,您将:
- 了解如何使用 RPA 进行数据收集
- 了解如何保存 RPA 收集的数据
准备
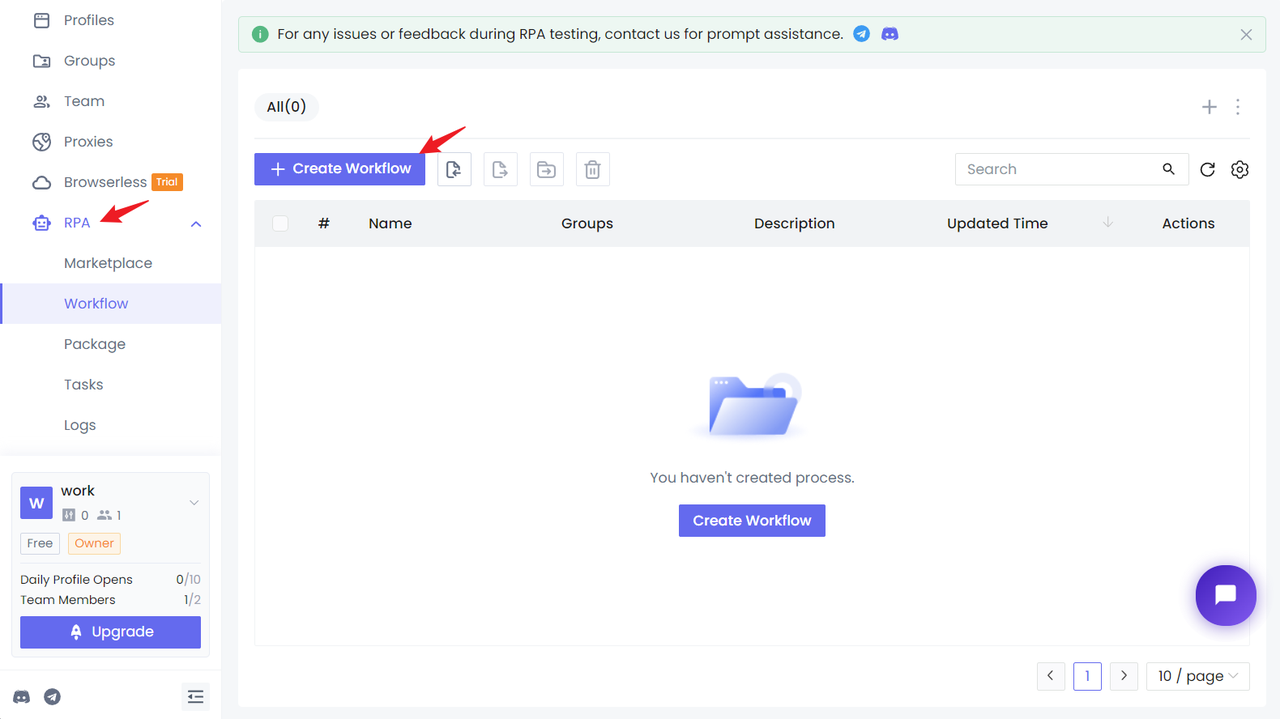
首先,您需要拥有一个 Nstbrowser 账户,然后登录 Nstbrowser 客户端,进入 RPA 模块的工作流页面,点击新建工作流。
现在,我们可以开始根据亚马逊产品搜索结果配置 RPA 抓取工作流。
第一步. 访问目标网站
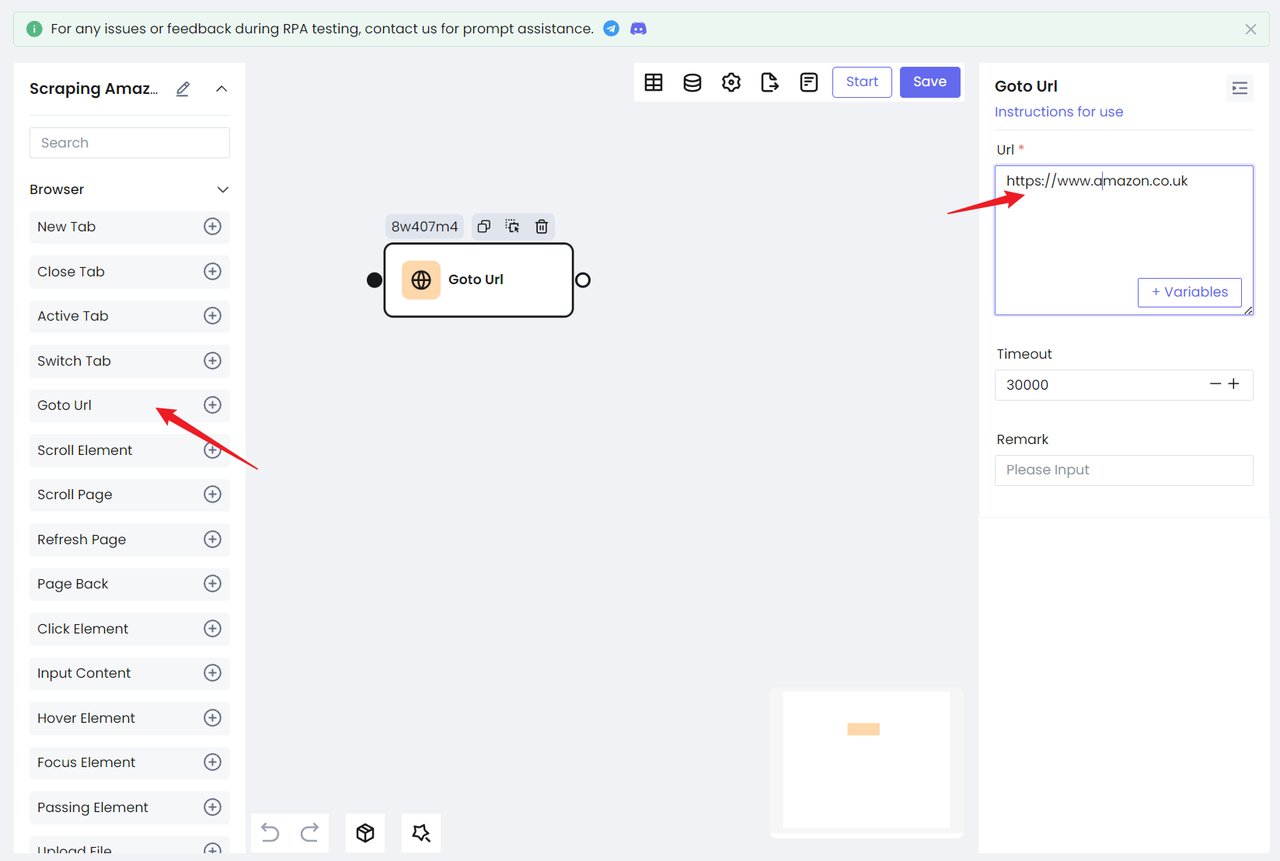
- 我们需要访问我们的目标网站:https://www.amazon.co.uk;
- 您也可以直接使用亚马逊主站点:Amazon.com 但是您需要手动处理第一次访问的验证码;
- 使用
Goto Url节点,配置网站 URL,您就可以访问目标网站:
第二步. 搜索目标内容
这次我们不会使用通过 URL 查询对应商品的方法,而是使用 RPA 帮助在首页输入框输入内容,然后触发查询跳转。这样不仅可以让我们更加熟悉 RPA 的操作,还可以最大程度地避免网站风控。
好了,到达目标网站后,我们需要先搜索目标地址。这里我们需要使用 Chrome Devtool 工具 定位 HTML 元素。
- 打开 Devtool 工具,用鼠标选择搜索框。我们可以看到:
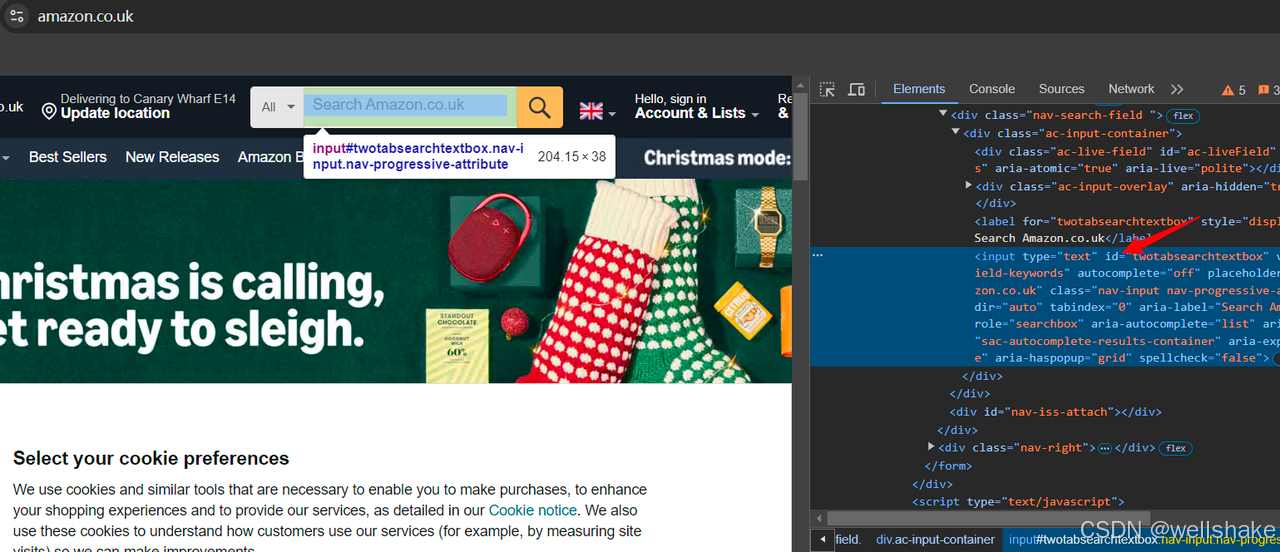
- 我们的目标输入框元素有 id 属性,可以作为 CSS 选择器来定位输入框。
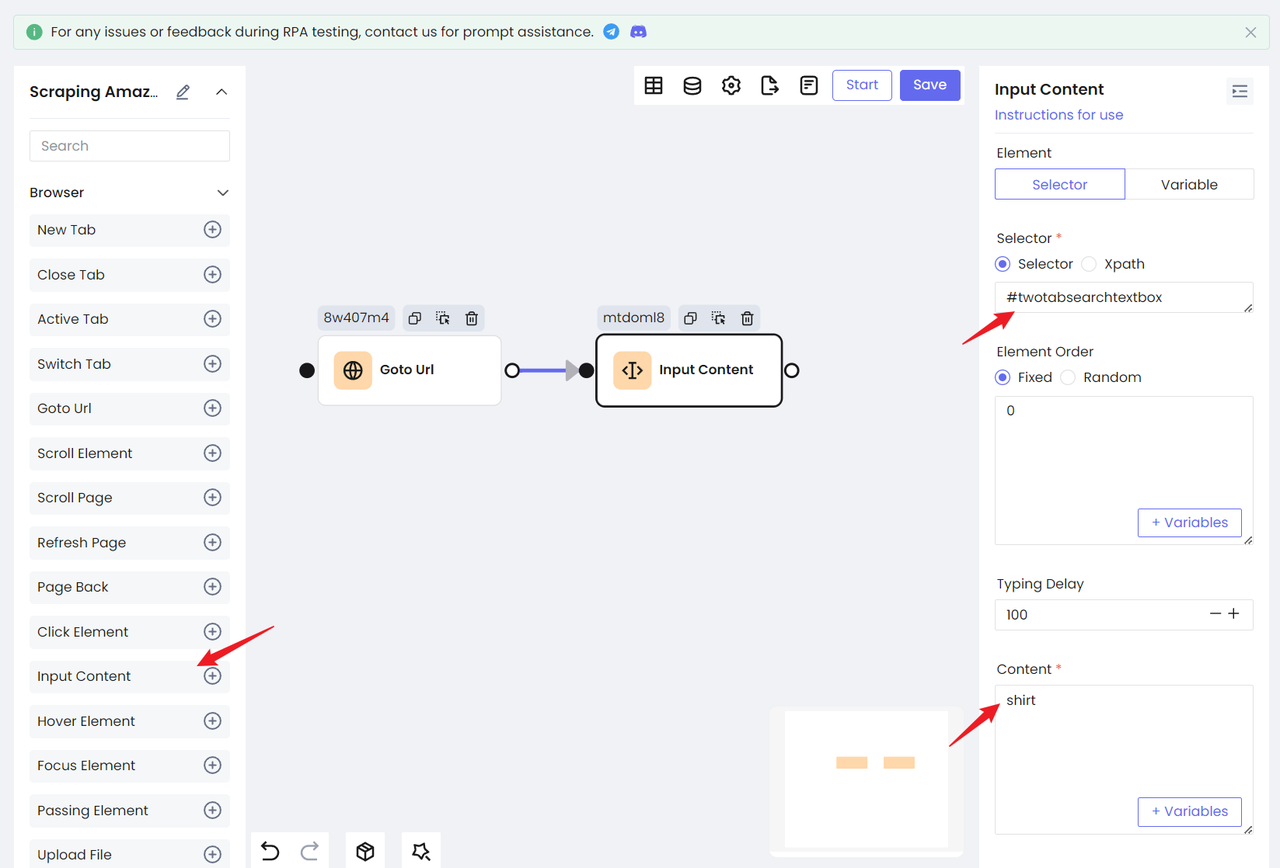
添加 Input Content 节点:
- 在 Element 选项中选择 Selector。此选项统一选择 Selector。
- 在输入框中填写我们定位到的
id的 CSS 选择器 - 然后在 Content 选项中输入我们要搜索的内容。
这样,我们就完成了输入框的输入操作。
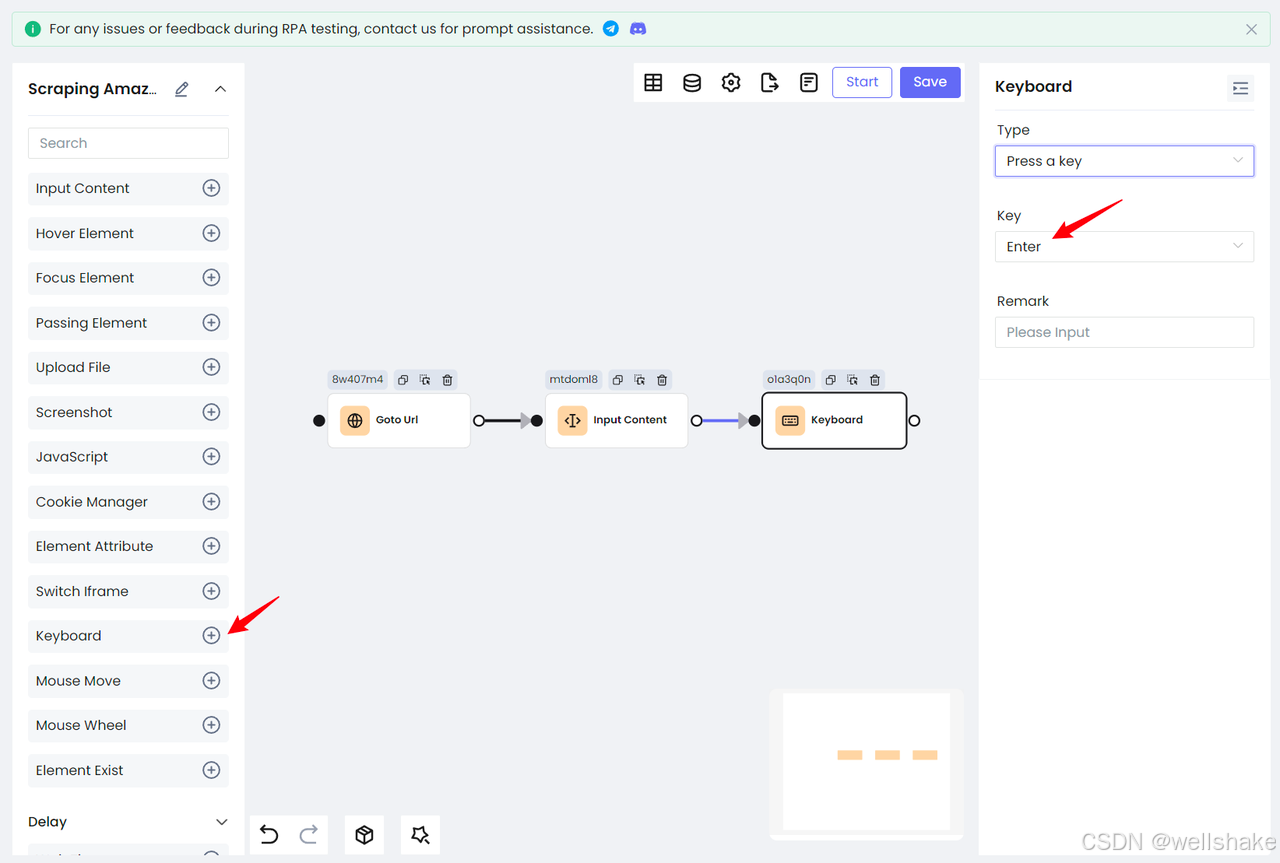
- 然后使用
Keyboard节点模拟键盘的回车操作来搜索商品:
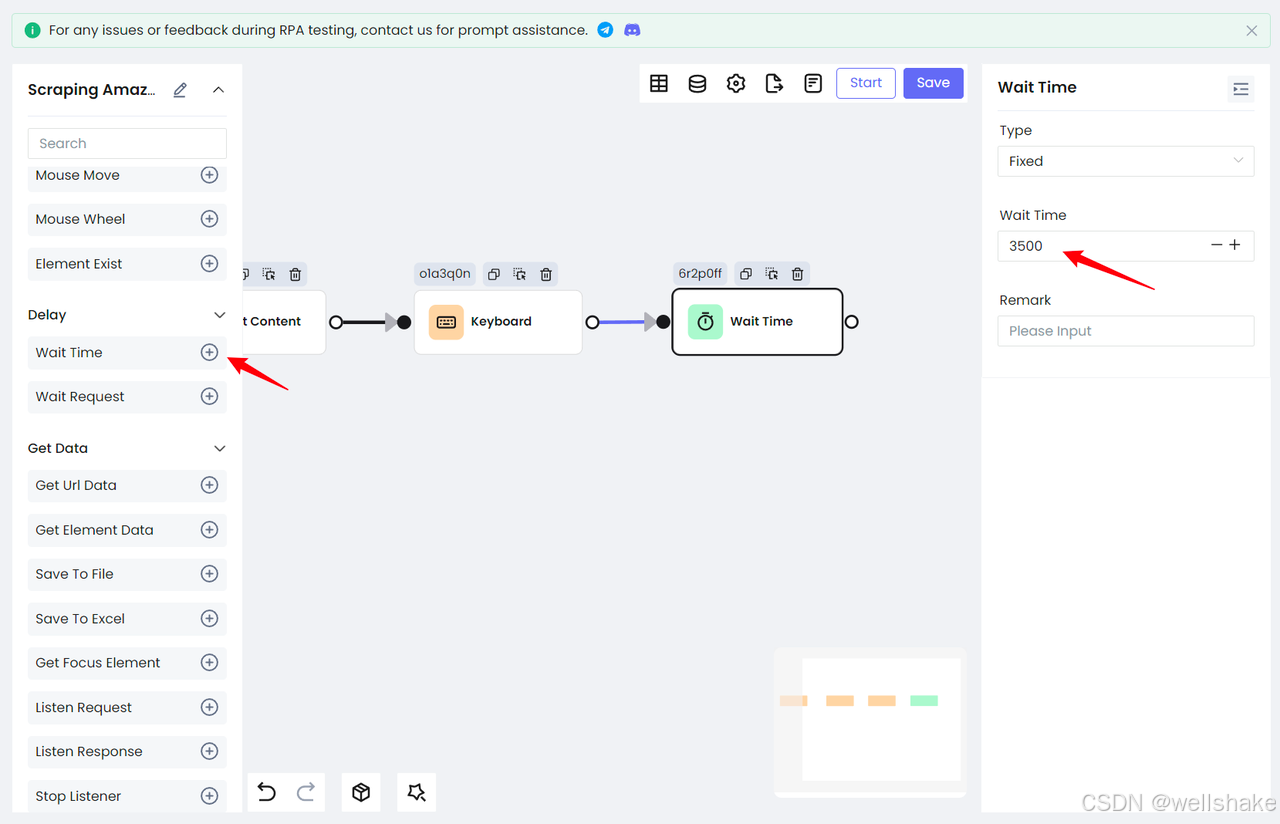
由于搜索页面会跳转到新的页面,我们需要添加等待操作,以确保我们已成功加载结果页面。Nstbrowser RPA 提供两种等待行为:Wait Time 和 Wait Request。
Wait Time: 用于等待一段时间。您可以根据您的具体情况选择固定时间或随机时间。Wait Request: 用于等待网络请求结束。适用于通过网络请求获取数据的情况。
第三步. 遍历商品列表
好了,现在我们就可以成功地看到新的商品搜索页面,接下来需要抓取这些内容。
通过观察,我们可以发现亚马逊的搜索结果以卡片列表的形式显示。这是一种非常经典的显示方式:
同样地,打开 Devtool 工具,定位卡片中的每个数据:
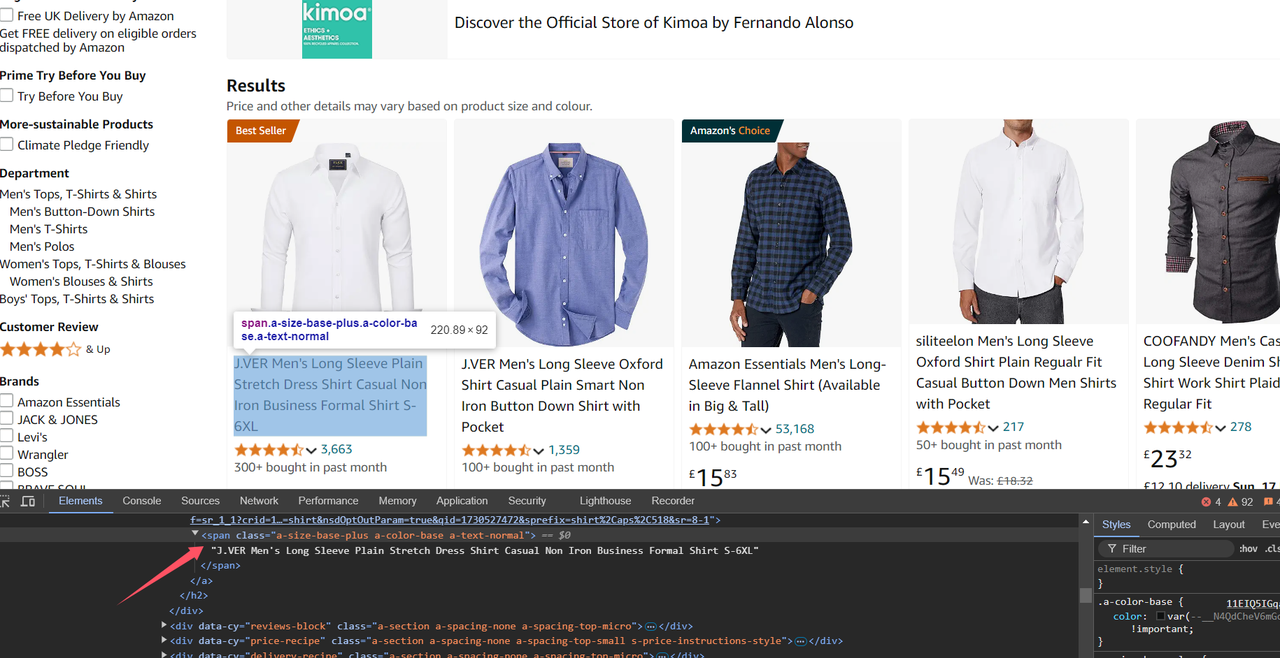
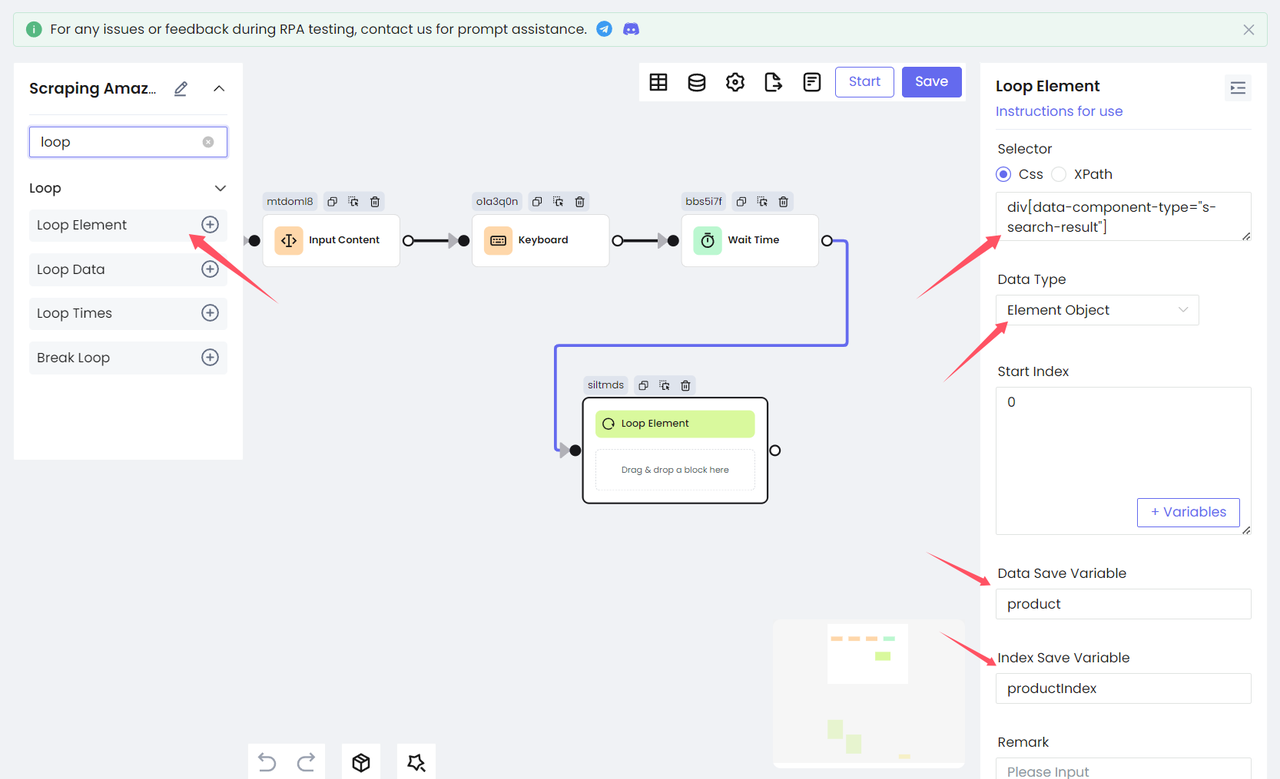
由于卡片列表中的每个项目都是一个 HTML 元素,我们需要使用 Loop Element 节点遍历所有查询结果。我们在 Selector 中填写 product 列表的 CSS 选择器,并将 Data Type 选择为 Element Object,表示获取目标元素并将其保存为元素对象到变量中。通过 Data Save Variable 将变量名称设置为 product,并将索引保存为 productIndex。
第四步. 获取数据
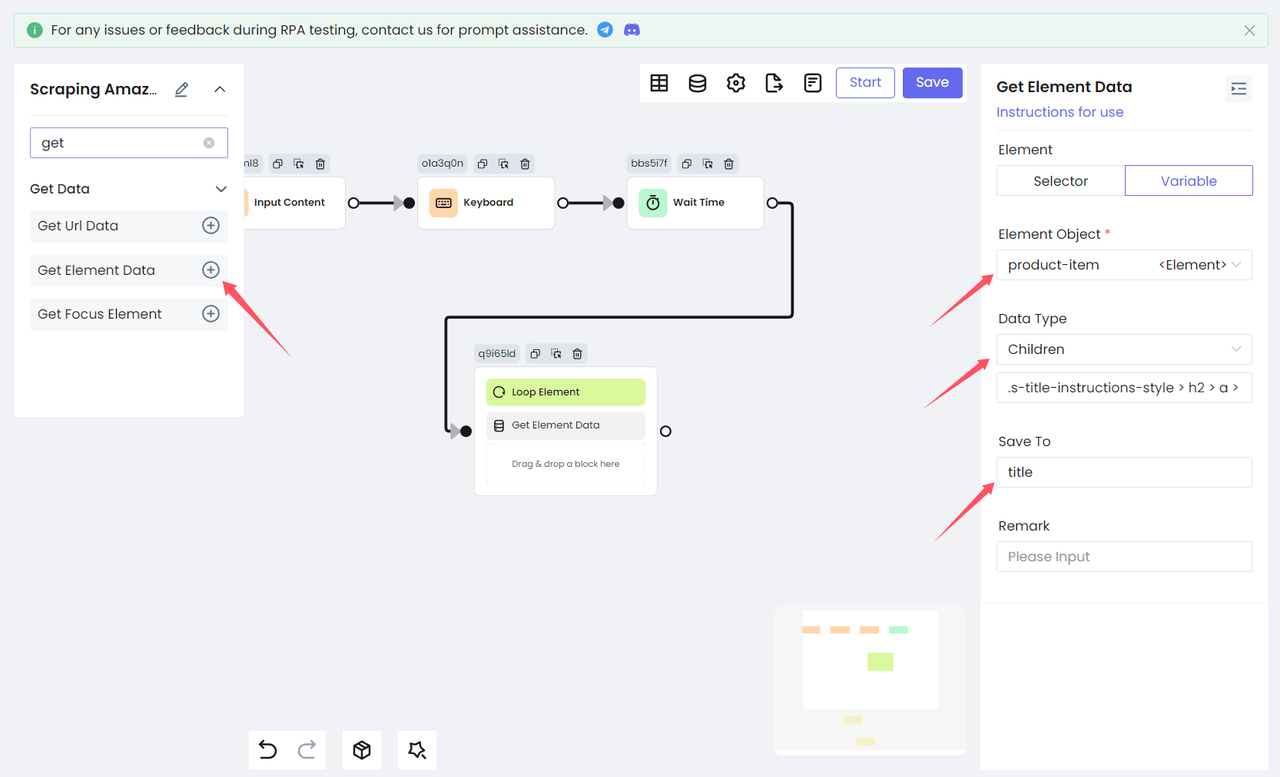
接下来,我们需要处理每个遍历的元素,从 product 中获取我们需要的的信息。我们获取商品的标题元素。这里我们需要使用 Get Element Data 节点来获取它,最后将其保存为变量 title。
选择 Children 作为 Data Type,表示获取目标元素的子元素,并将其保存为元素对象到变量 title 中。您需要填写子元素的元素选择器。这里输入的 CSS 选择器自然就是商品标题的 CSS 选择器:
然后我们使用相同的方法将剩余的商品信息:评分、图片链接和价格,都转换为 RPA 过程。
- 变量名称和 Children CSS 选择器:
'title' .s-title-instructions-style > h2 > a > span
'rate' a > i.a-icon.a-icon-star-small > span
'img' span[data-component-type="s-product-image"] img
'price' div[data-cy="price-recipe"] .a-offscreen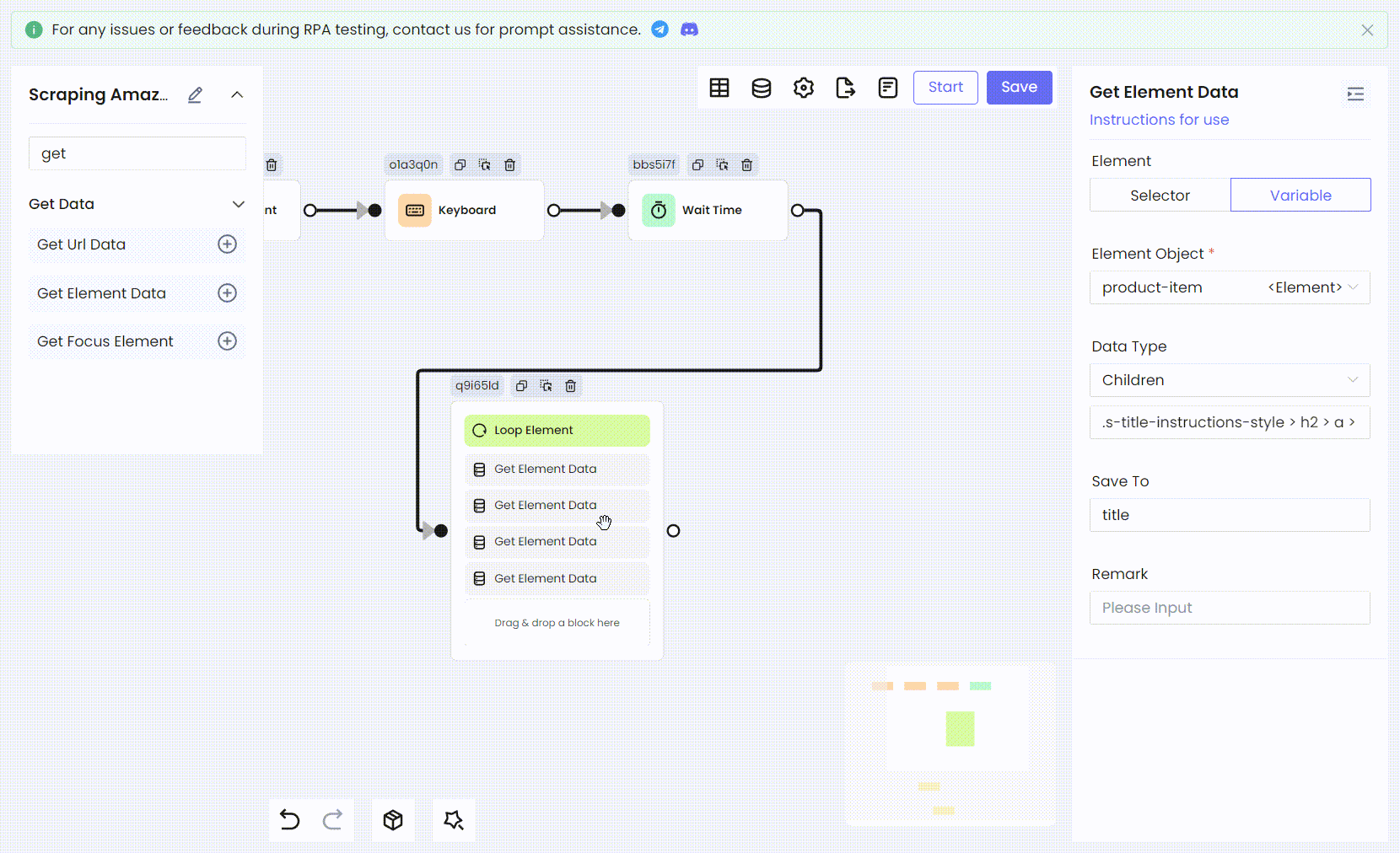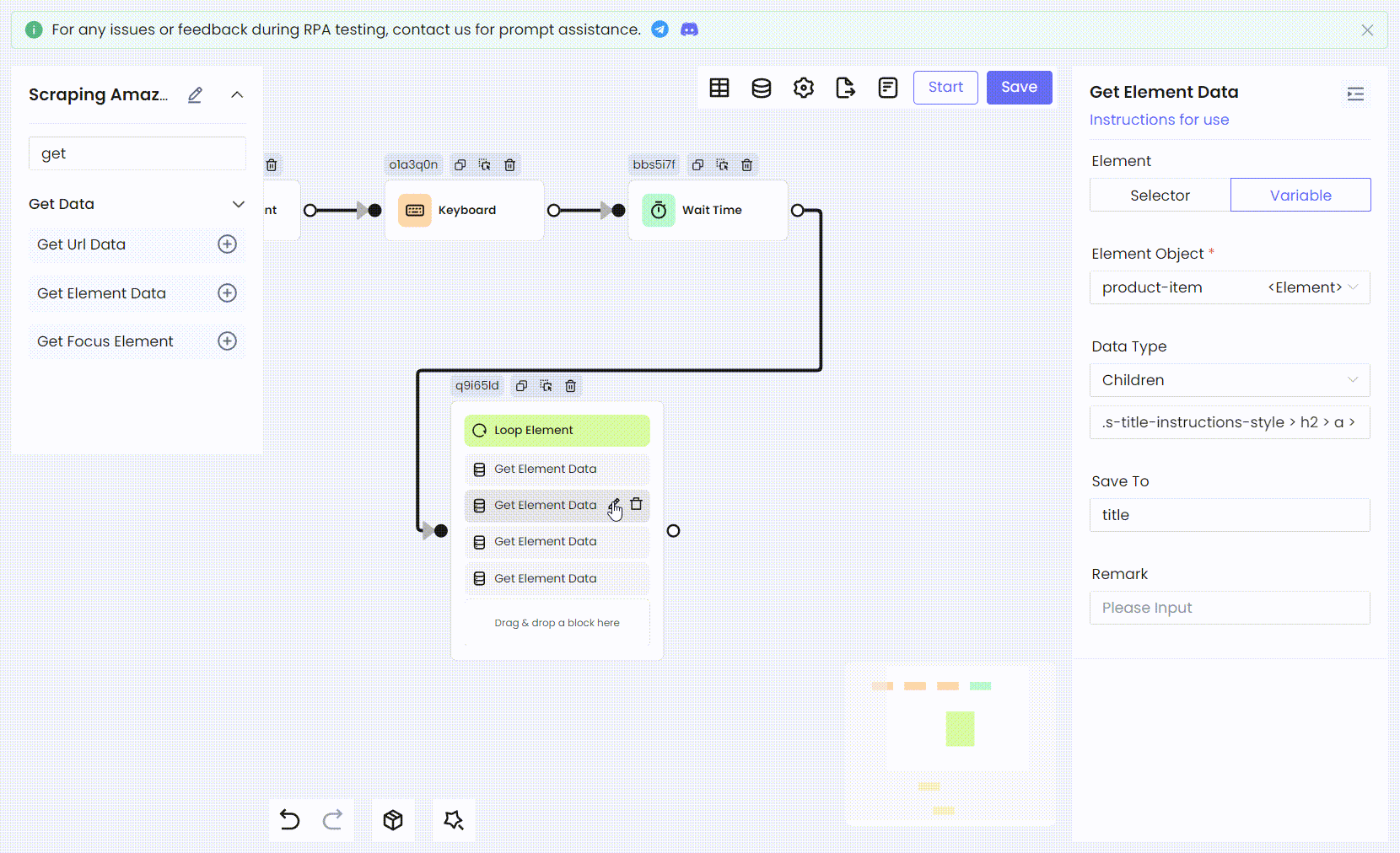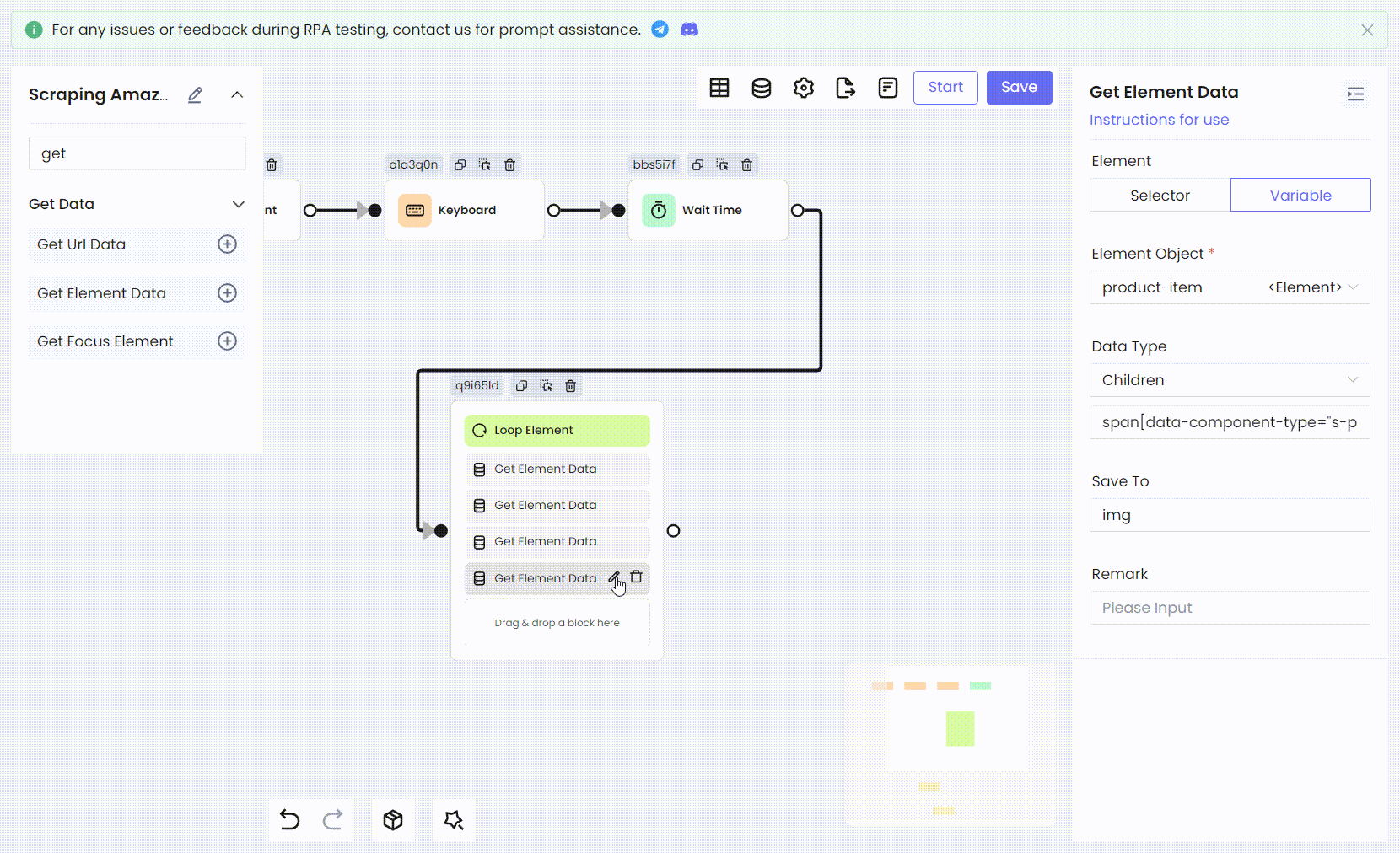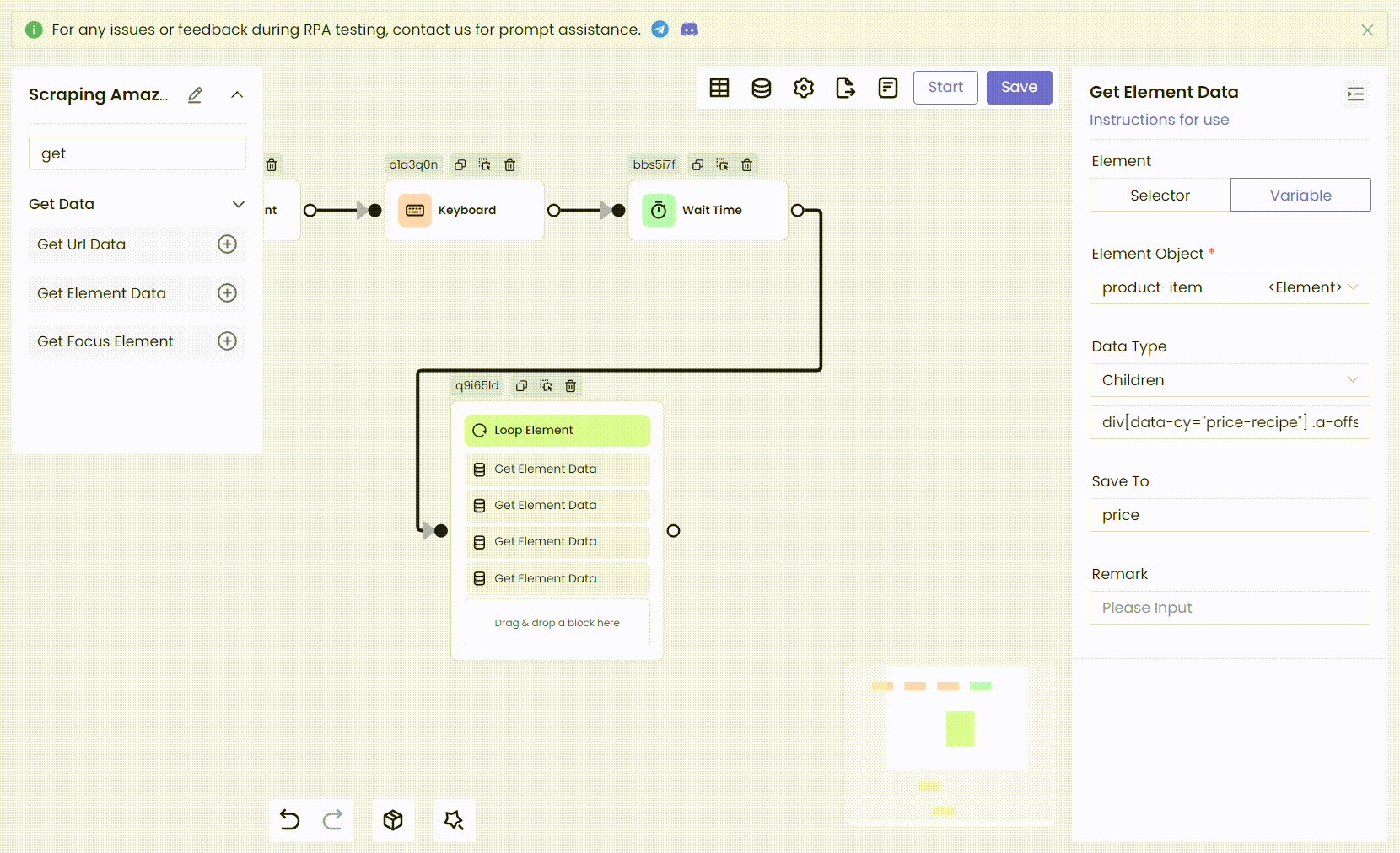
然而,上面获得的变量数据实际上都是 HTML 元素。我们还需要对其进行处理,输出 HTML 元素中的文本,并为后续的数据存储做好准备。
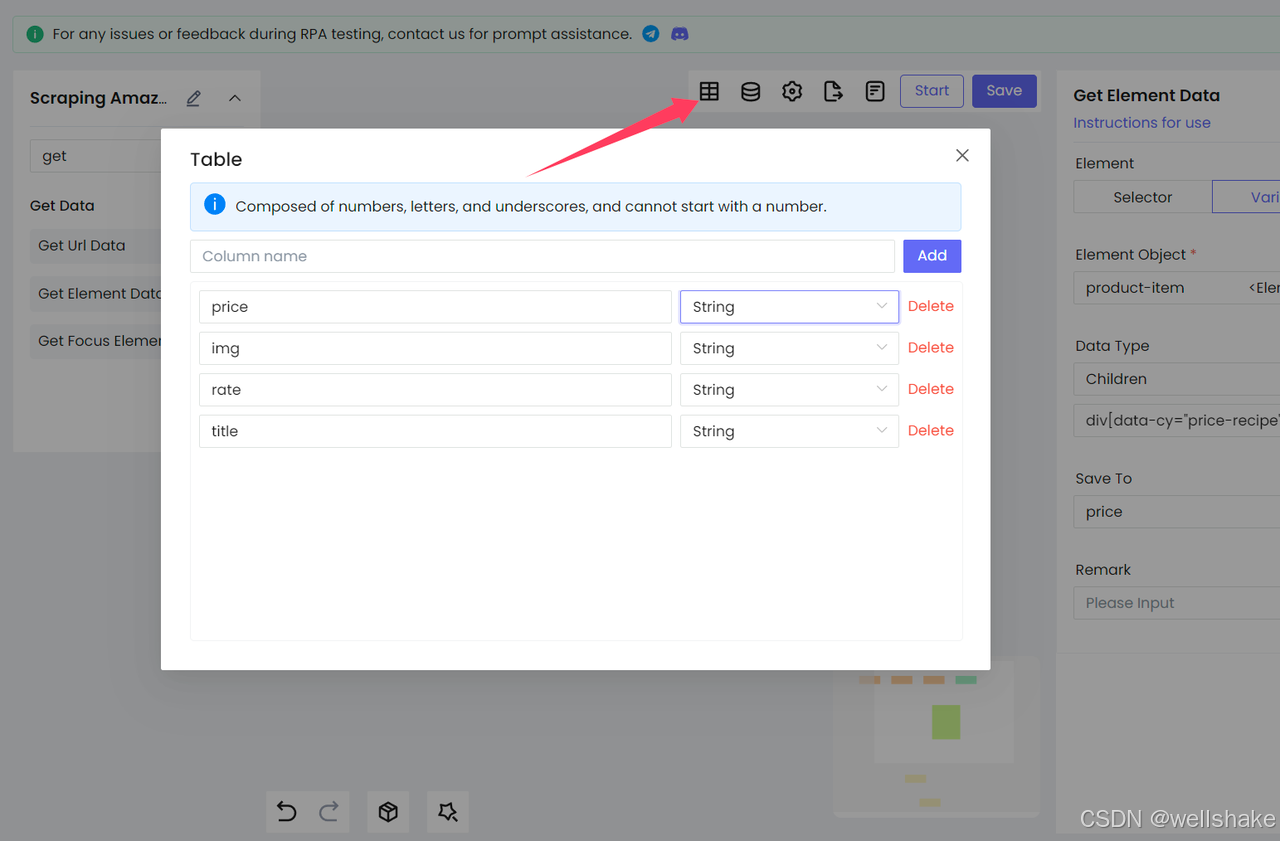
- 设置表格
我们需要
- 设置表格
- 并根据该表格的字段生成相应的 Excel:
- 获取元素的文本
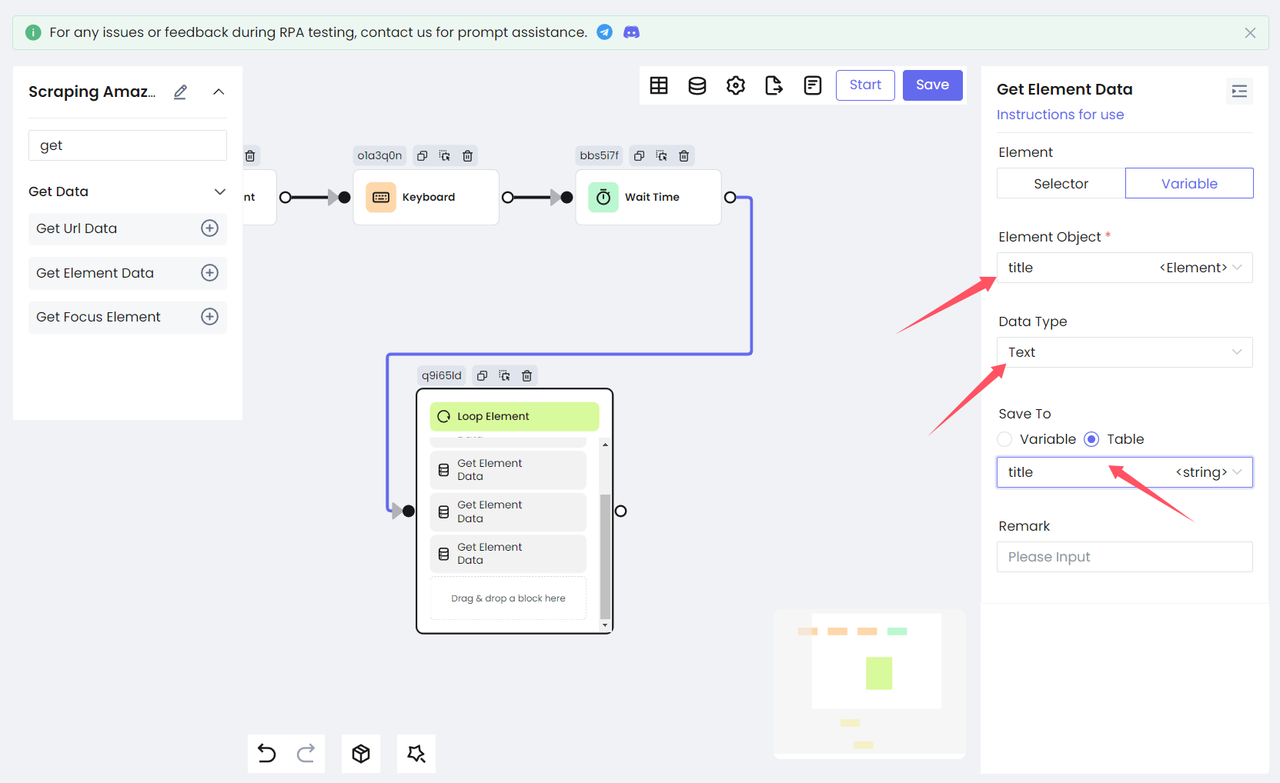
再次添加 Get Element Data 节点,将上面获得的变量输出为文本,并保存到表格变量中,以便后续的数据存储。选择 Data Type 为 Text,即可获取目标元素的 innerText。(下图展示了变量 title 的处理过程)
- 获取图片链接
然后我们使用相同的方法将商品的评分和价格转换为最终的文本信息。
图片链接需要额外的处理。这里我们使用 javascript 节点来获取当前遍历商品的图片 src。需要注意的是,Loop Element 节点保存的索引变量 productIndex 需要注入到脚本中,最后保存为变量 imgSrc。
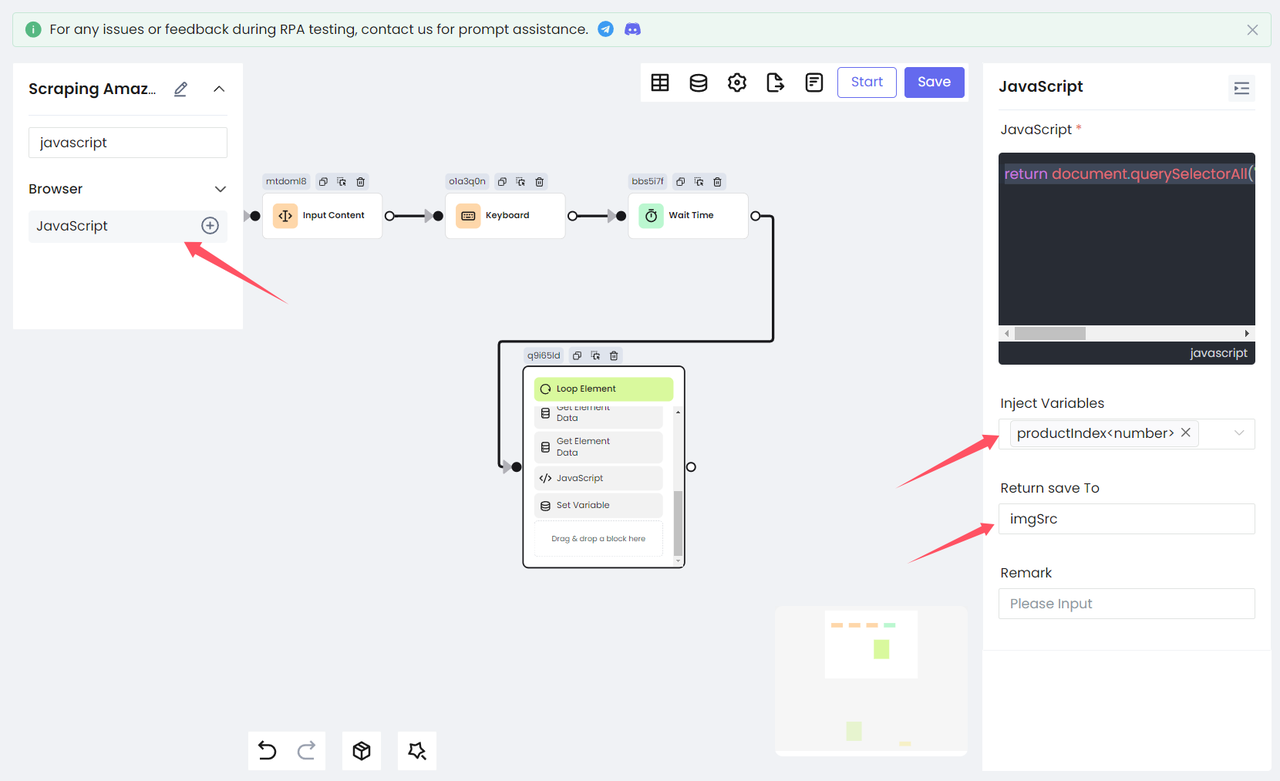
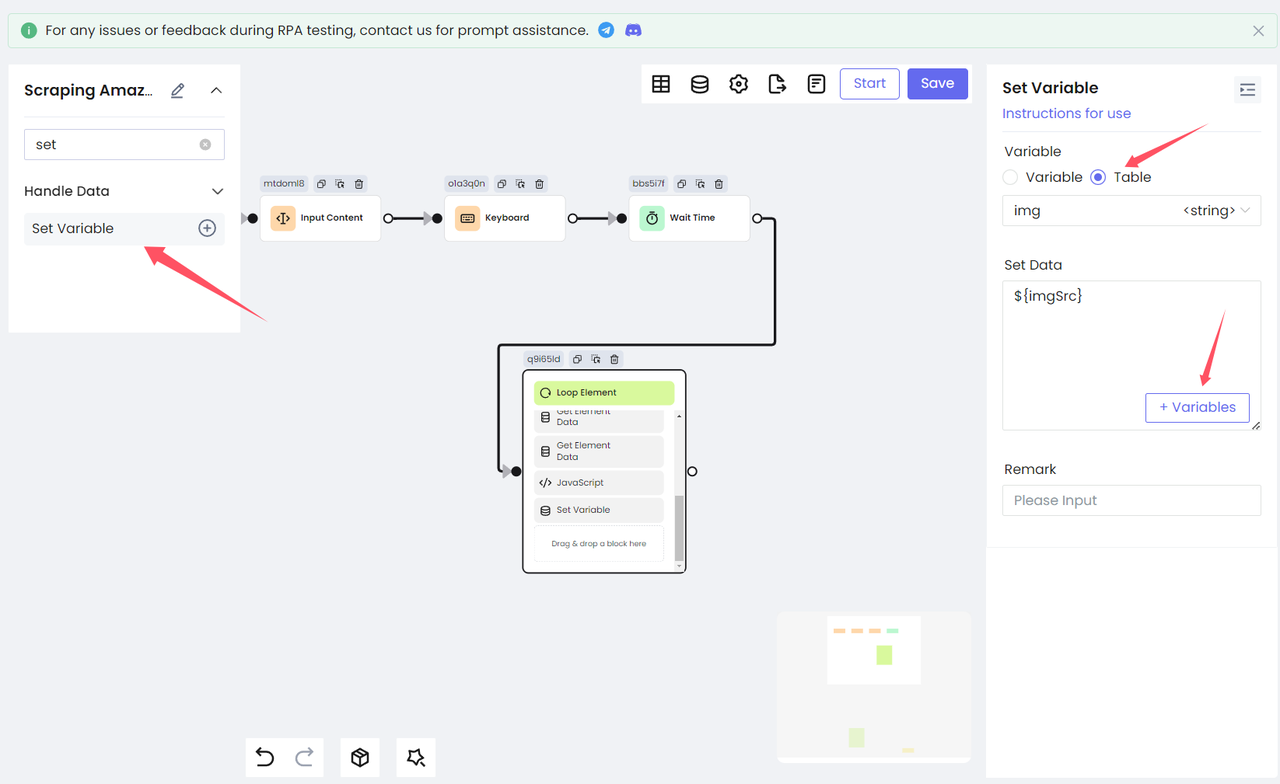
return document.querySelectorAll('[data-image-latency="s-product-image"]')[productIndex].getAttribute('src')最后,我们使用 Set Variable 节点将变量 imgSrc 存储在 table 中:
第五步. 保存结果
此时,我们已经获得了要收集的所有数据,现在该保存这些数据了。
- Nstbrowser RPA 提供两种保存数据的方式:
Save To File和Save To Excel。
Save To File提供三种文件类型供您选择 .txt, .CSV 和 .JSON。Save To Excel只能将数据保存到 Excel 文件中。
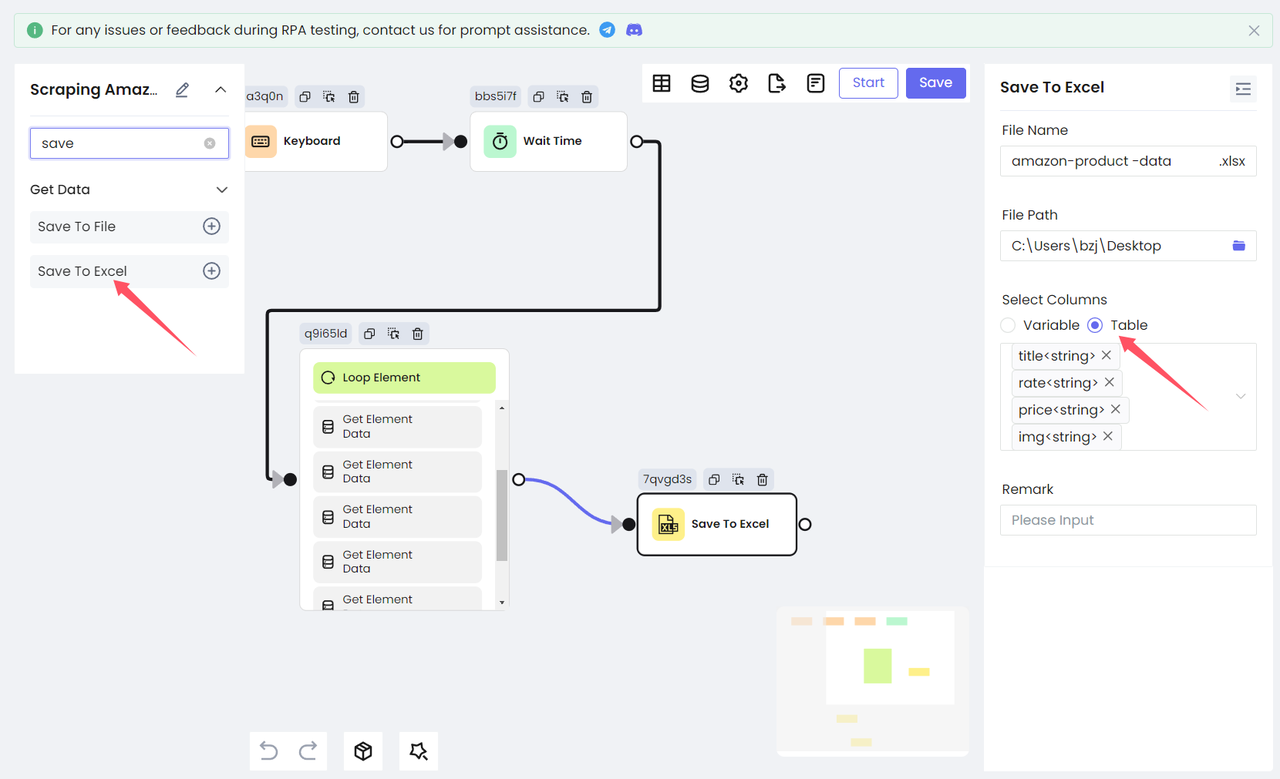
为了方便查看,我们选择将收集的数据保存到 Excel 中。添加 Save To Excel 节点,配置要保存的文件路径和文件名,选择要保存的表格内容,就完成了!
执行 RPA
先保存我们配置的工作流,然后您可以直接在当前页面上运行它,或者返回到上一页,创建新的任务,点击运行按钮运行它。此时,我们就可以开始收集亚马逊的产品数据了!
执行完成后,您可以在桌面上看到生成的 amazon-product-data.xlsx 文件。
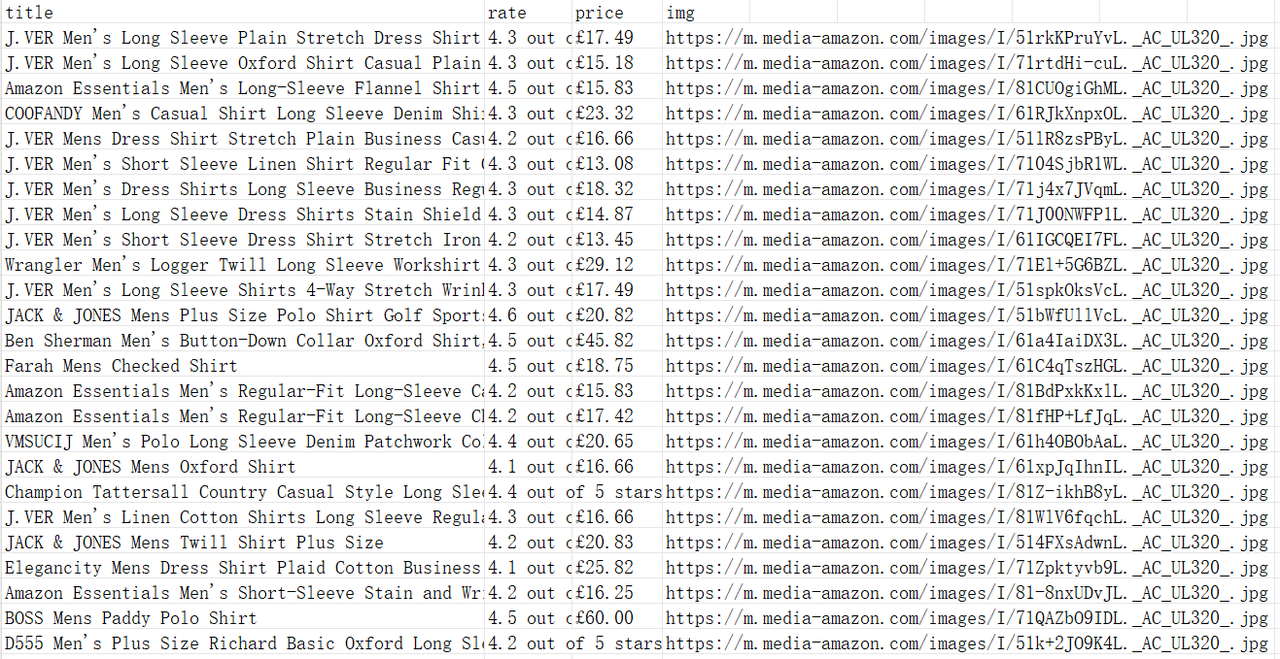
总结
使用 Browserless 构建您自己的亚马逊产品抓取器是最简单的方法。这篇 2024 年最全面的教程文章清晰地向您解释了:
- 抓取亚马逊产品的优势。
- Browserless 亚马逊产品抓取器的强大功能。
- 如何使用 Nstbrower 的 RPA 创建更简单的抓取器。
如果您对 Browserless、数据抓取或自动化有特殊需求,访问 Nstbrowser 官网寻求定制化服务。
原文地址:https://blog.csdn.net/wellshake/article/details/143625532
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!