如何从头训练大语言模型: A simple technical report
知乎:涮月亮的谪仙人(已授权)
链接:https://zhuanlan.zhihu.com/p/906819356
写在前面
自8月底训好自己的1.5B的LLM后,一直都没有发布一个完整的技术报告,不少小伙伴私信我催更,千呼万唤始出来。其实也没有太大动力去做,原因有三:
豁然开朗:搞定全流程之后,对LLM确实豁然开朗不少,不过,发现要学的新东西更多了....尤其是这三个月,qwen, meta, anthropic等等发布的好文章实在太多了,真不想落下,没时间"反刍"当年的剩饭。
Reasoning兴趣:对reasoning更感兴趣了(其实训1.5B模型的初衷,就是为了给将来从pretrain开始做reason的增强打基础)。
保研季忙碌:9月保研季,保研的事情忙的焦头烂额,各种预推免与考核....还好现在终于有书读了!
今天来快速捋一下路线,写个简短的technical report,更多是原理介绍性的。按我个人理解,从最简单的部分开始,逐步过渡到最繁复的环节:模型架构-> Pretrain -> Post-Train -> Infra -> 数据侧。再掺杂一些杂项,比如工具调用,agent, 推理解码,长文本。
大模型时代,倒不是看谁代码写的好了,只有涉猎广泛,有训练经验,能进行Infra的debug,肯认真做数据,才是王道。所以我觉得眼下最有价值的文章,还得看大厂技术报告。
1. Model Architecture
分两块讲:语言模型本身和对应的tokenizer构建。这部分没什么好说的,比较简单,大家都差不多。
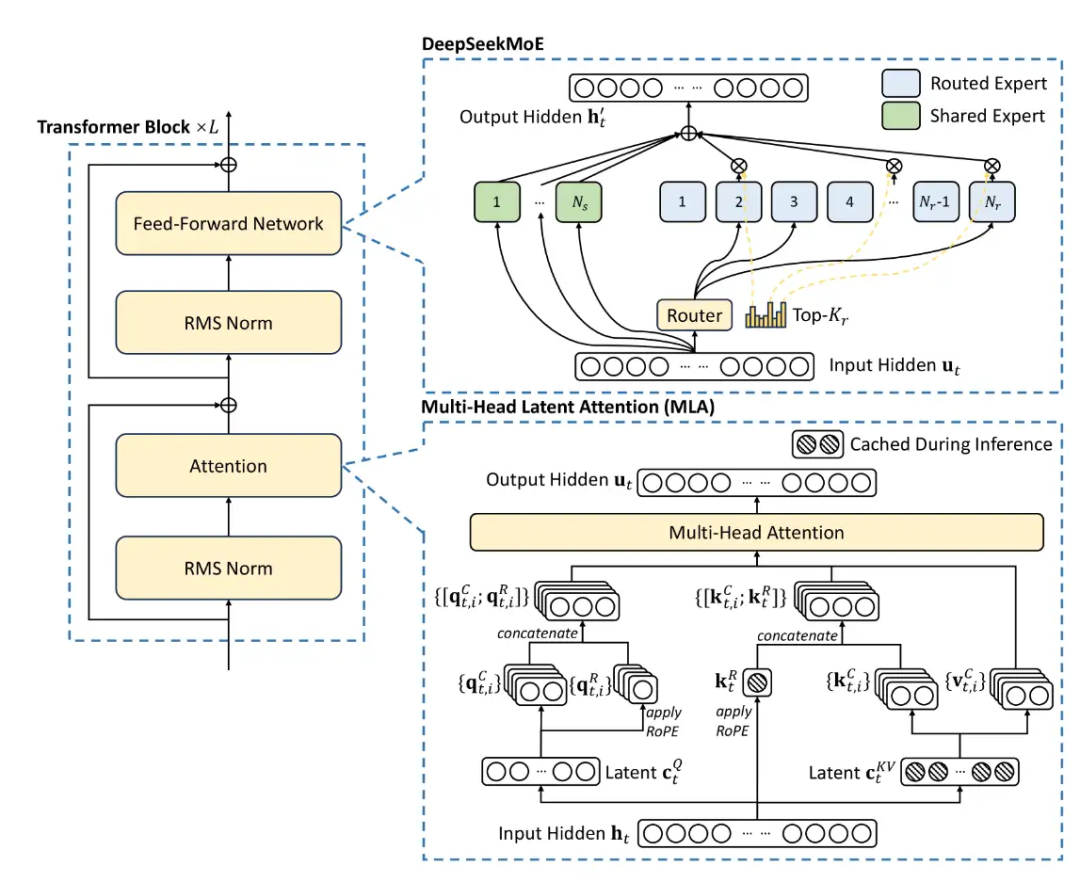
基本都是llama的魔改,不过今年大家更关注inference消耗和长文本了,所以出现了各种各样的变体。其中Deepseek的MLA架构一枝独秀。不过我不想讨论MoE。
与图像生成模型还在忙着争论模型架构不同,主流自回归LLM基本都是casual attention,只是各家对MHA做了优化而已,目的是为了尽可能减少kv cache, 从而在更少的显存消耗上做到更快的推理速度,降本增效。
1.1 MQA->GQA->MLA
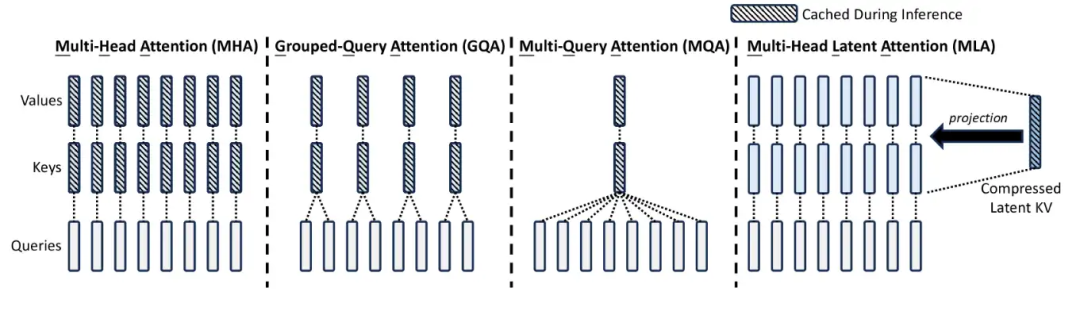
MQA:把多头注意力里的多个attention head去对应一个K与V,非常朴素的想法,是kv cache节约的上界。过于暴力,今年应该没人用了。
GQA:介于MHA与MQA之间,把attention head分成多个group, 组内共享KV,十分自然的过渡。
MLA:只需要少量的 KV 缓存,相当于只有 2.25 组的 GQA,但却能获得比 MHA 更强的性能。不过没法直接使用ROPE倒是一个弊病,需要做一些改动。虽然MLA会增加一些计算,但是推理速度无疑是很快的。
1.2 Norm, Activation, Initialization
现在主流共识是用RMSNorm和SwiGLU, 比layernorm和relu两个老东西效果好多了,训练也更稳定。(不过GLM是用的GeLU和deepnorm)
为了保证训练稳定(实在太难了),一般采用预归一化,先归一化,再残差计算。据说post-norm效果更好,但不够稳定。
参数初始化策略看模型大小而定。某些策略似乎能缓解loss spike现象,可见Spike No More: Stabilizing the Pre-training of Large Language Models
https://arxiv.org/pdf/2312.16903
1.3 Long Context
今年大家都卷起来了,似乎没有1M窗口都不好意思发布模型,“大海捞针”实验上kimi还是一枝独秀。
位置编码都是ROPE, 不少工作都在探究ROPE怎么做外推/内插。此前基本就是PI和NTK。后续训练中也有逐步增大ROPE基频的.
qwen报告里使用了Dual Chunk Attention(DCA),这是training free的;后面用yarn调整注意力权重做外推.
1.4 Tokenizer与词表
不少工作都是直接挪用的别人的tokenizer, 如果自己从头训,好处可能是在自己数据上有更高的压缩率(词表大小相同的情况下)。主流算法都是BPE或者BBPE比较多。实际训练上主要是工程优化并发的问题。
记得评估一下tokenizer的压缩率。压缩率表示文本向量化后的长度,压缩率越高向量越短。多语言的时候也留意一下token的覆盖率,比如llama的中文就不太行,他们的训练数据本身中文就很少 (不知道为什么meta这么做,反而support一些其他的语言比较多)
一个非常重要的问题就是词表的修改。尤其是SFT阶段有些special token, 做agent的时候更重要了,最好不要等模型训起来了再去补词表,否则norm的时候会乱掉,调整起来多少有些麻烦。当然,有些人也有词表剪枝的需求,去掉冗余的token,比如只要英文,这样可以大大减少参数量。
词表的大小也很重要,词表越大,也会导致Loss越大。有些文章在探讨vocal size的scaling law,很有意思:Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies (arxiv.org)。数据瓶颈就减小词表,够的话自然上大词表,vocab size经验一般是64的倍数。
https://arxiv.org/abs/2407.13623v1
2. SFT
倒反天罡,先讲SFT而不是pretrain。这只是因为工程上SFT更好做而已,先拿来讲了。
实际上,SFT也有自己的麻烦之处,不比pretrain简单。LLM其实每个部分都不容易,各有各的难处罢了。
本质上也是做next token prediction loss, 和预训练大量文本的直接学习不同,由于 SFT阶段文本都是prompt起手,故而会加一个mask,只在prompt后面的部分学习Loss.
2.1 SFT阶段的基本特点:
很多词表里的special token开始发挥作用了,比如有些用来标识user, assistant之类
指令微调数据不定长。而pretrain的时候一般都是padding再pack到定长的,比如4K, 后面可能还会长文本富集一下,逐步提升到16K,32K的训练
SFT主要目的是为了让模型学会新的format,无法在此阶段引入新的知识,哪怕是大量finetune,世界知识还是在吃pretrain的老本。千万不要拿SFT学新知识! 老老实实CPT吧
和pretrain完模型只会续写不同,SFT模型需要学会在eos停下来,并且follow instruction
Agent的Function call也是一种special token, 工具调用也是一个挺热门的研究方向
训练的时候SFT的lr很小。相比pretrain一般1e-4到5e-4的量级,sft可能只有1e-5到5e-5
别忘了SFT的时候也塞一些pretrain数据保持一下。
其实做SFT的时候最多的时间还是花在数据上......数据评估,配比,多阶段课程学习超超超超级重要!
2.2 SFT数据
SFT相比pretrain数据量很小,不过指令跟随能力习得完全靠这部分,所以需要更细粒度的调优把控,尤其是数据。我印象里做SFT的时候几乎100%的时间全砸在数据上了。
Quality is all your need, 应该是今年所有人的共识。数据的diversity和quality的评估一定要做好,数据量倒不是很多。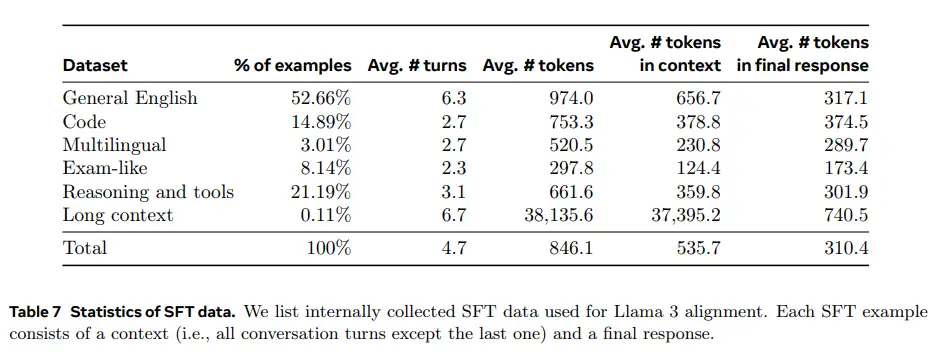
2.2.3 Diversity
多样性的话一定要保证format形式多,指令涵盖的domain广,高质量数学代码数据倒是越多越好。
打标签:一般借助强模型对文本进行label,看看Instag那篇文章[2308.07074] #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models (arxiv.org), 构造一棵多级标签树,然后由此控制数据配比。
关于Repeat: 有些难样本是需要repeat多个epoch的,不过具体该多少epoch好像没有统一说法,一般是暴力跑实验测出来的...或者拍脑袋想个数(bushi)。如果要repeat, 最好还是用另一个强模型把问题重写一下再塞回去训,能多diversity就尽量去做吧,反正不亏。
短数据和长数据都很重要,超级长数据也很重要,主打就是一个错落有致。
多轮对话的时候,有些数据得一直保持某topic, 有些也得中途切换topic, 这种diversity也很重要
千言万语一句话:数据形式要百花齐放,prompt里重要信息分布要足够杂乱,不要给模型机会找到规律。
2.2.4 Quality
数据质量评估就见仁见智了,之前有用IFD测指令跟随分数的,不过好像不是总能work, 某些人看上去很hard的任务IFD分反而不高,真是奇怪呢...借助强模型打分也是一个思路,比如delta,需要trade-off一下成本
或者各种质量评估方案全部集成进来(bushi)
如何处理低质量数据:看到有不少prompt自动进化的文章,可以一试。Reject sampling也可以提升一下
数据合成这里不展开,那得另写一篇长长的文章了。
2.3 SFT训练
你跟我讲LoRA? 我只能嘿嘿一笑。这里只讨论全量微调。
有人倾向于SFT开始时 不用warmup。我还是习惯0.25%warmup起手
lr上面说过了,比较小,1e-5量级,最后衰减为初始的10%,与pretrain一致
记得记录不同domain的loss变化,可以给下一阶段数据配比调整做准备。预训练末期的loss一般已经降到1.7左右,但是SFT不同domain的Loss差别很大,我观察到SFT末期不同domain是0.5到3的loss之间都有
如果认真做了数据,效果还不好----要么是pretrain知识没学够,要么是special token检查一下
Qwen组的DMT给了一个大致的数据配比方案,二阶段微调。模型最后见到的数据非常重要!直接影响用户体验。所以stage1进行一些数学代码这种特殊任务的提升,stage2进行更general的数据训练,看上去泛化性更好。要是倒过来,模型的输出可能就比较贴近特殊domain了(想刷榜math/code的反着来就行)。不过,还是得记得joint train, stage2也要混合stage1甚至pretrain数据,保持一定的前阶段能力
SFT还真没见过pretrain的loss spike现象,总体上比较稳定。不过单看各domain的loss曲线似乎不是很稳定....最麻烦的是就是过拟合,实在不好把握这个度。
华为有篇文章论证,小模型的SFT epoch可以多跑几次效果会好,大模型复杂度高可能更容易过拟合。可能是我从pretrain过来的惯性,还是很难接受两轮以上的training,所以我只把SFT epoch设为2
建议做sft的同学一定要自己看一下数据,做到心里有数;我手动看了百来条后,确实获得了不一样的理解
所以SFT微调链路的交付哥,一天的生活是这样的:每天早上开十几个job, 只改动一点点参数,然后苦等一天,期间做做数据,晚上收割一波模型,跑测评看结果.....
最后各domain的效果一定是有好有坏的,后续可以用DPO偏好数据去定向提升。
复杂指令是另一个很有意思的话题,可以看我知乎号此前发布的另一篇推理增强的文章。先写到这里,更详细的细节以后再来丰富吧
3. Pretrain
LLM训练的大Boss: Pretrain。
请认真读一下MiniCPM:2404.06395 (arxiv.org),以及openai的2001.08361 (arxiv.org)。会有很大收获的
https://arxiv.org/pdf/2404.06395
https://arxiv.org/pdf/2001.08361
 7月份我和洪神在飞书整理了一下scaling law,偷懒,直接截屏放上来了
7月份我和洪神在飞书整理了一下scaling law,偷懒,直接截屏放上来了
3.1 基本训练setting
优化器AdamW,weight decay 0.1, (看情况用ZeRO1/2),余弦退火,warmup
Batch: GPT3是32K过渡到3M,动态增大batch。较小的批次对应反向传播的频率更高,训练早期可以使用少量的数据让模型的损失尽快下降;而较大的批次可以在后期让模型的损失下降地更加稳定,使模型更好地收敛。这里也有一些finding optimal batch的方法Scaling Laws for Neural Language Models ,[1812.06162] An Empirical Model of Large-Batch Training (arxiv.org)。不过需要借助scaling law来预测batch,可惜我没做这个实验。我的方案是取让集群tgs(tokens/gpu/second)数最高的batch,毕竟对我来说,最大的瓶颈是集群算力
https://arxiv.org/pdf/2001.08361
https://arxiv.org/abs/1812.06162
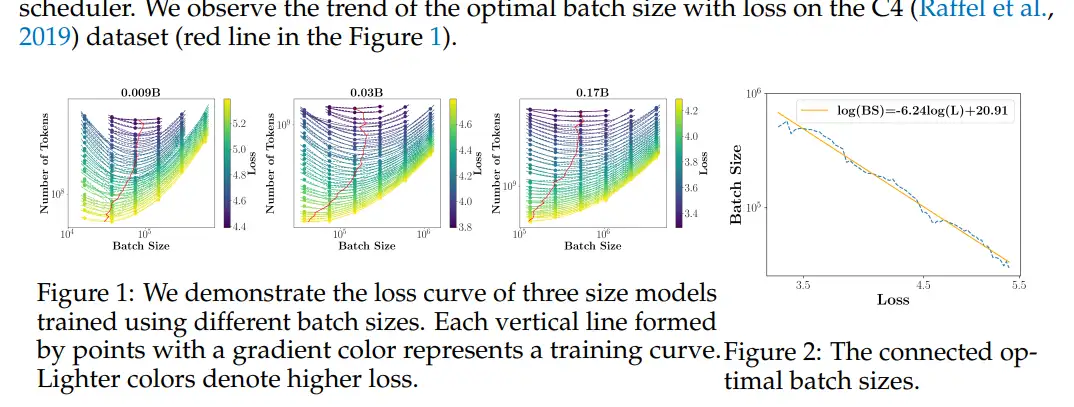 minicpm: optimal batch size
minicpm: optimal batch size from scaling law
from scaling law
scaling law: 建议openai, chinchllia,deepmind那三篇scaling law都要读一下,看完会有不一样的收获。由数据量,算力,大致能估算一个模型大小出来(就是需要很多实验才能测出来...给出的值也是非常不精确的,做到心里有数即可
开源框架还是用megatron和deepspeed吧,各大公司内部肯定都有自己的infra代码,我也不好讲。记得flash-attn开起来。
lr很重要!玄学的地方。BF16训练稳定是个共识。gradient clip一般1.0。似乎回归任务都不太适合dropout。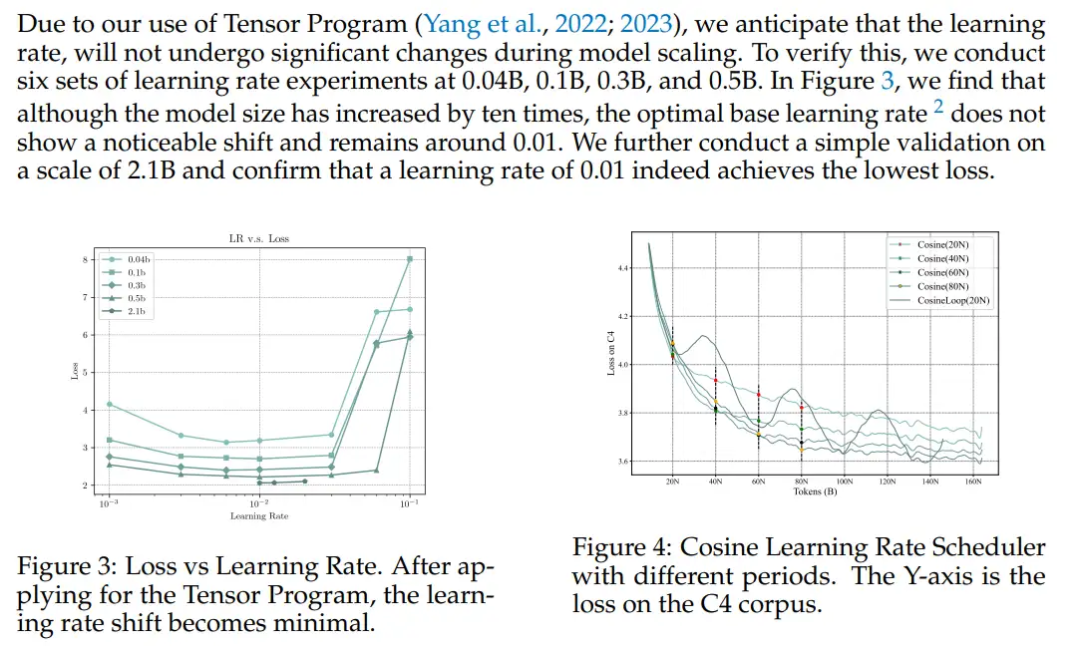 minicpm: lr
minicpm: lr 人大aibox收集的图
人大aibox收集的图
3.2 先讲一下Evaluation
pretrain测评最简单就是看ppl。有一些测评也能看多任务的续写能力。pretrain的评估是不好做的,大部分时间只看看着loss曲线,吹胡子瞪眼。
大模型:你猜我拟合的怎么样了,task_A是升了还是task_B是降了,升了一定不好吗,降了也不一定好。有的人升了,是为了别人将来更好地降;有的人陡降了,是为了别人loss疯狂飙升,是吧 loss spike。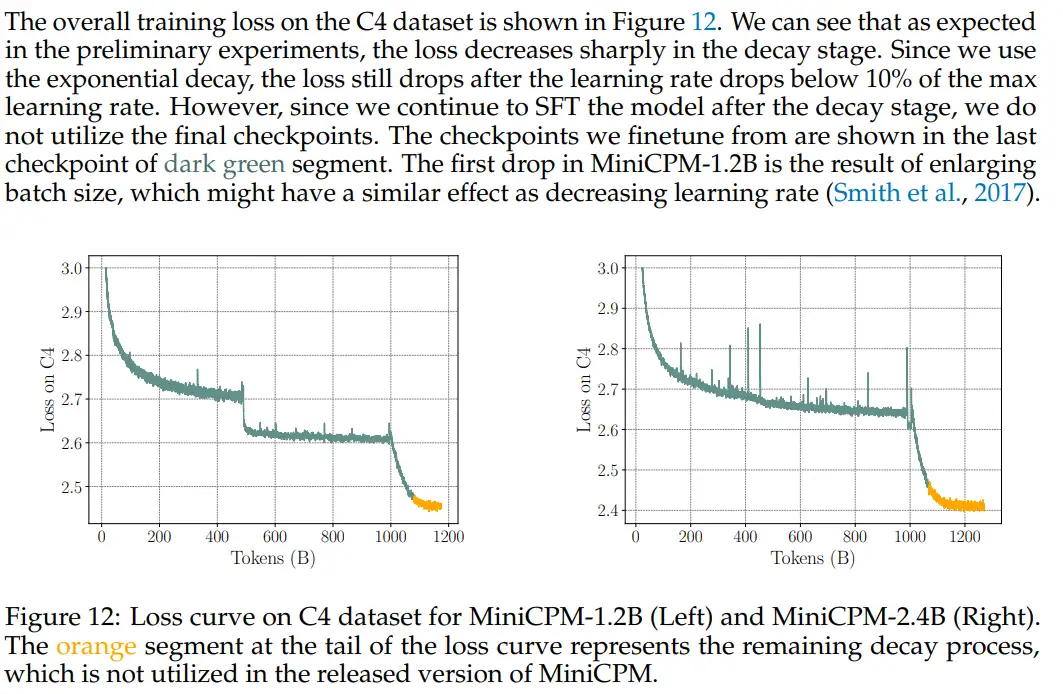 loss
loss
评估是眼下最难做的东西,好像卷的人也不多。
其实,个人感觉,评估比pretrain,sft要难做...可以这么想,作为本科生,我都能跑pretrain了,那大模型训练门槛确实已经低到了一定程度。无非就是数据清洗合成过滤,各种配比和课程学习,学习率优化器,数据质量与多样性,分布式跑通,但是要做评测,真会遇到各种各样的问题。
数据配比怎么调?scaling law怎么算?课程学习几个阶段,该怎么粗粒度调优?这都是经验性和实验性的东西,甚至有时,一拍脑袋确定的数,都比一通可解释性理论推导得到的数,效果更好。这个trick加不加,都是看评估结果。但是至今没什么高效全面的评估,一般都是下面这样:
跑benchmark
用强模型来评估,比如gpt4,不过不稳定
当然,用人来评估也是可行的方案,效果肯定最好。把实习生人数scale上去,是最有效的scaling law,有多少人工,就有多少智能。
看榜单benchmark也就图一乐,还是chatbot arena靠谱点。大家多多少少都会把benchmark拿过去拟合一下用。GSM8K已经被卷烂了(我感觉弱智吧都有过拟合的表现),与其信某些模型的性能,不如信我是秦始皇。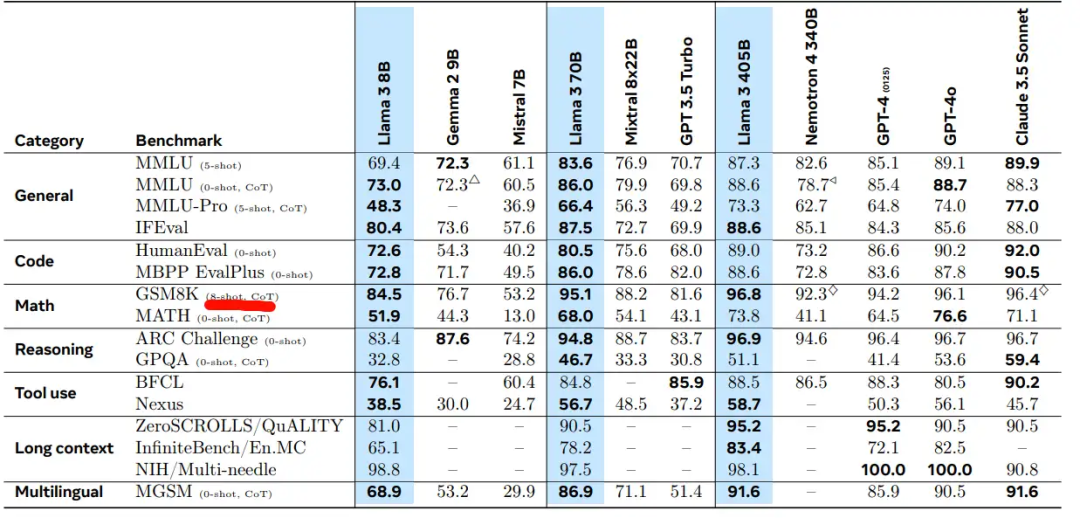 llama 3.1诡计多端的8-shot
llama 3.1诡计多端的8-shot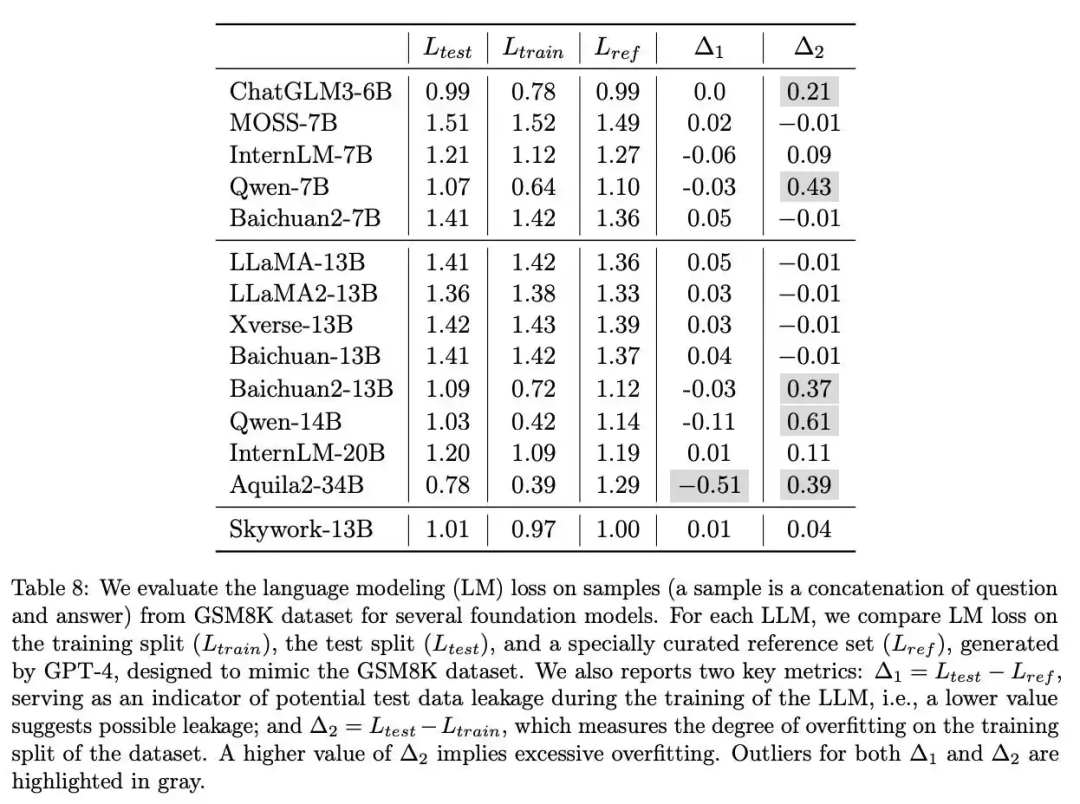 天工的报告:各大厂商overfit现象
天工的报告:各大厂商overfit现象
谁掌握了评估,谁就掌握了未来。
3.3 预训练数据处理
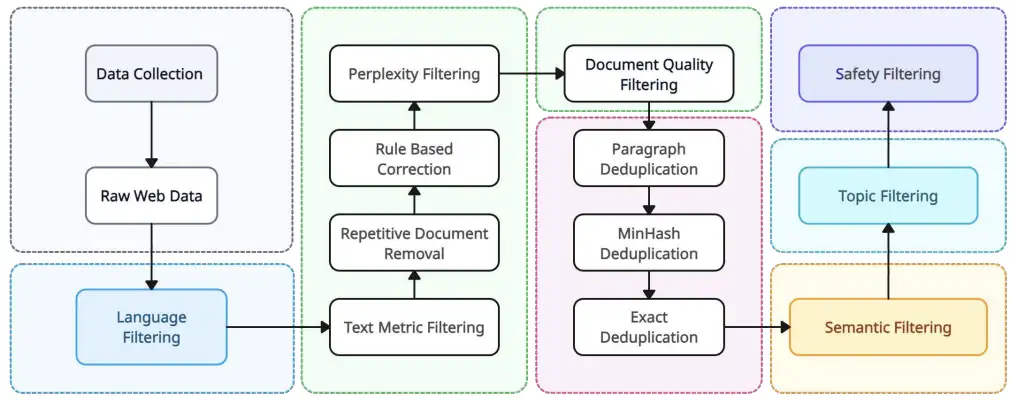 零一万物数据pipeline,一图胜千言
零一万物数据pipeline,一图胜千言
基于规则的过滤非常有用,老老实实编造各种各样的规则,带来的效益是稳定的
不知道为什么llama3的report里用llama2来做主题分类器,实际上训类Bert模型效果会更好。最后,也不能迷信分类结果,粗粒度看一下即可,本来就不是很准的东西,不要纠结于分类器准确率,有总比没有好
去重很重要。不过什么粒度的去重,还是看场景和成本。
多语言用fastext检测分类。(不过中译英这种问题,到底是归类到中文好,还是英文好?
代码和数学的数据pipeline参考deepseek
Textbook is all your need
数据合成:Cosmopedia: how to create large-scale synthetic data for pre-training Large Language Models (huggingface.co)
https://huggingface.co/blog/cosmopedia
(其实我的数据侧偷了很多懒,今年开源了不少质量不错的预训练数据集,比如huggingface的fineweb。天工的skypile,以及一个很大的Redpajama等等,集合起来做一些过滤,去重,分类即可)
3.4 数据配比
还是scaling law贯穿始终 llama3: 大家的配比和这个都差不多,不过这里的推理数据量确实占比有点高了
llama3: 大家的配比和这个都差不多,不过这里的推理数据量确实占比有点高了
D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models
https://arxiv.org/abs/2406.01375
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
https://arxiv.org/abs/2305.10429
具体multi-stage的设计就见仁见智了,每个阶段都是动态的重调配比。长文本和推理数据要稍微靠后一点再加入
末期一定是高质量数据!
所以不少文章都是利用退火来评估末期数据质量,然后选择性加入
3.5 训练前准备
按照scaling law估算一下吧。首先统计预测一下tokens数,大概能用多少卡多少天的算力,来推算需要多大模型,总共要多少step
3.5.1 模型参数计算:
Here’s the text from the image you provided, formatted in Markdown:
3.5.1 模型参数计算:
假设词表大小 ( V ),模型层 ( L ),中间状态维度 ( H ),FFN维度 ( H' ),以 Llama 为例:
(其实这个 MLP ratio 也挺有讲究的,Llama 好像是取得 8/3,我暴力穷举在 8/3 附近搜索,测得 tflo ps 数最高时应该是 2.6875,和 deepseek 保持一致)
embedding 层参数量:( VH )
MHA:( KQV ) 每个变换矩阵都是 ( H^2 ),还需要一个 MLP 来拼接输出,所以一共 ( 4H^2 )
FFN:三个线性变换,一共 ( 3HH' )
Norm:MHA 和 FFN 输出需要 RMSnorm(post-norm,故而是 ( 2H )),最后模型输出还有一个 norm 需要 ( H )
输出层:线性变换需要 ( VH )
所以一共是:参数量 ( N = 2VH + H + L(4H^2 + 3HH' + 2H) )
例如:
( V = 32000 ),
( H = 32 ),
( H' = 4096 ),
( L = 11008 ) 的 Llama 7B 参数量计算是 6738415616,和实际吻合。
3.5.2 运算量计算
假设模型参数 量N,batchsize为B,输入seq_len为T,那么训练的总词元数是C=BT
简单的估算是运算量=6CN(如果没用Gradient checkpointing)用了多一次forward,修正为8CN 来自ruc aibox gradient checkpointing介绍
来自ruc aibox gradient checkpointing介绍
以 LLaMA (7B) 的训练为例介绍运算总量的计算方法。其参数量 N ≈ 6.74×10^9。这里假设训练数据的词元总数均为 = 1×10^9,不使用激活重计算技术, 那么 LLaMA (7B) 的训练过程中浮点运算总量为 6 × 6.74 × 10^9 × 10^9 ≈ 4.04 × 10^19
3.5.3 训练时间估计
运算量数每秒浮点运算数
以 LLaMA (65B) 的预训练为例,其参数量 N = 6.5 × 10^10,词元数 = 1.4 × 10^12,由于采用了激活重计算技术, 其运算量大致为 8 = 7.28 × 10^23。它在预训练过程中使用了 2,048 张 A100 GPU, 而每张 A100 GPU 每秒最多能进行 3.12 × 10^14 次 BF16 浮点数运算。我们假设在训练过程中,每张 GPU 能达到每秒 2 × 10^14 次 BF16 浮点数运算的实际性能。
可以计算出 LLaMA (65B) 使用 2,048 张 A100 GPU 在 1.4T 个词元上 的训练时间大致为 1.78 × 10^6 秒,即大约为 20.6 天。这个估算结果与论文中公布的 21 天基本一致。
3.5.4 显存估计
老生常谈的话题。
模型参数和梯度用16位存储,AdamW额外存32位模型参数,动量,动量二阶矩,
设模型参数量P,数据并行数D,流水线并行P,张量并行T,GPU数G,
单卡存储模型参数和优化器显存开销:
不用ZeRO: 16P字节显存
ZeRO1: 4P+12P/D字节
ZeRO2: 2P+14P/D
如果用来tp,pp,那么全都除以PT即可得单卡开销
激活值显存:看模型架构,开不开flash-attn,有没有用激活值重计算,具体不再阐述,会算就行,慢慢分析即可
4. Post train
前面已经写了SFT,但我不会RLHF,(摊手,坦诚.jpg)。只会step-DPO调一下,其实DPO我也训不好,欸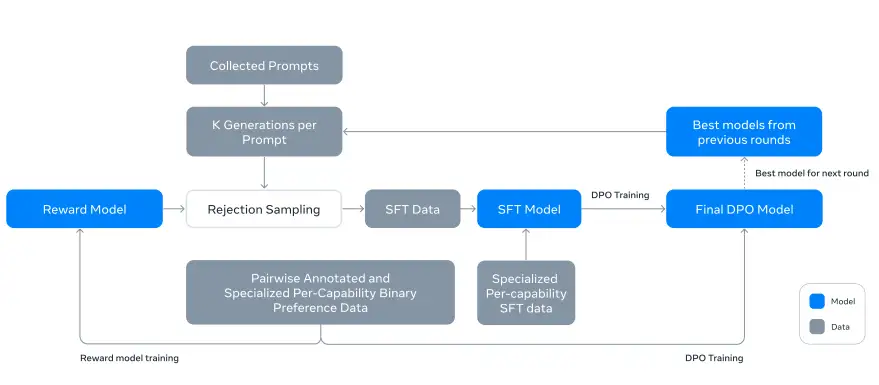 post-training pipeline
post-training pipeline
今年以及未来很长一段时间的主流都会是Post-Training,实在太重要了,尤其是o1出来之后。大家都热情高涨。虽然真要应用MCTS的下游任务也不是很多,但是着实有趣,大模型推理是一定要拿下的一座山峰。
代码,数学,多轮对话,安全价值观各有各的细节。这里放一个llama 3推理部分的处理,机翻,摆烂了
我们将推理定义为执行多步计算并得出正确最终答案的能力。指导我们训练在数学推理方面表现优异的模型时,存在以下挑战:
缺乏提示:随着问题的复杂性增加,用于监督微调(SFT)的有效提示或问题的数量减少。这种稀缺性使得创建多样化和代表性的训练数据集以教授模型各种数学技能变得困难。
缺乏真实值推理链:有效的推理需要一步一步的解决方案来促进推理过程。然而,通常缺乏真实值推理链,这些推理链对于指导模型如何一步一步地分解问题并得出最终答案至关重要。
中间步骤不正确:当使用模型生成的推理链时,中间步骤可能不总是正确的。这种不准确性可能导致最终答案不正确,需要解决。
教授模型使用外部工具:增强模型使用外部工具,如代码解释器,允许它们通过交替代码和文本来推理。这种能力可以显著提高它们的问题解决能力。
训练与推理之间的差异:模型在训练期间微调的方式与在推理期间使用的方式之间往往存在差异。在推理期间,微调后的模型可能会与人类或其他模型互动,需要它通过反馈来改进其推理能力。确保训练和现实世界使用之间的一致性对于保持推理性能至关重要。
为了解决这些挑战,我们应用以下方法论:
解决缺乏提示的问题:我们从数学上下文中获取相关预训练数据,并将它转换成一种问题-答案格式,然后用于监督微调。此外,我们识别出模型表现不佳的数学技能,并积极从人类那里获取提示/问题来教授模型这些技能。为了促进这一过程,我们创建了一个数学技能分类,并让人类根据相应的问题/问题提供相关提示。
增加逐步推理轨迹的训练数据:我们使用Llama 3为一系列提示生成一步一步的解决方案。对于每个提示,模型产生一个变数数量的生成。这些生成根据正确答案进行筛选。我们还在自我验证中使用Llama 3,它用于验证对于给定的问题,是否有一个一步一步的解决方案是有效的。这个过程通过消除模型不产生有效推理轨迹的实例,提高了微调数据的质量。
过滤不正确的推理轨迹:我们训练了结果和逐步奖励模型来过滤中间推理步骤不正确的训练数据。这些奖励模型用于消除数据中的无效一步一步的推理,确保微调的高质量数据。对于更复杂的提示,我们使用蒙特卡洛树搜索(MCTS)与学习到的逐步奖励模型来生成有效的推理轨迹,进一步提高了高质量推理数据的收集。
交替代码和文本推理:我们提示Llama 3通过结合文本推理和相关的Python代码来解决推理问题。代码执行用作消除推理链无效情况的反馈信号,确保推理过程的正确性。
从反馈和错误中学习:为了模拟人类反馈,我们利用了错误生成(即导致推理轨迹不正确的生成)并进行了错误校正,通过提示Llama 3来产生正确的生成。错误尝试和校正迭代过程的反馈使用,帮助提高了模型准确推理和从错误中学习的能力。
RLHF一定是非常重要的,SFT后RL一下往往能涨点。其实pretrain和sft都只是在正确的token上进行拟合,模型只知道什么是正确的输出,不知道什么是错误的,缺乏负反馈带来的多元信号。而RLHF在告诉你什么是正确的同时,也告诉了你错误的雷区在哪里,(不过RL完,错误的token是不是概率也增大了,毕竟出现频次比之前高了
Post train,RLHF这块,后面我会单独起一章详细写的,不像本文这样的行文匆匆,充满了草率的味道。我对这块非常感兴趣!欢迎小伙伴们一起交流呀!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
原文地址:https://blog.csdn.net/qq_27590277/article/details/142968577
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!