An Unsupervised Deep Learning Model for Early Network Traffic Anomaly Detection
摘要
迄今为止,针对此类攻击的最先进的防御系统主要依赖于从整个流或签名中提取的预定义特征。这些特征定义是手动的,提取流特征后阻止恶意流可能会太迟。在本研究中,我们提出了一种有效的异常流量检测机制,名为D-PACK,它由一个卷积神经网络(CNN)和一个无监督的深度学习模型(如自动编码器)组成,用于自动描述流量模式并过滤异常流量。值得注意的是,D-PACK仅检查每个流的前几个数据包的前几个字节,以进行早期检测。我们的实验结果表明,仅通过检查每个流的前两个数据包,D-PACK的准确性接近100%,同时具有极低的误报率,例如仅为0.83%。这种设计可以启发对在线异常检测系统的新兴努力,该系统通过减少处理数据包的数量,并及时阻止恶意流量,以提高网络安全性。
介绍
论文主要贡献的工作:
- 提出了一种基于深度学习的无监督网络流量异常检测模型,该模型可以自动构建流量特征,并在早期检测到异常流量。该模型仅检查每个流的前几个字节和前几个数据包,以实现早期检测。
- 实验结果表明,该模型在仅检查每个流的前两个数据包时,仍具有近100%的准确性,并且具有极低的误报率,例如0.83%。
- 该模型可以启发新兴的在线异常检测系统,这些系统可以减少处理的数据包数量并实时阻止恶意流量。
相关的工作
网络流量异常检测的四种主要方法:基于端口/规则的方法、深度/随机数据包检查方法、统计方法和行为方法。其中,基于端口/规则的方法、深度/随机数据包检查方法和统计方法在过去几十年中取得了较高的入侵检测性能,而行为方法在多个指标上表现不佳,例如高误报率。由于正常流量特征的复杂性和大规模原始数据中手动干预的缺乏,行为方法在定义“正常”边缘方面可能表现不佳。因此,深度学习是一种有效的方法来改进异常检测性能。
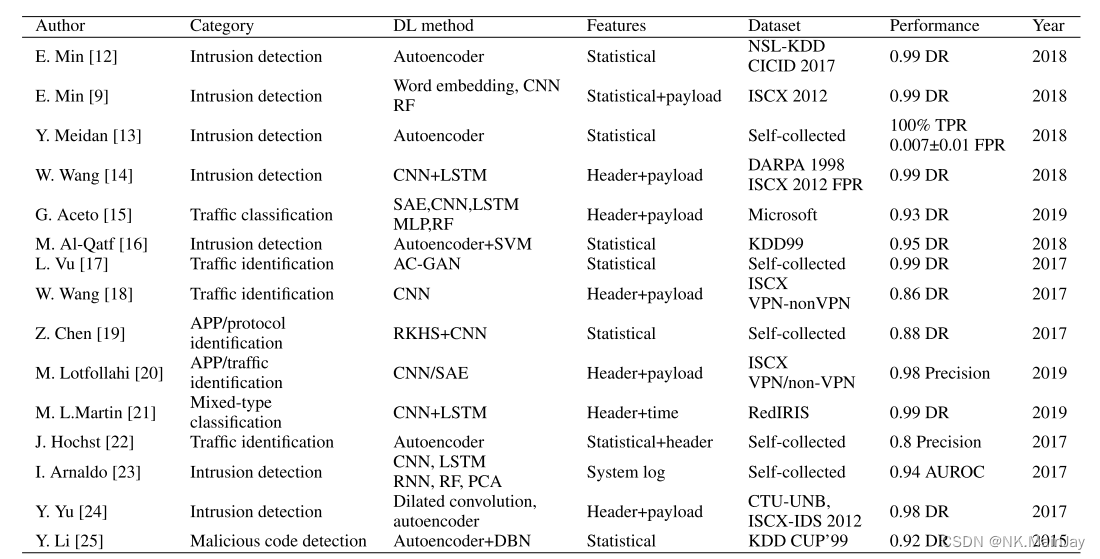
论文的工作有两个主要区别:(1)D-PACK可以通过检查每个流的第一个数据包,而不是检查流中的总数据包来构建流量的概况;(2) D-PACK可以直接处理原始数据包,即构建模式、读取输入数据和做出检测决策。
检测流量异常的方法是新颖的。我们不是收集整个流量,而是将每个流量的前几个数据包打包成固定长度的段,从而显著减少了计算和内存空间。
分类和检测的学习策略
采样网络流
考虑通过提取每个流的前 n n n 个数据包来对流进行采样,并且每个数据包被修剪成固定长度的 l l l 字节,从报头字段开始(必要时使用零填充)。注意,流的原始数据包是根据它们的5元组信息(源IP、源端口、目的IP、目的端口和传输层协议)进行分类的。 n n n 和 l l l 可根据部署时的网络流量特点灵活调整。
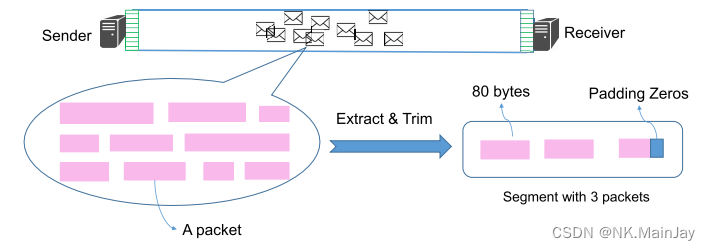
例如上图一个流由十个数据包组成,我们只检查前三个数据包并修剪它们的长度。将每个流中的修剪字节视为具有
n
×
l
n\times l
n×l个元素的一维向量,并将其转换为CNN模型的输入进行训练。
自动构建流量模型
1D-CNN适用于序列数据或语言等数据;2D-CNN适用于图像等数据;3D-CNN适用于视频或体积图像等数据。1D-CNN也被广泛用于网络流量分析。
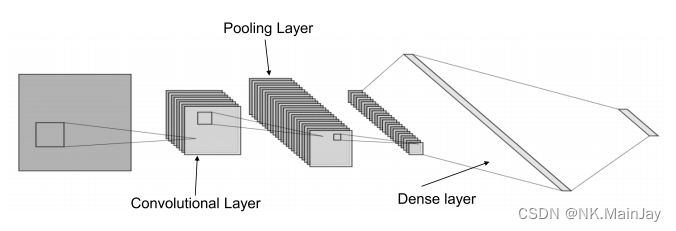
- 我们假设对每个流的前 n n n 个数据包进行采样,并且每个采样的数据包被修剪成前 l l l 个字节(主要在数据包头中,如果报文数小于 n n n 或报文大小小于 l l l 字节,则用0填充数据)。
- 卷积层运算,将卷积层滤波器的核大小设置为 6(在表头中,最大的字段是 MAC 地址)
- 然后在特征映射上应用max-over-time池化操作,并将最大值 m a x ( h ) max(h) max(h)作为下一层的特征。
- 使用多个卷积层和池化层来提取高级特征。这些特征构成了层,并被传递到一个完全连接的致密层,其输出是良性流类型的概率分布
- n n n 和 l l l 的理想配置是系统性能在几个度量之间达到平衡的阈值,例如,高精度和低处理流量。论文在实证实验中发现,当 n = 2 n = 2 n=2 和 l = 80 l =80 l=80 时,系统可以在大多数选定的数据集上达到这一目标。
- 在CNN中的隐藏层(第5层),连接到自动编码器模块,用于学习流的特征。
无监督机器学习模型
数据集
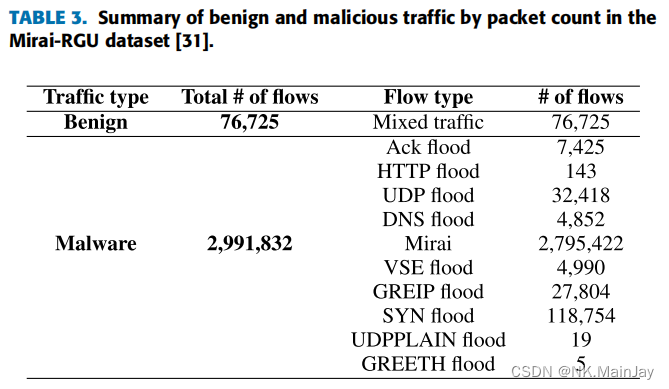
USTC-TFC2016 是一个优秀的数据集,匹配论文的需求。表2总结了数据集中良性流量和恶意流量的统计数据。根据他们的陈述,总共有十种类型的错误 从2011年到2015年,在一个真实的网络环境中从公共网站收集软件流量。
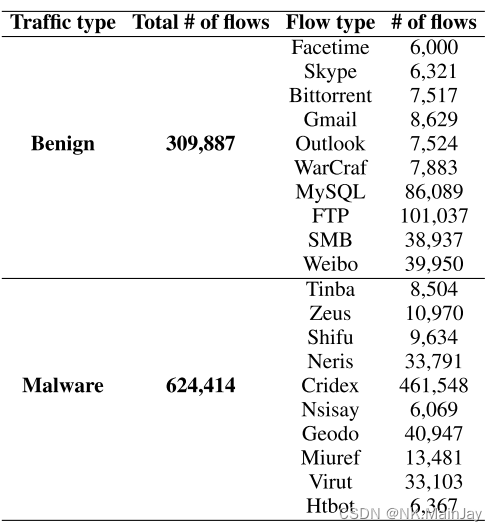
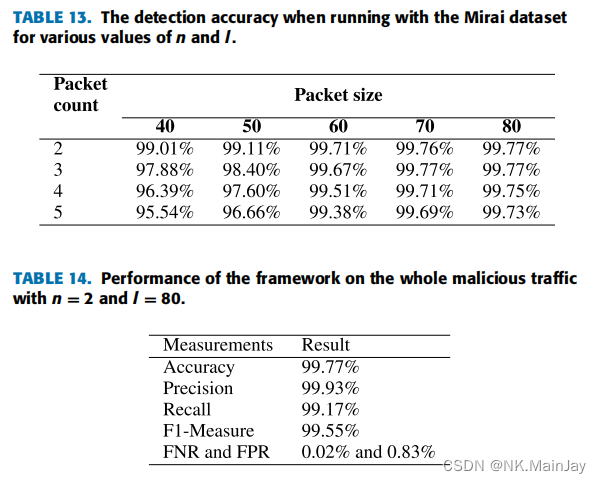
对于基于mirai的DDoS流量,我们使用了来自罗伯特·戈登大学的数据集,用Mirai-RGU表示。
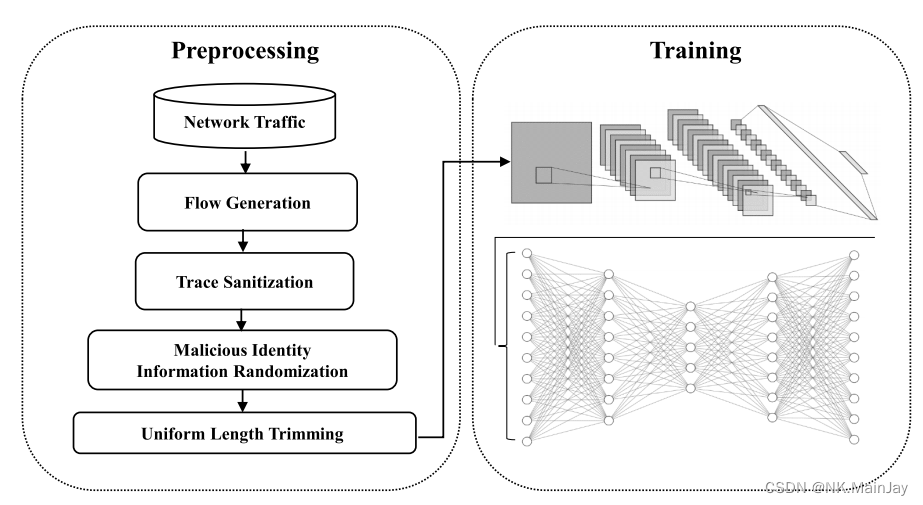
基于深度学习的无监督异常检测体系结构
在分类方面,根据良性流量的MSELoss分布设置阈值来区分良性流量和恶意流量。注意,在检测攻击时,自动编码器训练集(即良性流)产生的MSELoss分布用于确定检测阈值。MSELoss根据模糊特征计算流,将这些特征作为不同的向量输入到MSE中计算损失属性。为了避免MSELoss极值的影响,将最大值与MSELoss的99%百分位数进行比较。对于阈值,如果这两个值的差值超过MSELoss分布的三倍标准差,则设置第99个百分位数作为检测阈值;否则,将最大MSELoss设置为阈值。
调优的超参数
- n n n 和 l l l:这是早期检测的同时保持高精度的关键参数。
- 批量归一化:由于深度学习架构的深度,每层间的批量归一化可以保持参数分布稳定,加快学习效率,缓解梯度消失,避免过拟合。
- CNN 由 3 个隐藏层组成,第二个隐藏层的大小为 25 时可以显著提高该模型的性能
- 所有致密层都采用分层贪婪预训练进行初始化:分层贪婪预训练设计的目标是减轻深度构建模型中消失梯度问题和过拟合的影响。
结果评估
环境
Python: 3.6.12
pytorch: 1.10.2
指标
Accuracy、Precision、Recall、F1、FAR、FNR
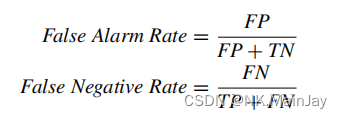
场景
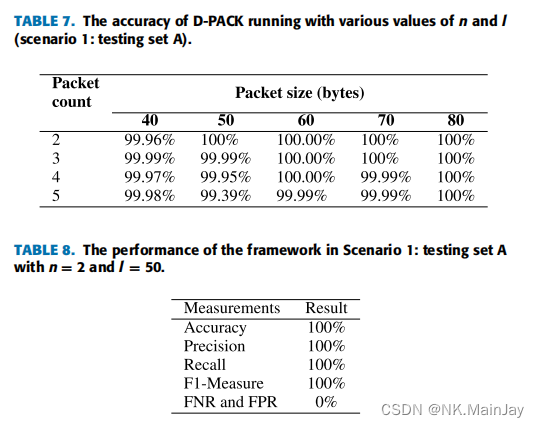
场景一
训练集:良性流量
测试集:USTC-TFC 2016的良性流量、Mirai-CCU的恶意流量
场景二
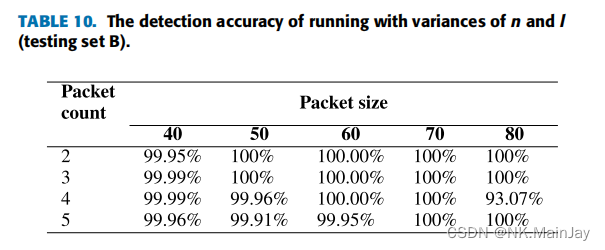
- 训练数据和测试数据均来自USTC-TFC 2016数据集
- 训练集与测试集中良性流量的比例为7:1
- 只有恶意流量出现在测试集中
场景三
- 训练和测试数据来自Mirai-RGU数据集
- 只有良性流量训练自动编码器
- 测试数据包括来自Mirai-RGU数据集的良性和恶意流量
源代码
原文地址:https://blog.csdn.net/troublenbfriend/article/details/136699990
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!