代码随想录算法训练营第64天:图论2[1]
代码随想录算法训练营第64天:图论2
广度优先搜索理论基础在深度优先搜索的讲解中,我们就讲过深度优先搜索和广度优先搜索的区别。
广搜(bfs)是一圈一圈的搜索过程,和深搜(dfs)是一条路跑到黑然后再回溯。
#广搜的使用场景
广搜的搜索方式就适合于解决两个点之间的最短路径问题。
因为广搜是从起点出发,以起始点为中心一圈一圈进行搜索,一旦遇到终点,记录之前走过的节点就是一条最短路。
当然,也有一些问题是广搜 和 深搜都可以解决的,例如岛屿问题,这类问题的特征就是不涉及具体的遍历方式,只要能把相邻且相同属性的节点标记上就行。 (我们会在具体题目讲解中详细来说)
#广搜的过程
上面我们提过,BFS是一圈一圈的搜索过程,但具体是怎么一圈一圈来搜呢。
我们用一个方格地图,假如每次搜索的方向为 上下左右(不包含斜上方),那么给出一个start起始位置,那么BFS就是从四个方向走出第一步。

如果加上一个end终止位置,那么使用BFS的搜索过程如图所示:
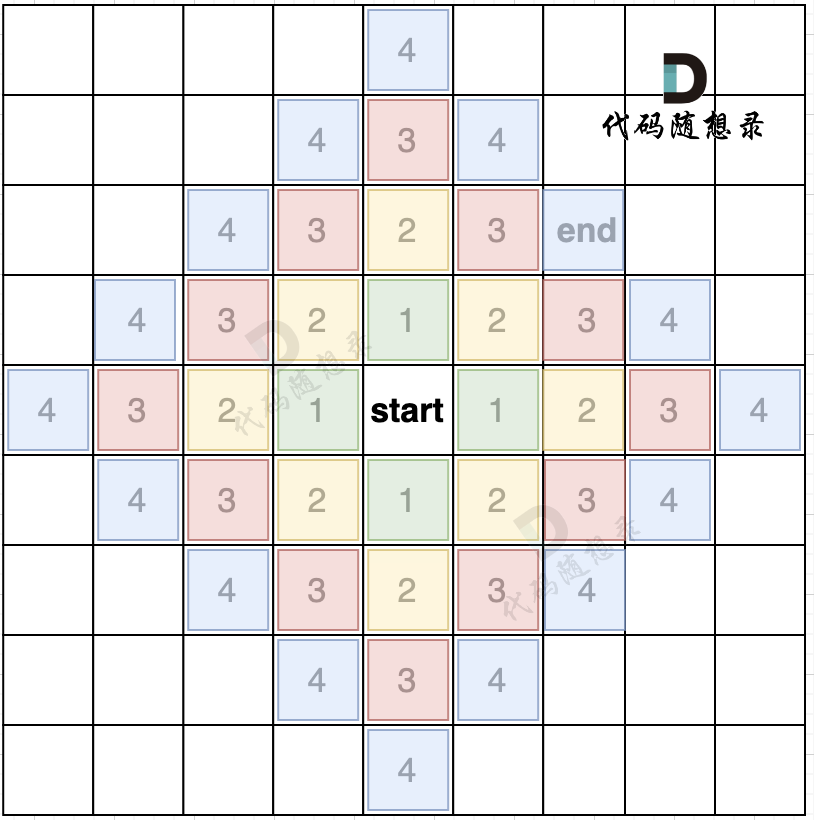
我们从图中可以看出,从start起点开始,是一圈一圈,向外搜索,方格编号1为第一步遍历的节点,方格编号2为第二步遍历的节点,第四步的时候我们找到终止点end。
正是因为BFS一圈一圈的遍历方式,所以一旦遇到终止点,那么一定是一条最短路径。
而且地图还可以有障碍,如图所示:

在第五步,第六步 我只把关键的节点染色了,其他方向周边没有去染色,大家只要关注关键地方染色的逻辑就可以。
从图中可以看出,如果添加了障碍,我们是第六步才能走到end终点。
只要BFS只要搜到终点一定是一条最短路径,大家可以参考上面的图,自己再去模拟一下。
#代码框架
大家应该好奇,这一圈一圈的搜索过程是怎么做到的,是放在什么容器里,才能这样去遍历。
很多网上的资料都是直接说用队列来实现。
其实,我们仅仅需要一个容器,能保存我们要遍历过的元素就可以,那么用队列,还是用栈,甚至用数组,都是可以的。
用队列的话,就是保证每一圈都是一个方向去转,例如统一顺时针或者逆时针。
因为队列是先进先出,加入元素和弹出元素的顺序是没有改变的。
如果用栈的话,就是第一圈顺时针遍历,第二圈逆时针遍历,第三圈有顺时针遍历。
因为栈是先进后出,加入元素和弹出元素的顺序改变了。
那么广搜需要注意 转圈搜索的顺序吗? 不需要!
所以用队列,还是用栈都是可以的,但大家都习惯用队列了,所以下面的讲解用我也用队列来讲,只不过要给大家说清楚,并不是非要用队列,用栈也可以。
下面给出广搜代码模板,该模板针对的就是,上面的四方格的地图: (详细注释)
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que; // 定义队列
que.push({x, y}); // 起始节点加入队列
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
while(!que.empty()) { // 开始遍历队列里的元素
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
int curx = cur.first;
int cury = cur.second; // 当前节点坐标
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
if (!visited[nextx][nexty]) { // 如果节点没被访问过
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
}
}
}
}
#总结
当然广搜还有很多细节需要注意的地方,后面我会针对广搜的题目还做针对性的讲解。
因为在理论篇讲太多细节,可能会让刚学广搜的录友们越看越懵,所以细节方面针对具体题目在做讲解。
本篇我们重点讲解了广搜的使用场景,广搜的过程以及广搜的代码框架。
其实在二叉树章节的层序遍历 **(opens new window)** 中,我们也讲过一次广搜,相当于是广搜在二叉树这种数据结构上的应用。
这次则从图论的角度上再详细讲解一次广度优先遍历。
相信看完本篇,大家会对广搜有一个基础性的认识,后面再来做对应的题目就会得心应手一些。
99. 岛屿数量
卡码网题目链接(ACM模式)(opens new window)
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例:
3
提示信息

根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
- 1 <= N, M <= 50
#思路
注意题目中每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
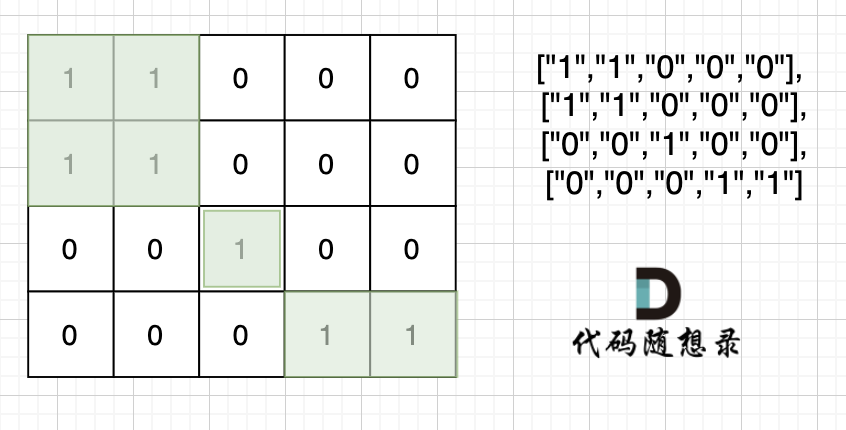
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:

这道题题目是 DFS,BFS,并查集,基础题目。
本题思路,是用遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
在遇到标记过的陆地节点和海洋节点的时候直接跳过。 这样计数器就是最终岛屿的数量。
那么如何把节点陆地所能遍历到的陆地都标记上呢,就可以使用 DFS,BFS或者并查集。
#深度优先搜索
以下代码使用dfs实现,如果对dfs不太了解的话,建议按照代码随想录的讲解顺序学习。
C++代码如下:
// 版本一
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {
for (int i = 0; i < 4; i++) {
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) { // 没有访问过的 同时 是陆地的
visited[nextx][nexty] = true;
dfs(grid, visited, nextx, nexty);
}
}
}
int main() {
int n, m;
cin >> n >> m;
vector<vector<int>> grid(n, vector<int>(m, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> grid[i][j];
}
}
vector<vector<bool>> visited(n, vector<bool>(m, false));
int result = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (!visited[i][j] && grid[i][j] == 1) {
visited[i][j] = true;
result++; // 遇到没访问过的陆地,+1
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
}
}
}
cout << result << endl;
}
很多录友可能有疑惑,为什么 以上代码中的dfs函数,没有终止条件呢? 感觉递归没有终止很危险。
其实终止条件 就写在了 调用dfs的地方,如果遇到不合法的方向,直接不会去调用dfs。
当然也可以这么写:
// 版本二
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {
if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水
visited[x][y] = true; // 标记访问过
for (int i = 0; i < 4; i++) {
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
dfs(grid, visited, nextx, nexty);
}
}
int main() {
int n, m;
cin >> n >> m;
vector<vector<int>> grid(n, vector<int>(m, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> grid[i][j];
}
}
vector<vector<bool>> visited(n, vector<bool>(m, false));
int result = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (!visited[i][j] && grid[i][j] == 1) {
result++; // 遇到没访问过的陆地,+1
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
}
}
}
cout << result << endl;
}
这里大家应该能看出区别了,无疑就是版本一中 调用dfs 的条件判断 放在了 版本二 的 终止条件位置上。
版本一的写法是 :下一个节点是否能合法已经判断完了,传进dfs函数的就是合法节点。
版本二的写法是:不管节点是否合法,上来就dfs,然后在终止条件的地方进行判断,不合法再return。
理论上来讲,版本一的效率更高一些,因为避免了 没有意义的递归调用,在调用dfs之前,就做合法性判断。 但从写法来说,可能版本二 更利于理解一些。(不过其实都差不太多)
很多同学看了同一道题目,都是dfs,写法却不一样,有时候有终止条件,有时候连终止条件都没有,其实这就是根本原因,两种写法而已。
#总结
其实本题是 dfs,bfs 模板题,但正是因为是模板题,所以大家或者一些题解把重要的细节都很忽略了,我这里把大家没注意的但以后会踩的坑 都给列出来了。
本篇我只给出的dfs的写法,大家发现我写的还是比较细的,那么后面我再单独给出本题的bfs写法,虽然是模板题,但依然有很多注意的点,敬请期待!
99. 岛屿数量
卡码网题目链接(ACM模式)(opens new window)
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例:
3
提示信息
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
- 1 <= N, M <= 50
#思路
注意题目中每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
这道题题目是 DFS,BFS,并查集,基础题目。
本题思路:遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
再遇到标记过的陆地节点和海洋节点的时候直接跳过。 这样计数器就是最终岛屿的数量。
那么如果把节点陆地所能遍历到的陆地都标记上呢,就可以使用 DFS,BFS或者并查集。
#广度优先搜索
如果不熟悉广搜,建议先看 广搜理论基础。
不少同学用广搜做这道题目的时候,超时了。 这里有一个广搜中很重要的细节:
根本原因是只要 加入队列就代表 走过,就需要标记,而不是从队列拿出来的时候再去标记走过。
很多同学可能感觉这有区别吗?
如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。

超时写法 (从队列中取出节点再标记,注意代码注释的地方)
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que;
que.push({x, y});
while(!que.empty()) {
pair<int ,int> cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
visited[curx][cury] = true; // 从队列中取出在标记走过
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {
que.push({nextx, nexty});
}
}
}
}
加入队列 就代表走过,立刻标记,正确写法: (注意代码注释的地方)
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que;
que.push({x, y});
visited[x][y] = true; // 只要加入队列,立刻标记
while(!que.empty()) {
pair<int ,int> cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {
que.push({nextx, nexty});
visited[nextx][nexty] = true; // 只要加入队列立刻标记
}
}
}
}
以上两个版本其实,其实只有细微区别,就是 visited[x][y] = true; 放在的地方,这取决于我们对 代码中队列的定义,队列中的节点就表示已经走过的节点。 所以只要加入队列,立即标记该节点走过。
本题完整广搜代码:
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que;
que.push({x, y});
visited[x][y] = true; // 只要加入队列,立刻标记
while(!que.empty()) {
pair<int ,int> cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) {
que.push({nextx, nexty});
visited[nextx][nexty] = true; // 只要加入队列立刻标记
}
}
}
}
int main() {
int n, m;
cin >> n >> m;
vector<vector<int>> grid(n, vector<int>(m, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> grid[i][j];
}
}
vector<vector<bool>> visited(n, vector<bool>(m, false));
int result = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (!visited[i][j] && grid[i][j] == 1) {
result++; // 遇到没访问过的陆地,+1
bfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
}
}
}
cout << result << endl;
}
原文地址:https://blog.csdn.net/2302_79934729/article/details/140148737
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!