Spark SQL【Java API】
前言
之前对 Spark SQL 的影响一直停留在 DSL 语法上面,感觉可以用 SQL 表达的,没有必要用 Java/Scala 去写,但是面试一段时间后,发现不少公司还是在用 SparkSQL 的,京东也在使用 Spark On Hive 而不是我以为的 Hive On Spark,经过一番了解之后发现,确实 Spark SQL 要比 HQL 灵活太多了。所以必须学学 SparkSQL(我喜欢用 Java 版本,和 Scala 执行速度一样,只不过代码复杂了点,对我来说也没多复杂),之后用 SparkSQL 对之前的离线项目实现一遍。
1、Spark SQL 介绍
Hive 是目前事实上离线数仓的标准,它的缺点是底层使用的 MR 引擎,所以执行稍微复杂点的 SQL 就非常慢,不过它支持更换执行引擎,换成 Spark/Tez 就会好很多,而我们实际开发中也几乎不会有人去用 MR 引擎的 Hive 去跑,一般都是 Hive on Spark 或者 Spark on Hive 的方式。
1.1、SparkSQL 的特点
正如官网描述:Spark SQL 是 Apache Spark 的一个用于处理结构化数据的模块。(而不是非结构化)
1.1.1、集成

Spark SQL 将 SQL 和 Spark 程序无缝衔接,它允许我们在 Spark 程序中使用 SQL 或者 DataFrame API 来查询结构化数据。
1.1.2、统一的数据访问

这也是 Spark SQL 优于 Hive 的一大原因,它支持很多的数据源(比如 hive、avro、parquet、orc、json、csv、jdbc 等),我们可以通过 API 去访问这些数据源并且可以将通过 API 或者 SQL 这些不同的数据源连接在一起。
1.1.3、集成 Hive

Spark SQL 可以使用 Hive 的元数据库、SerDes 和 UDFs,我们可以在现有的数据仓库上运行 SQL 或 HiveQL 查询。
1.1.4、标准连接

这里说的是 Spark SQL 的服务器模式为商业智能工具(比如 BI 工具)提供了工业标准的 JDBC/ODBC。
1.2、不同 API 的执行速度

可以看到,Python 在操作 RDD 时的速度要比 Java/Scala 慢几乎两倍多。
1.3、数据抽象
Spark SQL提供了两个新的抽象,分别是 DataFrame 和 Dataset;
Dataset是数据的分布式集合。是Spark 1.6中添加的一个新接口,它提供了RDDs的优点(强类型、使用强大lambda函数的能力)以及Spark SQL优化的执行引擎的优点。可以从 JVM 对象构造数据集(使用 createDataFrame 方法,参数是Java对象集合),然后使用函数转换(map、flatMap、filter等)操作数据集。数据集API可以在Scala和Java中使用。Python 和 R 并不支持Dataset API。
DataFrame 是组织成命名列的 Dataset。它在概念上相当于关系数据库中的表或 R/Python中的DataFrame,但在底层有更丰富的优化(这也是为什么 R/Python 操作 DataFrame 的效率能和 SQL、Java/Scala 差不多的原因)。DataFrame 可以从各种各样的数据源构建,例如: 结构化或半结构化数据文件(json、csv)、Hive中的表、外部数据库或现有的 rdd。DataFrame API 可以在Scala、Java、Python和 R 中使用。在Scala API中,DataFrame 只是 Dataset[Row] 的类型别名。而在Java API中,使用 Dataset<Row> 来表示DataFrame。
在Spark支持的语言中,只有Scala和Java是强类型的。因此,Python和R只支持无类型的DataFrame API。
1.3.1、DataFrame
DataFrame 可以比作一个表格或电子表格,它有行和列,每一列都有一个名称和数据类型。它提供了一种结构化的方式来存储和处理数据。
使用场景:DataFrame 非常适合处理结构化数据,也就是具有明确定义的模式的数据。它支持各种数据源,如 CSV 文件、数据库、JSON 等。DataFrame 提供了丰富的操作,如筛选、聚合、连接等,使得数据处理变得简单高效。当我们需要执行 SQL 查询或进行统计分析时,DataFrame 是首选的数据结构。
1.3.2、DataSet
DataSet 可以比作一个带有标签的盒子。每个数据集都包含一组对象,这些对象具有相同的类型,并且每个对象都有一组属性或字段。与 DataFrame 不同,DataSet 是类型安全的,这意味着 JVM 可以在编译时捕获类型错误。
使用场景:DataSet 适用于需要类型安全和对象操作的情况。它提供了更强大的类型检查和编译时错误检查,以及更丰富的函数式编程接口。当我们需要处理复杂的数据结构、需要执行对象转换或利用 Lambda 表达式等高级功能时,DataSet 是更好的选择。但是需要注意的是,DataSet 在某些情况下可能比 DataFrame 更复杂,并且可能需要更多的内存和处理时间。
1.3.3、DataFrame 和 DataSet 的对比
类型安全性
- DataFrame 不是类型安全的。它的每一行是一个Row对象,字段的类型是在运行时解析的。因此,如果在处理数据时类型不匹配,可能会遇到运行时错误。
- 相比之下,DataSet 是强类型的分布式集合。当你定义一个 DataSet 时,你需要为其提供一个case class(使用 Scala API 时),这个 case class定义了数据的结构。由于DataSet的每个元素都由这个 case class 的实例表示,因此每个字段的类型在编译时就是已知的。这提供了更好的类型安全性,允许在编译时捕获许多类型错误。
数据源和兼容性
- DataFrame可以很容易地从各种数据源中创建,如CSV文件、JSON、数据库等,并且它提供了与这些数据源的直接兼容性。
- DataSet也可以从这些数据源创建,但通常需要通过DataFrame作为中间步骤,或者需要更多的代码来定义数据的结构。
优化和性能:
DataFrame 和 DataSet在处理大量数据时都非常快,但有时候,DataFrame可能会因为它的结构更简单而得到更多的优化,跑得更快一些。但是同样对于 DataSet ,因为提前知道了每一列的数据类型,所以在某些情况下,它也可以进行优化,让处理速度更快。
1.4、Spark on Hive / Hive on Spark
1.4.1、Spark on Hive
Spark on Hive是Hive只作为存储角色,Spark负责sql解析优化,执行。这里可以理解为Spark通过Spark SQL使用Hive语句操作Hive表,底层运行的还是Spark RDD。具体步骤如下:
- 通过SparkSQL,加载Hive的配置文件,获取到Hive的元数据信息;
- 获取到Hive的元数据信息之后可以拿到Hive表的数据;
- 通过SparkSQL来操作Hive表中的数据。
1.4.2、Hive on Spark
与Spark on Hive不同,Hive on Spark则是Hive既作为存储又负责sql的解析优化,Spark负责执行。这里Hive的执行引擎变成了Spark,不再是MR。实现这个模式比Spark on Hive要麻烦得多,需要重新编译Spark和导入jar包。
1.4.3、性能对比
相比之下,Spark on Hive 应该是要更好一些,毕竟 Spark on Hive 更加 "原生",底层就是 RDD 计算,只有元数据用了Hive,对SQL的解析,转换,优化等都是Spark完成(而且 Spark SQL 相比 Hive 在执行计划上做了更多的优化)。而 Hive on Spark 只有计算引擎是Spark,前期解析,转换,优化等步骤都是 Hive 完成。
2、Spark SQL 编程
导入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
2.1、SparkSession
在 RDD 编程中,我们使用的是SparkContext 接口,但在 Spark SQL中,我们将使用SparkSession接口。Spark2.0 出现的 SparkSession 接口替代了 Spark 1.6 版本中的 SQLContext 和 HiveContext接口,来实现对数据的加载、转换、处理等功能。
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的
2.2、Spark SQL 语法
先创建一个 json 文件作为数据源:
{"name": "李大喜", "age": 20, "dept": "农民"}
{"name": "燕双鹰", "age": 20, "dept": "保安"}
{"name": "狄仁杰", "age": 40, "dept": "保安"}
{"name": "李元芳", "age": 40, "dept": "保安"}
{"name": "谢永强", "age": 20, "dept": "农民"}2.2.1、SQL 语法
package com.lyh;
import com.lyh.domain.User;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("test1");
// 2. 创建 SparkSession
SparkSession spark = SparkSession
.builder()
.config(conf)
.getOrCreate();
spark.sparkContext().setLogLevel("WARN"); // 只在 Spark Application 运行时有效
// 通过 json 文件创建 DataFrame
// 在 Java 的 API 中并没有 DataFrame 这种数据类型, DataSer<Row> 指的就是 DataFrame
Dataset<Row> lineDF = spark.read().json("src/main/resources/json/user.json");
lineDF.createOrReplaceTempView("users");
// 支持所有的hive sql语法,并且会使用spark的优化器
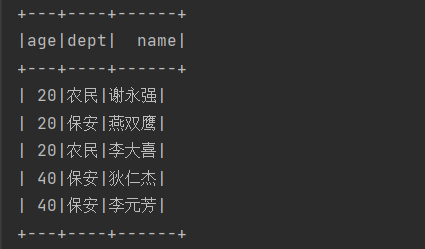
spark.sql("select * from users order by age").show();
// 关闭 SparkSession
spark.close();
}
}
运行结果:
2.2.2、DSL 语法
lineDF.select("*").orderBy("age").show();效果和上面是一样的,但是一般能用 SQL 就不用 DSL 。
2.3、自定义函数
2.3.1、UDF
一进一出(传一个参数进去,返回一个结果)
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.DataTypes;
import java.util.Locale;
import static org.apache.spark.sql.functions.udf;
public class MyUdf {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("udf").setMaster("local[*]");
SparkSession spark = SparkSession.builder().config(conf).getOrCreate();
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");
df.createOrReplaceTempView("users");
UserDefinedFunction up = udf((UDF1<String, String>) str -> str.toUpperCase(Locale.ROOT), DataTypes.StringType);
spark.udf().register("up",up);
spark.sql("SELECT up(name),age FROM users").show();
spark.close();
}
}上面,我们定义了一个函数,实现把英文全部大写,测试:

2.3.2、UDAF
输入多行,返回一行,一般和 groupBy 配合使用,其实就是自定义聚合函数。
- Spark3.x推荐使用extends Aggregator自定义UDAF,属于强类型的Dataset方式。
- Spark2.x使用extends UserDefinedAggregateFunction,属于弱类型的DataFrame
package com.lyh.udf;
import lombok.Data;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.Aggregator;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.DataTypes;
import java.io.Serializable;
import java.util.Locale;
import static org.apache.spark.sql.functions.udaf;
import static org.apache.spark.sql.functions.udf;
public class MyUdf {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("udaf").setMaster("local[*]");
SparkSession spark = SparkSession.builder().config(conf).getOrCreate();
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");
df.createOrReplaceTempView("users");
spark.udf().register("myavg",udaf(new MyAvg(),Encoders.LONG()));
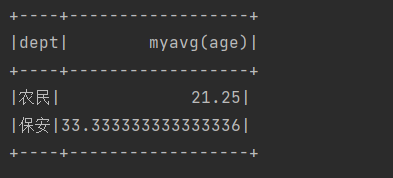
spark.sql("SELECT dept,myavg(age) FROM users group by dept").show();
spark.close();
}
@Data
public static class Buffer implements Serializable{
private Long sum;
private Long count;
public Buffer(){}
public Buffer(Long sum,Long count){
this.sum = sum;
this.count = count;
}
}
public static class MyAvg extends Aggregator<Long,Buffer,Double> {
@Override
public Buffer zero() {
return new Buffer(0L,0L);
}
@Override
public Buffer reduce(Buffer buffer, Long num) {
buffer.setSum(buffer.getSum() + num);
buffer.setCount(buffer.getCount()+1);
return buffer;
}
@Override
public Buffer merge(Buffer b1, Buffer b2) {
b1.setSum(b1.getSum()+b2.getSum());
b1.setCount(b1.getCount()+b2.getCount());
return b1;
}
@Override
public Double finish(Buffer reduction) {
return reduction.getSum().doubleValue()/reduction.getCount();
}
// 序列化缓冲区的数据
@Override
public Encoder<Buffer> bufferEncoder() {
// 用kryo进行优化
return Encoders.kryo(Buffer.class);
}
@Override
public Encoder<Double> outputEncoder() {
return Encoders.DOUBLE();
}
}
}Aggregator 有三个泛型参数,分别是输入类型,缓存类型和输出类型,需要重写的方法很好理解,其中, bufferEncoder 和 outputEncoder 这两个方法是用来序列化缓冲区和输出端的数据,这对于分布式处理环境尤为重要,因为数据需要在网络中传输或存储到磁盘上。
运行结果:
3、Spark SQL 数据的加载和保存
Spark SQL 会把读取进来的文件封装为一个 DataFrame 对象(DataSet<Row>),所以 Spark SQL 加载数据源的过程就是创建 DataFrame 的过程。
3.1、创建 DataFrame
这里省去公共的环境代码:
public class Main {
public static void main(String[] args) {
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("Spark Application名称");
// 2. 创建 SparkSession
SparkSession spark = SparkSession
.builder()
.config(conf)
.getOrCreate();
// 只在提交 Spark Application 时有效
spark.sparkContext().setLogLevel("WARN");
// 3. 业务代码
// 4. 关闭 sparkSession
spark.close();
}
}3.1.1、通过 JVM 对象创建
User user1 = new User("汤姆", 11L);
User user2 = new User("李大喜", 18L);
User user3 = new User("燕双鹰", 18L);
User user4 = new User("狄仁杰", 11L);
Dataset<Row> df = spark.createDataFrame(Arrays.asList(user1, user2, user3, user4), User.class);
df.show();这里的 df.show 就相当于注册了一张临时表然后 select * from 这张表。
运行结果:

3.1.2、csv 文件
注意:Spark 读取 csv 文件时,读进来的字段都是 String 类型,所以如果有需求需要把 csv 中的数据封装转为 Bean 的时候,对于任何类型的数据都必须使用 getString 来读取,读取进来再做转换。比如下面,我们把读取进来的 csv 文件使用 map 函数转为 dataset 再做查询
注意:通过 csv 读取进来的 DataFrame 并没有 schema 信息,也不能通过 as 方法转为 DataSet 方法,因为 DataFrame 的列名和类型都是 _c0 string , _c1 string ... 和 User 的属性名根本匹配不上,所以只能通过 map 函数来把 DataFrame 转为 DataSet ,这样它才有了类型信息。
// 加载 csv 文件
Dataset<Row> df = spark.read()
.option("seq", ",")
.option("header", false)
.csv("src/main/resources/csv/user.csv");
// 转为 dataset 展示
df.map(
(MapFunction<Row, User>) row -> new User(row.getString(0),Long.parseLong(row.getString(1)),row.getString(2)),
Encoders.bean(User.class)
).show();运行结果:

将结果写入到 csv 文件中:
写入到 csv 文件不能通过 DataFrame 直接写,因为现在它连 schema 都没有,sql 中的字段它都识别不了。所以必须先转为 DataSet 再去查询出结果写入到文件:
// 加载 csv 文件
Dataset<Row> df = spark.read()
.option("seq", ",")
.option("header", false)
.csv("src/main/resources/csv/user.csv");
df.printSchema();
// 不能这么转 因为 DataFrame 没有模式信息 字段名默认是 _c0,_c1 ... 和 User 的属性名完全匹配不上 会报错!
// Dataset<User> ds = df.as(Encoders.bean(User.class));
Dataset<User> ds = df.map(
(MapFunction<Row, User>) row -> new User(row.getString(0), Long.parseLong(row.getString(1)), row.getString(2)),
Encoders.bean(User.class)
);
ds.printSchema();
ds.createOrReplaceTempView("users");
spark.sql("SELECT CONCAT(name,'大侠') name, age FROM users WHERE age > 18")
.write()
.option("header",true)
.option("seq","\t")
.csv("output");运行结果:


3.1.3、json 文件
注意:Spark 在读取 json 文件时,默认把 int 类型的值当做 bigint ,如果我们使用 row.getInt 去解析时就会直接报错(因为是小转大),所以我们的 Bean 的整型应该升级为长整型 Long 才不会报错。此外,Spark 读取 json 文件后封装成的 Row 对象是以 json 的字段作为索引的(是根据索引的 ASCII 码进行排序之后再从 0 开始排的),而不是按照 json 文件中的字段顺序,这也是一个坑点。
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");
Dataset<User> ds = df.map(
(MapFunction<Row, User>) row -> new User(row.getString(2),row.getLong(0),row.getString(1)),
Encoders.bean(User.class)
);
ds.show();所以一般不会用上面的这种方式去读取 json,因为我们无法自己预估排序后的字段索引值。我们一般直接把 json 转为 DataFrame 之后立即转为 DataSet 进行操作,或者直接把 DataFrame 对象注册为临时表,然后使用 SQL 进行分析。
将结果写入到 json 文件:
下面我们把 json 读取进来解析为 DataFrame 之后直接注册为临时表——用户表,然后用 sql 进行分析(Spark SQL 支持 HQL 中的所有语法,所以这里试用一下窗口函数):
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");
df.createOrReplaceTempView("users");
spark.sql("SELECT name,ROW_NUMBER() OVER(PARTITION BY dept ORDER BY age) rk FROM users")
.write()
.json("users_rk");这里的 "user_rk" 是输出文件的目录名,最终会生成四个文件:两个 CRC 校验文件,一个 SUCCESS 和 生成的 json 文件。
运行结果:


我们这里直接用 DataFrame 来将分析出结果写入到 json 文件,但是上面的 csv 就不可以,因为 json 文件自带字段名,而字段类型 Spark 是可以识别的。
3.2、与 MySQL 交互
导入 MySQL 依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>public static void main(String[] args) {
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("read from mysql");
// 2. 创建 SparkSession
SparkSession spark = SparkSession
.builder()
.config(conf)
.getOrCreate();
Dataset<Row> df = spark.read()
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/spark")
.option("user", "root")
.option("password", "Yan1029.")
.option("dbtable", "student")
.load();
df.select("*").show();
spark.close();
}3.3、与 Hive 交互
导入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.3.1</version>
</dependency>拷贝 hive-site.xml到resources目录(如果需要操作Hadoop,需要拷贝hdfs-site.xml、core-site.xml、yarn-site.xml),然后启动 Hadoop 和 Hive。
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME","lyh");
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("spark sql operate hive");
// 2. 获取 SparkSession
SparkSession spark = SparkSession
.builder()
.enableHiveSupport() // 添加 hive 支持
.config(conf)
.getOrCreate();
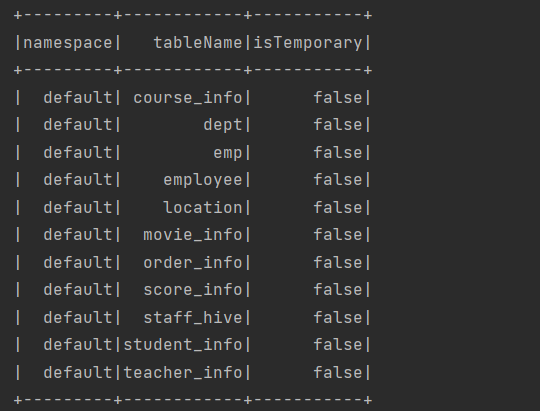
spark.sql("show tables").show();
// 4. 关闭 SparkSession
spark.close();
}运行结果:
4、Spark SQL 练习
4.1、统计每个商品的销量最高的日期
从订单明细表(order_detail)中统计出每种商品销售件数最多的日期及当日销量,如果有同一商品多日销量并列的情况,取其中的最小日期:
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME","lyh");
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("spark sql operate hive");
// 2. 获取 SparkSession
SparkSession spark = SparkSession
.builder()
.enableHiveSupport() // 添加 hive 支持
.config(conf)
.getOrCreate();
spark.sql("use db_hive2");
// order_detail_idorder_idsku_idcreate_dateprice sku_num
// 每件商品的最高销量
spark.sql("SELECT sku_id, create_date, sum_num FROM (SELECT sku_id, create_date, sum_num, ROW_NUMBER() OVER(PARTITION BY sku_id ORDER BY sum_num DESC,create_date ASC) rk FROM (SELECT sku_id, create_date, sum(sku_num) sum_num FROM order_detail GROUP BY sku_id,create_date)t1)t2 WHERE rk = 1").show();
// 4. 关闭 SparkSession
spark.close();
}上面个的代码就像在写 HQL 一样,我们可以把其中的子表提出来创建为临时表:
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME","lyh");
// 1. 创建配置对象
SparkConf conf = new SparkConf()
.setMaster("local[*]")
.setAppName("spark sql operate hive");
// 2. 获取 SparkSession
SparkSession spark = SparkSession
.builder()
.enableHiveSupport() // 添加 hive 支持
.config(conf)
.getOrCreate();
spark.sql("use db_hive2");
// order_detail_idorder_idsku_idcreate_dateprice sku_num
// 每件商品的最高销量
spark.sql("SELECT sku_id, create_date, sum(sku_num) sum_num FROM order_detail GROUP BY sku_id,create_date")
.createOrReplaceTempView("t1");
spark.sql("SELECT sku_id, create_date, sum_num, ROW_NUMBER() OVER(PARTITION BY sku_id ORDER BY sum_num DESC,create_date ASC) rk FROM t1")
.createOrReplaceTempView("t2");
spark.sql("SELECT sku_id, create_date, sum_num FROM t2 WHERE rk = 1").show();
// 4. 关闭 SparkSession
spark.close();
}没啥难度,这就是官网说的使用 Spark SQL 或者 HQL 来操作数仓中的数据,之后做个 Spark SQL 项目多练练手就行了。
运行结果:

原文地址:https://blog.csdn.net/m0_64261982/article/details/139168097
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!