2.12 过拟合与欠拟合是什么?怎么解决?
2.12 过拟合与欠拟合是什么?怎么解决?
场景描述
在模型评估与调整的过程中,我们往往会遇到“过拟合”或“欠拟合”的情况。如何有效地识别“过拟合”和“欠拟合”现象,并有针对性地进行模型调整,是不断改进机器学习模型的关键。特别是在实际项目中,采用多种方法、从多个角度降低“过拟合”和“欠拟合”的风险是算法工程师应当具备的领域知识。
1.在模型评估过程中,过拟合和欠拟合具体是指什么现象?
-
过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差。
-
欠拟合指的是模型在训练和预测时表现都不好的情况。图2.5形象地描述了过拟合和欠拟合的区别。
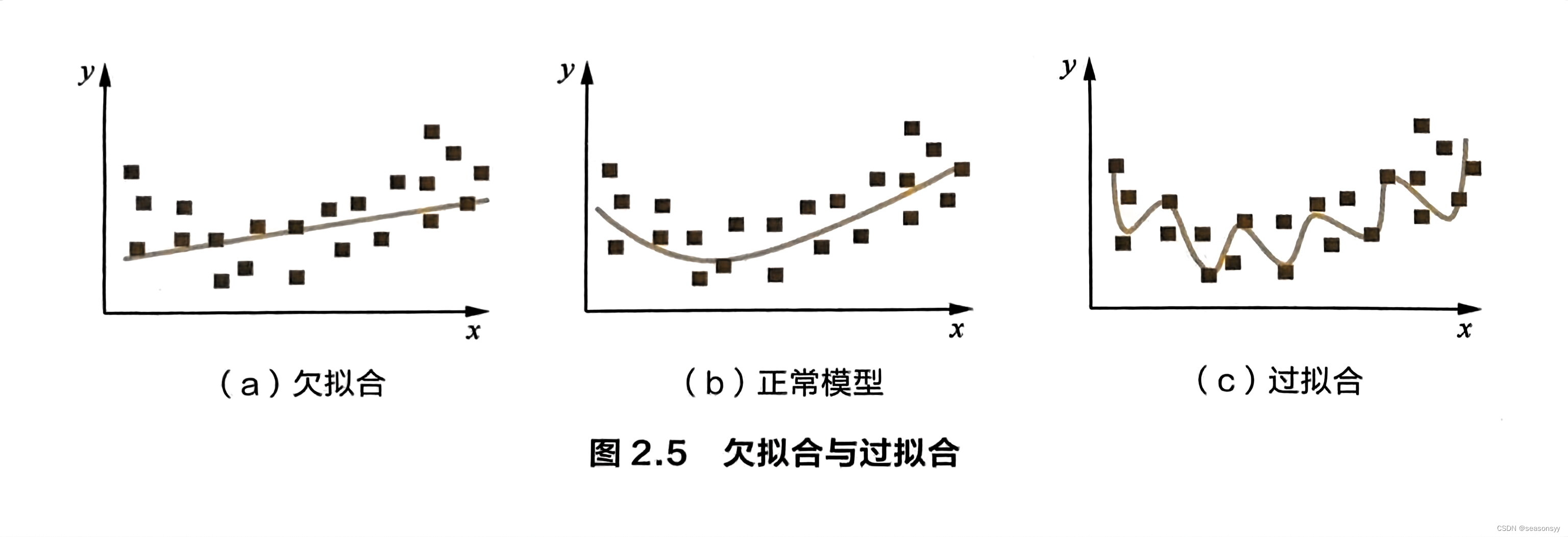
可以看出,图2.5(a)是欠拟合的情况,拟合的黄线没有很好地捕捉到数据的特征,不能够很好地拟合数据。
图2.5©则是过拟合的情况,模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力下降,在后期应用过程中很容易输出错误的预测结果。
2.有哪几种降低过拟合和欠拟合风险的方法?
-
降低“过拟合”风险的方法
-
从数据入手,获得更多的训练数据。使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。当然,直接增加实验数据一般是很困难的,但是可以通过一定的规则来扩充训练数据。比如,在图像分类的问题上,可以通过图像的平移、旋转、缩放等方式扩充数据;更进一步地,可以使用生成式对抗网络来合成大量的新训练数据。
-
降低模型复杂度。在数据较少时,模型过于复杂是产生过拟合的主要因素,适当降低模型复杂度可以避免模型拟合过多的采样噪声。例如,在神经网络模型中减少网络层数、神经元个数等;在决策树模型中降低树的深度、进行剪枝等。
-
正则化方法。给模型的参数加上一定的正则约束,比如将权值的大小加入到损失函数中。
以L2正则化为例:
C = C 0 + λ 2 n ⋅ ∑ i w i 2 C = {C_0} + \frac{\lambda }{{2n}} \cdot \sum\limits_i {{w_i}^2} C=C0+2nλ⋅i∑wi2
这样,在优化原来的目标函数 C_0 的同时,也能避免权值过大带来的过拟合风险。
- 集成学习方法。集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如 Bagging 方法。
-
-
降低“欠拟合”风险的方法
- 添加新特征。当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘“上下文特征”“ID类特征”“组合特征”等新的特征,往往能够取得更好的效果。在深度学习潮流中,Deep-crossing 帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等都可以成为丰富特征的方法。
- 增加模型复杂度。简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。例如,在线性模型中添加高次项,在神经网络模型中增加网络层数或神经元个数等。
- 减小正则化系数。正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
参考文献:
《百面机器学习》 诸葛越主编
出版社:人民邮电出版社(北京)
ISBN:978-7-115-48736-0
2022年8月第1版(2022年1月北京第19次印刷)
原文地址:https://blog.csdn.net/seasonsyy/article/details/136987749
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!