玄机----第一章 应急响应-Linux日志分析
01 前置知识点
linux常用日志路径:
1:Apache:/var/log/httpd/ /var/log/apache/ /var/log/apache2/
2:Nginx:/var/log/nginx/
3:MySQL:/var/log/mysql/ /var/log/mariadb/
4:PostgreSQL:/var/log/postgresql/
5:PHP:/var/log/php/
6:SSH(认证日志):/var/log/secure /var/log/auth.log
7:系统日志:/var/log/messages常用的linux文本处理命令:
cat 查看文件内容
cat filename # 查看文件内容
cat > filename # 重定向输出到文件,如果文件不存在则创建
cat file1 file2 > combined.txt # 将两个文件合并到一个文件中
grep 搜索文件中的文本模式
grep 'pattern' filename # 在文件中搜索包含pattern的行
grep -i 'pattern' filename # 忽略大小写搜索
grep -a 'pattern' filename # 以文本形式读取文件
awk 文本处理工具
awk '{print $1}' filename # 打印文件中每一行的第一个字段
awk '$3 > 100' filename # 打印第三个字段值大于100的行
awk 'NR % 2 == 0' filename # 打印偶数行
sort 对文本文件的内容进行排序
sort filename # 按升序对文件进行排序
sort -r filename # 按降序排序
sort -n filename # 按数值大小进行排序
uniq 过滤或合并文件中的重复行,通常与sort联合使用
sort filename | uniq # 过滤文件中的重复行
sort filename | uniq -c # 统计每行出现的频率
sort filename | uniq -d # 只显示重复出现的行
02 题目
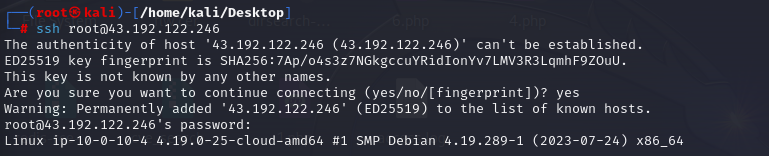
账号root密码linuxrz
ssh root@IP
1.有多少IP在爆破主机ssh的root账号,如果有多个使用","分割
2.ssh爆破成功登陆的IP是多少,如果有多个使用","分割
3.爆破用户名字典是什么?如果有多个使用","分割
4.登陆成功的IP共爆破了多少次
5.黑客登陆主机后新建了一个后门用户,用户名是多少
1.有多少IP在爆破主机ssh的root账号,如果有多个使用","分割
根据前置知识可知
linux登录相关的日志存储在**/var/log路径下的secure或auth.log**中
统计次数用uniq -c 命令
ssh连接
1.有多少IP在爆破主机ssh的root账号,如果有多个使用","分割
cd /var/log,进入日志文件夹
cd /var/log
vi auth.log.1auth.log.1 文件,是因为系统的一个日志轮换机制,当日志文件达到一定大小或满足特定的时间条件时,auth.log 文件会轮转,旧的文件会被重命名为auth.log.1
所以需要从auth.log和auth.log.1两个文件中获取内容
根据日志观察root用户登录的关键词,password for root
awk命令默认根据空格排列,所以ip在第11列
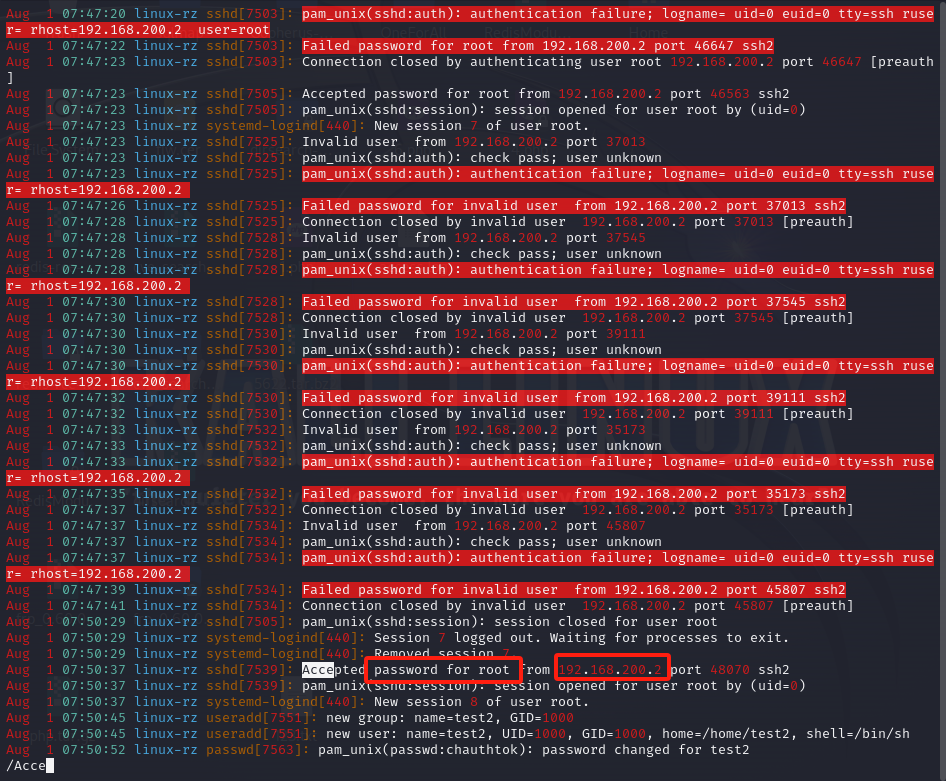
搜素爆破此主机的ip
cat auth.log auth.log.1|grep -a "password for root"|awk '{print $11}'|sort -nr|uniq -c
代码解析
以下是对这段代码的分析:
1. cat auth.log auth.log.1:
• 作用是将文件auth.log和auth.log.1的内容合并输出。通常auth.log.1可能是日志的轮转备份文件。
2. |grep -a "password for root":
• 管道符号|将上一步的输出作为输入传递给grep命令。
• -a选项用于处理二进制文件,使其如同文本文件一样被搜索。这里可能是为了确保即使日志文件中包含一些特殊字符也能正确搜索。
• "password for root"是要搜索的字符串,这个命令会从输入中筛选出包含“password for root”的行。
3. |awk '{print $11}':
• 再次通过管道接收上一步的输出。
• awk 命令打印出每一行的第 11 个字段。这意味着对于匹配到“password for root”的行,提取该行的第 11 个数据项进行输出。
4. |sort -nr:
• 继续通过管道接收上一步的输出。
• sort命令用于对输入进行排序。
• -n选项表示按照数值进行排序,而不是按照字符编码排序。
• -r选项表示逆序排序,即从大到小排序。
5. |uniq -c:
• 最后通过管道接收上一步的输出。
• uniq命令用于去除相邻的重复行。
• -c选项会在输出行前面加上重复的次数统计。
总体来说,这段代码的目的是在auth.log和auth.log.1文件中搜索包含“password for root”的行,提取这些行的第 11 个字段,对这些字段进行数值逆序排序,并统计每个不同字段出现的次数。flag
flag{192.168.200.2,192.168.200.31,192.168.200.32}2.ssh爆破成功登陆的IP是多少,如果有多个使用","分割
日志中登录成功的关键词为:Accepted,ip依旧在11列

cat auth.log auth.log.1|grep -a "Accepted"|awk'{print $11}'|sort -nr|uniq -c
flag
flag{192.168.200.2}3.爆破用户名字典是什么?如果有多个使用","分割
cat /var/log/auth.log.1 /var/log/auth.log | grep -a "Failed password" |sed -n 's/.*for \(.*\) from.*/\1/p'|uniq -c | sort -nr代码分析
以下是对这段代码的分析:
1. cat /var/log/auth.log.1 /var/log/auth.log:
• 将两个日志文件/var/log/auth.log.1和/var/log/auth.log的内容合并输出。
2. | grep -a "Failed password":
• 管道符号将上一步的输出传递给grep命令。
• -a选项用于处理可能包含二进制数据的日志文件,使其如同文本文件一样被搜索。
• "Failed password"是搜索的关键字,这个命令会筛选出包含“Failed password”的行,即记录了密码失败尝试的日志行。
3. | sed -n 's/.*for \(.*\) from.*/\1/p':
• 管道继续传递上一步的输出给sed命令。
• -n选项表示只输出经过处理后明确指定要输出的内容。
• s/.*for \(.*\) from.*/\1/p是一个替换命令,它的作用是从输入行中提取出“for”和“from”之间的内容,并输出这个提取出的部分。在这个上下文中,通常是提取出密码失败尝试所针对的用户。
4. | uniq -c:
• 再次通过管道传递输出。
• uniq -c会统计相邻的重复行,并在每行前面加上重复的次数。这样可以得到每个用户密码失败尝试的次数统计。
5. | sort -nr:
• 最后通过管道传递输出。
• sort -nr对输入进行数值逆序排序。在这里是按照密码失败尝试的次数从高到低进行排序,以便更容易看出哪些用户的密码失败尝试次数最多。
flag{user,hello,root,test3,test2,test1}4.登陆成功的IP共爆破了多少次
在日志中提取关键词Failed password,awk提取黑客登录ip,输出爆破次数
cat /var/log/auth.log.1 /var/log/auth.log | grep -a "Failed password" | awk '{if($11=="192.168.200.2") print $11}'|sort|uniq -c
flag
flag{4}5.黑客登陆主机后新建了一个后门用户,用户名是多少
新建用户关键词是new user,直接查找即可
cat /var/log/auth.log.1 /var/log/auth.log | grep -a "new user"
flag
flag{test2}原文地址:https://blog.csdn.net/a666666688/article/details/142560822
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!