MySQL 基本语法讲解及示例(下)

第六节:如何检索资料
在本节中,我们将介绍如何使用SQL语句检索数据库中的资料,具体包括选择特定列、排序、条件过滤以及组合排序等操作。我们以一个名为
student的表格为例,演示不同的检索方法。
初始表格 student
| student_id | name | major | score |
|---|---|---|---|
| 1 | 小白 | 英语 | 50 |
| 2 | 小黄 | 生物 | 90 |
| 3 | 小绿 | 历史 | 70 |
| 4 | 小蓝 | 英语 | 80 |
| 5 | 小黑 | 化学 | 20 |
检索目标表格
1. 选取目标列 name, major
SELECT `name`, `major` FROM `student`;
结果:
| name | major |
|---|---|
| 小白 | 英语 |
| 小黄 | 生物 |
| 小绿 | 历史 |
| 小蓝 | 英语 |
| 小黑 | 化学 |
2. 依照特定列 score,对目标列进行排序(顺序)
SELECT `name`, `major`, `score` FROM `student` ORDER BY `score`;
结果:
| name | major | score |
|---|---|---|
| 小黑 | 化学 | 20 |
| 小白 | 英语 | 50 |
| 小绿 | 历史 | 70 |
| 小蓝 | 英语 | 80 |
| 小黄 | 生物 | 90 |
3. 依照特定列 score,对目标列进行排序(倒序)
SELECT `name`, `major`, `score` FROM `student` ORDER BY `score` DESC;
结果:
| name | major | score |
|---|---|---|
| 小黄 | 生物 | 90 |
| 小蓝 | 英语 | 80 |
| 小绿 | 历史 | 70 |
| 小白 | 英语 | 50 |
| 小黑 | 化学 | 20 |
4. 组合排序,依照特定列 score, student_id 先后对目标列进行排序
SELECT * FROM `student` ORDER BY `score`, `student_id`;
结果:
| student_id | name | major | score |
|---|---|---|---|
| 5 | 小黑 | 化学 | 20 |
| 1 | 小白 | 英语 | 50 |
| 3 | 小绿 | 历史 | 70 |
| 4 | 小蓝 | 英语 | 80 |
| 2 | 小黄 | 生物 | 90 |
5. WHERE 多条件限定情况
SELECT * FROM `student`
WHERE `major` IN('生物', '历史', '英语');
或者
SELECT * FROM `student`
WHERE `major` = '生物' OR `major` = '历史' OR `major` = '英语';
结果:
| student_id | name | major | score |
|---|---|---|---|
| 1 | 小白 | 英语 | 50 |
| 2 | 小黄 | 生物 | 90 |
| 3 | 小绿 | 历史 | 70 |
| 4 | 小蓝 | 英语 | 80 |
第七节:案例:创建公司数据库
本案例展示了如何创建一个包含员工、部门、客户以及员工与客户关系的公司数据库。
创建数据表
1. Employee 表
CREATE TABLE `employee`(
`emp_id` INT PRIMARY KEY,
`name` VARCHAR(20),
`birth_date` DATE,
`sex` VARCHAR(1),
`salary` INT,
`branch_id` INT,
`sup_id` INT
);
2. Branch 表
CREATE TABLE `branch`(
`branch_id` INT PRIMARY KEY,
`branch_name` VARCHAR(20),
`manager_id` INT,
FOREIGN KEY (`manager_id`) REFERENCES `employee`(`emp_id`) ON DELETE SET NULL
);
外键 (
manager_id) 对应employee(emp_id
3. Customer 表
CREATE TABLE `customer`(
`cust_id` INT PRIMARY KEY,
`name` VARCHAR(50),
`address` VARCHAR(100),
`phone` VARCHAR(15)
);
4. Works_With 表
CREATE TABLE `works_with`(
`emp_id` INT,
`cust_id` INT,
`total_sales` DECIMAL(10, 2),
PRIMARY KEY (`emp_id`, `cust_id`),
FOREIGN KEY (`emp_id`) REFERENCES `employee`(`emp_id`) ON DELETE CASCADE,
FOREIGN KEY (`cust_id`) REFERENCES `customer`(`cust_id`) ON DELETE CASCADE
);
插入数据
让我们插入一些数据以便更好地演示如何进行查询。
插入 Employee 表数据
INSERT INTO `employee` (`emp_id`, `name`, `birth_date`, `sex`, `salary`, `branch_id`, `sup_id`)
VALUES
(1, 'Alice', '1985-01-15', 'F', 50000, 1, NULL),
(2, 'Bob', '1975-03-22', 'M', 60000, 1, 1),
(3, 'Charlie', '1990-07-18', 'M', 55000, 2, NULL);
插入 Branch 表数据
INSERT INTO `branch` (`branch_id`, `branch_name`, `manager_id`)
VALUES
(1, 'HQ', 1),
(2, 'Branch 1', 3);
插入 Customer 表数据
INSERT INTO `customer` (`cust_id`, `name`, `address`, `phone`)
VALUES
(1, 'Customer A', '123 Main St', '555-1234'),
(2, 'Customer B', '456 Elm St', '555-5678');
插入 Works_With 表数据
INSERT INTO `works_with` (`emp_id`, `cust_id`, `total_sales`)
VALUES
(1, 1, 2000.00),
(2, 1, 1500.00),
(2, 2, 3000.00);
复杂查询示例
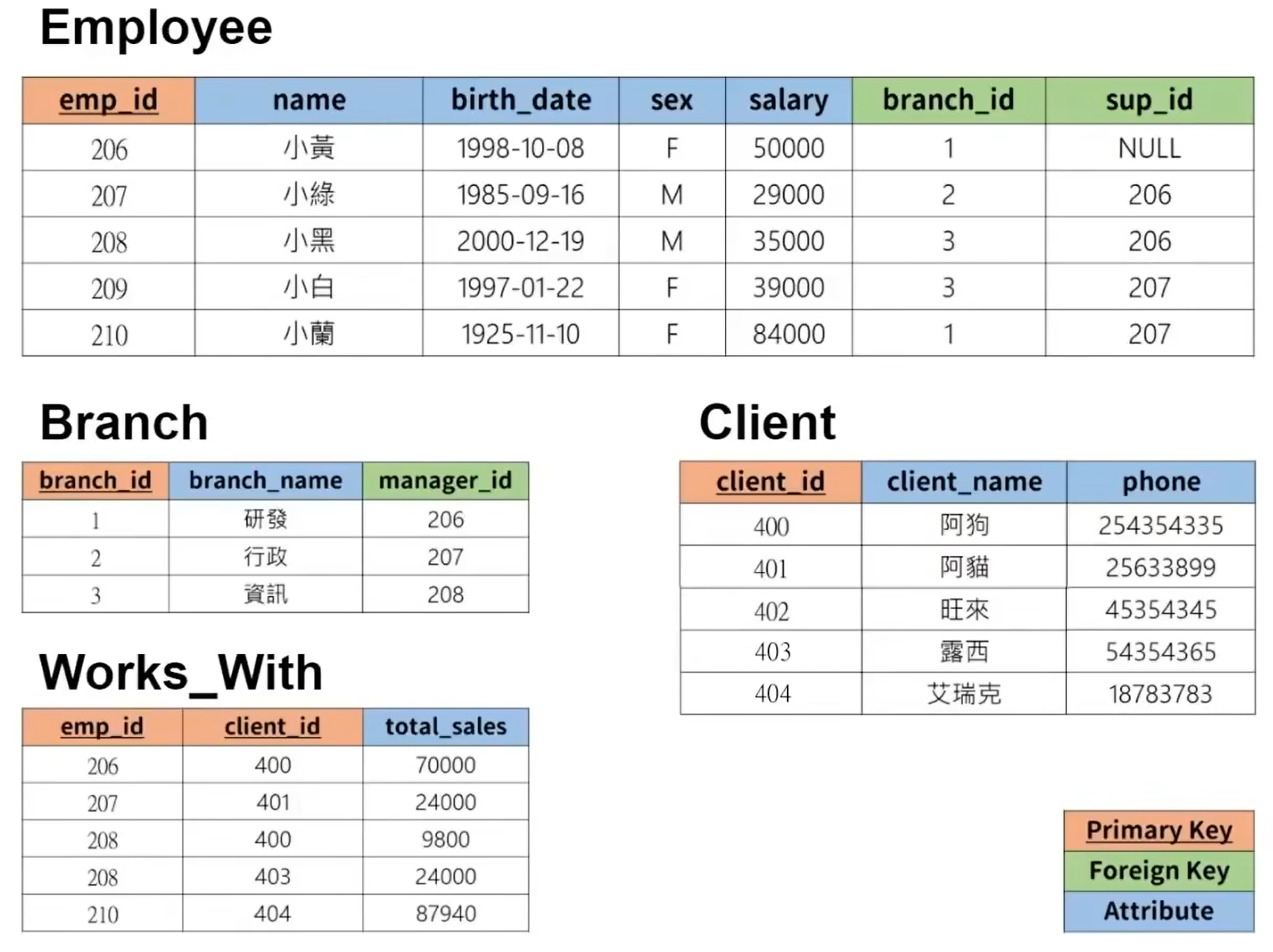
0. 图片案例查询
获取公司数据
基本语法案例:
-- 1.取得所有员工资料
SELECT * FROM `employee`;
-- 2.取得所有客户资料
SELECT * FROM `client`;
-- 3.按薪水低到高取得员工资料
SELECT * FROM `employee` ORDER BY `salary`;
-- 4.取得薪水前3高的员工
SELECT * FROM `employee` ORDER BY `salary` DESC LIMIT 3;
-- 5.取得所有员工的名子
SELECT `name` FROM `employee`;
-- 6.取得所有员工的性别,筛除重复值
SELECT DISTINCT `sex` FROM `employee`;
聚合函数
基本语法案例:
-- aggregate functions聚合函数
-- 1.取得员工人数
SELECT COUNT(`emp_id`) FROM `employee`;
-- 2.取得所有出生於 1970-01-01之後的女性员工人数
SELECT COUNT(`emp_id`) FROM `employee` WHERE `birth_data` > '1970-01-01' AND `sex` = 'F';
-- 3.取得所有员工的平均薪水
SELECT AVG(`salary`) FROM `employee`;
-- 4.取得所有员工薪水的总和
SELECT SUM(`salary`) FROM `employee`;
-- 5.取得的最高薪水
SELECT MAX(`salary`) FROM `employee`;
-- 6.取得的最低薪水
SELECT MIN(`salary`) FROM `employee`;
wildcards 万用字符
基本语法案例:
-- wildcards万用字符% 代表多个字元,_代表一固字元
-- 1.取得电话号码尾数是335的客户
SELECT * FROM `client` WHERE `phone` LIKE '%335';
-- 2.取得姓艾的客户
SELECT * FROM `client` WHERE `client_name` LIKE '艾%';
-- 3.取得生日在12月的员工
SELECT * FROM `employee` WHERE `birth_data` LIKE '____-12%';
union 联合
基本语法案例:
-- 1. 员工名子 union 客户名子
SELECT `name` FROM `employee`
UNION
SELECT `client_name` FROM `client`;
-- 2. 员工id + 员工名子 union 客户id + 客户名子
SELECT `emp_id`, `name` FROM `employee`
UNION
SELECT `client_id`, `client_name` FROM `client`;
-- 3.员工薪水 union 销售金额
SELECT `salary` AS `total_money` FROM `employee`
UNION
SELECT `total_sales` FROM `works_with`;
合并的字符类型要求一致
join 连接
-- join 连接
-- 取得所有部门经理的名子
SELECT `emp_id`, `name` FROM `employee` JOIN `branch`
ON `employee`.`emp_id` = `branch`.`manager_id`;
-- LEFT JOIN 左连接 空缺为NULL
-- RIGHT JOIN 右连接 空缺为NULL
JOIN连接时通过
.来标定属性的表归属
subquery 子查询
-- subquery子查韵
-- 1.找出研发部门经理名子
SELECT `name`
FROM `employee`
WHERE `emp_id` = (
SELECT `manager_id`
FROM `branch`
WHERE `branch_name` = '研发'
);
-- 2.找出对单一位客户销售金额超过50000的员工名子
SELECT `name`
FROM `employee`
WHERE `emp_id` IN (
SELECT `emp_id`
FROM `works_with`
WHERE `total_sales` > 50000
);
on delete
Branch
CREATE TABLE `branch`(
`branch_id` INT PRIMARY KEY,
`branch_name` VARCHAR(20),
`manager_id` INT,
FOREIGN KEY (`manager_id`) REFERENCES `employee`(`emp_id`) ON DELETE SET NULL
);
表示:在删除表单时
employee(emp_id)若缺失, (manager_id) 赋值为NULL
注意删除时,主键不能为NULL
Works_with
CREATE TABLE `works_with`(
`emp_id` INT,
`client_id` INT,
`total_sales` INT,
PRIMARY KEY(`emp_id`, `client_id`),
FOREIGN KEY (`emp_id`) REFERENCES `employee`(`emp_id`) ON DELETE CASCADE,
FOREIGN KEY (`client_id`) REFERENCES `client` (`client_id`) ON DELETE CASCADE
);
表示:在删除表单时
employee(emp_id)若无对应, 对应行直接删除
1. 查询每个员工的总销售额
SELECT
e.`name` AS `employee_name`,
SUM(w.`total_sales`) AS `total_sales`
FROM
`employee` e
JOIN
`works_with` w ON e.`emp_id` = w.`emp_id`
GROUP BY
e.`name`;
结果:
| employee_name | total_sales |
|---|---|
| Alice | 2000.00 |
| Bob | 4500.00 |
2. 查询每个部门的经理姓名
SELECT
b.`branch_name`,
e.`name` AS `manager_name`
FROM
`branch` b
JOIN
`employee` e ON b.`manager_id` = e.`emp_id`;
结果:
| branch_name | manager_name |
|---|---|
| HQ | Alice |
| Branch 1 | Charlie |
3. 查询特定员工负责的客户信息
假设我们想查询Bob(
emp_id= 2)负责的客户信息:
SELECT
c.`name` AS `customer_name`,
c.`address`,
c.`phone`,
w.`total_sales`
FROM
`customer` c
JOIN
`works_with` w ON c.`cust_id` = w.`cust_id`
WHERE
w.`emp_id` = 2;
结果:
| customer_name | address | phone | total_sales |
|---|---|---|---|
| Customer A | 123 Main St | 555-1234 | 1500.00 |
| Customer B | 456 Elm St | 555-5678 | 3000.00 |
如何使用Python与MySQL进行集成,并展示一些更复杂的查询和数据处理操作。
以公司数据库为例,如何编写Python代码来查询数据、进行数据分析,并将结果可视化。
使用Python与MySQL进行集成的详细示例
1. 安装 mysql-connector-python 库
首先,确保你安装了 mysql-connector-python 库。可以使用以下命令进行安装:
2. 连接MySQL数据库并执行查询
以下是一个详细的Python示例,展示如何连接到MySQL数据库,执行查询并处理结果:
import mysql.connector
def connect_to_database():
# 建立数据库连接
conn = mysql.connector.connect(
host='localhost',
user='root',
password='your_password',
database='your_database'
)
return conn
def fetch_employee_sales():
# 连接数据库
conn = connect_to_database()
cursor = conn.cursor()
# 查询每个员工的总销售额
query = """
SELECT
e.name AS employee_name,
SUM(w.total_sales) AS total_sales
FROM
employee e
JOIN
works_with w ON e.emp_id = w.emp_id
GROUP BY
e.name;
"""
cursor.execute(query)
# 获取查询结果
results = cursor.fetchall()
# 处理查询结果
for row in results:
print(f"Employee: {row[0]}, Total Sales: {row[1]}")
# 关闭游标和连接
cursor.close()
conn.close()
if __name__ == "__main__":
fetch_employee_sales()
3. 数据分析和可视化
使用Python中的Pandas库进行数据分析,并使用Matplotlib或Seaborn进行可视化。
首先,确保安装Pandas和Matplotlib:
pip install pandas matplotlib
然后,我们可以扩展上述示例,使用Pandas读取查询结果并进行可视化:
import mysql.connector
import pandas as pd
import matplotlib.pyplot as plt
def connect_to_database():
# 建立数据库连接
conn = mysql.connector.connect(
host='localhost',
user='root',
password='your_password',
database='your_database'
)
return conn
def fetch_employee_sales():
# 连接数据库
conn = connect_to_database()
cursor = conn.cursor()
# 查询每个员工的总销售额
query = """
SELECT
e.name AS employee_name,
SUM(w.total_sales) AS total_sales
FROM
employee e
JOIN
works_with w ON e.emp_id = w.emp_id
GROUP BY
e.name;
"""
cursor.execute(query)
# 获取查询结果并转换为Pandas DataFrame
results = cursor.fetchall()
df = pd.DataFrame(results, columns=['Employee', 'Total Sales'])
# 关闭游标和连接
cursor.close()
conn.close()
return df
def visualize_sales(df):
# 使用Matplotlib进行可视化
plt.figure(figsize=(10, 6))
plt.bar(df['Employee'], df['Total Sales'], color='skyblue')
plt.xlabel('Employee')
plt.ylabel('Total Sales')
plt.title('Employee Total Sales')
plt.show()
if __name__ == "__main__":
df = fetch_employee_sales()
visualize_sales(df)
高级数据处理和可视化
1. 查询每个部门的总销售额以及部门经理的姓名
如何在Python中执行此查询,并将结果进行可视化。
def fetch_branch_sales():
# 连接数据库
conn = connect_to_database()
cursor = conn.cursor()
# 查询每个部门的总销售额以及部门经理的姓名
query = """
SELECT
b.branch_name,
SUM(w.total_sales) AS total_sales,
e.name AS manager_name
FROM
branch b
JOIN
employee e ON b.manager_id = e.emp_id
JOIN
employee emp ON b.branch_id = emp.branch_id
JOIN
works_with w ON emp.emp_id = w.emp_id
GROUP BY
b.branch_name, e.name;
"""
cursor.execute(query)
# 获取查询结果并转换为Pandas DataFrame
results = cursor.fetchall()
df = pd.DataFrame(results, columns=['Branch', 'Total Sales', 'Manager'])
# 关闭游标和连接
cursor.close()
conn.close()
return df
def visualize_branch_sales(df):
# 使用Matplotlib进行可视化
plt.figure(figsize=(12, 6))
branches = df['Branch']
sales = df['Total Sales']
managers = df['Manager']
bars = plt.bar(branches, sales, color='lightgreen')
# 在图表上添加部门经理的姓名
for bar, manager in zip(bars, managers):
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval + 1000, manager, ha='center', va='bottom')
plt.xlabel('Branch')
plt.ylabel('Total Sales')
plt.title('Total Sales by Branch and Manager')
plt.show()
if __name__ == "__main__":
df = fetch_branch_sales()
visualize_branch_sales(df)
2. 创建销售记录表并插入数据
CREATE TABLE `sales_record`(
`record_id` INT PRIMARY KEY,
`emp_id` INT,
`sale_date` DATE,
`amount` DECIMAL(10, 2),
FOREIGN KEY (`emp_id`) REFERENCES `employee`(`emp_id`) ON DELETE CASCADE
);
INSERT INTO `sales_record` (`record_id`, `emp_id`, `sale_date`, `amount`)
VALUES
(1, 1, '2023-01-15', 2000.00),
(2, 2, '2023-02-20', 1500.00),
(3, 2, '2023-03-10', 3000.00),
(4, 1, '2023-03-25', 2500.00);
如果这对您有所帮助,希望点赞支持一下作者! 😊
[ 详细全文-点击查看](
)

原文地址:https://blog.csdn.net/ThsPool/article/details/140209455
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!