架构篇(04理解架构的演进)
目录
学习前言
在学习架构时,第一步不要去学习框架,而是要学习架构的演进。
强烈推荐李智慧老师的《大型网站技术架构》,这本书翻起来很快,对构筑你自己的体系很有帮助,本文的内容
来源于它,在此基础上拓展了下。@pdai
一、架构演进
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计
的数据和面对数以亿计的用户,问题就会变得很棘手。大型网站架构主要就是解决这类问题。
架构选型是根据当前业务需要来的,在满足业务需求的前提下,既要有足够的扩展性也不能过度设计,每次的架
构升级都是为了解决系统瓶颈而做的。
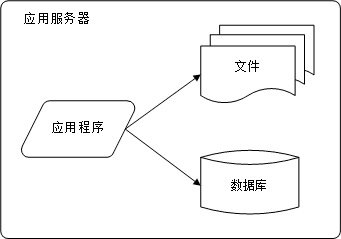
1. 初始阶段的网站架构
初始阶段都比较简单,通常一台服务器就可以搞定一个网站了,看图。
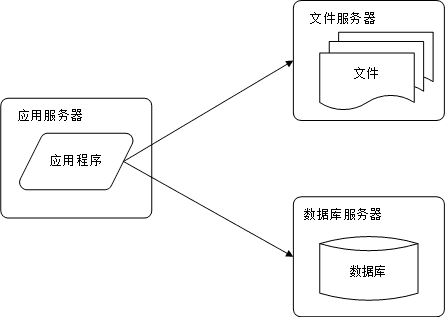
2. 应用服务和数据服务分离
随着网站业务的发展,一台服务器逐渐不能满足需求;这时候就需要将应用和数据分离,如图。
3. 使用缓存改善网站性能
毫无疑问,现在的网站基本上都会使用缓存,即:80%的业务访问都会集中在20%的数据上。
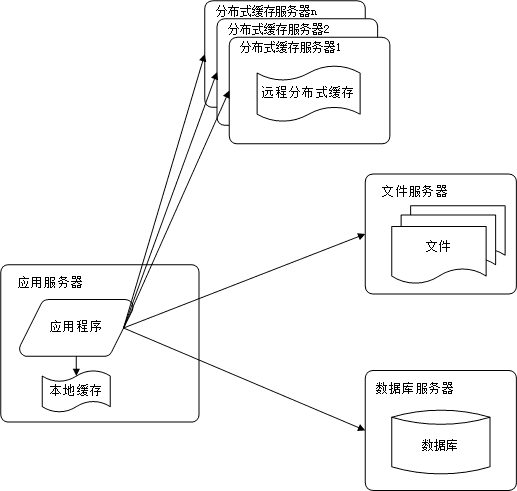
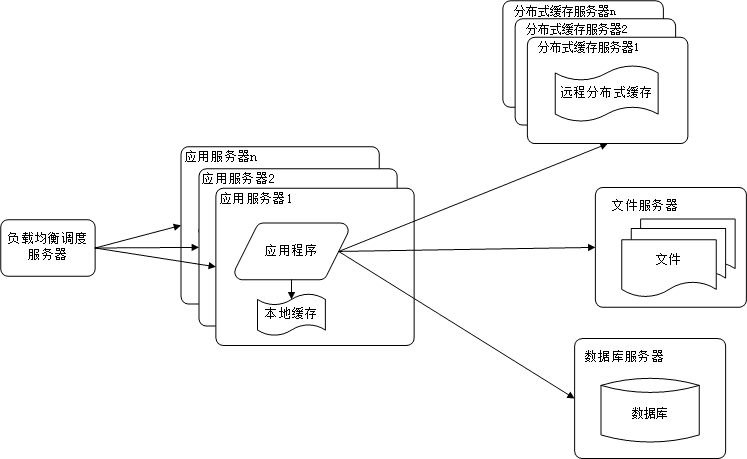
4. 使用应用服务器集群改善网站的并发处理能力
因为单一应用服务器能够处理的请求连接有限,在网站访问高峰时期,应用服务器会成为整个网站的瓶颈。因此
使用负载均衡处理器势在必然。通过负载均衡调度服务器,可将来自浏览器的访问请求分发到应用的集群中的任
何一台服务器上。
5. 数据库读写分离
当用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。而目前主流的数据库都提供主从热备功能,通过配置两台数据库主
从关系,可以将一台数据库的数据更新同步到另一台服务器上。网站利用数据库这一功能实现数据库读写分离,从而改善数据库负载压
力。
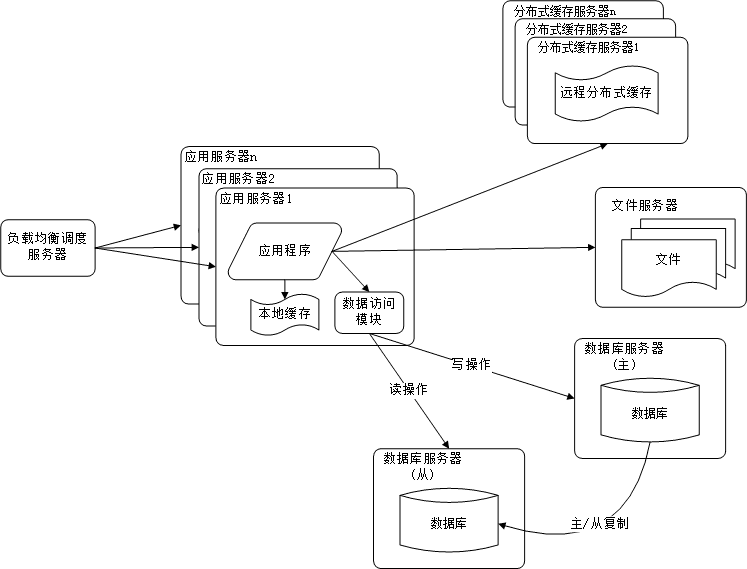
6. 使用反向代理和CDN加上网站相应
提高网站的访问速度,主要手段有使用CDN和反向代理。
CDN和反向代理的基本原理都是缓存,区别在于CDN部署在网络提供商的机房,而反向代理是部署在网站的中心
机房,当用户请求到达中心机房后,首先访问的反向代理,如果反向代理缓存着用户请求的资源,则直接返回给
用户。
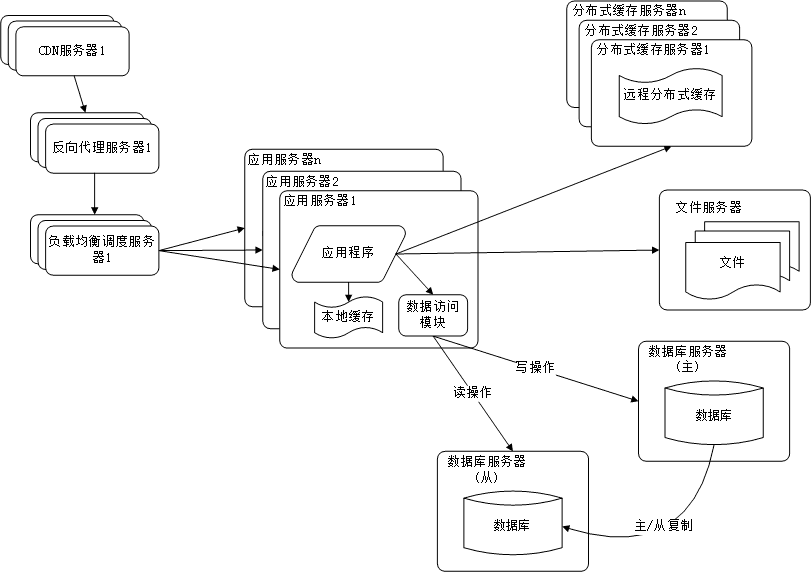
7. 使用分布式文件系统和分布式数据库系统
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。
分布式数据库时网站数据库拆分的最后手段,只用在单表数据规模非常大的时候才使用。不到不得已时,网站更
常用的数据库拆分手段是业务拆分,将不同业务的数据部署在不同的物理服务器上。
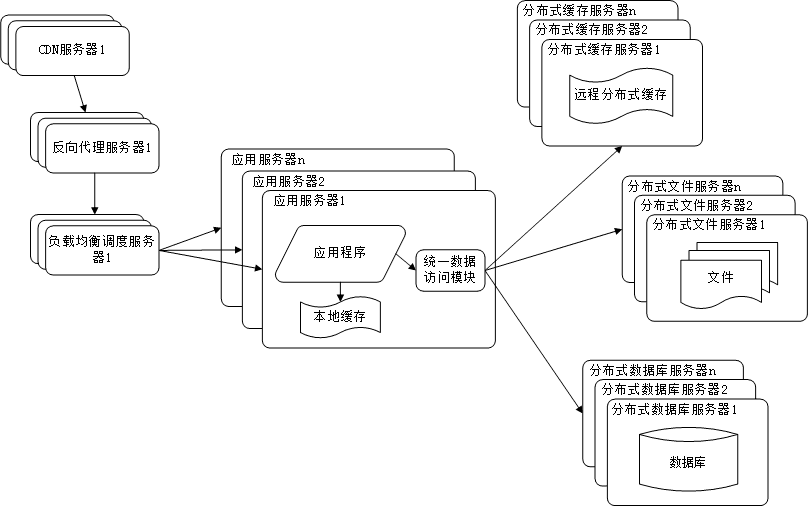
8. 使用NoSQL和搜索引擎
搜索引擎也基本已经形成现在大型网站必须提供的功能了,
网站需要采用一些非关系数据库技术如NoSQL和非数据库查询技术如搜索引擎。
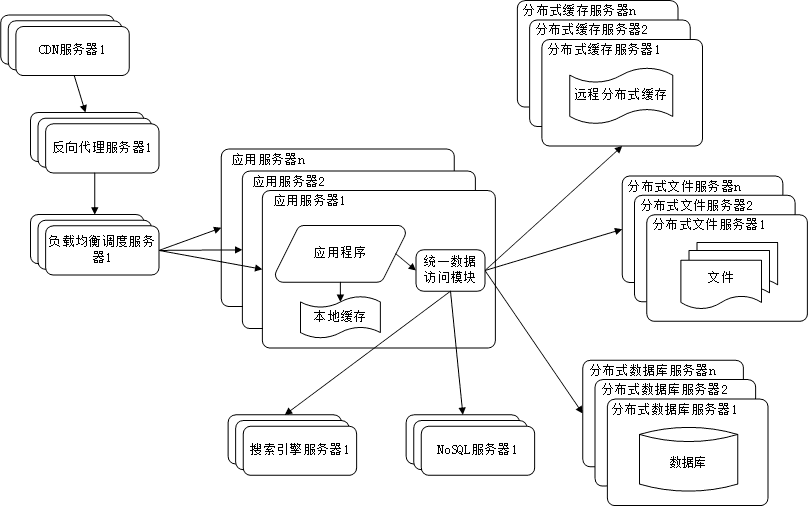
9. 业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将真个网站业务拆分成不同的产品线。
具体到技术上,也会根据产品线话费,将一个网站拆分成许多不同的应用,每个应用独立部署维护。应用之间可
以通过超链接建立管理,也可以通过消息队列进行数据分发,当然最多的还是通过访问同一个数据存储系统来构
成一个关联的完整系统。
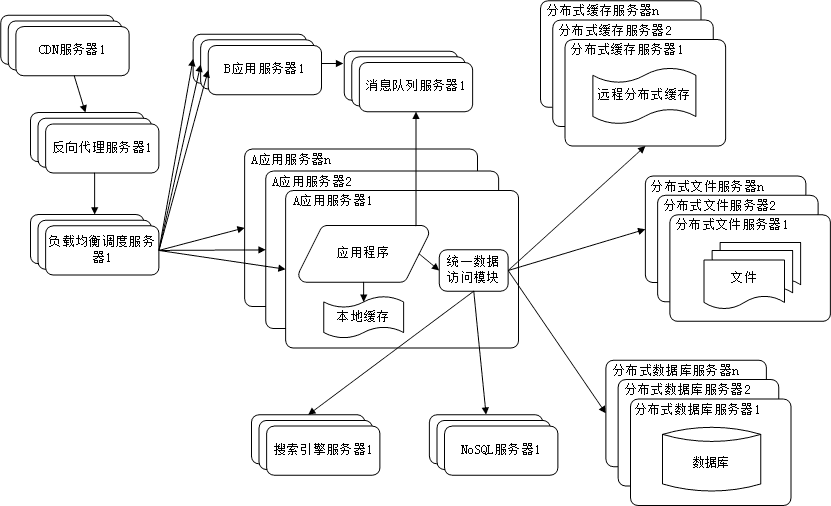
10. 分布式服务
由于每一个应用系统都需要执行许多相同的业务操作,比如用户管理,session管理,那么可以将这些公用的业务
提取出来,独立部署。
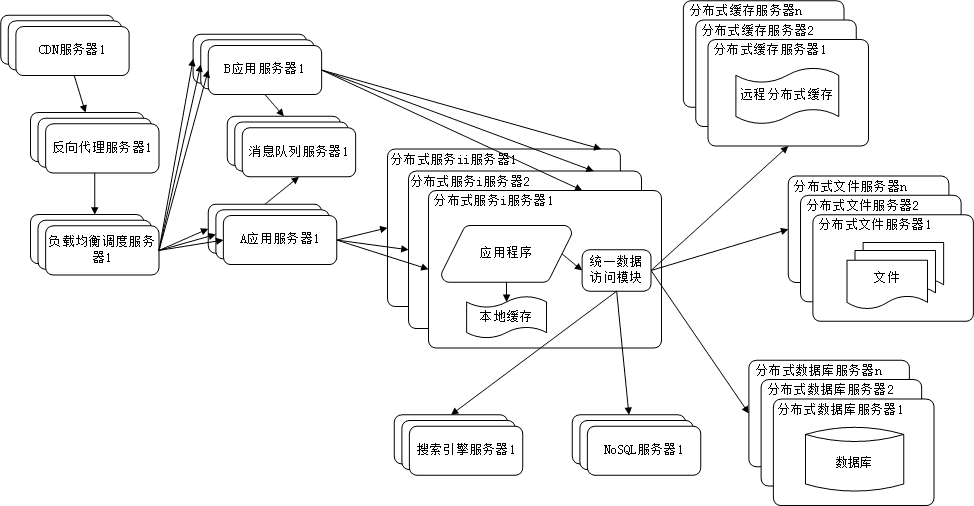
二、示例:电商系统架构演进
具体以电子商务网站为例, 展示web应用的架构演变过程。
1.0 时代

这个时候是一个web项目里包含了所有的模块,一个数据库里包含了所需要的所有表,这时候网站访问量增加时,
首先遇到瓶颈的是应用服务器连接数,比如tomcat连接数不能无限增加,线程数上限受进程内存大小、CPU内核
数等因素影响,当线程数到达一定数时候,线程上下文的切换对性能的损耗会越来越严重,响应会变慢,通过增
加web应用服务器方式的横向扩展对架构影响最小,这时候架构会变成下面这样:
2.0 时代
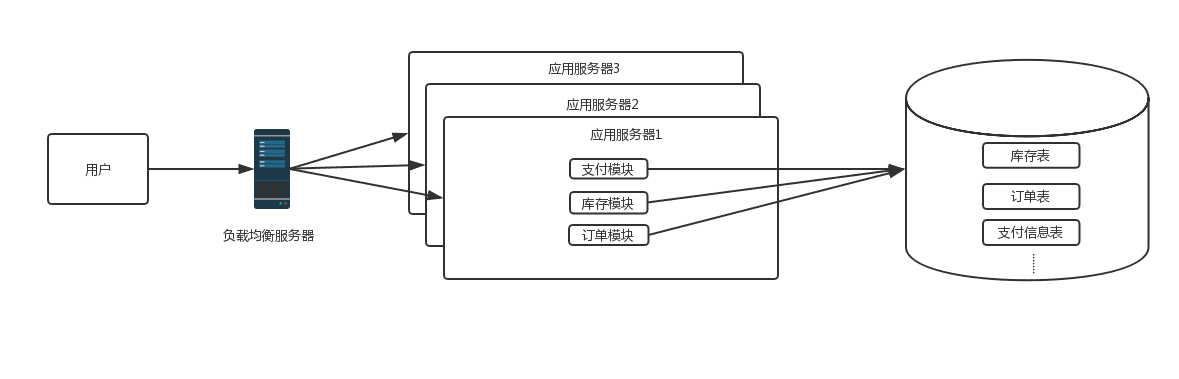
这时候随着网站访问量继续增加,继续增加应用服务器数量后发现数据库成了瓶颈,而数据库的最主要的瓶颈体
现在两方面:
- 数据库的最大连接数是有限的,比如当前数据库的连接数设置8000,如果每个应用服务器与数据库的初始连接数设置40,那么200台web服务器是极限, 并且连接数太多后,数据库的读写压力增大,耗时增加
- 当单表数量过大时,对该表的操作耗时会增加,索引优化也是缓兵之计
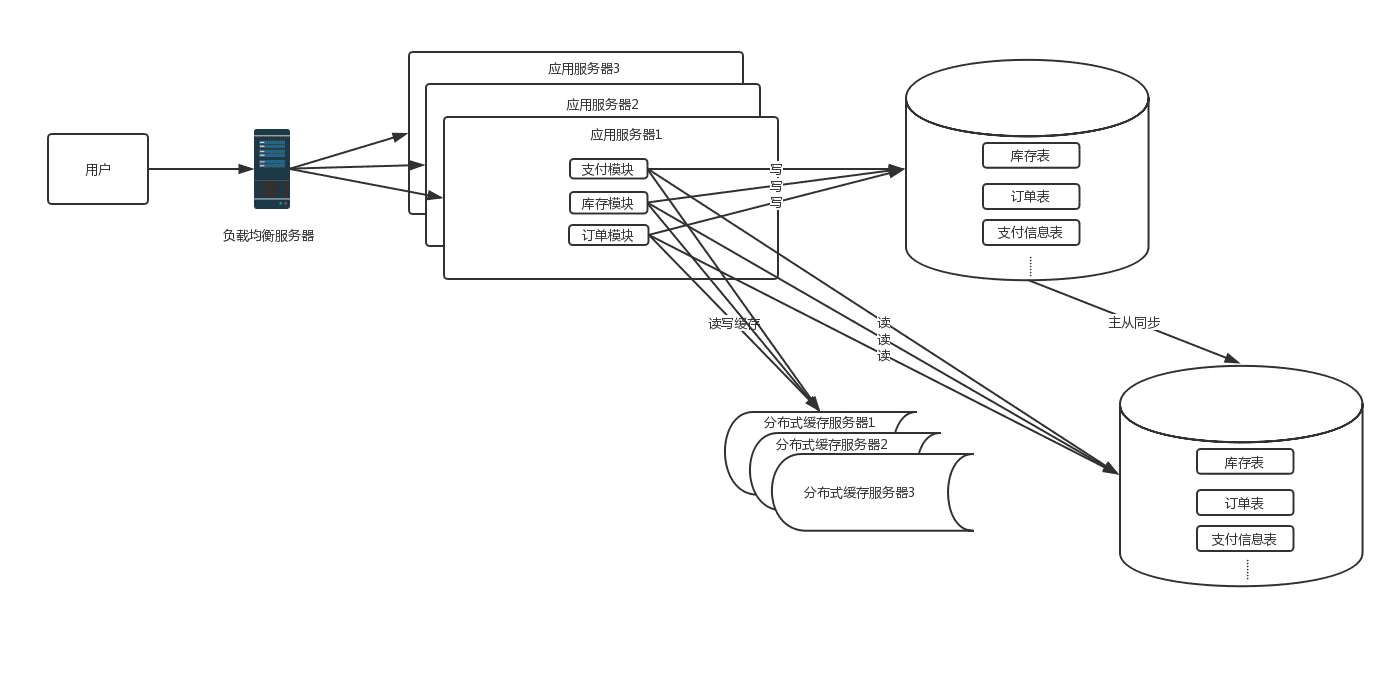
这时,根据业务特点,如果读写比差距不大,并且对数据一致性要求不是很高的情况下,数据库可以采用主从方
式进行读写分离的方案,并且引入缓存机制来抗读流量。如果读写比差距很大或者对数据一致性要求高时,就不
适合用读写分离方案,需要考虑业务的垂直拆分,这时期的系统架构图如下:
3.0 时代
读写分离
这时候仍然是垂直架构,所有业务集中在一个项目里。项目维护、快速迭代问题会越来越严重,单个模块的开发
都需要发布整个项目,项目稳定性也受到很大挑战,这是需要考虑业务的垂直拆分,需要将一些大的模块单独拆
出来,这时候的架构图如下:
4.0 业务垂直拆分
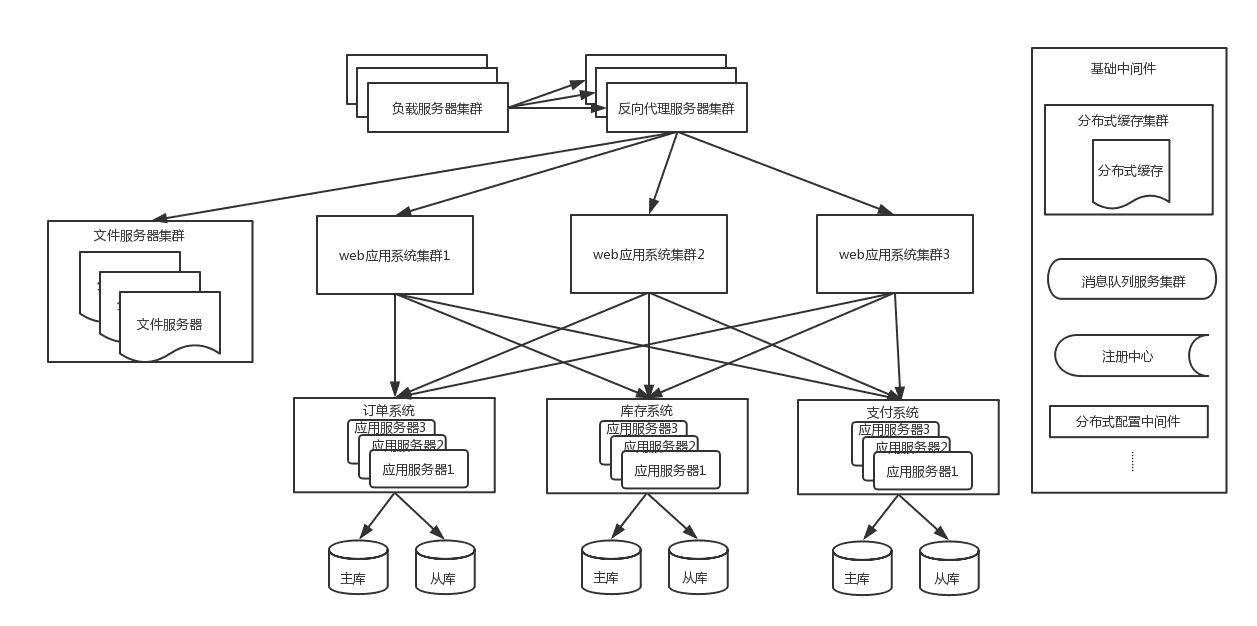
这时候为了进一步提升用户体验,加速用户的网站访问速度,会使用CDN来缓存信息,用户会访问最近的CDN节
点来提升访问速度。
此时的架构图如下:
使用CDN来缓存信息
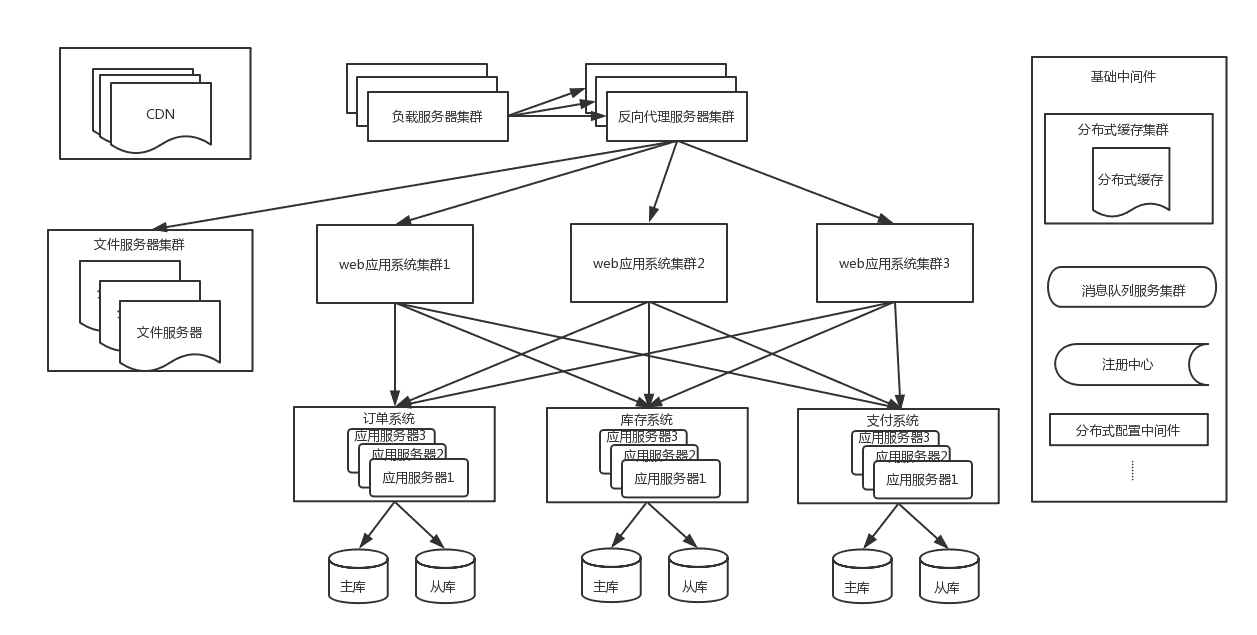
随着业务量增大,一些核心系统数据库单表数量达到几千万甚至亿级,这时候对该表的数据操作效率会大大降
低,并且虽然有缓存来抗读的压力,但是对于大量的写操作和一些缓存miss的流量到达一定量时,单库的负荷也
会到达极限,这时候需要将表拆分,一般直接采用分库分表,因为只做分表的话,单个库的连接瓶颈仍然无法解
决。分库分表后的架构如下:
分库分表架构
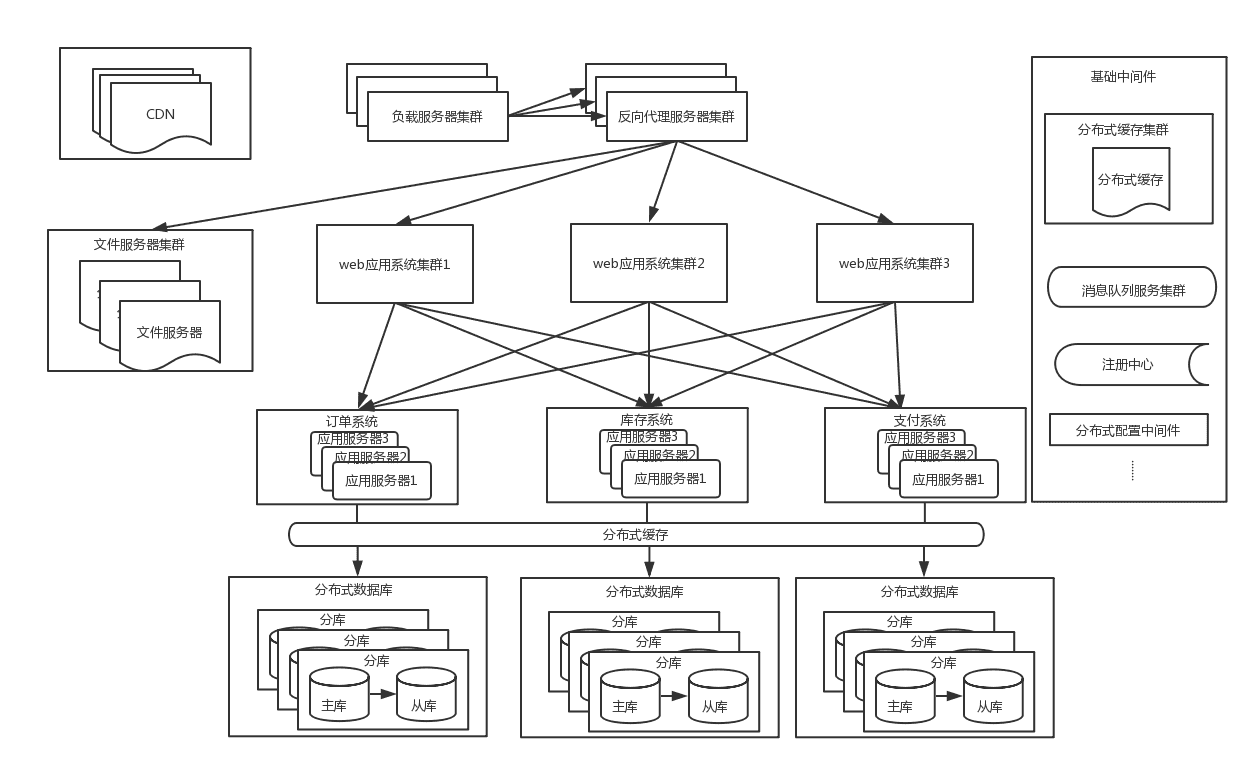
随着流量的进一步增大,这时候系统仍然会有瓶颈出现,以订单系统为例: 单个机房的机器是有限的,不能一直
新增下去,并且基于容灾的考虑,一般采用同城双机房的方式,机房之间用专线链接,同城跨机房质检的延时在
几毫秒,此时的架构图如下:
同城双机房
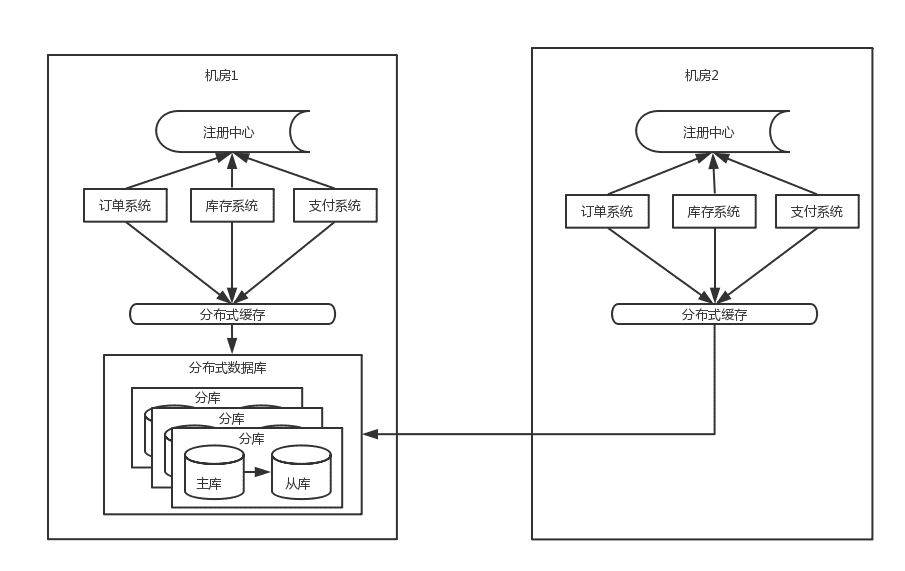
由于数据库主库只能是在一个机房,所以仍然会有一半的数据库访问是跨机房的,虽然延时只有几毫秒,但是一
个调用链里的数据库访问太多后,这个延时也会积少成多。其次这个架构还是没能解决数据库连接数瓶颈问题
- 随着应用服务器的增加,虽然是分库分表,但每增加一台应用服务器,都会与每个分库建立连接,比如数据
库连接池默认连接数是40,而如果mysql数据库的最大连接数是8000的话,那么200台应用服务器就是极
限。
- 当应用的量级太大后,单个城市的机器、电、带宽等资源无法满足业务的持续增长。这时就需要考虑SET化架
构,也就是单元化架构,大体思路就是将一些核心系统拆成多个中心,每个中心成为一个单元,流量会按照
一定的规则分配给每个单元,这样每个单元只负责处理自己的流量就可以了。每个单元要尽量自包含、高内
聚。这是从整体层面将流量分而治之的思路。这是单元化后的机构简图如下:
5.0 单元化
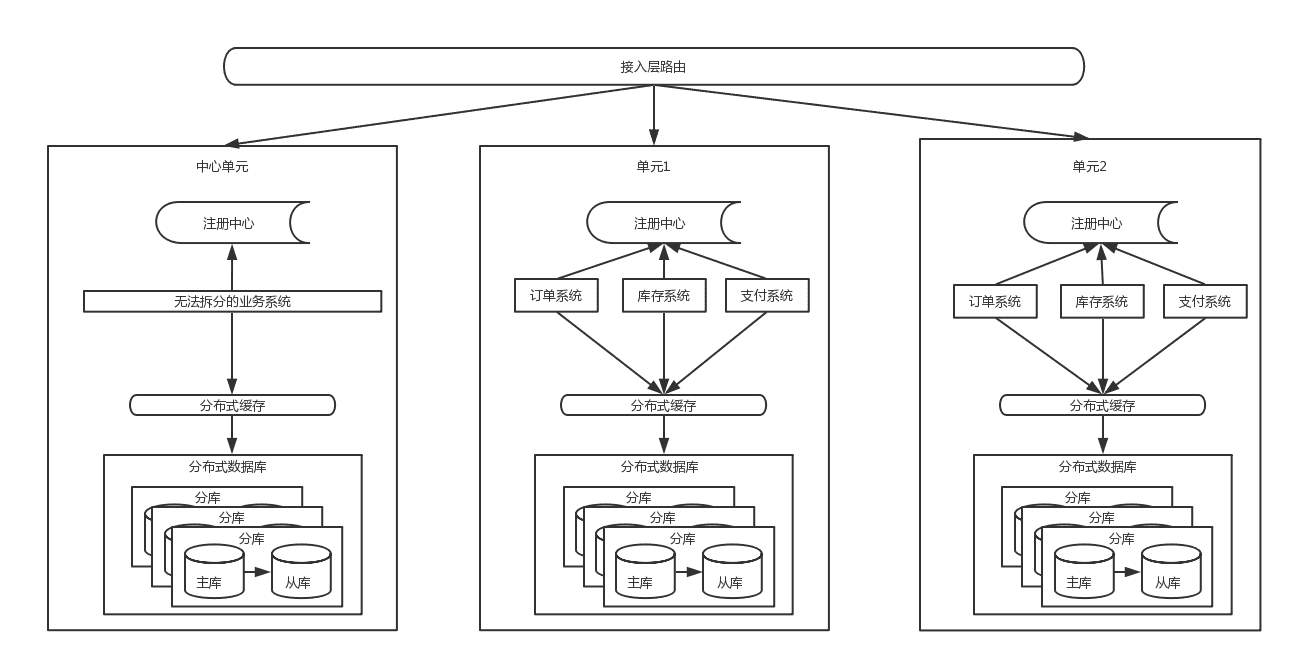
从上面的架构图里能看到,流量从接入层按照路由规则(比如以用户ID来路由)路由到不同单元,每个单元内都
是高内聚,包含了核心系统,数据层面的分片逻辑是与接入层路有逻辑一致,也解决了数据库连接的瓶颈问题,
但是一些跨单元的调用是无法避免的,同时也有些无法拆分的业务需要放在中心单元,供所有其他单元调用。
三、参考文献
文章主要参考自 李智慧的 《大型网站技术架构》,在此基础上还参考了(基本也是从这本书里自己画的):
原文地址:https://blog.csdn.net/qq_51226710/article/details/143664722
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!