Python数据分析案例41——基于CNN-BiLSTM的沪深300收盘价预测
案例背景
虽然我自己基于各种循环神经网络做时间序列的预测已经做烂了.....但是还是会有很多刚读研究生或者是别的领域过来的小白来问这些神经网络怎么写,怎么搭建,给我一篇论文看看感觉很厉害的样子。我一看:普刊、单变量时间序列预测、一个模型预测和对比、模型是CNN-LSTM。。。。。。我大为震惊,虽然在深度学习领域现在没得Transformer都是垃圾.....但是其他领域的论文还是在乐此不疲的用CNN,MLP(外行叫BP神经网络),RNN,LSTM,GRU,用这些基础的神经网络模块然后加一点别的模块来排列组合,以此来写论文发表......
什么CNN-LSTM, CNN-GRU, LSTM-GRU, 注意力机制+LSTM, 注意力机制+GRU, 模态分解+LSTM, 优化算法+模态分解+LSTM.........优化算法+模态分解+注意力机制+GRU,优化算法+模态分解+注意力机制+双向GRU。。。
算了,虽然他们确实没啥意义,但是毕业需要,做学术嘛,都懂的。都是学术裁缝。
别的不多说,模态分解我知道会用的就有5种(EMD,EEMD,CEEMDAN,VMD,SVMD),优化算法不计其数(PSO,SSA,SMR,CS,SMA,GA,SWO....等等各种动物园优化算法),然后再加上可能用上的神经网络(LSTM,GRU,CNN,BiLSTM,BiGRU),再加上注意力机制。简单来说,我可以组合出5*10*5*2=500种模型!!!, 而且我还没用上Transformer以及其他更高级的深度学习模块,还有不同的损失函数,梯度下降的方法,还有区间估计核密度估计等等,毫不夸张的说,就这种缝合模型,我可以组合上千种。够发一辈子的论文了。
那我今天就给大家演示一下学术裁缝,神经网络的模块的排列组合,究极缝合怪。
数据选取
做这个循环神经网络的数据很好找,时间序列都可以,例如天气 , 空气质量AQI,血糖浓度,交通流量,锂电池寿命(参考我的数据分析案例24),风电预测(参考我的数据分析案例25),太阳黑子,人口数量,经济GDP,冶金温度,商品销量........
再加上我前面说的上千种缝合模型,去用于这些不同的领域,可以写的论文3辈子都发不完......
我这里就不去找什么特定领域了,很简单,经济金融领域基本都是时间序列,我直接选个股票吧,来作为本次案例演示的数据,选取的是沪深300的指数。
优化算法和模态分解会有一点点麻烦,可以参考我以前的文章,我后面有时间写一个通用的版块。我这次就简单演示一下CNN组合双向的LSTM的模型,然后和LSTM, CNN-LSTM, BiLSTM,做对比。(随便一下就是4个模型了...)
然后关于注意力机制缝合的就下篇文章再写。(更新:基于Attention-BiGRU的时间序列数据预测)
本次案例的全部代码文件和数据集获取可以参考:(缝合模块演示)
需要定制各种缝合模块的代码的也可以私聊我。
代码实现
使用的还是小白最容易上手的Keras框架,pytorch现在好像也支持Keras了。
导入包:
import os
import math
import time
import datetime
import random as rn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_score
import tensorflow as tf
import keras
from keras.layers import Layer
import keras.backend as K
from keras.models import Model, Sequential
from keras.layers import GRU, Dense,Conv1D, MaxPooling1D,GlobalMaxPooling1D,Embedding,Dropout,Flatten,SimpleRNN,LSTM,Bidirectional
import tensorflow as tf
from keras.callbacks import EarlyStopping
#from tensorflow.keras import regularizers
#from keras.utils.np_utils import to_categorical
from tensorflow.keras import optimizers读取数据
data0=pd.read_csv('沪深300期货历史数据 (2).csv',parse_dates=['日期']).set_index('日期')[['开盘','高','低','收盘']].sort_index()
data0=data0.astype('float')
data0.head()
很标准的股票数据,把我们要预测的y——收盘价放在最后一列就行,前面都是特征。其他时间序列数据要模仿的话也是一样的。
构建训练集和测试集
自定义函数构建这种多变量时间序列分析预测的数据集的训练和测试集。
def build_sequences(text, window_size=24):
#text:list of capacity
x, y = [],[]
for i in range(len(text) - window_size):
sequence = text[i:i+window_size]
target = text[i+window_size]
x.append(sequence)
y.append(target)
return np.array(x), np.array(y)
def get_traintest(data,train_ratio=0.8,window_size=24):
train_size=int(len(data)*train_ratio)
train=data[:train_size]
test=data[train_size-window_size:]
X_train,y_train=build_sequences(train,window_size=window_size)
X_test,y_test=build_sequences(test,window_size=window_size)
return X_train,y_train[:,-1],X_test,y_test[:,-1]然后标准化,做神经网络必须标准化数据,不然很影响训练过程中的梯度
data=data0.to_numpy()
scaler = MinMaxScaler()
scaler = scaler.fit(data[:,:-1])
X=scaler.transform(data[:,:-1])
y_scaler = MinMaxScaler()
y_scaler = y_scaler.fit(data[:,-1].reshape(-1,1))
y=y_scaler.transform(data[:,-1].reshape(-1,1))查看训练集和测试集的形状
train_ratio=0.8 #训练集比例
window_size=5 #滑动窗口大小,即循环神经网络的时间步长
X_train,y_train,X_test,y_test=get_traintest(np.c_[X,y],window_size=window_size,train_ratio=train_ratio)
print(X_train.shape,y_train.shape,X_test.shape,y_test.shape)
画图看一下吧:
y_test1 = y_scaler.inverse_transform(y_test.reshape(-1,1))
test_size=int(len(data)*(1-train_ratio))
plt.figure(figsize=(10,5),dpi=256)
plt.plot(data0.index[:-test_size],data0.iloc[:,-1].iloc[:-test_size],label='训练集',color='#FA9905')
plt.plot(data0.index[-test_size:],data0.iloc[:,-1].iloc[-(test_size):],label='测试集',color='#FB8498',linestyle='dashed')
plt.legend()
plt.ylabel('沪深300',fontsize=14)
plt.xlabel('日期',fontsize=14)
plt.show()
看一下对应的时间区间:
print(f'训练集开始时间{data0.index[:-test_size][0]},结束时间{data0.index[:-test_size][-1]}')
print(f'测试集开始时间{data0.index[-test_size:][0]},结束时间{data0.index[-test_size:][-1]}')
定义评价指标
对于回归问题,我们采用MSE,RMSE,MAE,MAPE这几个指标来评价预测效果
def set_my_seed():
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(1)
rn.seed(12345)
tf.random.set_seed(123)
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
#r_2=r2_score(y_test, y_predict)
return mse, rmse, mae, mape #r_2定义模型
,我这里写了MLP,LSTM,GRU,BiLSTM,'CNN+LSTM','CNN+BiLSTM' 这几种模型。
def build_model(X_train,mode='LSTM',hidden_dim=[32,16]):
set_my_seed()
model = Sequential()
if mode=='MLP':
model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(Flatten())
model.add(Dense(hidden_dim[1],activation='relu'))
elif mode=='LSTM':
# LSTM
model.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))#
model.add(Dropout(0.4))
model.add(LSTM(hidden_dim[1]))
model.add(Dropout(0.5))
#model.add(Flatten())
#model.add(Dense(hidden_dim[1], activation='relu'))
elif mode=='GRU':
#GRU
model.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))
model.add(GRU(hidden_dim[1]))
elif mode=='BiLSTM':
# Bidirectional LSTM
model.add(Bidirectional(LSTM(hidden_dim[0], return_sequences=True), input_shape=(X_train.shape[-2], X_train.shape[-1])))
model.add(Dropout(0.4))
model.add(Bidirectional(LSTM(hidden_dim[1])))
model.add(Dropout(0.5))
elif mode=='CNN+LSTM':
# CNN followed by LSTM
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(X_train.shape[-2], X_train.shape[-1])))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.4))
model.add(Dense(hidden_dim[1], activation='relu'))
elif mode=='CNN+BiLSTM':
# CNN followed by BiLSTM
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(X_train.shape[-2], X_train.shape[-1])))
model.add(MaxPooling1D(pool_size=2))
model.add(Bidirectional(LSTM(hidden_dim[0])))
model.add(Dropout(0.4))
model.add(Dense(hidden_dim[1], activation='relu'))
model.add(Dense(1))
model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])
return model
有一点点代码基础应该就能看出来,这些模型的搭建就像搭积木一样简单,要什么模块就改个名字就行了(可能要注意一下数据转化的维度),所以说学术缝合模块写论文真的很水。。。
再定义一些观察模型训练用的图:
def plot_loss(hist,imfname=''):
plt.subplots(1,4,figsize=(16,4))
for i,key in enumerate(hist.history.keys()):
n=int(str('24')+str(i+1))
plt.subplot(n)
plt.plot(hist.history[key], 'k', label=f'Training {key}')
plt.title(f'{imfname} Training {key}')
plt.xlabel('Epochs')
plt.ylabel(key)
plt.legend()
plt.tight_layout()
plt.show()
def plot_fit(y_test, y_pred):
plt.figure(figsize=(4,2))
plt.plot(y_test, color="red", label="actual")
plt.plot(y_pred, color="blue", label="predict")
plt.title(f"拟合值和真实值对比")
plt.xlabel("Time")
plt.ylabel('values')
plt.legend()
plt.show()定义最终的训练函数:
df_eval_all=pd.DataFrame(columns=['MSE','RMSE','MAE','MAPE'])
df_preds_all=pd.DataFrame()
def train_fuc(mode='LSTM',batch_size=4,epochs=30,hidden_dim=[32,16],verbose=0,show_loss=True,show_fit=True):
#构建模型
s = time.time()
set_my_seed()
model=build_model(X_train=X_train,mode=mode,hidden_dim=hidden_dim)
earlystop = EarlyStopping(monitor='loss', min_delta=0, patience=5)
hist=model.fit(X_train, y_train,batch_size=batch_size,epochs=epochs,verbose=verbose,callbacks=[earlystop],validation_data=(X_test, y_test)) #
print(hist.history.keys())
if show_loss:
plot_loss(hist)
#预测
y_pred = model.predict(X_test)
y_pred = y_scaler.inverse_transform(y_pred)
#print(f'真实y的形状:{y_test.shape},预测y的形状:{y_pred.shape}')
if show_fit:
plot_fit(y_test1, y_pred)
e=time.time()
print(f"运行时间为{round(e-s,3)}")
df_preds_all[mode]=y_pred.reshape(-1,)
s=list(evaluation(y_test1, y_pred))
df_eval_all.loc[f'{mode}',:]=s
s=[round(i,3) for i in s]
print(f'{mode}的预测效果为:MSE:{s[0]},RMSE:{s[1]},MAE:{s[2]},MAPE:{s[3]}')
print("=======================================运行结束==========================================")
return hist我就不介绍我这里面自定义函数里面的参数都是什么意思了,后面使用就模仿就行,很简单。有代码基础的看不懂可以问gpt, 没代码基础的讲了也不懂....
初始化参数
window_size=5
batch_size=128
epochs=10
hidden_dim=[32,16]
verbose=0
show_fit=True
show_loss=True
mode='LSTM' #MLP,GRU开始训练
直接要用什么模型修改mode这个参数就行,使用真的很简单。
LSTM
hist=train_fuc(mode='LSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim,verbose=1)
出来的预测效果可以自己看看。
双向LSTM
hist=train_fuc(mode='BiLSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim,verbose=0)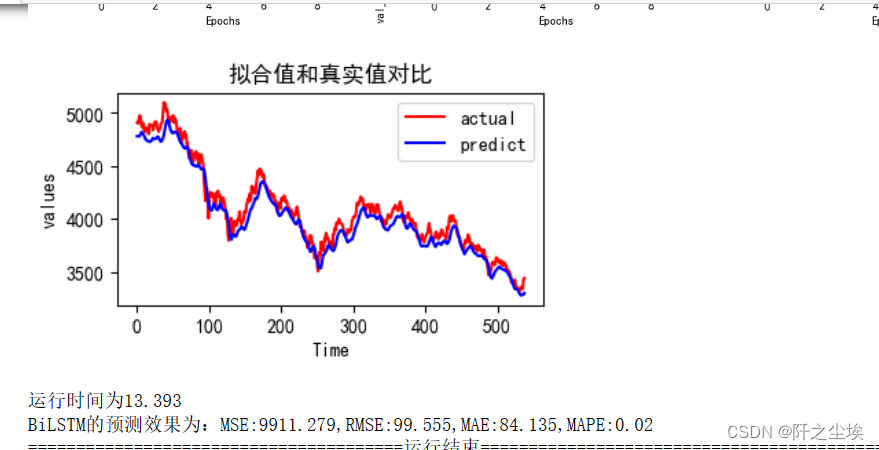
还可以画出训练过程中的损失变化图:
loss=hist.history['loss']
val_loss=hist.history['val_loss']
# 绘制训练和验证的损失值
plt.figure(figsize=(7,3),dpi=128)
plt.plot(range(len(loss)), loss, 'p-', label='训练集损失')
plt.plot(range(len(loss)), val_loss, 'y--', label='测试集损失')
plt.title('损失')
plt.xlabel('训练轮数')
plt.ylabel('损失率')
plt.xticks(range(len(loss)))
plt.legend()
plt.show() 
CNN+LSTM
hist=train_fuc(mode='CNN+LSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim,verbose=0)
CNN+BiLSTM
hist=train_fuc(mode='CNN+BiLSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim,verbose=0) 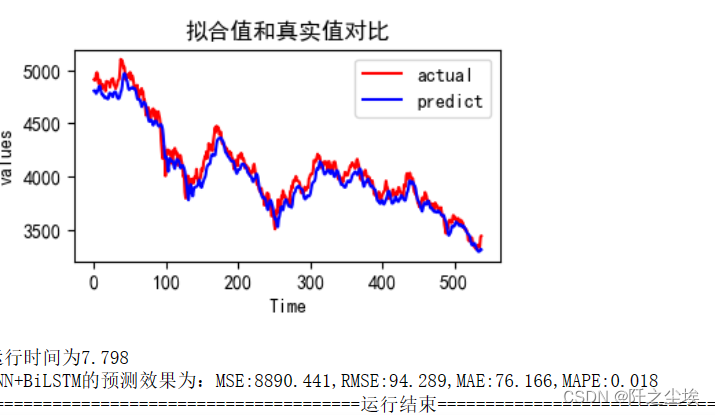
我一般都懒得一个个看这些预测效果,我自定义的函数里面都储存下来了,我下面画图一起看。方便对比。
查看评价指标对比
前面自定义函数的时候都写好了接口,都存下来了:
df_eval_all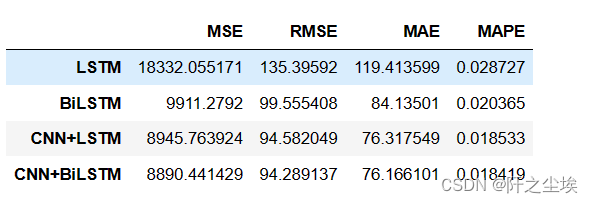
可视化:
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','gold','r']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval_all.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval_all[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()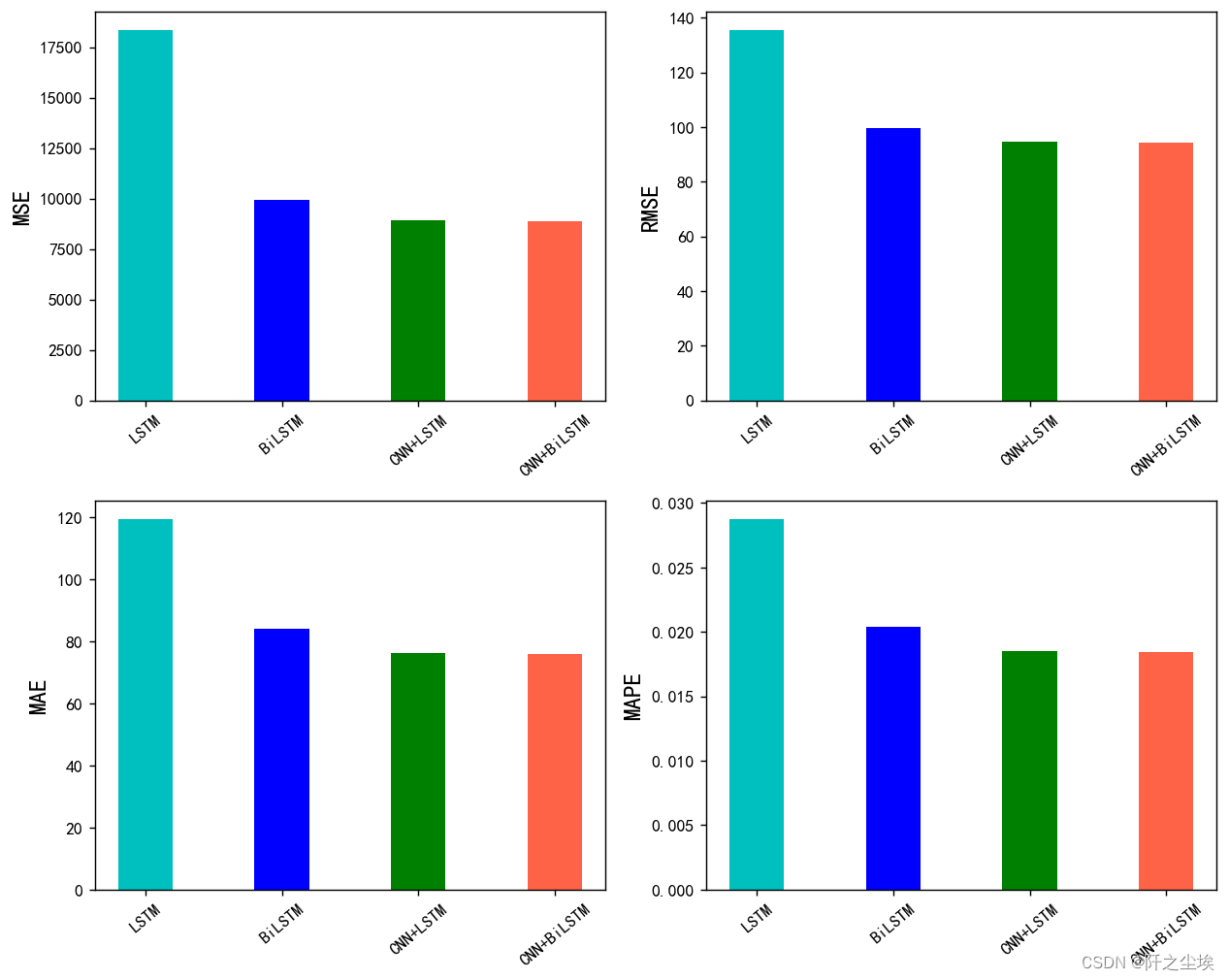
可以看到,根据给出的结果,我们可以进行以下分析来比较不同模型的预测效果:
均方误差 (MSE):MSE 衡量了模型预测与真实值之间的平均差异的平方。从结果看,CNN+BiLSTM 的 MSE 值最小,表明该模型在对数据进行预测时能够较好地匹配真实值。
均方根误差 (RMSE):RMSE 是均方误差的平方根,用于度量模型预测和真实值之间的平均差异。从结果来看,CNN+BiLSTM 的 RMSE 值最小,说明该模型在整体预测的准确性上表现较好。
平均绝对误差 (MAE):MAE 表示模型预测值与真实值之间的平均绝对差异。结果显示,CNN+BiLSTM 具有最小的 MAE 值,这意味着该模型对数据的预测偏差较小。
平均绝对百分比误差 (MAPE):MAPE 衡量了模型预测值与真实值之间的平均相对误差。根据结果,CNN+BiLSTM 的 MAPE 值最小,说明该模型在相对预测误差方面表现较好。
综合上述指标,CNN+BiLSTM 模型在这个预测任务中的效果是最好的。它在不同的误差度量指标上都表现出色,预测结果与真实值之间的差异相对较小。
效果 CNN+BiLSTM>CNN+LSTM>BiLSTM>LSTM。
是不是感觉效果很合理,加了CNN还有双向的模型是有效的?
但是这是我改了好几轮参数调出来的结果。。一开始可不是这样的。。一开始还是BiLSTM效果最好。。
深度学习都是玄学,在不同的数据集,不同的参数上,模型的效果对比有着截然不同的结论。
不要以为加的模块越多越好,加了组合模型效果一定比单一模型好,很多时候都是一顿操作猛如虎,一看效果二百五。 这是要看数据,看参数去调整的。
预测效果对比
预测出来的值和真实值一起画图。
plt.figure(figsize=(10,5),dpi=256)
for i,col in enumerate(df_preds_all.columns):
plt.plot(data0.index[-test_size-1:],df_preds_all[col],label=col) # ,color=colors[i]
plt.plot(data0.index[-test_size-1:],y_test1.reshape(-1,),label='实际值',color='k',linestyle=':',lw=2)
plt.legend()
plt.ylabel('',fontsize=16)
plt.xlabel('日期',fontsize=14)
#plt.savefig('点估计线对比.jpg',dpi=256)
plt.show()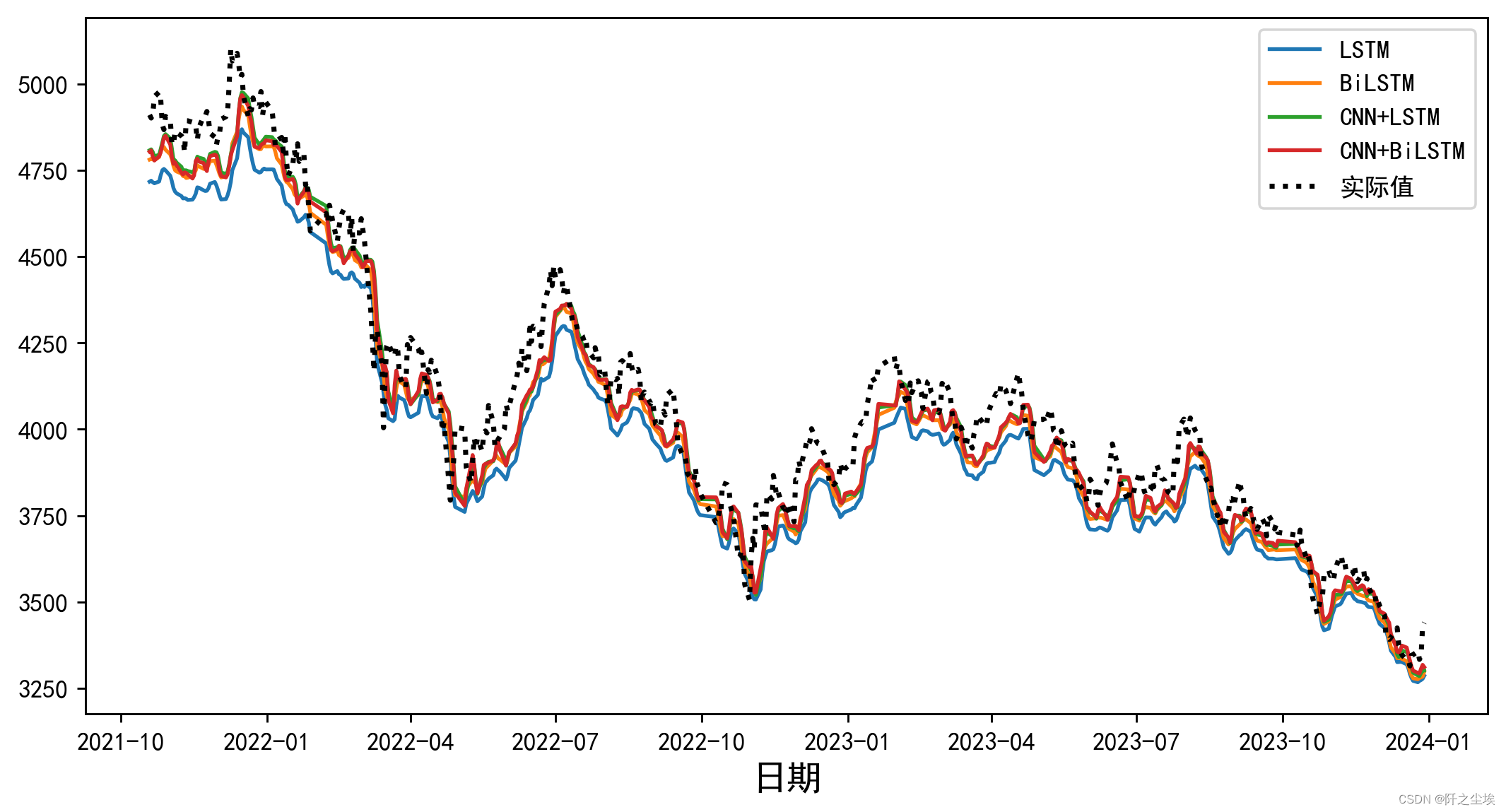
分析就不多写了,如果是发论文的话,我一般会用gpt写。。主打一个全自动。:

所以说写代码很简单,要什么模块修改我的函数参数就行。效果不好调整参数改到效果好为止。
分析文字也可以gpt写,现在水论文的成本真的很低。。。
当然发好的SCI期刊这种简单的组合模型还不够,我后面有空写一点更高级的模型,各种模态分解优化算法损失函数都组合上去.....
(更新:注意力机制缝合可以看这篇:“Python数据分析案例42——基于Attention-BiGRU的时间序列数据预测-CSDN博客”)
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)
原文地址:https://blog.csdn.net/weixin_46277779/article/details/137738446
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!