Java项目中整合多个pdf合并为一个pdf
一、Java项目中整合多个pdf合并为一个pdf
gitee笔记路径:https://gitee.com/happy_sad/drools
一、依赖导入
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.6</version>
</dependency>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
<version>7.6.0.Final</version>
</dependency>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-internal</artifactId>
<version>7.6.0.Final</version>
</dependency>
二、设置端口
server.port=8082
三、设置已存在的多个pdf
注意:此次为模拟获取多个pdf,所以本人做两个pdf的合并实验,所以将两个pdf放入项目中的/resources/mergepdfs文件夹中,合并时遍历该文件夹下的所有文件,转换字节流
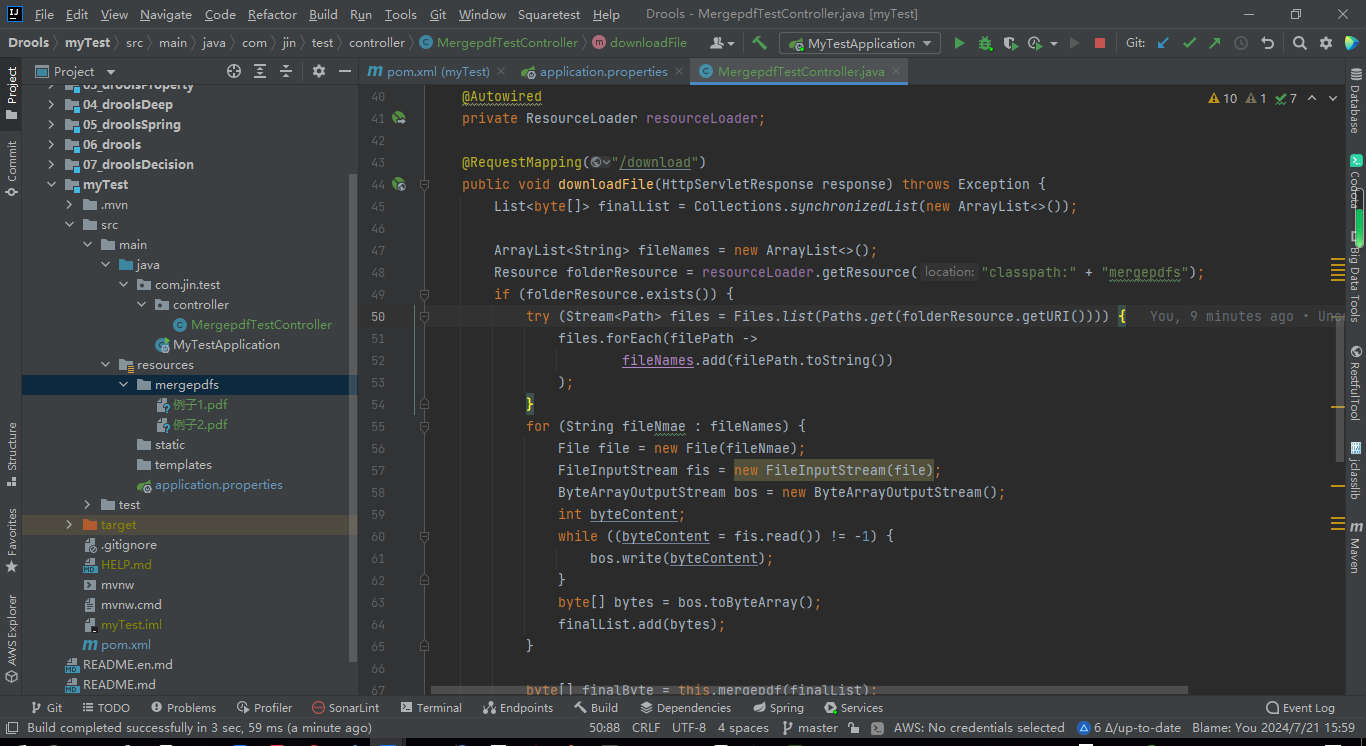
四、controller
package com.jin.test.controller;
import com.itextpdf.text.Document;
import com.itextpdf.text.pdf.PdfCopy;
import com.itextpdf.text.pdf.PdfImportedPage;
import com.itextpdf.text.pdf.PdfReader;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
/**
* @Package:com.jin.test.controller
* @ClassName: MergepdfTestController
* @Description: 项目中整合多个pdf合并为一个pdf
* @Date: 2024/07/21 14:22
* @Author: Jin
*/
@Log4j2
@RestController
@RequestMapping("/mergepdf")
public class MergepdfTestController {
@Autowired
private ResourceLoader resourceLoader;
@RequestMapping("/download")
public void downloadFile(HttpServletResponse response) throws Exception {
List<byte[]> finalList = Collections.synchronizedList(new ArrayList<>());
ArrayList<String> fileNames = new ArrayList<>();
Resource folderResource = resourceLoader.getResource("classpath:" + "mergepdfs");
if (folderResource.exists()) {
try (Stream<Path> files = Files.list(Paths.get(folderResource.getURI()))) {
files.forEach(filePath ->
fileNames.add(filePath.toString())
);
}
for (String fileNmae : fileNames) {
File file = new File(fileNmae);
FileInputStream fis = new FileInputStream(file);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int byteContent;
while ((byteContent = fis.read()) != -1) {
bos.write(byteContent);
}
byte[] bytes = bos.toByteArray();
finalList.add(bytes);
}
byte[] finalByte = this.mergepdf(finalList);
ServletOutputStream outputStream = response.getOutputStream();
outputStream.write(finalByte);
outputStream.flush();
} else {
System.out.println("Folder not found: " + "mergepdfs");
}
}
/**
* pdf合并方法
* @param bytes
* @return
* @throws Exception
*/
public byte[] mergepdf(List<byte[]> bytes) throws Exception {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Document document = new Document();
PdfCopy copy = new PdfCopy(document, bos);
document.open();
for (byte[] bs : bytes) {
PdfReader reader = new PdfReader(bs);
int pageTotal = reader.getNumberOfPages();
log.info("pdf的页码数是 ==>{}", pageTotal);
for (int pageNo = 1; pageNo <= pageTotal; pageNo++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, pageNo);
copy.addPage(page);
}
reader.close();
}
document.close();
byte[] pdfs = bos.toByteArray();
bos.close();
copy.close();
return pdfs;
}
}
五、测试结果
1、Apifox请求
http://localhost:8082/mergepdf/download
2、例子1.pdf页数为26

3、例子2.pdf页数为2

4、合并后的pdf页数为28

原文地址:https://blog.csdn.net/weixin_45207323/article/details/140589522
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!