Redis 数据类型
概览:
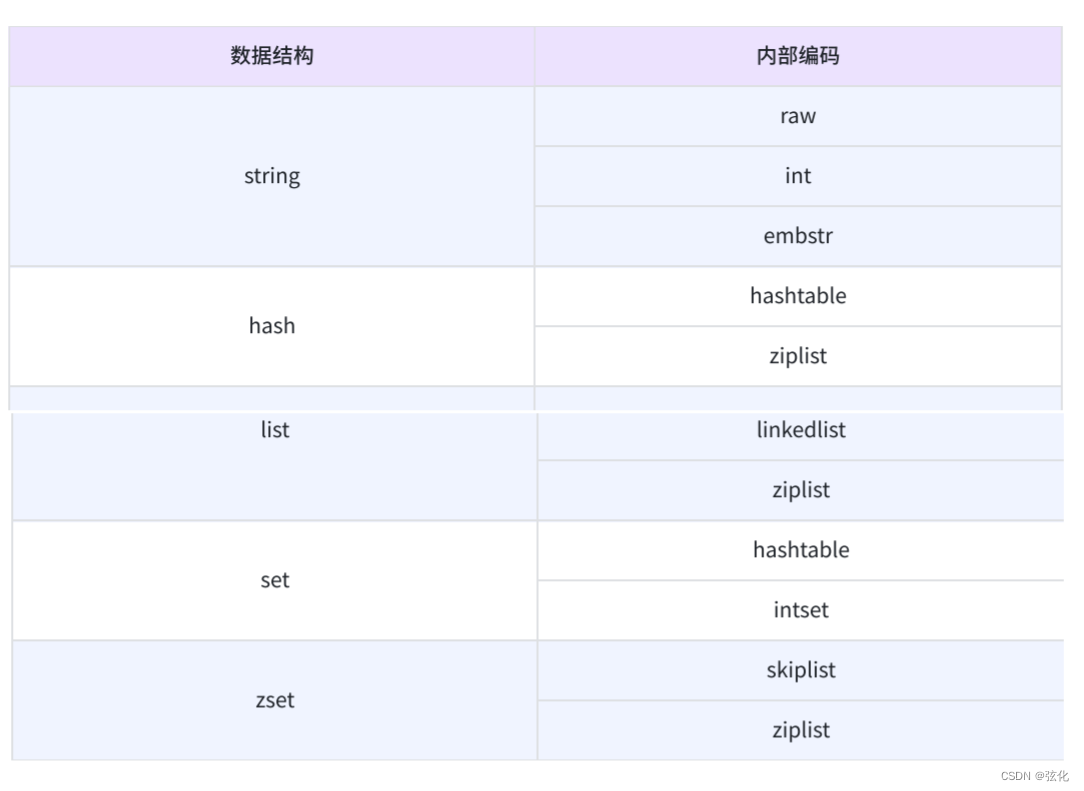
数据结构 :
key = value 中value的类型
内部编码: 实际在底层用来存储value的结构
设计优点:
① 解耦,用户可根据需求再开发内部编码方式
② 实现空间或效率优化, 多种内部编码实现可以在不同场景下发挥各⾃的优势,例如 ziplist ⽐较节省内存,但是在列表元素⽐较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程⽤⼾同样⽆感知。
Reidis 命名规范
与 MySQL 等关系型数据库不同的是,Redis 没有表、字段这种命名空间,⽽且也没有对键名有强制要求(除了不能使⽤⼀些特殊字符)。但设计合理的键名,有利于防⽌键冲突和项⽬ 的可维护性,⽐较推荐的⽅式是使⽤ “业务名:对象名:唯⼀标识:属性” 作为键名。例如 MySQL 的数据库名为 vs,⽤⼾表名为 user_info,那么对应的键可以使⽤ “vs:user_info:6379”、“vs:user_info:6379:name” 来表⽰,如果当前 Redis 只会被⼀个业务 使⽤,可以省略业务名 “vs:”。如果键名过程,则可以使⽤团队内部都认同的缩写替代,例如"user:6379:friends:messages:5217" 可以被 “u:6379🇫🇷m:5217” 代替。毕竟键名过⻓,还是会导致 Redis 的性能明显下降的
String类型
- 基本介绍:
① :String类型是redis最基础的数据类型,其他⼏种数据结构也都是在字符串类似基础上构建的,例如列表和集合的元素类型是字符串类型,所以字符串类型能为其他 4 种数据结构的学习奠定基础。
②:字符串类型的值实际可以是字符串,包含⼀般格式的字符串或者类似 JSON、XML 格式的字符串;数字,可以是整型或者浮点型;甚⾄是⼆进制流数据,例如图⽚、⾳频、视频等。不过⼀个字符串的最⼤值不能超过 512 MB。
③:由于 Redis 内部存储字符串完全是按照⼆进制流的形式保存的,所以 Redis 是不处理字符集编码问题的,客⼾端传⼊的命令中使⽤的是什么字符集编码,就存储什么字符集编码。
- 内部编码:
redis同种数据结构(string)的内部编码不一定相同, Redis会根据当前值的类型和⻓度动态决定使⽤哪种内部编码实现。
字符串类型的内部编码有 3 种:
① int:8 个字节的⻓整型。(数据为纯数字时,redis内部使用)
② embstr:⼩于等于 39 个字节的字符串。(数据为字符串时,redis内部使用)
③ raw:⼤于 39 个字节的字符串。(数据为字符串时,redis内部使用))
Hash 类型
- 基本介绍
①:
Redis 本身的键值对被称为 “key - value”
Redis 提供的Hash类型 为 “field - value”
即Redis中Hash类型的键值对表示为 “key - ’ filed1 - value1 , filed2 - value2 …’ ”
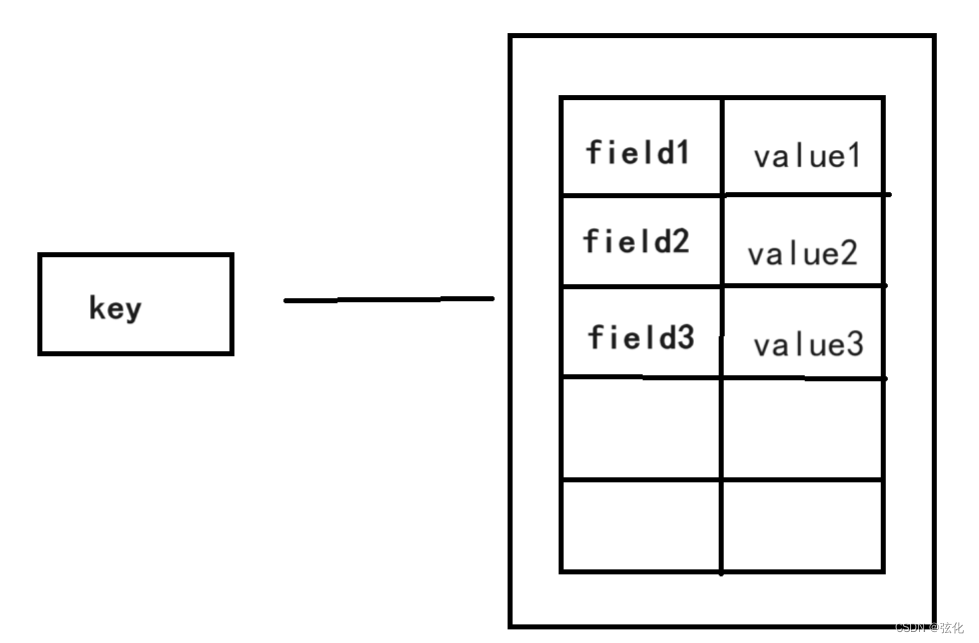
② 对Hash类型的操作使用Hash系列的指令,例如
hset key field value 设置值 O(1)
hget key field 获取值 O(1)
hdel key field [field ...] 删除 field O(k), k 是 fiel个数
- 内部编码
哈希的内部编码有两种:
① ziplist(压缩列表):当哈希类型元素个数⼩于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐hashtable 更加优秀。
② hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,⽽ hashtable 的读写时间复杂度为 O(1)。
- 注意:
① Redis是键值型数据库 、 Redis的Hash类型也是键值类型的、MySQL的数据库是关系型数据库。 关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,⽽关系型数据库⼀旦添加新的列,所有⾏都要为其设置值,即使为 null。关系数据库可以做复杂的关系查询,⽽ Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本⾼。 总结:关系型数据库定义严格,但可以做复杂查询;键值型数据库定义稀疏只能模拟复杂查询,且部分查询方式几乎不可能实现,维护成本高 ;
List 类型
- 基本介绍
①列表类型是⽤来存储多个有序的字符串,List中元素可以重复
②支持对两端进行插入/删除操作
③支持下标访问
④最多可以存储 2^32 -1 个元素。
- 列表类型的内部编码有两种:
① ziplist(压缩列表):当列表的元素个数⼩于 list-max-ziplist-entries 配置(默认 512 个),同时列表中每个元素的⻓度都⼩于 list-max-ziplist-value 配置(默认 64 字节)时,Redis 会选⽤ziplist 来作为列表的内部编码实现来减少内存消耗。
②linkedlist(链表):当列表类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ linkedlist 作为列表的内部实现。
- 相关指令(看看就就好,没需要不用记)
LPUSH key value1 [value2 ...]:将一个或多个值插入到列表的左侧(头部)。
RPUSH key value1 [value2 ...]:将一个或多个值插入到列表的右侧(尾部)。
LPOP key:移除并返回列表的左侧(头部)第一个元素。
RPOP key:移除并返回列表的右侧(尾部)第一个元素。
LINDEX key index:获取列表中指定位置的元素。
LRANGE key start stop:获取列表中指定范围内的元素。
LLEN key:获取列表的长度。
LINSERT key BEFORE|AFTER pivot value:在列表中指定元素的前面或后面插入新元素。
LREM key count value:从列表中删除指定数量的元素。
LSET key index value:设置列表中指定位置的元素的值。
LTRIM key start stop:保留列表中指定范围内的元素,其他元素删除。
blpop/brpop key [key ...] timeout 阻塞指定时间后删除元素
- 使用场景:
. Redis 可以使⽤ lpush + brpop 命令组合实现经典的阻塞式⽣产者-消费者模型队列,⽣产者客⼾端使⽤ lpush 从列表左侧插⼊元素,多个消费者客⼾端使⽤ brpop 命令阻塞式地从队列中"争抢" 队⾸元素。通过多个客⼾端来保证消费的负载均衡和⾼可⽤性。
Set 类型
-
基本介绍:. 集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是;
①集合中元素之间是⽆序的元素不允许重复,⼀个集合中最多可以存储 2^32 - 1个元素。
②Redis 除了⽀持集合内的增删查改操作,同时还⽀持多个集合取交集、并集、差集,合理地使⽤好集合类型,能在实际开发中解决很多问题。 -
内部编码:
①intset(整数集合):当集合中的元素都是整数并且元素的个数⼩于 set-max-intset-entries 配置(默认 512 个)时,Redis 会选⽤ intset 来作为集合的内部实现,从⽽减少内存的使⽤。
②hashtable(哈希表):当集合类型⽆法满⾜ intset 的条件时,Redis 会使⽤ hashtable 作为集合的内部实现
3.使用场景:
集合类型⽐较典型的使⽤场景是标签(tag)。例如 A ⽤⼾对娱乐、体育板块⽐较感兴趣,B ⽤⼾
对历史、新闻⽐较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同⼀个标签
的⼈,以及⽤⼾的共同喜好的标签,这些数据对于增强⽤⼾体验和⽤⼾黏度都⾮常有帮助。 例如⼀个
电⼦商务⽹站会对不同标签的⽤⼾做不同的产品推荐
- 相关指令:
SET key value [EX seconds] [PX milliseconds] [NX|XX] - 将键的值设为指定值,并返回键的旧值,可选设置过期时间和条件判断。
SETEX key seconds value - 将值与键关联,并设置键的过期时间(以秒为单位)。
PSETEX key milliseconds value - 类似于SETEX,但过期时间以毫秒为单位。
SETNX key value - 当键不存在时设置键的值。
MSET key value [key value ...] - 同时设置多个键值对。
MSETNX key value [key value ...] - 同时设置多个键值对,仅当所有给定键都不存在时。
GET key - 返回键关联的值。
GETSET key value - 设置键的值,并返回旧值。
MGET key [key ...] - 返回多个键的值。
STRLEN key - 返回键存储的字符串值的长度。
SETRANGE key offset value - 从指定偏移量开始,覆写键的字符串值。
GETRANGE key start end - 返回键中字符串值的子字符串。
APPEND key value - 如果键存在且为字符串类型,将值追加到键原有值的末尾。
求交集:
SINTER key [key ...]:返回给定所有集合的交集。
SINTERSTORE destination key [key ...]:将给定集合的交集存储到指定的 destination 集合中。
求并集:
SUNION key [key ...]:返回给定所有集合的并集。
SUNIONSTORE destination key [key ...]:将给定集合的并集存储到指定的 destination 集合中
Zset 类型
-
基本介绍
有序集合相对于字符串、列表、哈希、集合来说会有⼀些陌⽣。它保留了集合不能有重复成员的
特点,但与集合不同的是,有序集合中的每个元素都有⼀个唯⼀的浮点类型的分数(score)与之关
联,这使得有序集合中的元素是可以维护有序性的,但这个有序不是⽤下标作为排序依据⽽是⽤这个
分数。有序集合中的元素是不能重复的,但分数允许重复。 -
内部编码
①ziplist(压缩列表):当有序集合的元素个数⼩于 zset-max-ziplist-entries 配置(默认 128 个),
同时每个元素的值都⼩于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会⽤ ziplist 来作
为有序集合的内部实现,ziplist 可以有效减少内存的使⽤。
②skiplist(跳表):当 ziplist 条件不满⾜时,有序集合会使⽤ skiplist 作为内部实现,因为此时
ziplist 的操作效率会下降 -
使用场景
有序集合⽐较典型的使⽤场景就是排⾏榜系统。例如常⻅的⽹站上的热榜信息,榜单的维度可能
是多⽅⾯的:按照时间、按照阅读量、按照点赞量。本例中我们使⽤点赞数这个维度,维护每天的热
榜 -
相关指令
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]:向有序集合添加一个或多个成员,或者更新已存在成员的分数。
NX:只在成员不存在时添加。
XX:只在成员已存在时更新。
CH:修改操作只修改已存在成员的分数,而不添加新成员。
INCR:对成员的分数进行自增操作。
ZCARD key:获取有序集合的成员数量。
ZCOUNT key min max:计算有序集合中指定分数范围内的成员数量。
ZINCRBY key increment member:对有序集合中指定成员的分数进行增加或减少。
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]:计算给定的一个或多个有序集的交集,并将结果集存储在新的有序集合 destination 中。
ZRANGE key start stop [WITHSCORES]:通过索引区间返回有序集合指定区间内的成员。
ZREM key member [member ...]:移除有序集合中的一个或多个成员。
ZREMRANGEBYRANK key start stop:移除有序集合中,指定排名(rank)区间内的所有成员。
ZREMRANGEBYSCORE key min max:移除有序集合中,指定分数范围内的所有成员。
ZSCORE key member:获取有序集合中指定成员的分数。
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]:计算给定的一个或多个有序集的并集,并将结果集存储在新的有序集合 destination 中。
补充
1.渐进式遍历
Redis中的SCAN命令用于渐进式地遍历集合(Set)、有序集合(Sorted Set)、哈希表(Hash)等数据结构。它以游标(cursor)的方式逐步返回数据,支持分批处理数据而不会阻塞 Redis 服务器的其他操作。
SCAN命令的基本语法如下:
SCAN cursor [MATCH pattern] [COUNT count]
其中:
cursor:游标,用于标识当前遍历的位置。
MATCH pattern:可选参数,用于指定匹配模式,只返回与模式匹配的元素。
COUNT count:可选参数,指定每次返回的元素数量,用于控制每次迭代返回的元素个数。
示例用法:
SCAN 0 MATCH prefix* COUNT 10
这个命令从游标0开始,匹配以"prefix"开头的元素,并每次返回最多10个元素。
SCAN命令返回的结果是一个包含两个元素的数组,第一个元素是下一个游标,第二个元素是当前游标位置对应的元素数组。
通过SCAN命令,可以有效地遍历大型数据集,逐步处理数据而不会对 Redis 服务器造成过大的压力
2.Redis中数据分库
许多关系型数据库,例如 MySQL ⽀持在⼀个实例下有多个数据库存在的,但是与关系型数据库⽤字符来区分不同数据库名不同,Redis 只是⽤数字作为多个数据库的实现。Redis 默认配置中是有 16个数据库。select 0 操作会切换到第⼀个数据库,select 15 会切换到最后⼀个数据库。0 号数据库和15 号数据库保存的数据是完全不冲突的(如图 2-30 所⽰),即各种有各⾃的键值对。默认情况下,我们处于数据库 0。
Redis 中虽然⽀持多数据库,但随着版本的升级,其实不是特别建议使⽤多数据库特性。如
果真的需要完全隔离的两套键值对,更好的做法是维护多个 Redis 实例,⽽不是在⼀个
Redis 实例中维护多数据库。这是因为本⾝ Redis 并没有为多数据库提供太多的特性,其次
⽆论是否有多个数据库,Redis 都是使⽤单线程模型,所以彼此之间还是需要排队等待命令
的执⾏。同时多数据库还会让开发、调试和运维⼯作变得复杂。所以实践中,始终使⽤数据
库 0 其实是⼀个很好的选择。
flushdb / flushall 命令⽤于清除数据库,区别在于 flushdb 只清除当前数据库,flushall 会清楚所有数据库。
原文地址:https://blog.csdn.net/WSK1454360679/article/details/136080093
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!