llm接口高可用工程实践(尽快关注我,以后这些文章将只对粉丝开放)
上一节课程链接:中文llama3仿openai api实战-CSDN博客 ,本文是在上一节基础上继续操作
课程介绍
本文基于Chinese-LLaMA-Alpaca-3(https://github.com/ymcui/Chinese-LLaMA-Alpaca-3)项目,介绍如何通过搭建2个llama3私有化api和oneapi网关,实现大模型接口的高可用方案。
(1)上节课,我们进行了llama3-8b模型的本地化部署及仿openai api接口开放;
(2)本次课基于上节课的基础,进行llama3-8b本地化及接口的高可用;
学习知识:
(1)windows终端ssh服务器、windows版本客户端安装;
(2)windows作为客户端的cpu/gpu大模型的部署和应用:
(3)基于容器(docker)安装oneapi及配置,使用oneapi连接已部署的cpu/gpu版本大模型;
(4)基于oneapi学习高可用测试;
(5)一些常用指令操作;
实验环境
本文的基础环境如下
操作系统:ubuntu20.04
CUDA:12.2
英伟达显卡驱动版本:535.183.01
显卡型号:本实验用英伟达3090(全模型(未开量化)需要单张显存大于20GB的英伟达显卡;
**开量化之后的模型可以使用11GB显存的英伟达显卡,基本市面上大部分消费级显卡可以满足实验要求,
大家根据自己的显卡进行选择实验)
客户端演示环境: windows
实验环境准备
MacOS
命令行工具
如果您使用的是苹果操作系统,可以直接使用系统自带的终端软件来连接服务器。具体操作步骤如下,首先按Command+空格打开聚焦搜索界面:

然后在聚焦搜索框中,输入终端两个字,如下图:

回车即可打开终端:

大模型聊天客户端
我们使用ChatGPTNextWeb工具测试我们的接口,如果您没有下载客户端,可以通过下面地址下载:
Windows10/11
命令行工具
在windows系统中,我们使用Git Bash来连接服务器,下面是具体安装步骤,首先我们通过如下地址下载安装包:https://github.com/git-for-windows/git/releases/download/v2.46.0.windows.1/Git-2.46.0-64-bit.exe,下载好以后,双击安装包,出现如下画面:
可以将Only show new options选项去掉,以看到更多的安装选项。点击Next,将看到如下图:

继续点击Next,出现如下图界面:


在上述界面中,一直点击Next即可。最后点击install:
大模型聊天客户端
我们使用ChatGPTNextWeb工具测试我们的接口,如果您没有下载客户端,可以通过下面地址下载:
下载后,双击安装包运行,如果出现如下画面,点击更多信息:
然后一直点击Next即可安装。
开始实验
本文默认您在操作系统的用户名为:llm_course,如果您使用的是其他用户名,请更改涉及到用户名的地址。基本的搭建架构图如下:
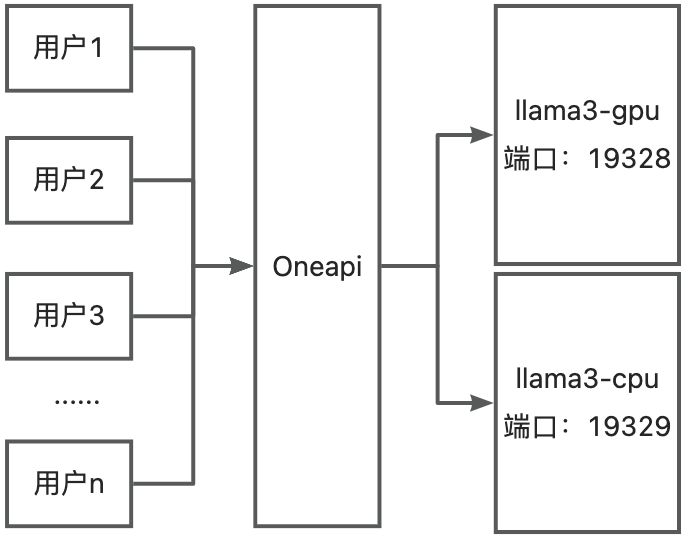
我们通过人工停掉llama3-cpu,保持llama3-gpu运行,来模拟节点故障。
安装Docker(如有可跳过)
#移除 Docker 相关的软件包和容器运行时
apt remove docker-ce docker-ce-cli containerd.io docker-compose-plugin docker docker-engine docker.io containerd runc
# 切换国内源
sed -i -r 's#http://(archive|security).ubuntu.com#https://mirrors.aliyun.com#g' /etc/apt/sources.list && apt update -y
### 安装docker
# 安装ca-certificates curl gnupg lsb-release
apt install ca-certificates curl gnupg lsb-release -y
#下载 Docker 的 GPG 密钥,并将其添加到 apt-key 中
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | apt-key add -
# 为Docker 添加阿里源
add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# 更新系统的软件包
apt -y update
# 安装docker相关的包
apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y兼容多端口启动
因为我们要基于一份代码,启动两个服务,我们需要在原有的代码中加入端口参数,打开下面文件:~/Chinese-LLaMA-Alpaca-3-3.0/scripts/oai_api_demo/openai_api_server.py,做如下修改:
parser = argparse.ArgumentParser() # 找到改行代码,在改行代码下添加一行
parser.add_argument('--port', default=19327, type=int) # 新添加一行
# 找到这行代码
uvicorn.run(app, host="0.0.0.0", port=19327, workers=1, log_config=log_config)
# 改为如下内容
uvicorn.run(app, host="0.0.0.0", port=args.port, workers=1, log_config=log_config)启动llama3 gpu和cpu版本
我们假设您已在上次课《中文llama3仿openai api实践》中搭建好了相应的环境。如果您还未搭建对应的环境,可以参考之前的课程文档。
启动gpu版本
conda activate chinese_llama_alpaca_3 # 激活虚拟环境
cd ~/Chinese-LLaMA-Alpaca-3-3.0/scripts/oai_api_demo/ # 进入脚本目录
python openai_api_server.py --gpus 0 --base_model /home/llm_course/.cache/modelscope/hub/ChineseAlpacaGroup/llama-3-chinese-8b-instruct-v3默认情况下,程序将监听19327端口。
启动cpu版本
conda activate chinese_llama_alpaca_3_cpu # 激活虚拟环境
cd ~/Chinese-LLaMA-Alpaca-3-3.0/scripts/oai_api_demo/ # 进入脚本目录
python openai_api_server.py --only_cpu --port 19328 --base_model /home/llm_course/.cache/modelscope/hub/ChineseAlpacaGroup/llama-3-chinese-8b-instruct-v3部署oneapi
创建docker-compose.yam文件
mkdir -p ~/oneapi-compose
cd ~/oneapi-compose
touch docker-compose.yaml在docker-compose.yaml文件中添加如下内容(命令行中可以使用nano docker-compose.yaml打开):
version: '3.8'
services:
oneapi:
image: m.daocloud.io/ghcr.io/songquanpeng/one-api:v0.6.7
container_name: oneapi
restart: always
ports:
- 3030:3000
networks:
- oneapi_llm_course
environment:
- TZ=Asia/Shanghai
volumes:
- ./data:/data
networks:
oneapi_llm_course:启动服务
使用如下命令启动容器:docker compose up -d
修改默认密码
打开刚才部署的oneapi页面,通过ifconfig命令可以查看您的服务器地址,我们这里假设您的服务器地址是:192.168.9.96,在浏览器中打开:http://192.168.9.96:3030,可以看到如下界面:
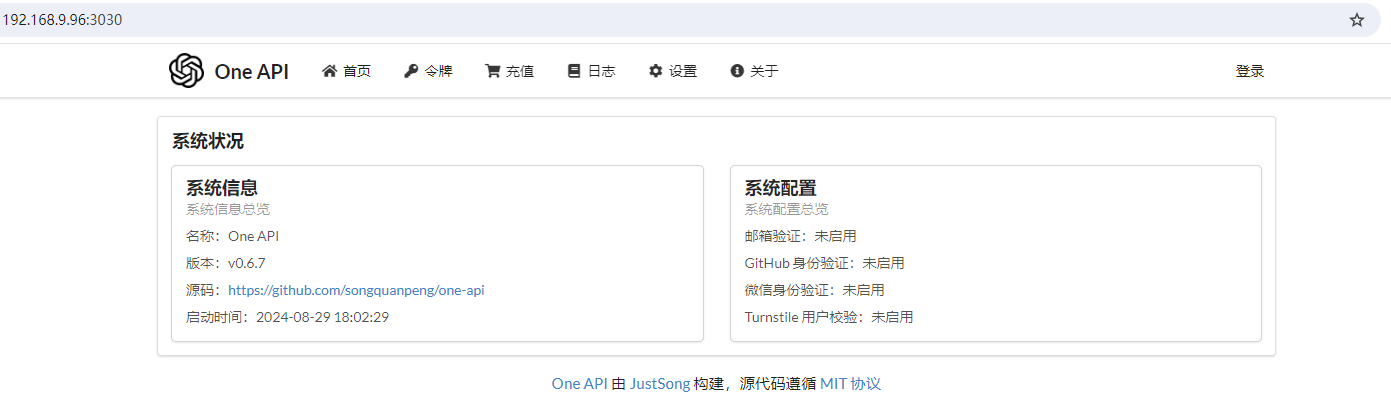
点击登录,当您第一次登录oneapi时,默认用户名是root,默认密码是123456,登录后需要立即修改密码:
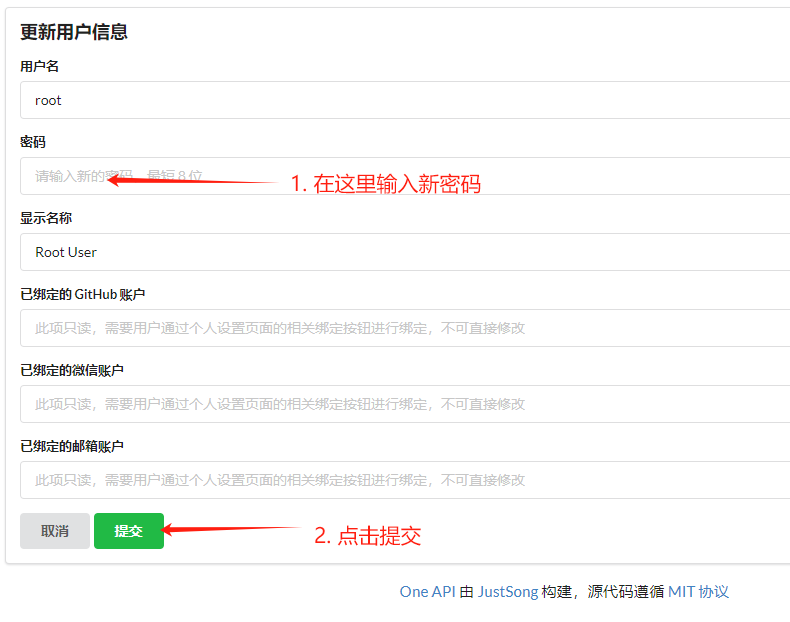
我们这里将密码设置为:Llm_course,您可以设置您自己认为安全的密码。
添加渠道
添加llama3-gpu渠道
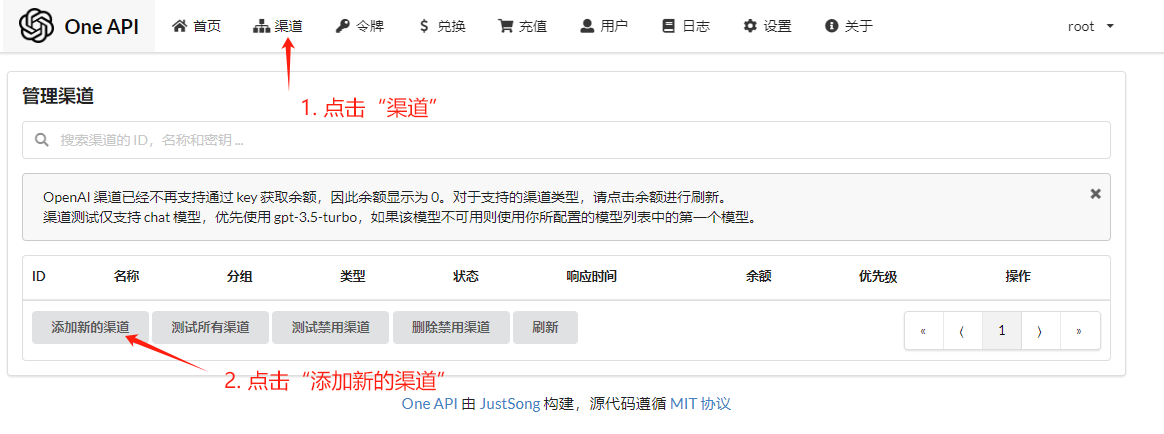
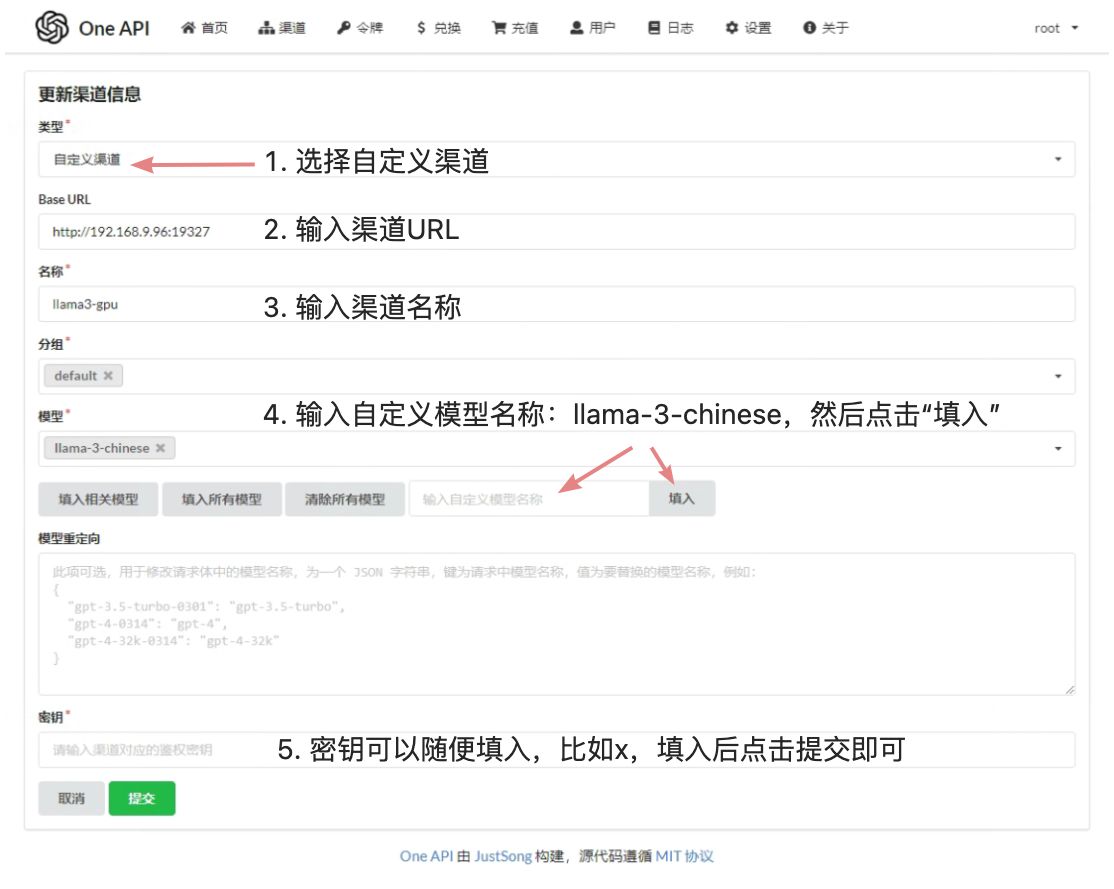
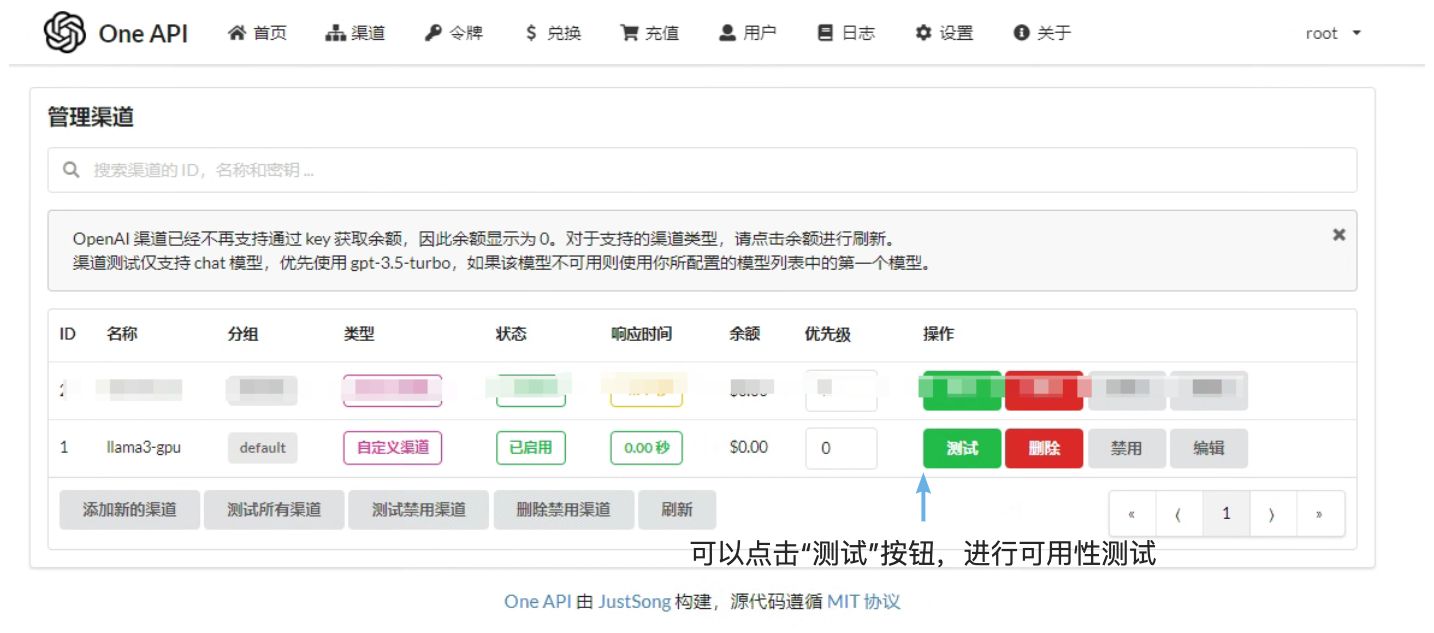
再次点击渠道菜单,可以看到如下页面:
添加llama3-cpu渠道
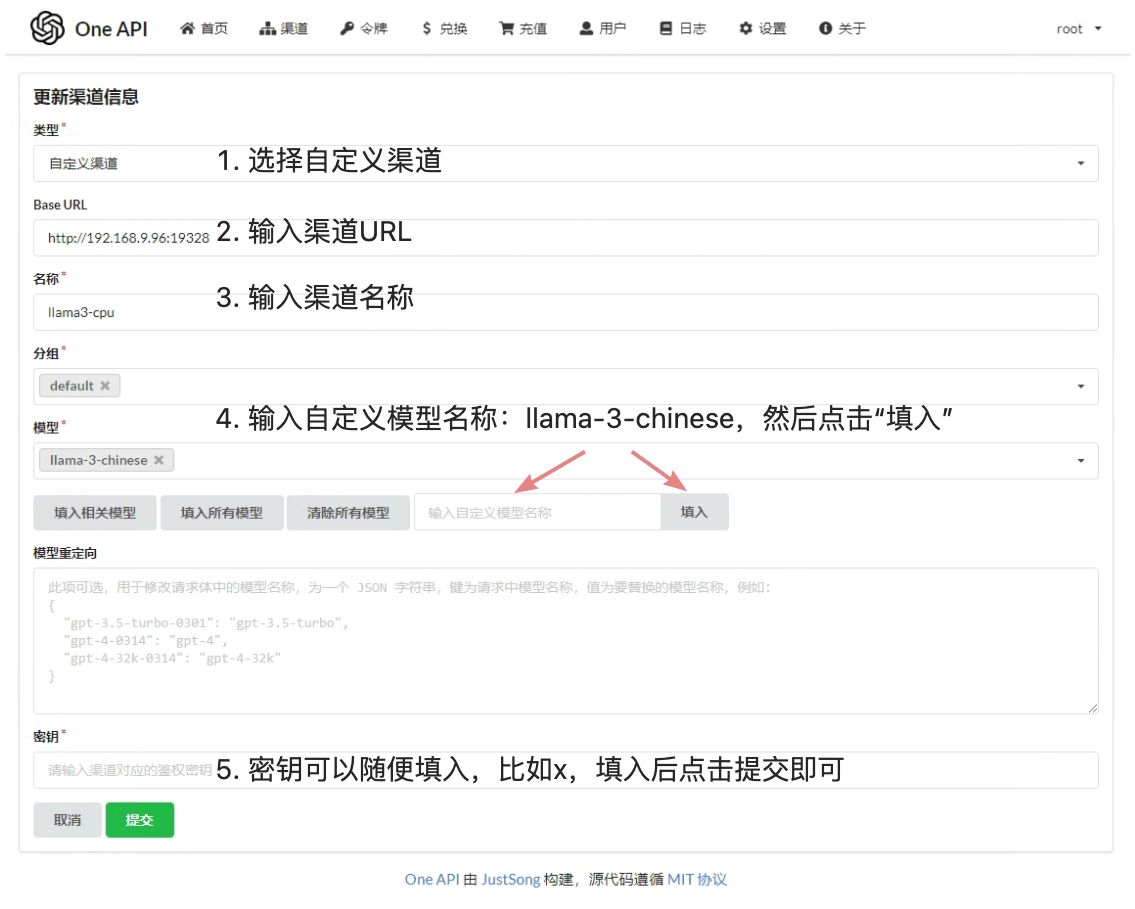
再次点击渠道菜单,可以看到如下页面:
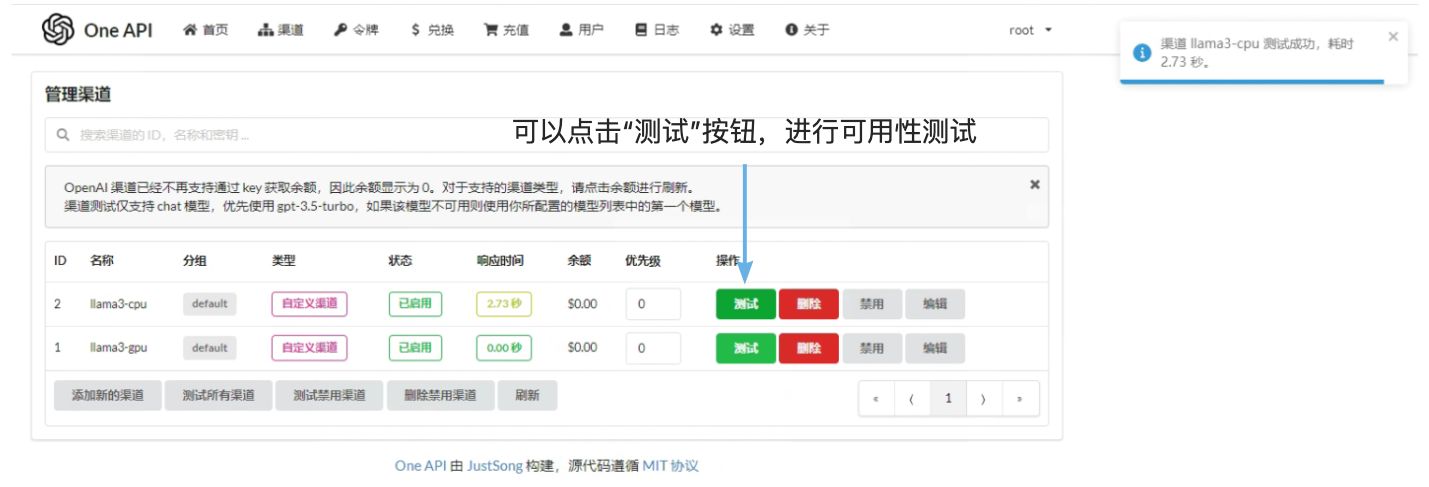
添加Token
我们需要添加一个Token用于后续测试:

输入令牌详情:

复制刚才创建的Token在后续高可用测试中将用到该Token:
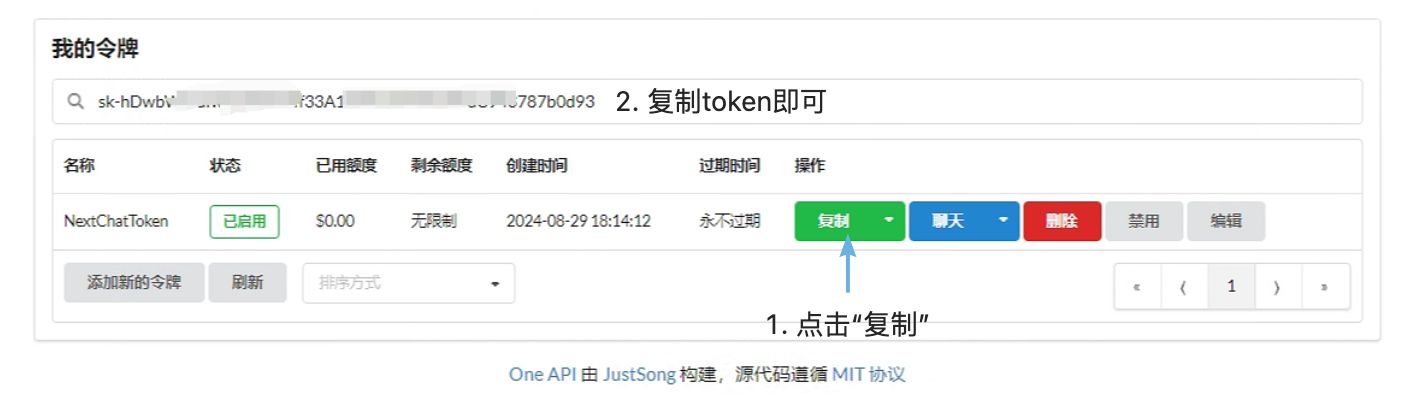
测试高可用
配置ChatGPTNextWeb
我们使用ChatGPTNextWeb来进行测试,首先我们需要配置该软件。如下图:
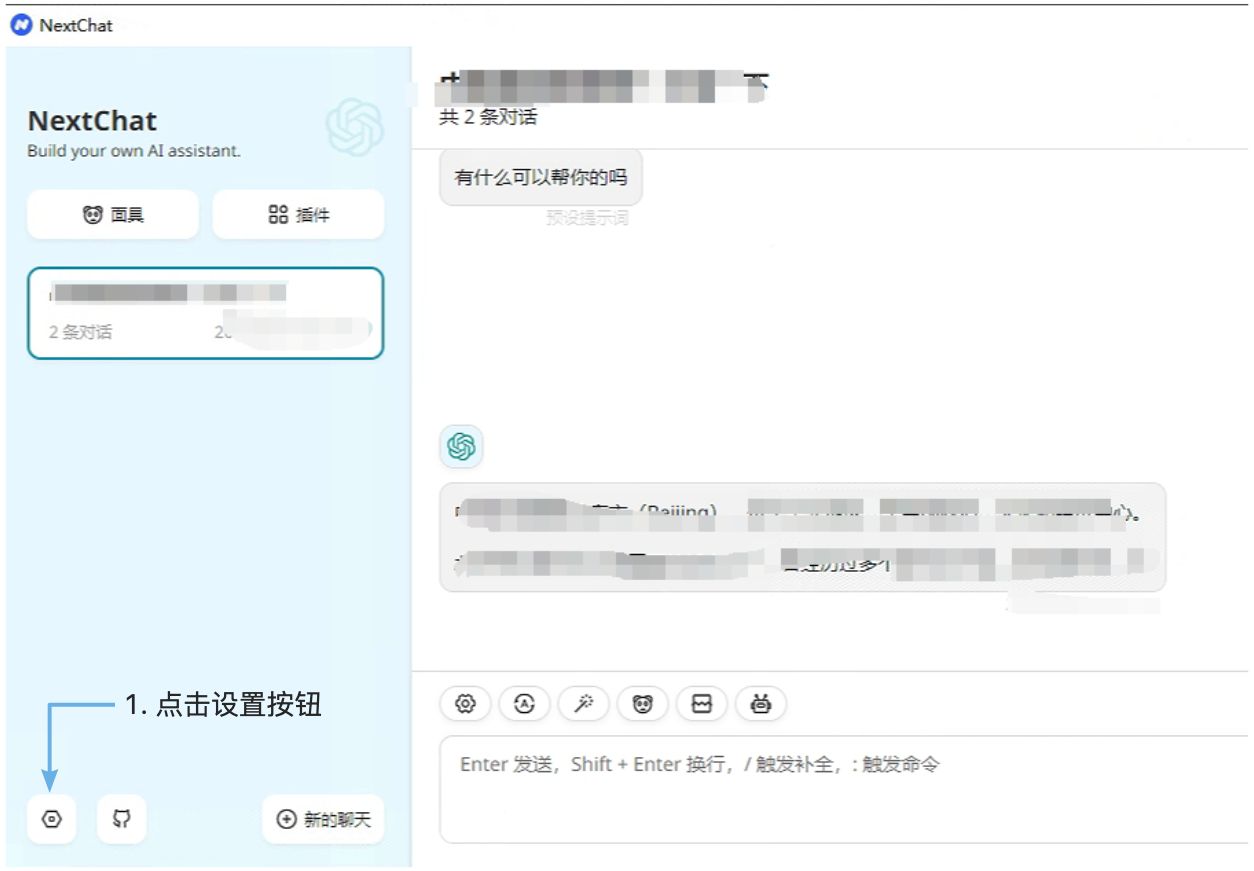
设置渠道信息:
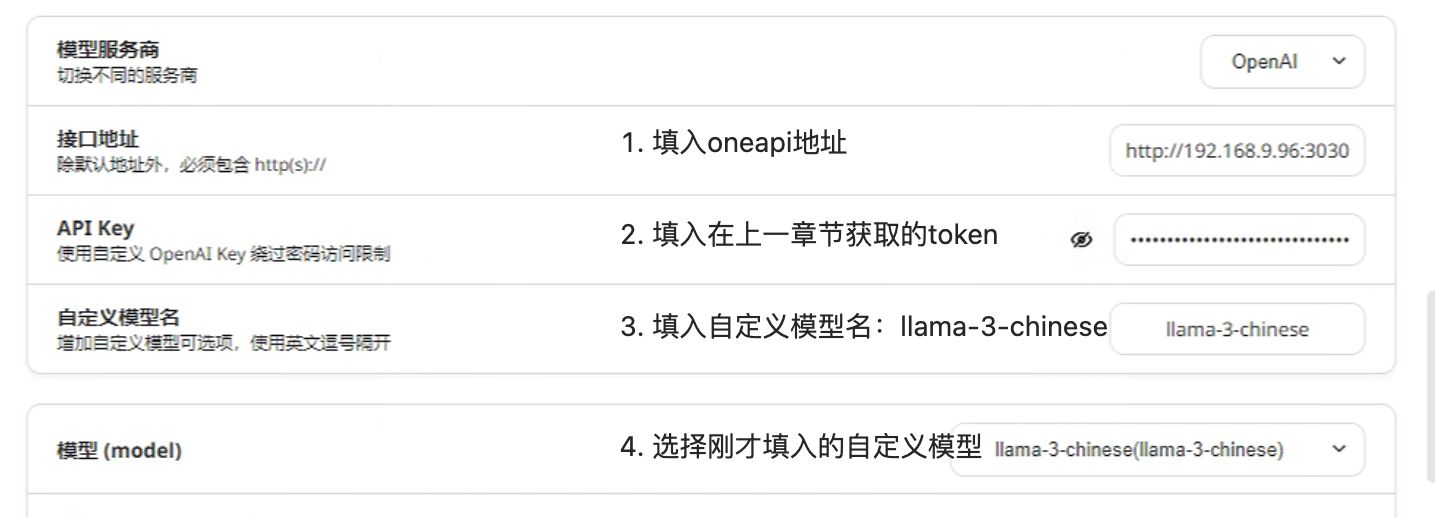
双渠道可用
我们输入同样的问题两次,可以观察回答一次慢,一次快,说明是第一次是调用了CPU渠道,第二次是调用了GPU渠道,您在测试时,有可能是第一次快,第一次慢,是正常的现象。
CPU可用GPU不可用
我们切换到GPU渠道的命令行运行界面:
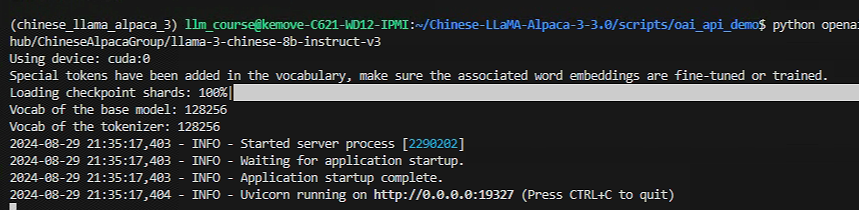
我们按Ctrl+c结束掉GPU渠道,如下所示:
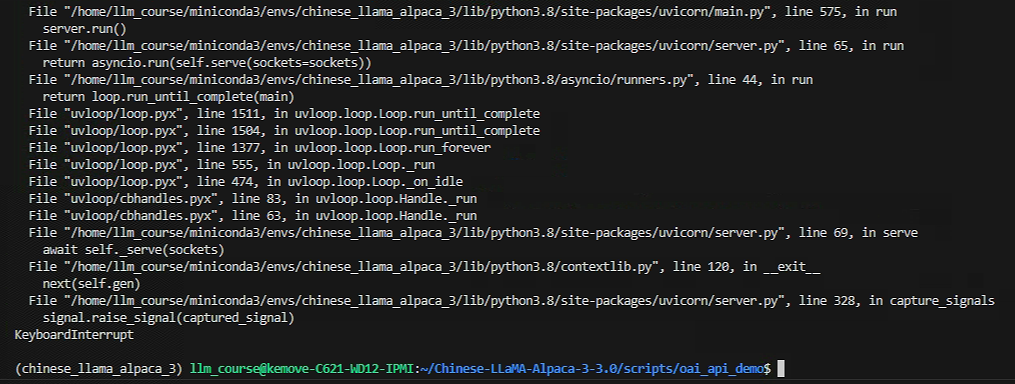
我们再次回到ChatGPTNextWeb窗口,发送问题,依然可以得到回答,只是回答得非常慢,说明CPU渠道正在提供服务,我们到oneapi的渠道页面,对gpu渠道进行测试,应该会得到如下信息:

GPU可用CPU不可用
我们回到GPU渠道的命令行界面,再次启动GPU渠道服务:

然后切换到CPU渠道命令行页面,按Ctrl+c结束掉CPU渠道,如下所示:

我们再次回到ChatGPTNextWeb窗口,发送问题,依然可以得到回答,这次的回答非常快,说明GPU渠道正在提供服务,我们到oneapi的渠道页面,对cpu渠道进行测试,应该会得到如下信息:
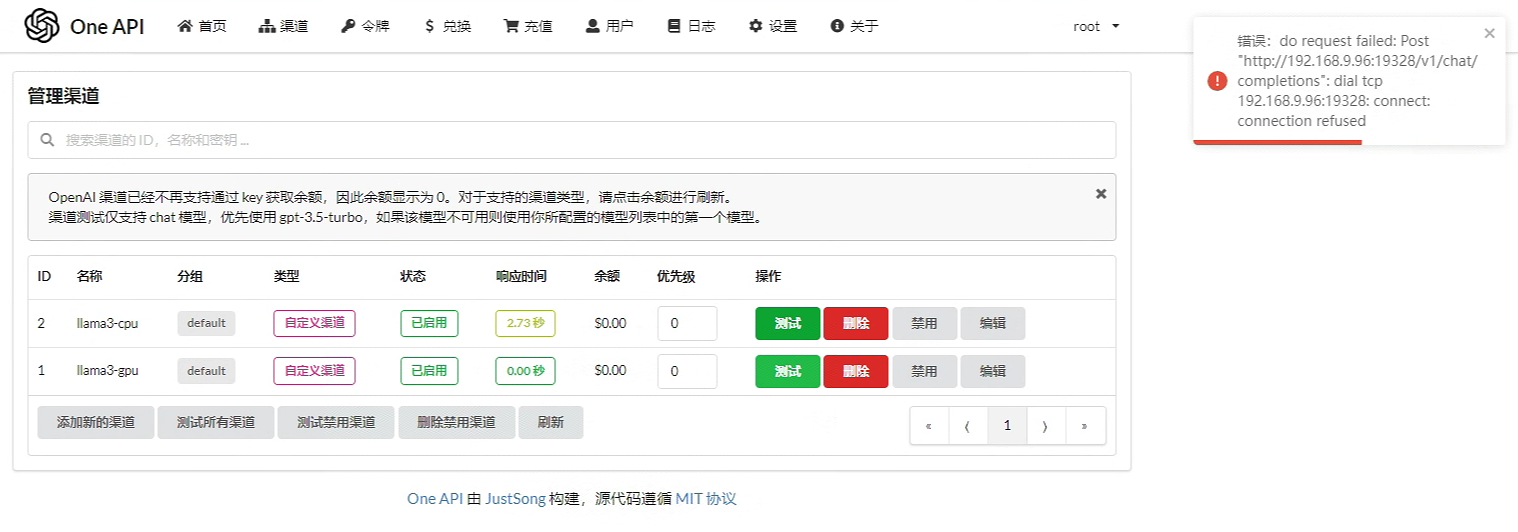
常见问题
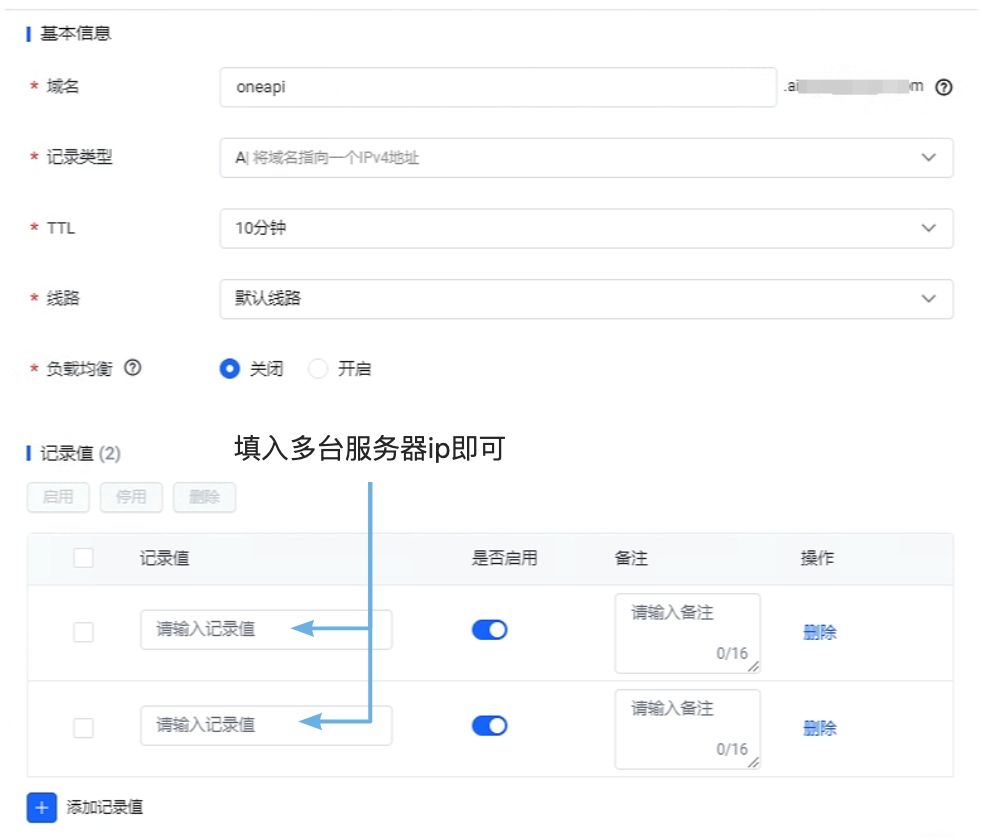
oneapi怎么做到高可用
以火山引擎为例,我们可以在多台ECS(云服务器)中部署oneapi,然后设置一个域名映射到多个ip即可:
原文地址:https://blog.csdn.net/fanghailiang2016/article/details/142722377
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!