14. 文档对象模型
打开网页时,浏览器会检索网页的 HTML 文本并对其进行解析,就像第 12 章中的解析器解析程序一样。浏览器会建立一个文档结构模型,并使用该模型在屏幕上绘制页面。这种文档表示法是 JavaScript 程序在沙盒中的玩具之一。它是一种可以读取或修改的数据结构。它就像一个实时数据结构:当它被修改时,屏幕上的页面也会随之更新以反映变化。
文件结构
你可以把 HTML 文档想象成一组嵌套的方框。<body>和</body>等标签包含其他标签,而这些标签又包含其他标签或文本。下面是上一章的示例文档:
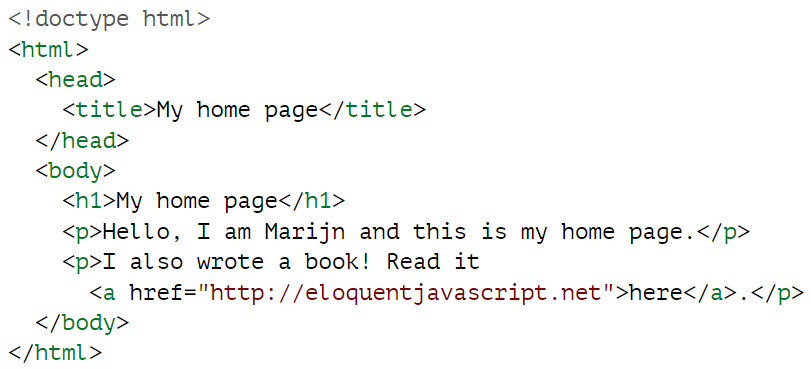
该页面的结构如下:

浏览器用来表示文档的数据结构就是这种形状。每个方框都有一个对象,我们可以通过与该对象交互来了解它所代表的 HTML 标记以及它包含的方框和文本。这种表示方法称为文档对象模型,简称 DOM。
通过全局绑定文档,我们可以访问这些对象。它的 documentElement 属性指的是代表 <html> 标记的对象。由于每个 HTML 文档都有 head 和 body,因此它也有指向这些元素的 head 和 body 属性。
树
回想一下第 12 章中的语法树。它们的结构与浏览器文档的结构极为相似。每个节点都可以指向其他节点(子节点),而子节点又可以有自己的子节点。这种形状是典型的嵌套结构,其中的元素可以包含与自身相似的子元素。
当数据结构具有分支结构、无循环(节点不得直接或间接包含自身)和单一、定义明确的根时,我们就称其为树。在 DOM 中,document.documentElement 就是根节点。树在计算机科学中经常出现。除了表示 HTML 文档或程序等递归结构外,树还经常用于维护分类数据集,因为在树中查找或插入元素通常比在平面数组中更有效率。
典型的树状结构有不同类型的节点。Egg 语言的语法树有标识符、值和应用节点。应用程序节点可能有子节点,而标识符和值是叶子,或者说是没有子节点的节点。DOM 也是如此。代表 HTML 标记的元素节点决定了文档的结构。这些节点可以有子节点。document.body 就是这样一个节点。其中一些子节点可以是叶子节点,如文本片段或注释节点。
每个 DOM 节点对象都有一个 nodeType 属性,其中包含一个标识节点类型的代码(数字)。元素的代码为 1,也定义为常量属性 Node.ELEMENT_NODE。文本节点代表文档中的一段文本,代码为 3(Node.TEXT_NODE)。注释的代码为 8(Node.COMMENT_NODE)。
另一种可视化文档树的方法如下:
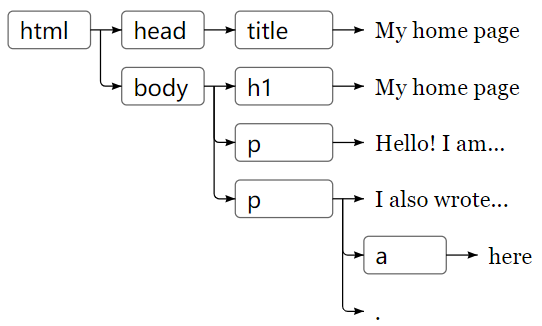
叶子是文本节点,箭头表示节点之间的父子关系。
标准
使用隐晦的数字代码来表示节点类型并不像 JavaScript 所做的那样。在本章后面的内容中,我们将看到 DOM 界面的其他部分也让人感觉繁琐和陌生。这是因为 DOM 界面并不只是为 JavaScript 设计的。相反,它试图成为一个语言中立的界面,可以在其他系统中使用,不仅适用于 HTML,也适用于 XML,后者是一种具有类似 HTML 语法的通用数据格式。这是令人遗憾的。标准往往是有用的。但在这种情况下,其优势(跨语言一致性)并不那么引人注目。与跨语言的熟悉界面相比,拥有一个与你正在使用的语言适当整合的界面会为你节省更多的时间。以 DOM 中元素节点所具有的 childNodes 属性为例,就可以说明这种整合不佳的情况。该属性包含一个类似数组的对象,具有长度属性和用数字标注的属性,用于访问子节点。但它是 NodeList 类型的一个实例,而不是一个真正的数组,因此它没有 slice 和 map 等方法。
还有一些问题是由于设计不当造成的。例如,创建一个新节点后,无法立即为其添加子节点或属性。相反,您必须首先创建它,然后使用副作用逐个添加子节点和属性。与 DOM 进行大量交互的代码往往会变得冗长、重复和难看。但这些缺陷并不是致命的。由于 JavaScript 允许我们创建自己的抽象,因此可以设计出更好的方法来表达我们正在执行的操作。许多用于浏览器编程的库都带有这样的工具。
在树上移动
DOM 节点包含大量指向附近其他节点的链接。下图对此进行了说明:

虽然图中只显示了每种类型的一个链接,但每个节点都有一个 parentNode 属性,指向它所属的节点(如果有的话)。同样,每个元素节点(节点类型 1)都有一个子节点(childNodes)属性,指向一个包含其子节点的数组对象。
理论上,只需使用这些父节点和子节点链接,你就可以在树中任意移动。但 JavaScript 还提供了一些额外的便利链接。firstChild 和 lastChild 属性指向第一个和最后一个子元素,如果节点没有子元素,则其值为空。同样,previousSibling 和 nextSibling 属性指向相邻节点,即在节点本身之前或之后出现的具有相同父节点的节点。对于第一个子节点,previousSibling 的值为空,而对于最后一个子节点,nextSibling 的值为空。
还有一个 children 属性,它与 childNodes 类似,但只包含元素(类型 1)的子节点,不包含其他类型的子节点。当你对文本节点不感兴趣时,这可能会很有用。
在处理像这样的嵌套数据结构时,递归函数通常很有用。下面的函数会扫描文档,查找包含给定字符串的文本节点,找到后返回 true:

文本节点的 nodeValue 属性包含它所代表的文本字符串。
查找元素
在父节点、子节点和同级节点之间浏览这些链接通常很有用。但是,如果我们想找到文档中的一个特定节点,那么从 document.body 开始并沿着固定的属性路径找到它就不是一个好主意了。这样做会在我们的程序中加入对文档精确结构的假设--而这种结构可能是你以后想要改变的。另一个复杂因素是,即使在节点之间的空白处也会创建文本节点。示例文档的 <body> 标记不仅有三个子节点(<h1> 和两个 <p> 元素),而且有七个:这三个子节点,加上它们之前、之后和之间的空格。
如果我们想获取该文档中链接的 href 属性,就不能说 “获取文档 body 第六个子元素的第二个子元素 ”这样的话。如果我们能说 “获取文档中的第一个链接 ”就更好了。我们可以这样做。

所有元素节点都有一个 getElementsByTagName 方法,该方法会收集所有带有给定标记名的元素,这些元素都是该节点的后代(直接或间接子节点),并以数组对象的形式返回。
要查找特定的单个节点,可以给它一个 id 属性,然后使用 document.getElementById 代替。

第三个类似的方法是 getElementsByClassName,与 getElementsByTagName 一样,它也是通过搜索元素节点的内容,检索所有在其 class 属性中包含给定字符串的元素。
改变文档
DOM 数据结构的几乎所有内容都可以更改。文档树的形状可以通过改变父子关系来修改。节点有一个 remove 方法,可以将节点从当前父节点中移除。要为元素节点添加子节点,我们可以使用 appendChild(将其放在子节点列表的末尾)或 insertBefore(将作为第一个参数的节点插入到作为第二个参数的节点之前)。
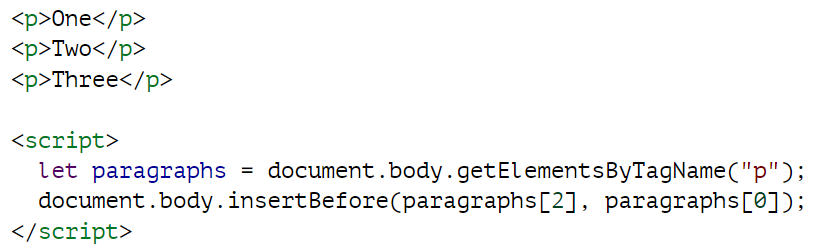
一个节点在文档中只能存在于一个位置。因此,在段落一前面插入段落三,将首先从文档末尾移除该段落,然后在段落一前面插入该段落,结果是三/一/二。所有在某处插入节点的操作都会产生副作用,导致节点从其当前位置(如果有的话)移除。
replaceChild 方法用于用另一个节点替换一个子节点。它需要两个节点作为参数:一个新节点和要替换的节点。被替换的节点必须是调用该方法的元素的子节点。请注意,replaceChild 和 insertBefore 方法的第一个参数都是新节点。
创建节点
假设我们要编写一个脚本,用图片 alt 属性中的文本替换文档中的所有图片(<img> 标记)。这不仅需要删除图像,还需要添加一个新的文本节点来替换它们。
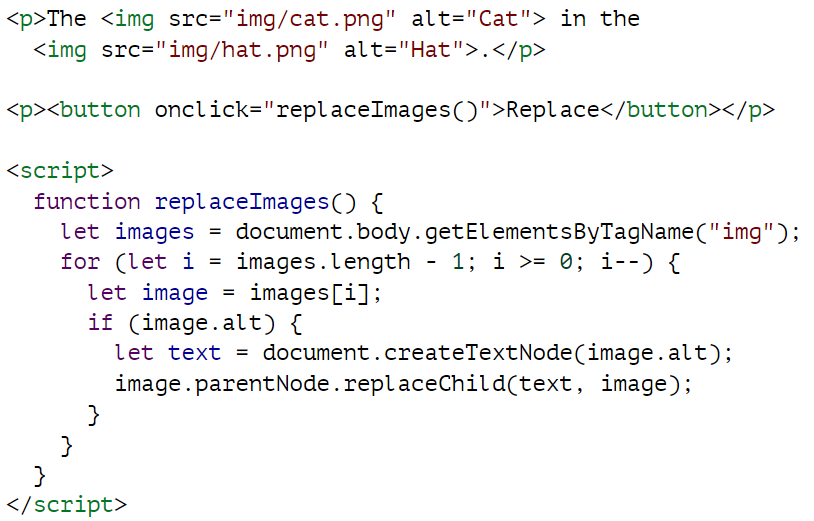
如果给定一个字符串,createTextNode 将为我们提供一个文本节点,我们可以将其插入文档,使其显示在屏幕上。遍历图像的循环从列表末尾开始。这是必要的,因为由 getElementsByTagName 等方法(或 childNodes 等属性)返回的节点列表是实时的。也就是说,它会随着文档的变化而更新。如果我们从头开始,移除第一张图片会导致列表丢失第一个元素,这样当循环第二次重复时,当 i 为 1 时,循环就会停止,因为此时集合的长度也是 1。如果你想要一个实体的节点集合,而不是一个活的节点集合,你可以通过调用 Array.from 将集合转换为一个真正的数组。

要创建元素节点,可以使用 document.createElement 方法。该方法接收一个标记名,并返回一个给定类型的新空节点。
下面的示例定义了一个实用程序 elt,它可以创建一个元素节点,并将其余参数视为该节点的子节点。该函数用于为引文添加属性。
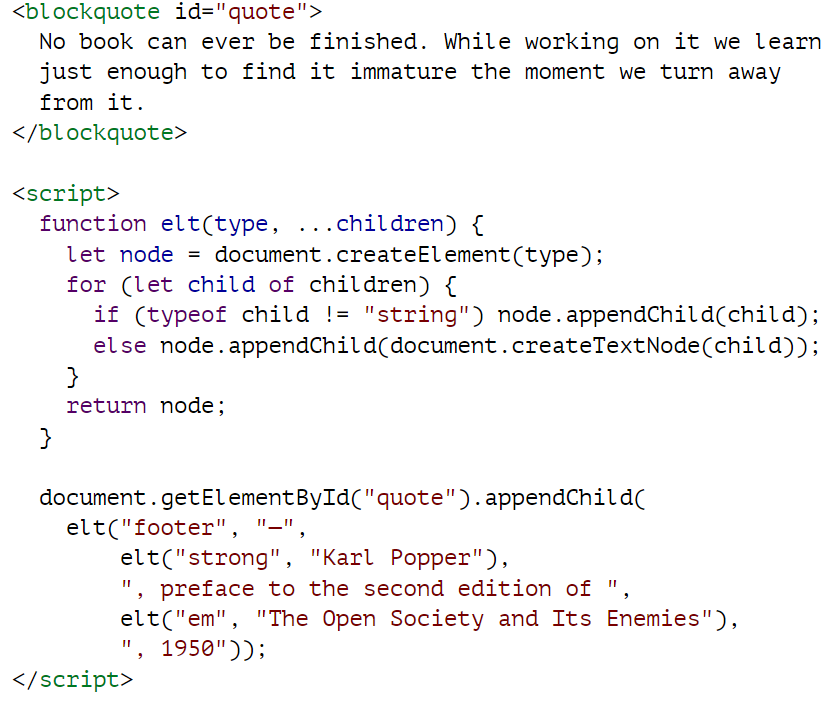
属性
某些元素属性(如链接的 href)可以通过元素 DOM 对象上的同名属性进行访问。大多数常用的标准属性都是如此。HTML 允许在节点上设置任何属性。这非常有用,因为它可以在文档中存储额外的信息。要读取或更改自定义属性(这些属性不能作为常规对象属性使用),必须使用 getAttribute 和 setAttribute 方法。

建议在此类编造的属性名称前加上 data- 字样,以确保它们不会与任何其他属性冲突。
有一个常用的属性--class,是 JavaScript 语言中的一个关键字。由于历史原因(一些旧的 JavaScript 实现无法处理与关键字匹配的属性名称),用于访问该属性的属性称为 className。您也可以使用 getAttribute 和 setAttribute 方法访问它的真名 “class”。
布局
你可能已经注意到,不同类型的元素的布局方式是不同的。有些元素,例如段落(<p>)或标题(<h1>),占据文档的整个宽度,并且呈现在单独的行上。这些称为块级元素。其他元素,例如链接(<a>)或<strong>元素,则与周围文本在同一行呈现。这些称为行内元素。对于任何给定的文档,浏览器能够计算出一个布局,该布局为每个元素基于其类型和内容分配大小和位置。然后,这个布局用于实际绘制文档。
可以通过JavaScript访问元素的大小和位置。offsetWidth和offsetHeight属性给出元素在像素中占据的空间。像素是浏览器中的基本测量单位。它通常对应于屏幕上可以绘制的最小点,但在现代显示器上,由于可以绘制非常小的点,这可能不再成立,并且浏览器像素可能跨越多个显示点。
类似地,clientWidth和clientHeight给出元素内部空间的大小,忽略边框宽度。

要找到元素在屏幕上的精确位置,最有效的方法是使用 getBoundingClientRect 方法。该方法会返回一个包含顶部、底部、左侧和右侧属性的对象,表示元素两侧相对于屏幕左上方的像素位置。如果需要相对于整个文档的像素位置,则必须添加当前的滚动位置,这可以在 pageXOffset 和 pageYOffset 绑定中找到。
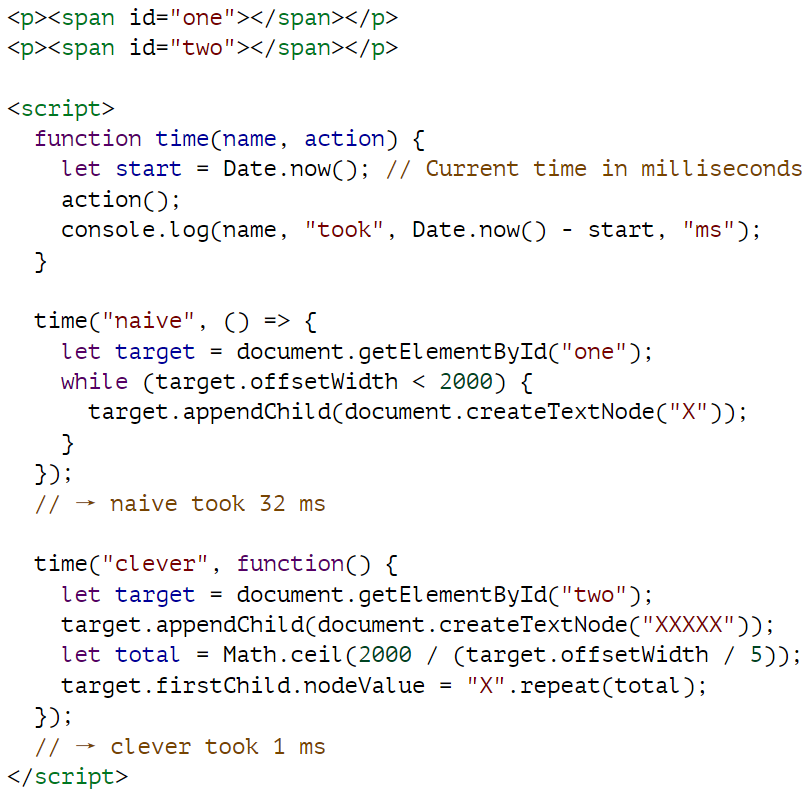
排版文档是一项相当繁重的工作。为了提高速度,每次更改文档时,浏览器引擎都不会立即重新布局,而是尽可能等待一段时间后再重新布局。当更改文档的 JavaScript 程序运行完毕后,浏览器必须计算出新的布局,才能将更改后的文档绘制到屏幕上。当程序通过读取偏移高度(offsetHeight)等属性或调用 getBoundingClientRect 来询问某些内容的位置或大小时,提供这些信息也需要计算布局。如果程序在读取 DOM 布局信息和更改 DOM 之间反复交替,就必须进行大量的布局计算,因此运行速度会非常慢。下面的代码就是一个例子。它包含两个不同的程序,分别建立一行 2000 像素宽的 X 字符,并测量每个程序所需的时间。
样式
我们看到不同的 HTML 元素以不同的方式绘制。有些元素以块级方式显示,而其他元素则是行内显示。有些元素还添加了样式——例如,<strong> 使其内容变为粗体,而 <a> 标签则使文本变为蓝色并加下划线。<img> 标签显示图像的方式或 <a> 标签在点击时跟随链接的方式与元素类型密切相关。但是,我们可以更改与元素关联的样式,例如文本颜色或下划线。以下是一个使用 style 属性的示例:

一个样式属性可以包含一个或多个声明,即一个属性(如颜色),后面跟一个冒号和一个值(如绿色)。如果有多个声明,必须用分号隔开,如:
![]()
文档的很多方面都会受到样式的影响。例如,显示属性可以控制一个元素是显示为块元素还是内联元素。

由于块元素不会与周围的文本同列显示,因此块标签将在自己的行中结束。最后一个标签是完全不显示--display: none 可以防止元素显示在屏幕上。这是一种隐藏元素的方法。这通常比将元素从文档中完全删除要好,因为这样可以方便以后再次显示。
JavaScript 代码可以通过元素的样式属性直接操作元素的样式。该属性包含一个对象,该对象具有所有可能的样式属性。这些属性的值都是字符串,我们可以通过写入字符串来改变元素样式的某个特定方面。

有些样式属性名包含连字符,如 font-family。由于在 JavaScript 中使用此类属性名比较麻烦(必须使用 style[“font-family”]),因此样式对象中的此类属性名都去掉了连字符,并将后面的字母大写(style.fontFamily)。
级联样式
HTML 的样式系统称为 CSS,即级联样式表。样式表是文档中元素样式的一组规则。它可以在 <style> 标签中给出。

名称中的“层叠”指的是多个此类规则被组合在一起,以产生元素的最终样式。在这个例子中,<strong> 标签的默认样式(使其字体加粗)被 <style> 标签中的规则覆盖,该规则添加了字体样式和颜色。当多个规则为同一属性定义值时,最近读取的规则具有更高的优先级并胜出(就近原则)。例如,如果 <style> 标签中的规则包含 font-weight: normal,与默认的 font-weight 规则相矛盾,那么文本将是正常的,而不是粗体。直接应用于节点的 style 属性中的样式具有最高优先级,并始终胜出。
在 CSS 规则中,可以定位除标签名以外的其他内容。针对 .abc 的规则适用于所有类属性中包含“abc”的元素。针对 #xyz 的规则适用于 id 属性为“xyz”的元素(在文档中应是唯一的)。

优先级规则优先考虑最近定义的规则,仅在规则具有相同的特异性时适用。规则的特异性是衡量它描述匹配元素的精确程度,取决于所需元素方面的数量和种类(标签、类或 ID)。例如,针对 p.a 的规则比针对 p 或仅 .a 的规则更具特异性,因此会优先于它们。表示法 p > a {…} 将指定的样式应用于所有直接子元素为 <p> 标签的 <a> 标签。同样,p a {…} 将应用于所有位于 <p> 标签内部的 <a> 标签,无论它们是直接子元素还是间接子元素。
查询选择器
在本书中,我们不会经常使用样式表。了解样式表对在浏览器中编程很有帮助,但它们非常复杂,需要单独写一本书。我介绍选择器语法--样式表中用于确定一组样式适用于哪些元素的符号--的主要原因是,我们可以使用相同的迷你语言作为查找 DOM 元素的有效方法。
querySelectorAll 方法既定义在文档对象上,也定义在元素节点上,它接收一个选择器字符串,并返回一个包含所有匹配元素的 NodeList。
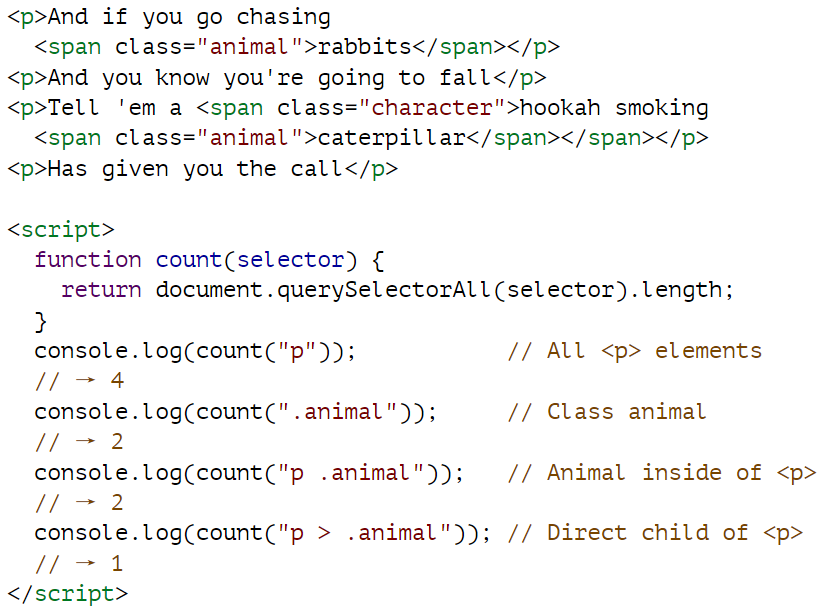
与 getElementsByTagName 等方法不同,querySelectorAll 返回的对象不是实时对象。当你更改文档时,它不会改变。不过,它仍然不是一个真正的数组,所以如果你想把它当作一个数组,就需要调用 Array.from。querySelector 方法(没有 All 部分)的工作方式与此类似。如果你想要特定的单个元素,这个方法就很有用。它只会返回第一个匹配的元素,如果没有匹配的元素,则返回空值。
定位和动画
position 样式属性以一种强大的方式影响布局。它的默认值为static,这意味着元素位于文档中的正常位置。当设置为relative时,元素仍占用文档中的空间,但现在可以使用top和left样式属性将其相对于正常位置移动。当 position 设置为absolute位置时,该元素将从文档的正常流程中移除,也就是说,它不再占用空间,并可能与其他元素重叠。它的top和left属性可用于将其相对于position属性不是static的最近包围元素的左上角进行绝对定位,如果没有这样的包围元素,则可将其相对于文档进行绝对定位。
我们可以用它来创建动画。下面的文档显示了一幅在椭圆形中移动的猫的图片:

我们的图片在页面上居中,位置为相对位置。我们将反复更新图片的顶部和左侧样式,以移动图片。只要浏览器准备好重新绘制屏幕,脚本就会使用 requestAnimationFrame 调度 animate 函数运行。动画函数本身会再次调用 requestAnimationFrame 来安排下一次更新。当浏览器窗口(或标签页)处于活动状态时,这将导致更新以大约每秒 60 次的速度进行,从而产生好看的动画。
如果我们只是循环更新 DOM,页面就会冻结,屏幕上也不会显示任何内容。浏览器不会在 JavaScript 程序运行时更新显示内容,也不允许与页面进行任何交互。这就是我们需要 requestAnimationFrame 的原因--它让浏览器知道我们暂时完成了任务,它可以继续做浏览器要做的事情,例如更新屏幕和响应用户操作。
动画函数的参数是当前时间。为确保猫每毫秒的运动稳定,它将角度变化的速度建立在当前时间与函数上次运行时间之差的基础上。如果每步只移动固定的角度,那么当同一台电脑上运行的另一项繁重任务导致函数无法运行几分之一秒时,运动就会出现停顿。
圆周运动是通过三角函数 Math.cos 和 Math.sin 完成的。对于不熟悉这两个函数的读者,我将简要介绍它们,因为我们在本书中偶尔会用到它们。
Math.cos 和 Math.sin 可用于查找位于半径为 1 的点(0,0)周围圆上的点。这两个函数都将其参数解释为圆上的位置,0 表示圆最右边的点,顺时针方向直到 2π(约 6.28)绕完整个圆为止。Math.cos 可以告诉您给定位置对应点的 x 坐标,Math.sin 可以得出 y 坐标。位置(或角度)大于 2π 或小于 0 都是有效的--旋转重复进行,因此 a+2π 指的是与 a 相同的角度。这种测量角度的单位称为弧度--一整圈是 2π 弧度,类似于用度数测量时的 360 度。常数 π 在 JavaScript 中可以用 Math.PI 表示。

猫动画代码为动画的当前角度保留了一个计数器 angle,并在每次调用 animate 函数时递增。然后,它就可以使用这个角度来计算图像元素的当前位置。顶部样式用 Math.sin 计算,然后乘以 20,即我们椭圆的垂直半径。左侧样式基于 Math.cos 并乘以 200,因此椭圆的宽度远大于高度。
请注意,样式通常需要单位。在这种情况下,我们必须在数字后面加上 “px”,告诉浏览器我们是以像素为单位(而不是厘米、ems 或其他单位)。这一点很容易忘记。使用不带单位的数字会导致您的样式被忽略,除非该数字为 0,这意味着无论使用什么单位都是一样的。
总结
JavaScript 程序可以通过一个名为 DOM 的数据结构来检查和干扰浏览器正在显示的文档。这个数据结构代表了浏览器的文档模型,JavaScript 程序可以通过修改它来改变可见文档。
DOM 的组织结构就像一棵树,其中的元素根据文档的结构分层排列。代表元素的对象具有父节点(parentNode)和子节点(childNodes)等属性,可用于在树中导航。
文档的显示方式可以受到样式的影响,既可以直接将样式附加到节点上,也可以定义与某些节点匹配的规则。有许多不同的样式属性,如颜色或显示。JavaScript 代码可以直接通过元素的样式属性来操作元素的样式。
原文地址:https://blog.csdn.net/u010398484/article/details/142751306
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!