四、(2)获取数据(补充urllib)(爬虫及数据可视化)
四、(2)获取数据(补充urllib)(爬虫及数据可视化)
urllib
此处的扩展,可以进行在主体的程序学习完成后,再回过头来学习,用于新的网站的爬取等分析
Python3中将urllib2中的功能整合到urllib中了,使用urllib就可以了

此处主要讲解urllib的扩展,可以增加创新性,也可跳过,不影响主代码的编写
get请求
#获取一个get请求
response = urllib.request.urlopen("http://www.baidu.com") #打开网页并将网页的数据返回
#print(response) #打印结果<http.client.HTTPResponse object at 0x0000013918EEF188>
#从打印的结果可以看出,返回来一个HTTPResponse的对象,此对象包含网页的所有信息,可以使用read读取出来
#print(response.read())
#对获取到的网页源码进行utf-8解码
print(response.read().decode('utf-8')) #使用decode('utf-8')解析,防止中文乱码
结果如下,简写
<!DOCTYPE html><!--STATUS OK-->
<html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。"><link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" /><link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" /><link rel="icon" sizes="any" mask
...........
<script>
if (navigator.userAgent.indexOf('Edge') > -1) {
var body = document.querySelector('body');
body.className += ' browser-edge';
}
</script>
<textarea id="s_is_result_css" style="display:none;">
post请求
#获取一个post请求
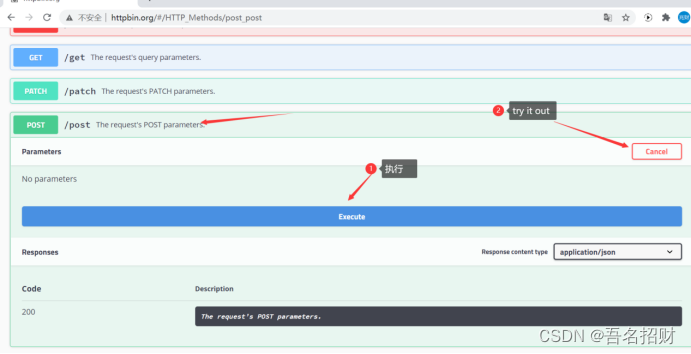
#访问网址,可发送表单,可将用户名、密码加密
#post必须有服务器端的获取响应才行,又不想写一个服务器代码,使用网址httpbin.org可用来测试
#当向此网址发送请求时会响应,可进行测试自己的请求的响应

#获取一个post请求
#访问网址,可发送表单,可将用户名、密码加密
#post必须有服务器端的获取响应才行,又不想写一个服务器代码,使用网址httpbin.org可用来测试
#当向此网址发送请求时会响应,可进行测试自己的请求的响应
'''
response = urllib.request.urlopen("http://httpbin.org/post") #此处默认进行post请求的
print(response) #直接打印会报错,urllib.error.HTTPError: HTTP Error 405: METHOD NOT ALLOWED
#是不能直接进行post访问的,需要对发送表单封装才能进行post访问
'''
import urllib.request
import urllib.parse #解析器,可以解析键值对,
#bytes() 可以将里面数据转换成2进制的数据包
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8") #使用utf-8的方式将键值对解析,并封装成2进制数据
#data可以作为post传递的内容
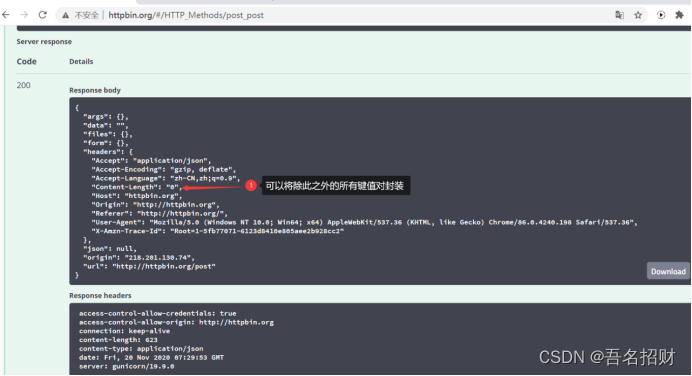
response = urllib.request.urlopen("http://httpbin.org/post",data=data)
print(response.read().decode('utf-8'))
上方一段代码运行后
Response body
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7",
"X-Amzn-Trace-Id": "Root=1-5fb778bb-56192ac74ae35b32718702aa"
},
"json": null,
"origin": "218.201.130.74",
"url": "http://httpbin.org/post"
}
上方会将收到的表单放入form显示()
使用urlib模拟浏览器发送请求
若使用post方式访问是,必须按照post方式封装数据
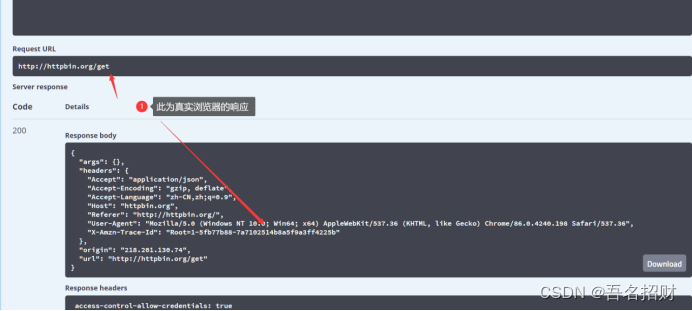
#get请求无需传递data
response = urllib.request.urlopen("http://httpbin.org/get")
print(response.read().decode('utf-8'))
User-Agent
下方的User-Agent,直接告诉浏览器自己是爬虫,若对方有防御,只要有Python-urllib/3.7就无法爬取。
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7",
"X-Amzn-Trace-Id": "Root=1-5fb77b02-41623d10507c765005fe7ed1"
},
"origin": "218.201.130.74",
"url": "http://httpbin.org/get"
}
Response
单段代码,可直接运行
import urllib.request
#超时处理
#对于超时,需要有个计划性的准备
#不一定是0.01秒,正常3秒,5秒还没有响应就不用爬取了
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01) #此处若超时0.01就报错
print(response.read().decode('utf-8'))
except urllib.error.URLError as e: #若有多个错误可以加入
print("timeout!")
#当返回状态码为418,则表明被发现是爬虫了
#平常经常使用请求看网页,看信息,此处可以简单解析
#response = urllib.request.urlopen("http://douban.com")
#print(response.status) #urllib.error.HTTPError: HTTP Error 418: 被发现是爬虫
#response = urllib.request.urlopen("http://httpbin.org/get")
#print(response.status) #200 表示正常
response = urllib.request.urlopen("http://www.baidu.com")
print(response.getheaders()) #拿到整个header信息
print(response.getheader("Server")) #可以拿到里面的具体内容
打印结果
[('Bdpagetype', '1'), ('Bdqid', '0xab3ddba0000896e8'), ('Cache-Control', 'private'), ('Content-Type', 'text/html;charset=utf-8'), ('Date', 'Fri, 20 Nov 2020 08:41:34 GMT'), ('Expires', 'Fri, 20 Nov 2020 08:41:20 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=F9D3BADF25A1AA5CE17143909FE3D220:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=F9D3BADF25A1AA5CE17143909FE3D220; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1605861694; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=F9D3BADF25A1AA5C801B5470001E58EF:FG=1; max-age=31536000; expires=Sat, 20-Nov-21 08:41:34 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=1; path=/'), ('Set-Cookie', 'H_PS_PSSID=1463_32855_33117_33058_31253_33099_33100_32962_26350_22158; path=/; domain=.baidu.com'), ('Traceid', '1605861694261455130612339260034306840296'), ('Vary', 'Accept-Encoding'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]
BWS/1.1
与下方的进行对比可得
Response引入的对象不仅仅将网页信息保存,还能获取请求中的头部信息状态码等。
#爬取爬虫时,需要将自己模拟为一个浏览器
url = "https://www.douban.com"
#需要将自己的请求对象再次封装一下
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST")
主要的是user-agent这就是关键,要想完全模拟甚至可以将上面的所有内容args,data,headers等键值对中的全部封装
Headers中的内容怎么得到,在浏览器的检查中,有user-agent,将当前浏览器的复制下来
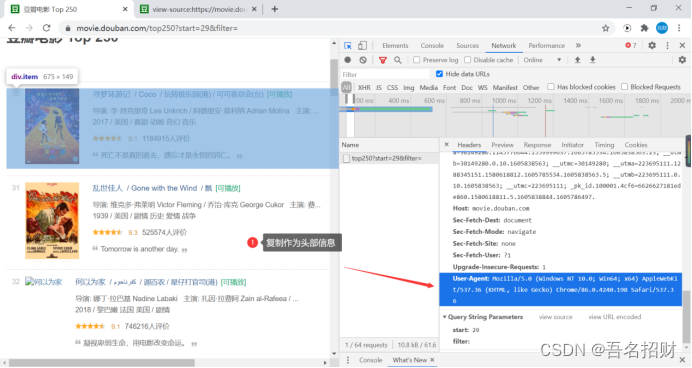
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
模拟真实信息
#爬取爬虫时,需要将自己模拟为一个浏览器
#url = "https://www.douban.com"
url = "http://httpbin.org/post"
#需要将自己的请求对象再次封装一下
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
data = bytes(urllib.parse.urlencode({"name":"eric"}),encoding="utf-8") #使用utf-8的方式将键值对解析,并封装成2进制数据
#data可以作为post传递的内容
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST") #构建的是请求对象
#需要发出请求
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
#下面是访问真实豆瓣的代码(可以模拟浏览器,欺骗豆瓣了)
#爬取爬虫时,需要将自己模拟为一个浏览器(爬取豆瓣的网页,一定要将浏览器的user-agent信息填写)
url = "https://www.douban.com"
#需要将自己的请求对象再次封装一下
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
#data = bytes(urllib.parse.urlencode({"name":"eric"}),encoding="utf-8") #使用utf-8的方式将键值对解析,并封装成2进制数据
#data可以作为post传递的内容
req = urllib.request.Request(url=url,headers=headers) #构建的是请求对象
#需要发出请求
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
打印结果如下
<!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
<head>
<meta charset="UTF-8">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">
<meta name="keywords" content="豆瓣,小组,电影,同城,豆品,广播,登录豆瓣">
<meta property="qc:admins" content="2554215131764752166375" />
<meta property="wb:webmaster" content="375d4a17a4fa24c2" />
<meta name="mobile-agent" content="format=html5; url=https://m.douban.com">
<title>豆瓣</title>
<script>
。。。
在豆瓣spider中真实实现

https://movie.douban.com/top250?start=0
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
#得到指定一个url的网页内容
def askURL(url):
#head作用是为了让对方自己是浏览器,模拟浏览器头部信息,向豆瓣服务器发送消息
#head信息一定不要写错,否则会返回否码为418,对方不认为我们是浏览器
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"} #如果信息不多的话,可以使用键值对的方式,若很多的话可以使用列表的方式head=[]
#用户代理。表示告诉豆瓣服务器。我们是什么类型的机器。浏览器(本质上是告诉浏览器。我们可以接收什么水平的文件内容)
#发送消息使用下方方式
request = urllib.request.Request(url=url, headers=head) # 构建的是请求对象,使用Request()封装了请求对象,此对象包含url和head头部信息
#可以携带头部信息访问url,
try:
response = urllib.request.urlopen(request) #发送请求对象,返回一个response对象,此对象包含我们的网页信息
html = response.read().decode("utf-8") #将读取的html界面读取出来
print(html)
except urllib.error.URLError as e: #访问时可能会遇到404遇到一些浏览器内部错误,如500等
if hasattr(e,"code"): #将里面的如404等code打印出来
print(e.code)
if hasattr(e, "reason"): #将产生的错误的原因打印出来
print(e.reason)
return html
执行上面的函数可以得到结果如下
<!DOCTYPE html>
<html lang="zh-CN" class="ua-windows ua-webkit">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="renderer" content="webkit">
<meta name="referrer" content="always">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<title>
豆瓣电影 Top 250
</title>
<meta name="baidu-site-verification" content="cZdR4xxR7RxmM4zE" />
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Expires" content="Sun, 6 Mar 2005 01:00:00 GMT"
。。。。。
原文地址:https://blog.csdn.net/qq_44870829/article/details/140146989
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!