(2024,ViM,双向 SSM 骨干,序列建模)利用双向状态空间模型进行高效视觉表示学习
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0.摘要
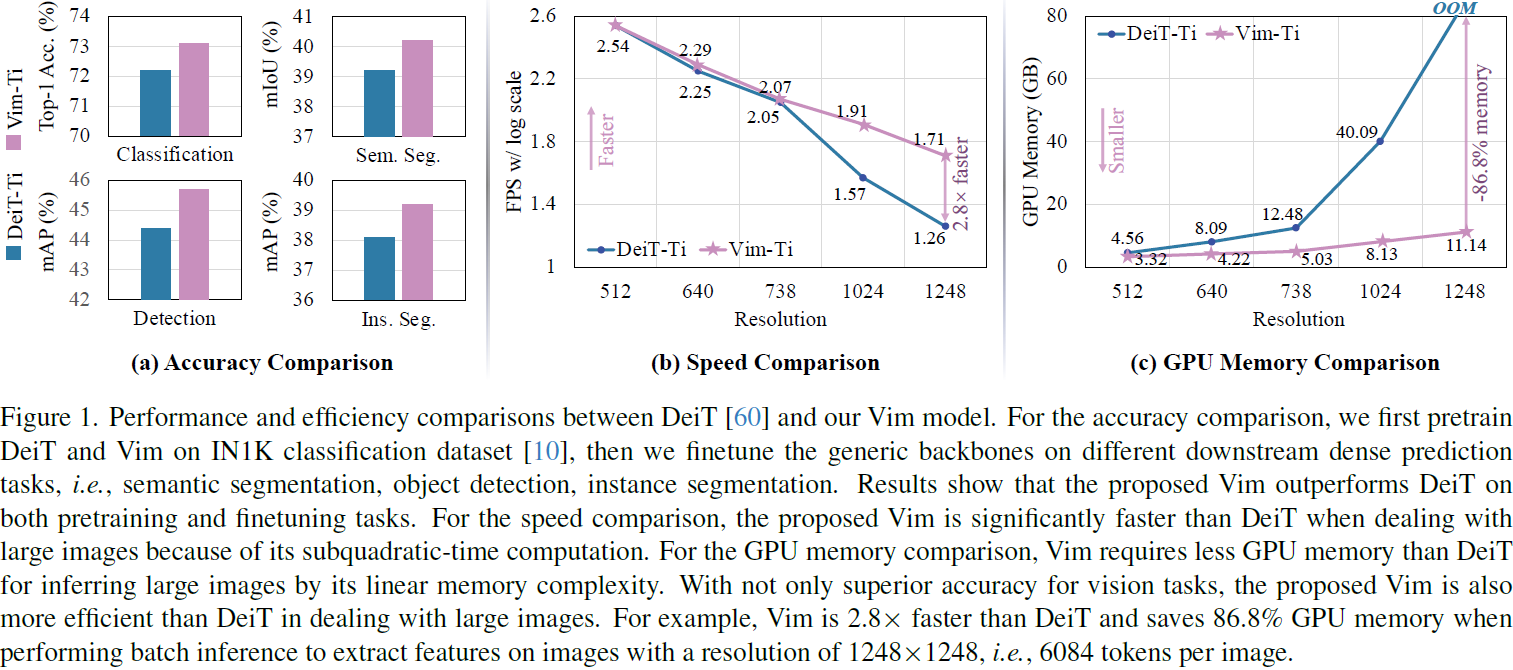
最近,具有高效硬件感知设计的状态空间模型(state space models,SSMs),即 Mamba,展现出了在长序列建模方面的巨大潜力。仅基于 SSMs 构建高效通用的视觉骨干是一个吸引人的方向。然而,由于视觉数据的位置敏感性和对全局上下文进行视觉理解的要求,用 SSMs 表示视觉数据具有挑战性。在本文中,我们展示了视觉表示学习对自注意力的依赖并非必要,并提出了一种具有双向 Mamba 块(Vim)的新型通用视觉骨干,该骨干使用位置嵌入标记图像序列并用双向状态空间模型压缩视觉表示。在 ImageNet 分类、COCO 目标检测和 ADE20k 语义分割任务中,Vim相比于已经建立良好的视觉 Transformer(如 DeiT)实现了更高的性能,同时还显著提高了计算和内存效率。例如,Vim 在执行批量推理以提取分辨率为 1248×1248 的图像特征时比 DeiT 快 2.8倍,并节省 86.8% 的GPU内存。结果表明,Vim 能够克服对高分辨率图像执行 Transformer-style理解的计算和内存约束,有望成为视觉基础模型的下一代骨干。
代码: https://github.com/hustvl/Vim
源自经典的状态空间模型 [30],现代 SSM 擅长捕捉长程依赖关系,并受益于并行训练。它们在处理长序列时效率高,这是因为卷积计算和近似线性计算。最近的工作 Mamba [20] 将时变参数纳入SSM,并提出了一种硬件感知算法,以实现高效的训练和推理。Mamba 的卓越扩展性能表明它是语言建模中对 Transformer 的一种有希望的替代方案。然而,尚未探索基于纯 SSM 的通用视觉任务骨干。
3. 方法
3.1. 基础知识
基于 SSM 的模型(即结构化状态空间序列模型(structured state space sequence models,S4))和 Mamba 均受连续系统启发,通过隐藏状态 h(t) ∈ R^N 将一个一维函数或序列 x(t) ∈ R映射到 y(t) ∈ R。该系统使用 A ∈ R^(N×N) 作为演化参数,以及 B ∈ R^(N×1)、C ∈ R^(1×N) 作为投影参数。
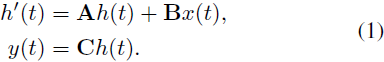
S4 和 Mamba 是连续系统的离散版本,其中包括一个时间尺度参数 Δ,用于将连续参数 A、B 转换为离散参数 -A、-B。常用的转换方法是零阶保持(zero-order hold,ZOH),其定义如下:

在对 A、B 进行离散化之后,方程(1)可重新表述为使用步长 Δ 的离散化版本,可以写成:
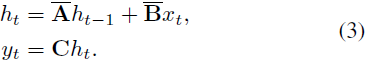
最后,模型通过全局卷积计算输出。
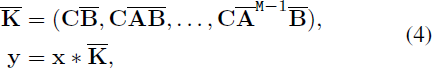
其中,M 是输入序列 x 的长度,-K ∈ R^M 是一个结构化卷积核。
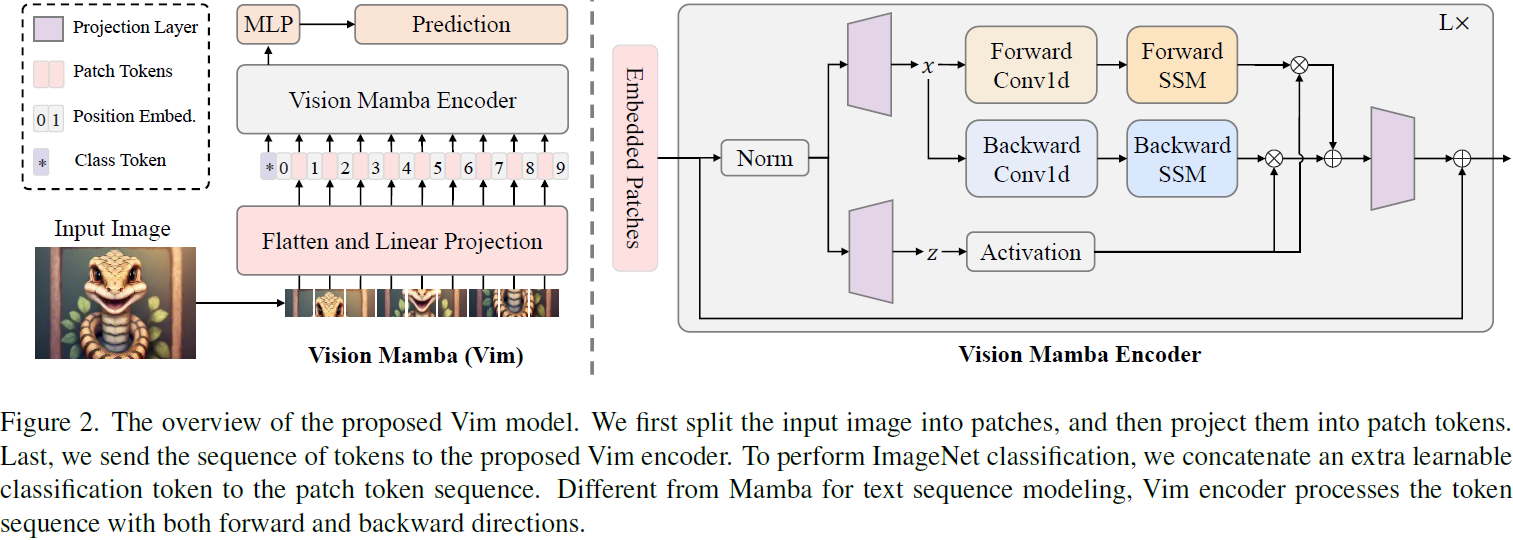
3.2. Vision Mamba
Vim 的概述如图 2 所示。标准 Mamba 设计用于 1 维序列。为了处理视觉任务,我们首先将 2 维图像 t ∈ R^(H×W×C) 转换为展平的 2 维块 x_p ∈ R^(J×(P^2·C)),其中(H,W)是输入图像的大小,C 是通道数,P 是图像块的大小。接下来,我们将 x_p 线性投影到大小为 D 的向量中,并添加位置嵌入E_pos ∈ R^((J+1)×D),如下所示:
![]()
其中,t^j_p 是 t 的第 j 个块,W ∈ R^((P^2·C)×D) 是可学习的投影矩阵。受到 ViT [14] 和 BERT [31] 的启发,我们还使用类别标记(class token)表示整个块序列,表示为 t_cls。然后,我们将标记序列 T_(l−1) 发送到 Vim 编码器的第 l 层,并得到输出 T_l。最后,我们对输出的类别标记 T^0_L进行归一化,并将其馈送到多层感知机(MLP)头部以获得最终的预测 ˆp,如下所示:

其中,Vim 是提出的 Vision Mamba 块,L 是层数,Norm 是归一化层。
3.3. Vim 块
原始的 Mamba 块设计用于 1 维序列,不适用于需要空间感知理解的视觉任务。在本节中,我们介绍 Vim 块,该块将双向序列建模纳入视觉任务中。Vim 块如图 2 所示。

具体而言,我们在 Algo. 1 中呈现了 Vim 块的操作。
- (1)首先,将输入的标记序列 T_(l−1) 通过归一化层进行归一化。
- (2-3)接下来,将归一化序列线性投影到维度为 E 的 x 和 z(注:对应于潜在 h)。
- (4)然后,我们从正向和反向方向处理 x。
- (5)对于每个方向,我们首先对 x 应用 1 维卷积,得到 x′_o。
- (6-8)然后,将 x′_o 线性投影到 B_o、C_o、Δ_o,分别得到 y_forward 和 y_backward。
- (9-10)Δ_o 然后用于转换 A_o、B_o。
- (11)最后,通过 SSM 计算 y_forward 和 y_backward。
- (13-16)y_forward 和 y_backward 然后由 z 进行门控,并相加得到输出的标记序列 T_l。
3.4. 架构细节
总体而言,我们架构的超参数如下所列:
- B:Batch?没找到具体说明
- M:输入序列 x 的长度,
- L:块的数量,
- D:隐藏状态维度,
- E:扩展状态维度,
- N:SSM 维度。
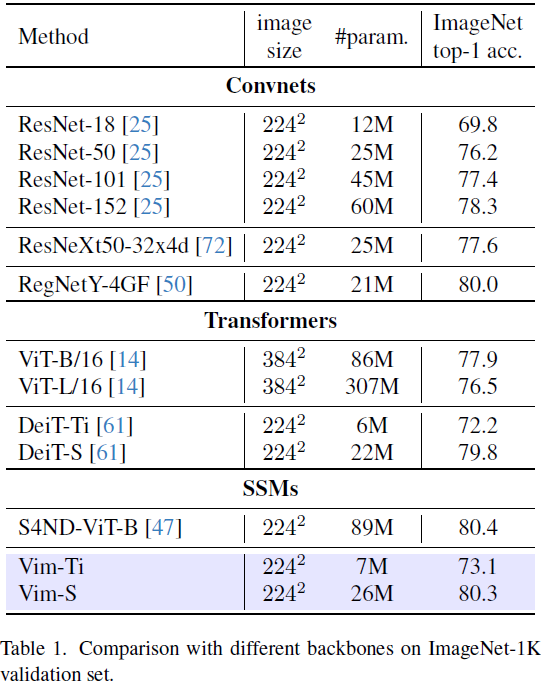
按照 ViT [14] 和 DeiT [61] 的做法,我们首先使用 16×16 的核大小投影层,以获得一个非重叠块嵌入的 1 维序列。随后,我们直接堆叠 L 个 Vim 块。默认情况下,我们将块的数量 L 设置为 24,SSM 维度 N 设置为 16。为了与 DeiT 系列的模型大小保持一致,我们将隐藏状态维度 D 设置为192,扩展状态维度 E 设置为 384,用于 tiny-size 变体。对于 small-size 变体,我们将 D 设置为384,E 设置为 768。
3.5. 效率分析
传统的基于 SSM 的方法利用快速傅里叶变换来提高卷积操作的效率,如 Eq.(4)所示。对于依赖于数据的方法,例如 Mamba,在 Algo.1 的第 11 行的 SSM 操作不再等同于卷积。为解决这个问题,Mamba 和提出的 Vim 选择了一种现代硬件友好的方式来确保效率。这种优化的关键思想是避免现代硬件加速器(GPU)的 IO 限制和内存限制。
IO 效率。高带宽内存(HBM)和静态随机存取存储器(SRAM)是 GPU 的两个重要组件。其中,SRAM 具有更大的带宽,而 HBM 具有更大的内存大小。Vim 的 SSM 操作的标准实现需要在HBM 上进行 O(BMEN) 数量级的内存 IO。受到 Mamba 的启发,Vim 首先从慢速的 HBM 读取O(BME + EN) 字节的内存(Δo, Ao, Bo, Co),并将其写入快速的 SRAM。然后,Vim 在 SRAM 中获取大小为 (B, M, E, N) 的离散 -Ao,-Bo。最后,Vim 在 SRAM 中执行 SSM 操作,并将大小为 (B, M, E) 的输出写回 HBM。这种方法有助于将 IO 的数量从 O(BMEN) 减少到 O(BME + EN)。
内存效率。为了避免内存不足的问题并在处理长序列时实现较低的内存使用,Vim 选择了与 Mamba 相同的重计算方法。对于中间状态的大小 (B, M, E, N) 以计算梯度,Vim 在网络反向传播时重新计算它们。对于中间激活,如激活函数和卷积的输出,Vim 也重新计算它们以优化 GPU 的内存需求,因为激活值占用大量内存,但重新计算速度快。
计算效率。Vim 块中的 SSM 操作(Algo.1 的第 11 行)和 Transformer 中的自注意力都在自适应地提供全局上下文方面发挥关键作用。给定一个视觉序列 T ∈ R^(1×M×D) 和默认设置 E = 2D,全局自注意力和 SSM 的计算复杂性分别为:
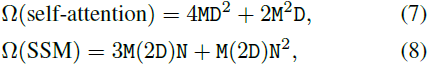
其中,自注意力对序列长度 M 是二次的,而 SSM 对序列长度 M 是线性的(N 是一个固定的参数,默认设置为 16)。计算效率使得 Vim 在具有大序列长度的千亿像素应用中具有可扩展性。
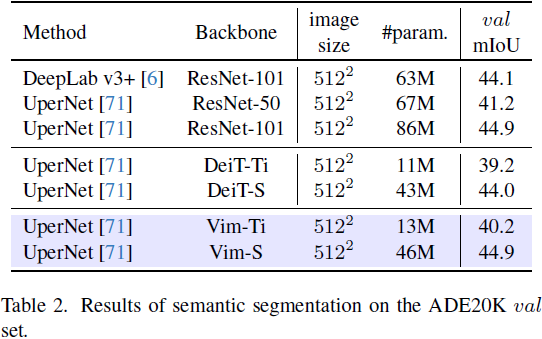
4. 实验




5. 结论与未来工作
我们提出了 Vision Mamba(Vim)来探索最近非常高效的状态空间模型,即 Mamba,作为通用的视觉骨干。与先前用于视觉任务的状态空间模型(使用混合体系结构或等效的全局 2D 卷积核)不同,Vim 以序列建模方式学习视觉表示,并且不引入图像特定的归纳偏差。由于提出的双向状态空间建模,Vim 实现了依赖于数据的全局视觉上下文,并享有与 Transformer 相同的建模能力,同时具有更低的计算复杂性。由于 Mamba 的硬件感知设计,Vim 在处理高分辨率图像时的推理速度和内存使用明显优于 ViTs。在标准计算机视觉基准测试上的实验结果验证了 Vim 的建模能力和高效性,表明 Vim 有望成为下一代视觉骨干。
在未来的工作中,具有位置嵌入的 Vim 和双向 SSM 建模适用于无监督任务,如掩蔽图像建模的预训练以及与 Mamba 相似的架构可用于多模态任务,如 CLIP 风格的预训练。基于预训练的 Vim 权重,探索 Vim 在分析高分辨率医学图像、遥感图像和长视频等可以视为下游任务的领域中的用途是非常直接的。
原文地址:https://blog.csdn.net/qq_44681809/article/details/135695644
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!