如何让爬虫在管理中优雅地应对错误并实现智能重试
摘要
本文深入探讨了爬虫管理中的两大核心挑战——错误处理与重试机制,揭秘如何确保数据采集过程既稳定又高效。通过实战策略与技巧分享,帮助企业和开发者构建健壮的爬虫系统,从容面对网络异常、数据结构变化等常见难题,持续获取高质量数据。
正文
一、引言:数据采集的稳定性为何至关重要?
在大数据时代,数据采集稳定性是企业决策与市场分析的基石。无论是市场趋势预测、竞品分析,还是用户行为洞察,高质量的数据来源都是前提。爬虫作为数据采集的得力工具,其运行的稳定性和效率直接影响着后续数据分析的有效性。
二、爬虫管理的挑战:错误无处不在
2.1 网络异常:连接超时与拒绝访问
网络波动、目标网站限制访问等导致的连接问题,是爬虫最常见的挑战之一。
2.2 结构变化:动态加载与反爬策略
网页结构频繁变动、动态加载技术以及反爬虫机制,使得数据抓取路径变得不确定。
三、错误处理的艺术:让爬虫更健壮
3.1 异常捕获与分类
利用try-except语句精确捕获各类异常,并分类处理,比如针对HTTP错误码制定不同的应对策略。
3.2 日志记录:监控的双眼
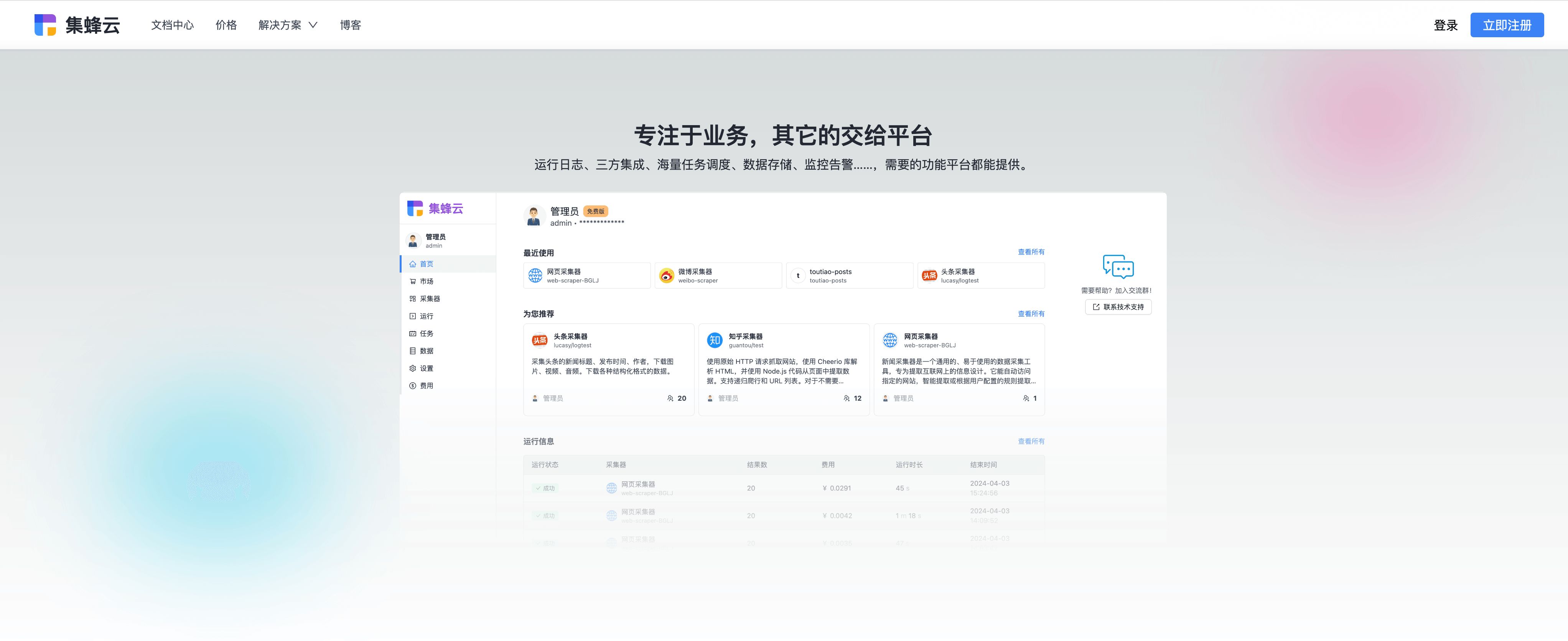
详尽的日志记录机制,便于追踪问题源头,结合集蜂云平台的运行日志查看功能,实时监控爬虫健康状态。
四、智能重试:优雅地应对失败
4.1 重试策略设计
实施基于时间间隔递增的重试策略,避免因频繁请求而被封禁,同时利用指数退避算法优化重试效率。
4.2 状态管理与任务调度
引入队列管理机制,如Redis,对任务状态进行有效跟踪,结合海量任务调度能力,灵活调整爬取节奏。
五、实战案例:某电商平台数据采集优化
某电商平台,通过上述策略,将爬虫的成功率从70%提升至95%,并在遇到反爬机制时,利用三方应用集成快速调整策略,保障数据连续性。
六、外部视角:行业最佳实践
数据采集稳定性优化指南(高质量外部链接) 该指南深入分析了多个行业案例,提供了更多关于提升数据采集稳定性的实用技巧和工具推荐。
七、总结与展望
通过精细的错误处理和智能的重试机制,我们能够显著提升爬虫系统的稳定性和数据采集效率。随着AI技术的融合,未来爬虫管理将更加自动化和智能化,为数据驱动决策提供更强大的支撑。
常见问题与解答
问:如何识别和应对反爬机制? 答:使用User-Agent池、IP代理、设置合理的请求间隔,并定期更新爬虫策略以适应目标网站的变化。
问:数据采集频率过高怎么办? 答:实施智能调度,根据服务器响应时间和目标网站负载情况动态调整爬取速度。
问:如何高效管理大量爬虫任务? 答:采用分布式爬虫架构,结合集蜂云平台的监控告警功能,实现任务的集中管理和自动故障恢复。
问:如何保证数据的一致性和完整性? 答:利用数据校验机制,对比历史数据检测异常,结合重试策略确保数据的完整收集。
问:遇到复杂登录认证怎么办? 答:实现模拟登录功能,通过Cookies或Token管理用户会话,确保爬虫能访问受限内容。
推荐内容
对于追求极致数据采集体验的用户,推荐尝试集蜂云平台,它不仅提供强大的数据采集能力,还拥有易用的界面和全面的管理工具,助您轻松驾驭数据海洋,解锁商业智能的新篇章。
原文地址:https://blog.csdn.net/zhou6343178/article/details/140578780
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!