记一次Flink通过Kafka写入MySQL的过程
一、前言
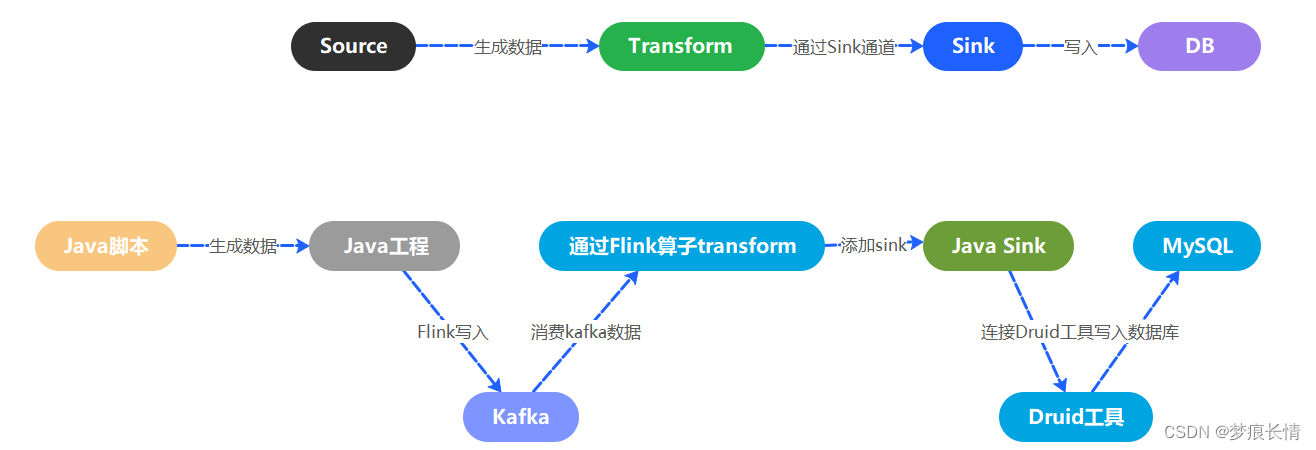
总体思路:source -->transform -->sink ,即从source获取相应的数据来源,然后进行数据转换,将数据从比较乱的格式,转换成我们需要的格式,转换处理后,然后进行sink功能,也就是将数据写入的相应的数据库DB中或者写入Hive的HDFS文件存储。
思路:
pom部分放到最后面。
二、方案及代码实现
2.1 Source部分
Source部分构建一个web对象用于保存数据等操作,代码如下:
package com.lzl.flink;
import java.util.Date;
/**
* @author lzl
* @create 2024-01-18 12:19
* @name pojo
*/
public class Web {
private String uuid;
private String ip;
private String area;
private String web;
private String operate;
private Date createDate;
public String getArea() {
return area;
}
public String getIp() {
return ip;
}
public String getOperate() {
return operate;
}
public String getUuid() {
return uuid;
}
public String getWeb() {
return web;
}
public Date getCreateDate() {
return createDate;
}
public void setArea(String area) {
this.area = area;
}
public void setIp(String ip) {
this.ip = ip;
}
public void setOperate(String operate) {
this.operate = operate;
}
public void setUuid(String uuid) {
this.uuid = uuid;
}
public void setWeb(String web) {
this.web = web;
}
public void setCreateDate(Date createDate) {
this.createDate = createDate;
}
}
将生成的数据转化为JSON格式,测试如下:
public static void webDataProducer() throws Exception{
//构建web对象,在ip为10.117后面加两个随机数
int randomInt1 = RandomUtils.nextInt(1,255);
int randomInt2 = RandomUtils.nextInt(1,999);
int randomInt3 = RandomUtils.nextInt(1,99999);
List<String> areas = Arrays.asList("深圳", "广州", "上海", "北京", "武汉", "合肥", "杭州", "南京");
List<String> webs = Arrays.asList("www.taobao.com","www.baidu.com","www.jd.com","www.weibo.com","www.qq.com","www.weixin.com","www.360.com","www.lzl.com","www.xiaomi.com");
List<String> operates = Arrays.asList("register","view","login","buy","click","comment","jump","care","collect");
Web web = new Web(); //实例化一个web对象,并向对象中放入数据
web.setUuid("uid_" + randomInt3);
web.setIp("10.110." + randomInt1 +"." + randomInt2);
web.setArea(getRandomElement(areas));
web.setWeb(getRandomElement(webs));
web.setOperate(getRandomElement(operates));
web.setCreateDate(new Date());
// 转换成JSON格式
String webJson = JSON.toJSONString(web);
System.out.println(webJson); //打印出来看看效果
}
//构建一个从列表里面任意筛选一个元素的函数方法
public static <T> T getRandomElement(List<T> list) {
Collections.shuffle(list);
return list.get(0);
}
public static void main(String[] args) {
while (true) {
try {
// 每三秒写一条数据
TimeUnit.SECONDS.sleep(3);
webDataProducer();
} catch (Exception e) {
e.printStackTrace();
}
}
}
执行测试结果如下:
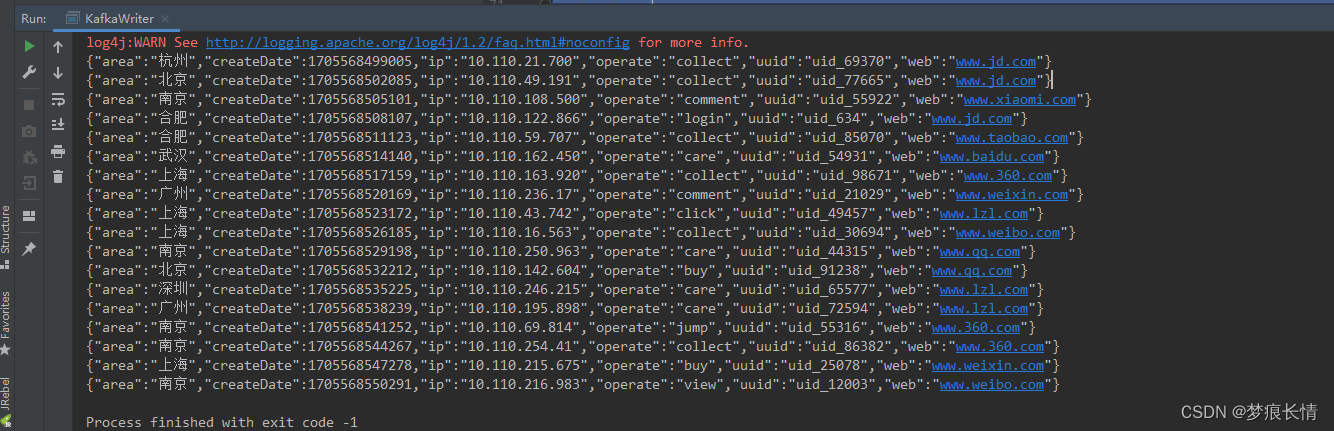
至此Source部分结束~~~~!!!!!!
2.2 Transform_1部分
2.2.1 写入kafka方法函数:
package com.lzl.flink;
import com.alibaba.fastjson.JSON;
import org.apache.commons.lang3.RandomUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.*;
import java.util.concurrent.TimeUnit;
/**
* @author lzl
* @create 2024-01-18 12:18
* @name KafkaWriter
*/
public class KafkaWriter {
//kafka集群列表
public static final String BROKER_LIST = "cdh39:9092,cdh40:9092,cdh41:9092";
//kafka的topic
public static final String TOPIC_WEB = "web";
//kafka序列化的方式,采用字符串的形式
public static final String KEY_SERIALIZER = "org.apache.kafka.common.serialization.StringSerializer";
//value的序列化方式
public static final String VALUE_SERIALIZER = "org.apache.kafka.common.serialization.StringSerializer";
public static void writeToKafka() throws Exception {
Properties props = new Properties(); //实例化一个Properties
props.put("bootstrap.servers", BROKER_LIST);
props.put("key.serializer", KEY_SERIALIZER);
props.put("value.serializer", VALUE_SERIALIZER);
// 构建Kafka生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 将web生成的数据发送给kafka的记录
String webDataJson = webDataProducer();
ProducerRecord<String,String> record = new ProducerRecord<String,String>(TOPIC_WEB,null,null,webDataJson);
// 发送到缓存
producer.send(record);
System.out.println("向kafka发送数据:" + webDataJson);
producer.flush();
}
public static void main(String[] args) {
while (true) {
try {
// 每三秒写一条数据
TimeUnit.SECONDS.sleep(3);
writeToKafka();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.2.2 建立 web的topic:

启动程序测试:
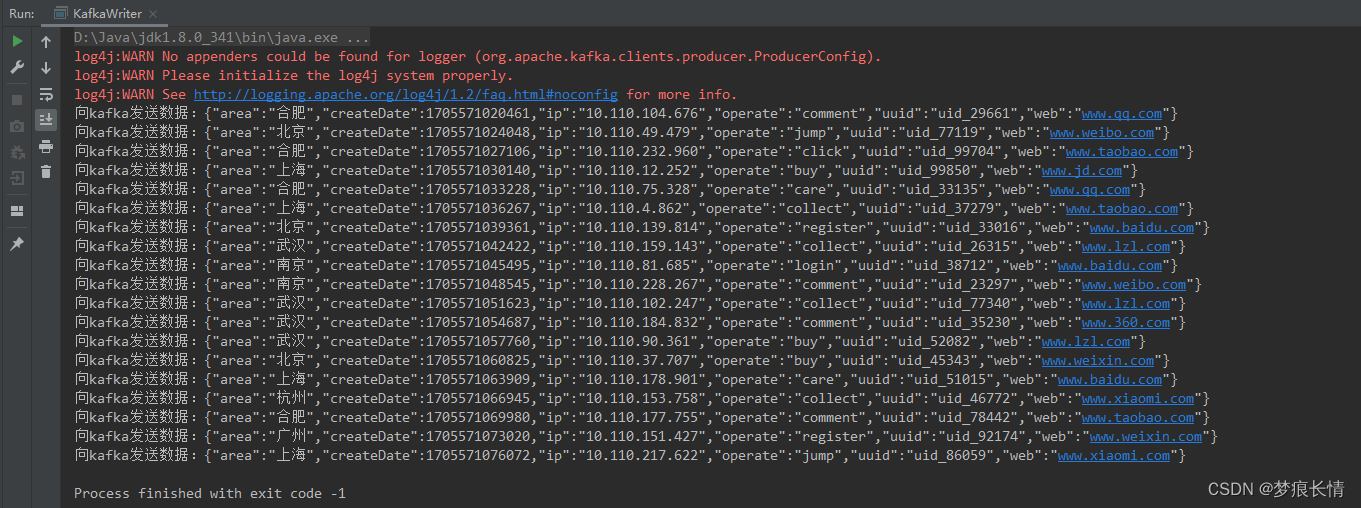
2.2.3 消费kafka看看是否有数据?
[root@cdh39 kafka]# bin/kafka-console-consumer.sh --bootstrap-server cdh39:9092 --from-beginning --topic web
{"area":"合肥","createDate":1705571020461,"ip":"10.110.104.676","operate":"comment","uuid":"uid_29661","web":"www.qq.com"}
{"area":"北京","createDate":1705571024048,"ip":"10.110.49.479","operate":"jump","uuid":"uid_77119","web":"www.weibo.com"}
{"area":"合肥","createDate":1705571027106,"ip":"10.110.232.960","operate":"click","uuid":"uid_99704","web":"www.taobao.com"}
{"area":"上海","createDate":1705571030140,"ip":"10.110.12.252","operate":"buy","uuid":"uid_99850","web":"www.jd.com"}
{"area":"合肥","createDate":1705571033228,"ip":"10.110.75.328","operate":"care","uuid":"uid_33135","web":"www.qq.com"}
{"area":"上海","createDate":1705571036267,"ip":"10.110.4.862","operate":"collect","uuid":"uid_37279","web":"www.taobao.com"}
{"area":"北京","createDate":1705571039361,"ip":"10.110.139.814","operate":"register","uuid":"uid_33016","web":"www.baidu.com"}
{"area":"武汉","createDate":1705571042422,"ip":"10.110.159.143","operate":"collect","uuid":"uid_26315","web":"www.lzl.com"}
{"area":"南京","createDate":1705571045495,"ip":"10.110.81.685","operate":"login","uuid":"uid_38712","web":"www.baidu.com"}
{"area":"南京","createDate":1705571048545,"ip":"10.110.228.267","operate":"comment","uuid":"uid_23297","web":"www.weibo.com"}
{"area":"武汉","createDate":1705571051623,"ip":"10.110.102.247","operate":"collect","uuid":"uid_77340","web":"www.lzl.com"}
{"area":"武汉","createDate":1705571054687,"ip":"10.110.184.832","operate":"comment","uuid":"uid_35230","web":"www.360.com"}
{"area":"武汉","createDate":1705571057760,"ip":"10.110.90.361","operate":"buy","uuid":"uid_52082","web":"www.lzl.com"}
{"area":"北京","createDate":1705571060825,"ip":"10.110.37.707","operate":"buy","uuid":"uid_45343","web":"www.weixin.com"}
{"area":"上海","createDate":1705571063909,"ip":"10.110.178.901","operate":"care","uuid":"uid_51015","web":"www.baidu.com"}
{"area":"杭州","createDate":1705571066945,"ip":"10.110.153.758","operate":"collect","uuid":"uid_46772","web":"www.xiaomi.com"}
{"area":"合肥","createDate":1705571069980,"ip":"10.110.177.755","operate":"comment","uuid":"uid_78442","web":"www.taobao.com"}
{"area":"广州","createDate":1705571073020,"ip":"10.110.151.427","operate":"register","uuid":"uid_92174","web":"www.weixin.com"}
{"area":"上海","createDate":1705571076072,"ip":"10.110.217.622","operate":"jump","uuid":"uid_86059","web":"www.xiaomi.com"}
至此,Transform_1部分结束~~~!!!!
2.3 Sink部分
创建一个MySQLSink,继承RichSinkFunction类。重载里边的open、invoke 、close方法,在执行数据sink之前先执行open方法,然后开始调用invoke方法,调用完之后最后执行close方法关闭资源。即在open里面创建数据库连接,然后调用invoke执行具体的数据库写入程序,完毕之后调用close关闭和释放资源。这里要继承flink的RichSinkFunction接口。代码如下:
package com.lzl.flink;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.sql.Timestamp;
import java.util.logging.Logger;
/**
* @author lzl
* @create 2024-01-22 15:30
* @name MySqlToPojoSink
*/
public class MySqlToPojoSink extends RichSinkFunction<Web> {
private static final Logger log = Logger.getLogger(MySqlToPojoSink.class.getName());
private static final long serialVersionUID = 1L;
private Connection connection = null;
private PreparedStatement ps = null;
private String tableName = "web";
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
log.info("获取数据库连接");
// 通过Druid获取数据库连接,准备写入数据库
connection = DbUtils.getConnection();
// 插入数据库的语句 因为我们封装的pojo的类型为PojoType<com.lzl.flink.Web, fields = [area: String, createDate: Date, ip: String, operate: String, uuid: String, web: String]>
String insertQuery = "INSERT INTO " + tableName + "(time,ip,uid,area,web,operate) VALUES (?,?,?,?,?,?)" ;
// 执行插入语句
ps = connection.prepareStatement(insertQuery);
}
// 重新关闭方法。 关闭并释放资源
@Override
public void close() throws Exception {
super.close();
if(connection != null) {
connection.close();
}
if (ps != null ) {
ps.close();
}
}
// 重写invoke方法
@Override
public void invoke(Web value,Context context) throws Exception {
//组装数据,执行插入操作
ps.setTimestamp(1, new Timestamp(value.getCreateDate().getTime()));
ps.setString(2,value.getIp());
ps.setString(3, value.getUuid());
ps.setString(4, value.getArea());
ps.setString(5, value.getWeb());
ps.setString(6, value.getOperate());
ps.addBatch();
// 一次性写入
int[] count = ps.executeBatch();
System.out.println("成功写入MySQL数量:" + count.length);
}
}
特别说明:从kafka读取到的内容是String,里面包含JSON格式。本文是先将它封装成Pojo对象,然后在Sink这里解析它的Value。(开始是尝试通过apply算子将它转换为List,但是失败了(时间有限,后续再弄),最后是通过map算子)
至此,Sink部分结束~!
2.4 Transform_2部分。消费kafka 数据,添加Sink。
package com.lzl.flink;
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/**
* @author lzl
* @create 2024-01-19 8:49
* @name DataSourceFromKafka
*/
public class DataSourceFromKafka {
public static void transformFromKafka() throws Exception {
// 构建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//kafka 配置
Properties prop = new Properties();
prop.put("bootstrap.servers", KafkaWriter.BROKER_LIST);
prop.put("zookeeper.connect", "cdh39:2181");
prop.put("group.id", KafkaWriter.TOPIC_WEB);
prop.put("key.serializer", KafkaWriter.KEY_SERIALIZER);
prop.put("value.serializer", KafkaWriter.VALUE_SERIALIZER);
prop.put("auto.offset.reset", "earliest");
// 建立流数据源
DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer<String>(
KafkaWriter.TOPIC_WEB,
new SimpleStringSchema(),
prop
)).setParallelism(1); // 单线程打印,控制台不乱序,不影响结果
SingleOutputStreamOperator<Web> webStream = env.addSource(new FlinkKafkaConsumer<>(
"web",
new SimpleStringSchema(),
prop
)).setParallelism(1)
.map(string-> JSON.parseObject(string,Web.class));
webStream.addSink(new MySqlToPojoSink());
env.execute();
}
public static void main(String[] args) throws Exception {
while (true) {
try {
// 每1毫秒写一条数据
TimeUnit.MILLISECONDS.sleep(1);
transformFromKafka();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
如果要设置空值报错异常,或者排除空值可以:
package com.lzl.flink;
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class DataSourceFromKafka {
public static void transformFromKafka() throws Exception {
// 构建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//checkpoint设置
//每隔10s进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(10000);
//设置模式为:exactly_one,仅一次语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//确保检查点之间有1s的时间间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
//检查点必须在10s之内完成,或者被丢弃【checkpoint超时时间】
env.getCheckpointConfig().setCheckpointTimeout(10000);
//同一时间只允许进行一次检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//表示一旦Flink程序被cancel后,会保留checkpoint数据,以便根据实际需要恢复到指定的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend,将检查点保存在hdfs上面,默认保存在内存中。先保存到resources目录下
env.setStateBackend(new FsStateBackend("D:java//Flink1.17//src//main//resources"));
// kafka 配置
Properties prop = new Properties();
prop.put("bootstrap.servers", KafkaWriter.BROKER_LIST);
prop.put("zookeeper.connect", "cdh39:2181");
prop.put("group.id", KafkaWriter.TOPIC_WEB);
prop.put("key.serializer", KafkaWriter.KEY_SERIALIZER);
prop.put("value.serializer", KafkaWriter.VALUE_SERIALIZER);
prop.put("auto.offset.reset", "earliest")
DataStreamSource<String> webStream = env.addSource(new FlinkKafkaConsumer<>(
"web",
new SimpleStringSchema(),
prop
)).setParallelism(1);
//使用process算子 排除空值
DataStream<Web> processData = webStream.process(new ProcessFunction<String, Web>() {
@Override
public void processElement(String s, Context context, Collector<Web> collector) throws Exception {
try {
Web webs = JSON.parseObject(s, Web.class);
if (webs != null) {
collector.collect(webs);
}
} catch (Exception e) {
System.out.println("有空值数据");
}
}
});
processData.addSink(new MySqlToPojoSink());
env.execute();
}
public static void main(String[] args) throws Exception {
while (true) {
try {
// 每1毫秒写一条数据
TimeUnit.MILLISECONDS.sleep(1);
transformFromKafka();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
至此,Transfrom结束~!
2.5 DB部分(这部分可以先做,或者放到前面,因为需要测试)
本次的DB演示采用常规的MySQL数据库。采用Druid工具连接。
思路:创建一个数据库连接的工具,用于连接数据库。使用Druid工具,然后放入具体的Driver,Url,数据库用户名和密码,初始化连接数,最大活动连接数,最小空闲连接数也就是数据库连接池,创建好之后返回需要的连接。
package com.lzl.flink;
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
/**
* @author lzl
* @create 2024-01-18 17:58
* @name DbUtils
*/
public class DbUtils {
private static DruidDataSource dataSource;
public static Connection getConnection() throws Exception {
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://cdh129:3306/flink?useSSL=true");
dataSource.setUsername("root");
dataSource.setPassword("xxb@5196");
// 设置初始化连接数,最大连接数,最小闲置数
dataSource.setInitialSize(10);
dataSource.setMaxActive(50);
dataSource.setMinIdle(5);
// 返回连接
return dataSource.getConnection();
}
}
数据库建表语句:
CREATE TABLE `web_traffic_analysis` (
`time` varchar(64) DEFAULT NULL COMMENT '时间',
`ip` varchar(32) DEFAULT NULL COMMENT 'ip地址',
`uid` varchar(32) DEFAULT NULL COMMENT 'uuid',
`area` varchar(32) DEFAULT NULL COMMENT '地区',
`web` varchar(64) DEFAULT NULL COMMENT '网址',
`operate` varchar(32) DEFAULT NULL COMMENT '操作'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='网页流量分析表'
三、启动程序
开始本来是想将上面所有的功能都写成函数方法,然后单独开一个Main()主函数的入口,然后在主函数下面调用那些方法(生产数据、消费数据方法)。思路是借鉴python的:if name == ‘main’: 下调用很多的方法 。但实际执行过程,是先生成数据,然后将数据写入kafka,然后再消费数据,过程执行非常慢,这个方案被pass了。后来又想到多线程方案,一个线程跑生产数据和写入数据,一个线程跑消费数据和写入下游数据库。这个方法是测试成功了,但是跑了一会儿就出现数据的积压和内存oom了,因为我设定的是1毫秒生产一条数据,写入kafka也需要一定的时间,加上电脑内存不足,有点卡,这个方案也被pass了。最后的方案是将生产数据打包放到集群去跑,本地电脑开启消费kafka数据写入MySQL数据库。结果如下:
生产数据:
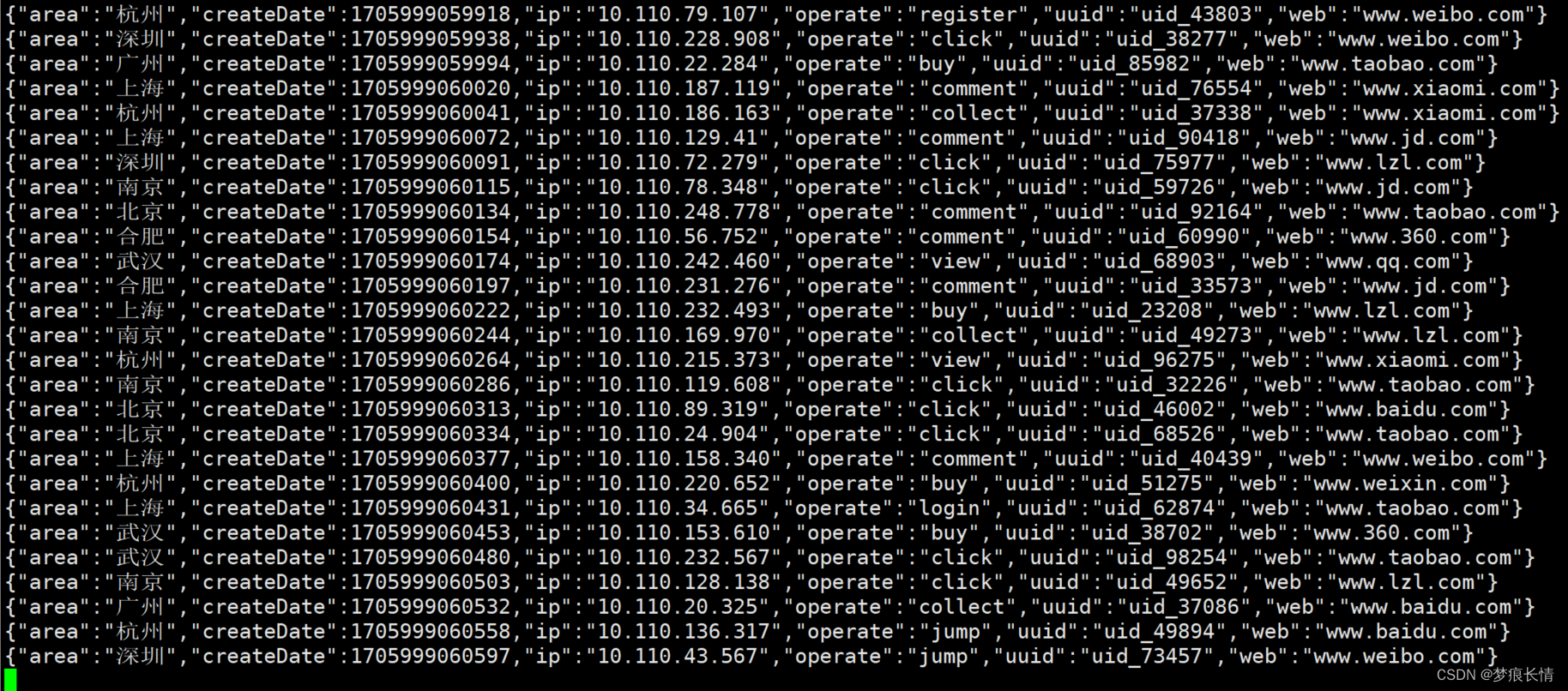
消费和写入数据库数据:
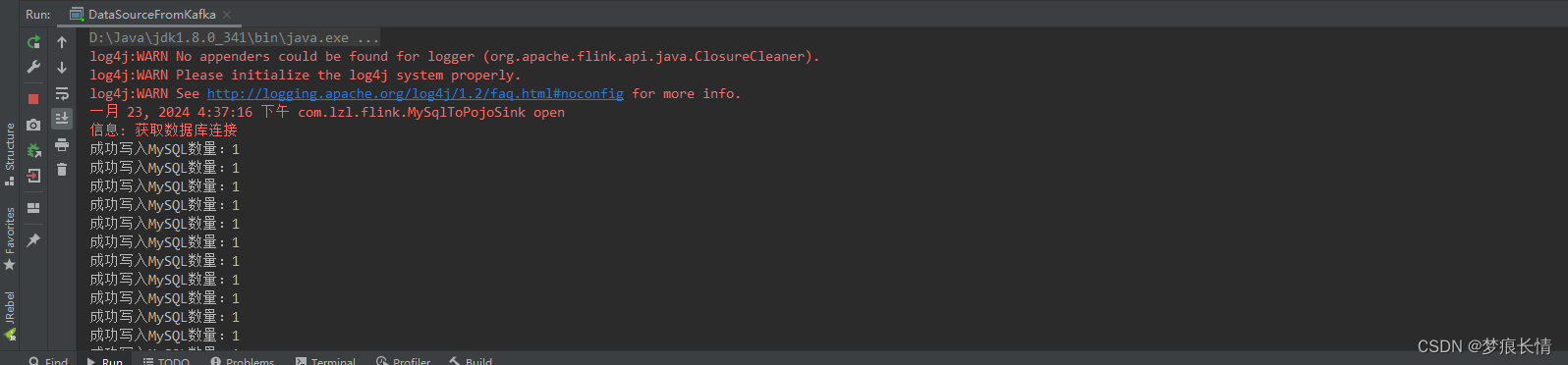
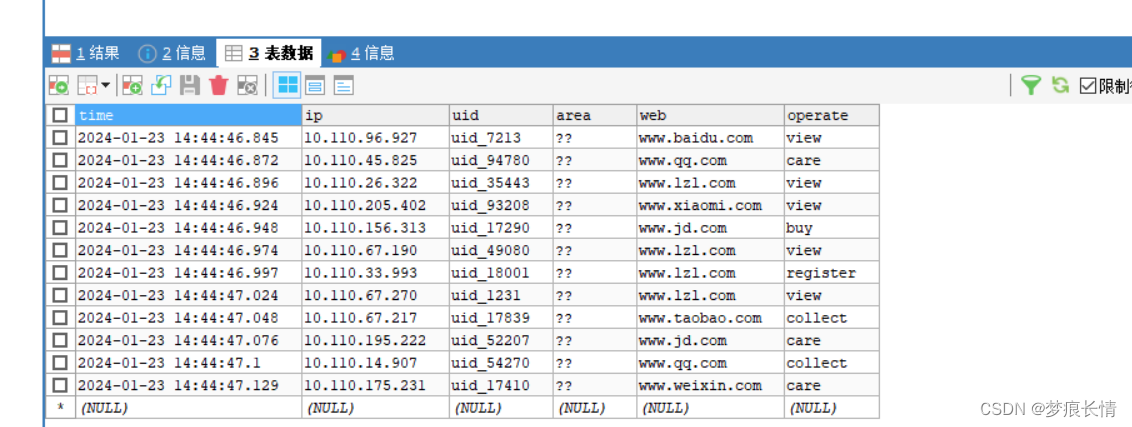
数据库数据:
至此结束,后面有其他想法再补充~!
多线程部分代码:
package com.example.study;
import com.lzl.flink.DataSourceFromKafka;
import com.lzl.flink.KafkaWriter;
public class WebApplication {
public static void main(String[] args) throws Exception {
// 创建线程1
Thread threadOne = new Thread(new Runnable() {
@Override
public void run() {
while (true){
try{
KafkaWriter kafkaWriter = new KafkaWriter();
kafkaWriter.webDataProducer();
kafkaWriter.writeToKafka();
System.out.println("线程一在跑~!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
// 创建线程2
Thread threadTwo = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
DataSourceFromKafka dataSourceFromKafka = new DataSourceFromKafka();
try {
dataSourceFromKafka.transformFromKafka();
System.out.println("线程二在跑~!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
//启动线程
threadOne.start();
threadTwo.start();
Thread.sleep(5);
}
}
结果:
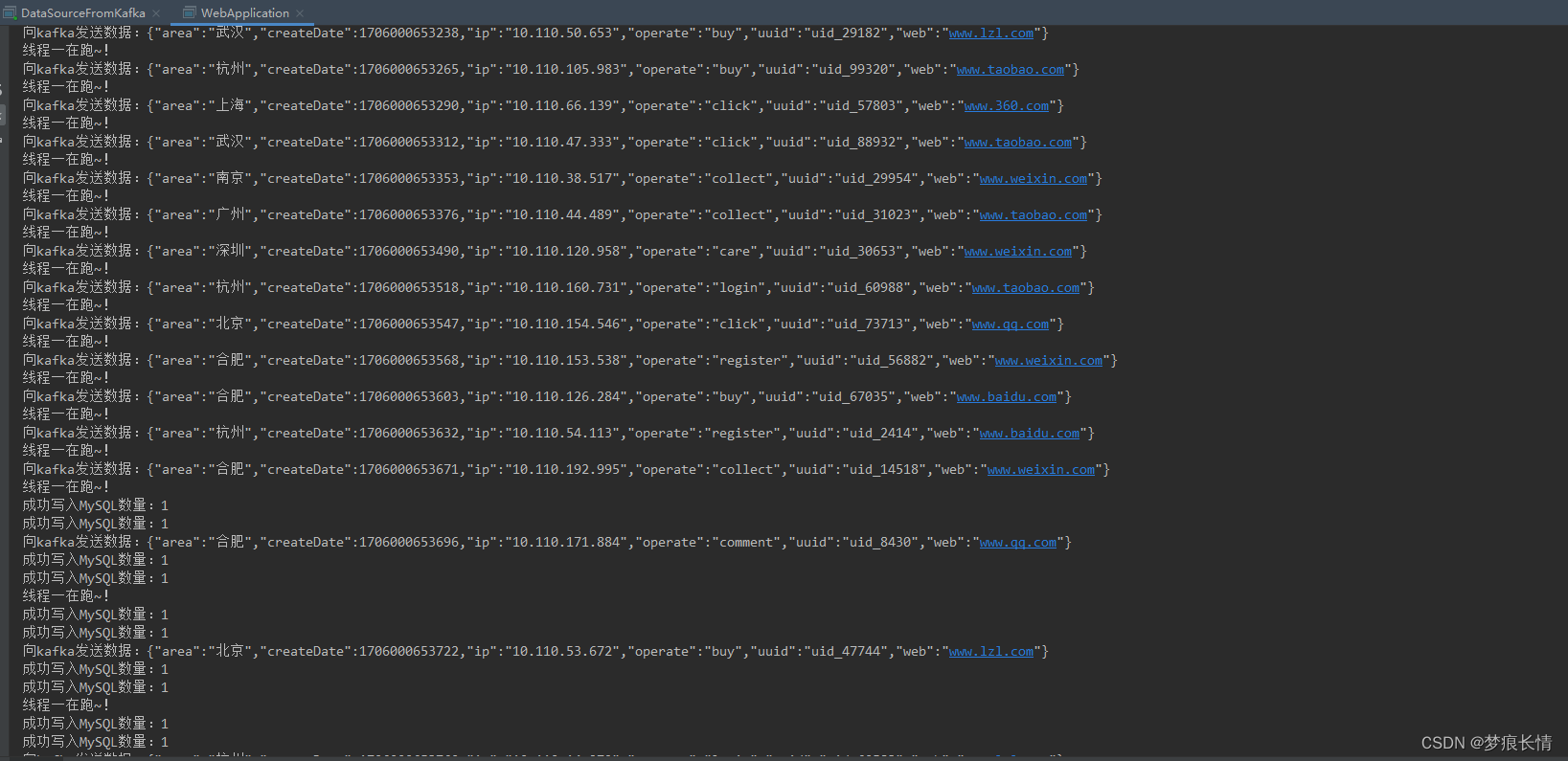
原文地址:https://blog.csdn.net/m0_48830183/article/details/135631295
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!