专业技能(挖坑填坑)——Java核心基础知识,对集合、线程
熟悉Java核心基础知识,对集合、线程等都有了解,能运用模块化、面向对象的方式编程。
1.Java八种基本数据类型

Java的数据类型分为两大类:①基本数据类型 ②引用数据类型

1.重写和重载区别
重写:是子类对父类方法重写,要求方法名、参数列表、返回值类型与父类相同,修饰符访问权限要大于等于父类,抛出的异常小于等于父类。如果父类方法修饰符为private,那么子类就不能重写该方法。
重载:是同一类中,不同的函数使用相同 的函数名,要求方法名相同,参数类型个数顺序、返回值类型有不同。
2.==和 equals 的区别
==:对基本数据类型比较值是否相等;对引用数据类型比较地址是否相同。
equals:默认比较地址是否相同,对String、Integer、Date等对equals进行重写,可以比较内容是否相同。
3.接口和抽象类的区别
实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
类可以实现很多个接口;但是只能继承一个抽象类。
核心区别: 抽象类中可以包含普通方法和普通字段, 这样的普通方法和字段可以被子类直接使用(不必重写),
而接口中不能包含普通方法, 子类必须重写所有的抽象方法.
构造函数:抽象类可以有构造函数;接口不能有。
main 方法:抽象类可以有 main 方法,并且我们能运行它;接口不能有 main 方 法。
访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符
4.String、StringBuffer、StringBuilder区别
可变性:
String类中他使用的是字符数组保存字符串,所以String对象他是不可变的
StringBuffer、StringBuilder这两种是可变的
线程安全性:
String的对象他是不可变的,可就可以理解为是常量,线程是安全的。
StringBuffer对方法中加了同步锁或者对调用方法加了同步锁,所以线程是安全的。
StringBuilder并没有对方法进行加同步锁,所以是非线程安全的
性能:
每次对String类型进行改变的时候,都会生成一个String对象,这时候空指针会指向新的String对象。
操作少量的字符串 用String; 单线程下需要操作大量数据 用StringBuilder;多线程下需要操作大量数据 用StringBuffer
5.java几种关键字的区别
5.String 对象的创建
JDK7之后:
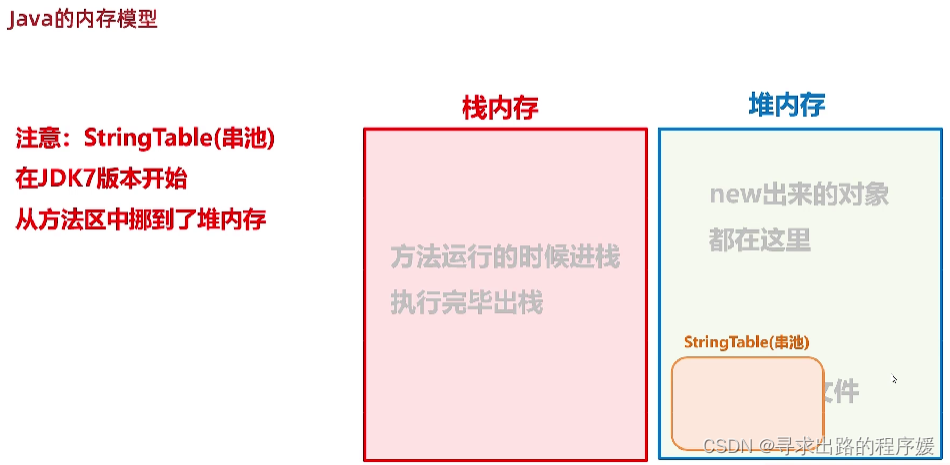
(1)有两种方式创建String对象:字面量赋值、new关键字
- 字面值创建:JVM首先检查字符串常量池中是否已经存在该字符串,如果存在 则直接返回字符串对象的引用,否则就创建一个新的字符串对象并放入字符串常量池中,最终将该对象的引用赋值给变量str。【字符串常量池中不会存储相同内容的字符串】
- 通过new关键字创建字符串对象:会先检查字符串常量池中是否有相同的字符串,如果有则拷贝一份放到堆中,然后返回堆中地址;如果没有 就先在字符串常量池中创建"abc"这个字符串,而后再复制一份放到堆中 并把堆地址返回给str。【字符串常量池和堆内存都会有这个对象】
- 方式一效率比方式二高。
(2) String str1="abc"和String str2=new String(“abc”)区别
- String str=“abc"创建了几个对象? 0个 或 1个。如果字符串常量池中没有"abc”,则在常量池中创建"abc" 并让str引用指向该对象(1个);如果字符串常量池中有"abc",则一个都不创建 直接返回地址值给str(0个)
- String str=new String(“abc”)创建了几个对象? 1个 或 2个。如果字符串常量池中没有"abc",则在字符串常量池和堆内存中各创建一个对象,返回堆地址(2个);如果常量池中有"abc",则只在堆中创建对象并返回地址值给str(1个)。【new相当于在堆中新建了value值,每new一个对象就会在堆中新建,地址值也因此不同,堆中的value存储着指向常量池的引用地址】
(3)字符串拼接操作
- 常量 与 常量 的拼接结果在 常量池,原理是 编译期 优化;常量池 中不会存在相同内容的常量
- 只要其中一个是变量,结果就在堆中
- 变量拼接的原理 是StringBuilder
- 如果拼接的结果调用 intern() 方法,则主动将常量池中 还没有的字符串对象放入池中,并返回地址
(4)String类型变量+常量
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";
String str4 = str1 + str2;
String str5 = "string";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true——常量折叠,字符串常量池中同一个
System.out.println(str4 == str5);//false——两个引用在程序编译期是无法确定的所以无法常量折叠
(1)对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。
对于 String str3 = “str” + “ing”; 编译器会给你优化成 String str3 = “string”; —— 这就是常量折叠。
只有编译器在程序编译期就可以确定值的常量才可以:
- 基本数据类型( byte、boolean、short、char、int、float、long、double)以及字符串常量。
- final 修饰的基本数据类型和
- 字符串变量字符串通过 “+”拼接得到的字符串、基本数据类型之间算数运算(加减乘除)、基本数据类型的位运算(<<、>>、>>> )
(2)引用的值在程序编译期是无法确定的,编译器无法对其进行优化。
String str4 = str1 + str2实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。
String[] arr = {"he", "llo", "world"};
String s = "";
for (int i = 0; i < arr.length; i++) {
s += arr[i];
}
System.out.println(s);
上述代码:StringBuilder 对象是在循环内部被创建的,这意味着每循环一次就会创建一个 StringBuilder 对象。
String[] arr = {"he", "llo", "world"};
StringBuilder s = new StringBuilder();
for (String value : arr) {
s.append(value);
}
System.out.println(s);
上述代码:如果直接使用 StringBuilder 对象进行字符串拼接的话,就不会存在这个问题了。
6.内部类
7.Java集合类有哪些
将一个类的定义放在里另一个类的内部,这就是内部类。
广义上我们将内部类分为四种:成员内部类、静态内部类、局部(方法)内部类、匿名内部类。
8.HashMap底层数据结构
HashMap核心知识,扰动函数、负载因子、扩容链表拆分
HashMap 的底层数据结构是哈希表(散列表),具体实现为数组+链表(JDK1.8前)或数组+链表+红黑树(JDK1.8及以后)
主要特点:
- 数组:用于存储桶(Bucket)的数组,每个桶要么存储一个元素(键值对),要么存储一个指向链表头结点的引用(哈希冲突时)
- 链表:用于解决哈希冲突,的那个多个键值对银蛇到数组的同一位置时,会形成一个链表。
- 红黑树:联保长度超过某个阈值(默认为8),链表会转换为红黑树以提高查找效率。红黑树是自平衡的二叉查找树,能保持较低的高度,从而减少查找时间。
工作流程:

9.List和Set的区别,以及底层数据结构实现
10.为什么arraylist检索快增删慢
1.检索快:
- 直接通过索引访问,因为数组内存地址联系,通过首地址+(元素长度*下标)就能计算出内存地址
- 时间复杂度低,查找的时间复杂度为O(1)
2.增删慢
- 需要移动元素,尤其是操作发生在列表开头或中间位置时,后续元素需要前移或后移,导致时间复杂度高。
- 当ArrayList容量不足时,需要扩容。扩容涉及创建新数组,然后间原数组复制到新数组中,时间复杂度O(n)且会导致内存碎片化。
3.删除的额外开销
删除元素使,还需要处理数组末尾的null元素???,以及可能的数组缩容
11.红黑树和链表的查询效率对比
BST(二叉搜索树),AVL(平衡二叉树)、RBT(红黑树)的区别
红黑树是自平衡二叉搜索树,通过一些列旋转和重新着色操作维护树的平衡性。
平衡性有一组规则来保证高度近似O(logn),每个节点要么是红要么是黑,根节点是黑色,叶子结点是黑色(NIL节点、空节点)。
因此红黑树的查询时间复杂度为O(logn)
/
链表是线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。链表中每个元素通过指针链接,不支持索引访问元素,每次查询需要从头结点开始循序遍历,查询的时间复杂度O(logn)。
12.多线程下想用hashmap怎么办
多线程下使用HashMap可能会导致数据不一致问题,因为HashMap不是线程安全的。
(1)使用Java集合提供的Collection.synchronizedMap方法,使其成为一个线程安全的Map。
每次只能有一个线程访问Map,可能个会限制并发性。
(2)ConcurrentHashMap提供更高级的并发级别。内部使用分段锁(分段加锁,减少锁的竞争),使得多个线程可以同时读写不同的数据段,从而提高性能。
(3)使用读写锁来控制对Map的访问。这种锁允许多个读操作同时进行但写操作互斥。
常见多线程的使用方式(创建线程的方式)
1.继承Thread类
继承java.lang.Thread类并重写run()方法,可以创建一个新线程。
创建该类的实例并调用start()方法来启动线程。
优点:简单直观
缺点:Java不支持多重继承,如果类已经继承了另一个类,则无法再继承Thread类
class Grape extends Thread { /**当某个类继承了Thread类后,就可以当作线程使用*/
@Override
public void run() {
}
}
public class Thread_Demo1 {
public static void main(String[] args) {
//创建线程对象
Grape grape = new Grape();
//启动线程!
grape.start();
}
}
2.实现Runnable接口
实现java.lang.Runnable接口并重写run()方法。
将任务实例传递给Thread类的构造器来创建线程对象,调用start()方法启动线程。
优点:避免java单继承的限制;线程与任务Runnable实例分离,便于任务的传递和共享。
缺点:相比继承Thread类 稍显复杂
class Fruit {}
class Apple extends Fruit implements Runnable {
@Override
public void run() {
System.out.println("线程是:" + Thread.currentThread().getName());
}
}
public class Thread_Demo2 {
public static void main(String[] args) throws InterruptedException {
Apple apple = new Apple();
//实例传递给Thread类的构造器来创建线程对象
Thread thread = new Thread(apple);
thread.start();
}
}
3.使用Callable和Future
Callable接口类似于Runable,但它可以返回一个结果并可以抛出异常。Future接口用于表示异步计算的结果。
FutureTask是Future和Runnable之间的桥梁,它实现了Runnable并封装了Callable。
优点:可以返回执行结果和抛出异常。
缺点:需要处理Future的结果,可能会阻塞调用线程。
4.使用线程池ExecutorService
线程池是一种基于池化技术的多线程管理工具,可以重用线程,减少线程创建和销毁的开销,提高系统的相应速度和吞吐量。
- 实现Callable接口,需要返回值类型
- 重写call方法,需要抛出异常
- 创建目标对象
- 创建执行服务:ExecutorService ser = Executors.newFixedThreadPool(1);
- 提交执行:Future result1 = ser.submit(t1);
- 获取结果:boolean r1 = result1.get();
- 关闭服务:ser.shutdownNow();
package Threads;
// Commons IO是针对开发IO流功能的工具类库
// FileUtils文件工具,复制url到文件
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.net.URL;
import java.util.concurrent.*;
// 线程创建方式三:实现callable接口
/*
callable的好处
1.可以定义返回值
2.可以抛出异常
*/
public class PictureDownloadCallable implements Callable<Boolean> {
private String url;//网络图片地址
private String name;//保存的文件名
public PictureDownloadCallable(String url, String name) {
this.url = url;
this.name = name;
}
//下载图片线程的执行体
public Boolean call() {
WebDownloader webDownloader = new WebDownloader();
webDownloader.downloader(url, name);
System.out.println("下载了文件名为:" + name);
return true;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
PictureDownloadCallable pd = new PictureDownloadCallable("https://pic1.zhimg.com/80/v2-674f0d37fca4fac1bd2df28a2b78e633_720w.jpg?source=1940ef5c", "图片1.jpg");
PictureDownloadCallable pd2 = new PictureDownloadCallable("https://pic1.zhimg.com/80/2886e9751c3df175ecdfc423dfe18493_720w.jpg?source=1940ef5c", "图片2.jpg");
PictureDownloadCallable pd3 = new PictureDownloadCallable("https://pic2.zhimg.com/80/4e509eaa6a6445c87af5ac335abbb090_720w.jpg?source=1940ef5c", "图片3.jpg");
//创建执行服务
ExecutorService ser = Executors.newFixedThreadPool(3);
//提交执行
Future<Boolean> r1 = ser.submit(pd);
Future<Boolean> r2 = ser.submit(pd2);
Future<Boolean> r3 = ser.submit(pd3);
//获取结果
boolean rs1 = r1.get();
boolean rs2 = r2.get();
boolean rs3 = r3.get();
//关闭服务
ser.shutdownNow();
}
//下载器
class WebDownloader {
//下载方法
public void downloader(String url, String name) {
try {
FileUtils.copyURLToFile(new URL(url), new File(name));//把url变成文件,文件名为name的值
} catch (IOException e) {
e.printStackTrace();
System.out.println("IO,异常,downloader方法出现问题");
}
}
}
}
优点:提高了资源利用率和系统相应速度;便于管理和控制线程的生命周期。
缺点L需要合理配置线程池的参数,比如线程池大小、队列类型等以避免资源耗尽或性能瓶颈。
JDK 1.8运行时数据区域:

线程私有的:【它们的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡。】
- 程序计数器
- 虚拟机栈( VM Stack)
- 本地方法栈
线程共享的:
- 堆(内含字符串常量池)
- 方法区
- 直接内存 (非运行时数据区的一部分)
堆
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。
方法区
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。在不同的虚拟机实现上,方法区的实现是不同的。
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。
方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
字符串常量池
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
直接内存
直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的,而是通过 JNI 的方式在本地内存上分配的。
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
虚拟机对象创建
1.类加载检查
- 虚拟机遇到一条 new 指令时,首先去检查指令的参数是否能在常量池中定位到这符号引用,并且检查引用代表的类是否被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
2.分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。
对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。
分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择哪种分配方式由 Java 堆是否规整决定。
内存分配的两种方式 (补充内容,需要掌握):
- 指针碰撞:
- 适用场合:堆内存规整(即没有内存碎片)的情况下。
- 原理:用过的内存全部整合到一边,没有用过的内存放在另一边,中间有一个分界指针,只需要向着没用过的内存方向将该指针移动对象内存大小位置即可。
- 使用该分配方式的 GC 收集器:Serial, ParNew
- 空闲列表:
- 适用场合:堆内存不规整的情况下。
- 原理:虚拟机会维护一个列表,该列表中会记录哪些内存块是可用的,在分配的时候,找一块儿足够大的内存块儿来划分给对象实例,最后更新列表记录。
- 使用该分配方式的 GC 收集器:CMS
内存分配并发问题(补充内容,需要掌握)
在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
. CAS+失败重试: CAS 是如果冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
. TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
3.初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
4.设置对象头
将这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
5.执行 init 方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始, 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 <init> 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 引用数据来操作堆上的具体对象。
对象的访问方式由虚拟机实现而定,目前主流的访问方式有:使用句柄、直接指针。
直接指针:
reference中存储的直接就是对象地址

原文地址:https://blog.csdn.net/weixin_44040169/article/details/140063505
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!