XML:DOM4j解析XML
XML简介:
什么是XML:XML 是独立于软件和硬件的信息传输工具。
- XML 的设计宗旨是传输数据,而不是显示数据。
- XML 标签没有被预定义。您需要自行定义标签。
- XML不会做任何事情,XML被设计用来结构化、存储以及传输信息。
XML可以发明自己的标签:
HTML仅仅可以用在 标准中定义过的标签
而XML没有预定义的标签,XML允许创作者定义自己的标签和自己的文档结构
特点:
XML与操作系统、编程语言的开发平台无关实现不同系统之间的数据交换
作用:
数据交互配置应用程序和网站Ajax基石
文档声明:
<?xml version="1.0" encoding="UTF-8"?>
属性值用双引号包裹
一个元素可以有多个属性
属性值中不能直接包含<、“、&
不建议使用的字符:‘、>
XML编写注意事项:
- 所有XML元素都必须有结束标签
- XML标签对大小写敏感XML必须正确的嵌套
- 同级标签以缩进对齐
- 元素名称可以包含字母、数字或其他的字符
- 元素名称不能以数字或者标点符号开始
- 元素名称中不能含空格
- 属性必须加”“
XML 文档:
- XML文件必须要有根元素,这里的class就是根元素,
- 元素可以包含属性,属性提供有关元素的附加信息,属性位于开始标签中。
<?xml version="1.0" encoding="UTF-8"?>
<class>
<student name="王显明">
<score predicted="75" actualScore="80" />
</student>
<student name="宋佳">
<score predicted="75" actualScore="88" />
</student>
</class>XML实体引用:
在xml这样是错误的,因为xml会把<当作一个新的开始标签
<message>if salary < 1000 then</message>为了为避免我们就可以用实体标签:
| < | ⁢ |
| > | > |
| & | & |
| ' | ' |
| " | " |
CDATA区:
CDATA 区段中的内容不会被 XML 解析器处理为 XML 标签或特殊字符,而是作为纯文本来处理。
<content>
<![CDATA[
aaaa<<<>>>
]]>
</content>XML注释:
和html的注释一样
<!-- This is a comment -->xml的空格:
在html中空格会被合并为1个,但是XML中空格不会被删减
XML元素:
元素命名规则:
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
XML属性:
- 属性值必须被引号包围,不过单引号和双引号均可使用。
<person sex="female">也可以
<person sex='female'>没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用元素。我的经验是在 HTML 中,属性用起来很便利,但是在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用元素吧。
XML命名空间:
xmlns:[前缀属性] ="[命名空间的URL]"
解决在复杂、大型XML文件中,出现名称相同,但是含义不同的元素
这样可以在同一个文档中使用 book 和 author 命名空间下的元素,避免名称冲突并保持数据结构的清晰性。
xmlns:book="http://www.example.com/book"定义了一个名为book的命名空间,用于描述书籍相关的元素。xmlns:author="http://www.example.com/author"定义了一个名为author的命名空间,用于描述作者相关的元素。
<?xml version="1.0" encoding="UTF-8"?>
<document xmlns:book="http://www.example.com/book" xmlns:author="http://www.example.com/author">
<book:title>The Great Gatsby</book:title>
<author:name>F. Scott Fitzgerald</author:name>
</document>
DOM4j解析XML:
1.DOM解析XML
DOM把XML文档映射成一个倒挂的树
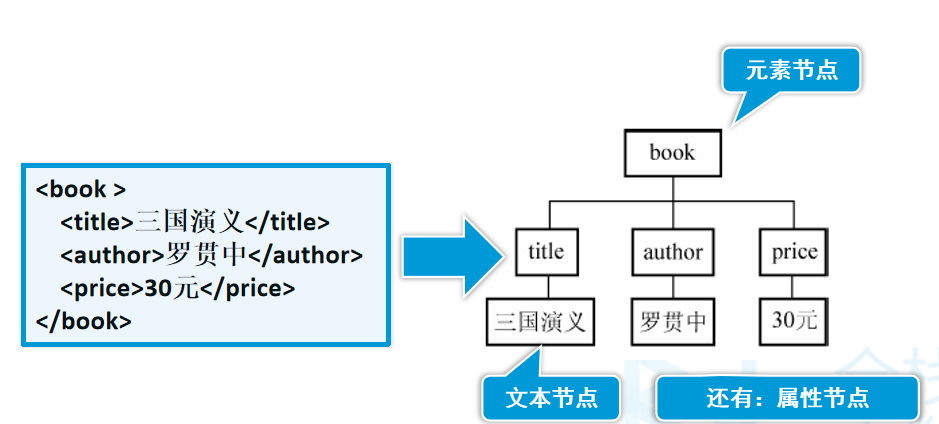
访问DOM树节点:
<?xml version="1.0" encoding="GB2312"?>
<PhoneInfo>
<Brand name="华为">
<Type name="U8650"/>
<Type name="HW123"/>
<Type name="HW321"/>
</Brand>
<Brand name="苹果">
<Type name="iPhone4"/>
</Brand>
</PhoneInfo>
package QuestionPpt02;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
public class UtilPhone {
public static void main(String[] args) {
//将xml文件加载到内存中 XM;解析器
SAXReader saxReader = new SAXReader();
//加载执行获取Document对象
try {
Document document = saxReader.read("D:\\idea-workspace\\Book03\\ch010\\src\\QuestionPpt02\\phone.xml");
//获取根节点
Element rootElement = document.getRootElement();
//获取该节点下的所有子节点
List<Element> Elist = rootElement.elements();
for (Element e : Elist){
System.out.println("子节点为_____________________"+e.getName()+"____________________________________");
//获取当前点下所有子节点
List<Element> EChild = e.elements();
for (Element child : EChild){
System.out.println("Brand的子节点为_________"+child.getName());
System.out.println("获取当前节点属性"+child.attributeValue("name"));
}
//获取当前节点的属性
System.out.println( e.attributeValue("name"));
}
} catch (DocumentException e) {
throw new RuntimeException(e);
}
}
}
具体的DOM4j的pdf地址:
"D:\AAAhz鸿卓\2Java三本书\高级编程\高级编程资料\dom4j解析XML.doc"
例题:
写入的时候需要先获取文档对象读再获取写入对象写
public class UtilsXml {
public static void main(String[] args) {
//读取XML
//showXml();
editXml();
}
/**
* 修改文档内容
*/
public static void editXml(){
try {
//读取原有的文档
//构建解析器
SAXReader saxReader = new SAXReader();
//通过read方法获得doc对象
Document document = saxReader.read("ch10/students.xml");
//获得根节点
Element root = document.getRootElement();
List<Element> elementList = root.elements();
for(Element element:elementList){
if("1002".equals(element.attributeValue("id")))
{
element.element("name").setText("王五");
}
}
//新增节点
Element stu = root.addElement("stu");
stu.addAttribute("id","1003");
stu.addElement("name").setText("马六");
stu.addElement("age").setText("20");
stu.addElement("score").addAttribute("value","77");
//document 写入students.xml
XMLWriter xmlWriter = new XMLWriter(
new FileWriter("ch10/students.xml"));
xmlWriter.write(document);
xmlWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void showXml(){
try {
//构建解析器
SAXReader saxReader = new SAXReader();
//通过read方法获得doc对象
Document document = saxReader.read("ch10/students.xml");
//获得根节点
Element root = document.getRootElement();
//打印根节点名称
System.out.println("根节点:"+root.getName());
//获得所有子节点
List<Element> elements = root.elements();
for(Element element : elements)
{
System.out.println("---------stu--------");
//获得每个子节点上的id属性值
String id = element.attributeValue("id");
System.out.println("id:"+id);
//获得stu下name元素节点
Element name = element.element("name");
System.out.println("name:"+name.getText());
Element age = element.element("age");
System.out.println("age:"+age.getText());
Element score = element.element("score");
System.out.println("score:"+score.attributeValue("value"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}dom4j解析XML:
1.读取xml文件 SAXReader()
//将xml文件加载到内存中 XML解析器
SAXReader saxReader = new SAXReader();
//document 加载执行xml文档获取Document对象
Document document = saxReader.read(XML路径);2.获取XML根节点getRootElement()
Element rootElement = document.getRootElement();3.获取当前节点下所有子节点 elements()
//获取根节点下所有子节点
List<Element> Elist = rootElement.elements();4.根据指定子元素名,获取元素下所有子节点
//获取节点名称为books下所有子节点
List<Element> Elist = rootElement.elements(“books”);5.根据指定子元素名,获取子元素对象,如果重复,则获取第一个
//获取节点名称为books下单个子节点
Element element= rootElement.element(“books”);6.设置元素文本内容 setText()
newelement.setText("内容");7.获取当前节点文本内容 getText()
elenent.getText()8.根据指定子元素名,获取元素中的文本
e.elementText(“book”)9.获取当前节点属性 attributeValue(“属性名”)
e.attributeValue("name")11.创建节点Element对象.addElement("节点名")
Element newelement = rootElement.addElement("span");12.节点添加,修改属性Element对象.addAttribute("节点属性名",“属性值”)
newelement.addAttribute("type","属性值");13.新XML添加Documen对象
通过DocumentHelper.creatDocument()创建一个Document对象
Document read = DocumentHelper.createDocument();14.设置XML编码
通过OutputFormat的静态方法createPrettyPrint()创建OutputFormat对象,并设置编码集
OutputFormat outputFormat=OutputFormat.createPrettyPrint();
outputFormat.setEncoding("UTF-8");15.写入XML文件
//写入XML文件的位置 以及指定的格式
XMLWriter xmlWriter=new XMLWriter(new FileWriter("cs.xml"),outputFormat);
//开始写入XML文件 写入Document对象
xmlWriter.write(document);
xmlWriter.close();原文地址:https://blog.csdn.net/qq_62859013/article/details/142388733
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!