【机器学习300问】130、什么是Seq2Seq?又叫编码器(Encoder)和解码器(Decoder)。
Seq2Seq,全称为Sequence to Sequence,是一种用于处理序列数据的神经网络模型,特别适用于如机器翻译、语音识别、聊天机器人等需要将一个序列转换为另一个序列的任务。这种模型由两部分核心组件构成:编码器(Encoder)和解码器(Decoder)。
一、Seq2Seq的模型结构
在之前我写的文章中,简单介绍了RNN的多种不同结构,其中有一种叫多对多结构。这种结构具体细分为两种类型:一种是输入输出序列长度相等的对称型多对多结构,另一种是输入与输出序列长度不等的非对称型多对多结构。想复习一下的同学可以看看哦:
【机器学习300问】118、循环神经网络(RNN)的基本结构是怎样的?![]() https://blog.csdn.net/qq_39780701/article/details/139685879
https://blog.csdn.net/qq_39780701/article/details/139685879
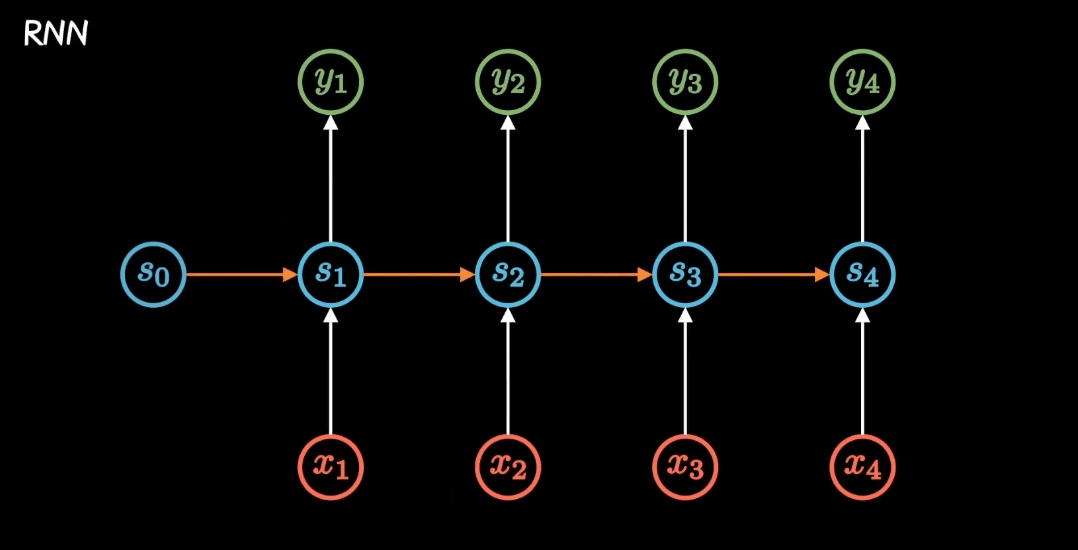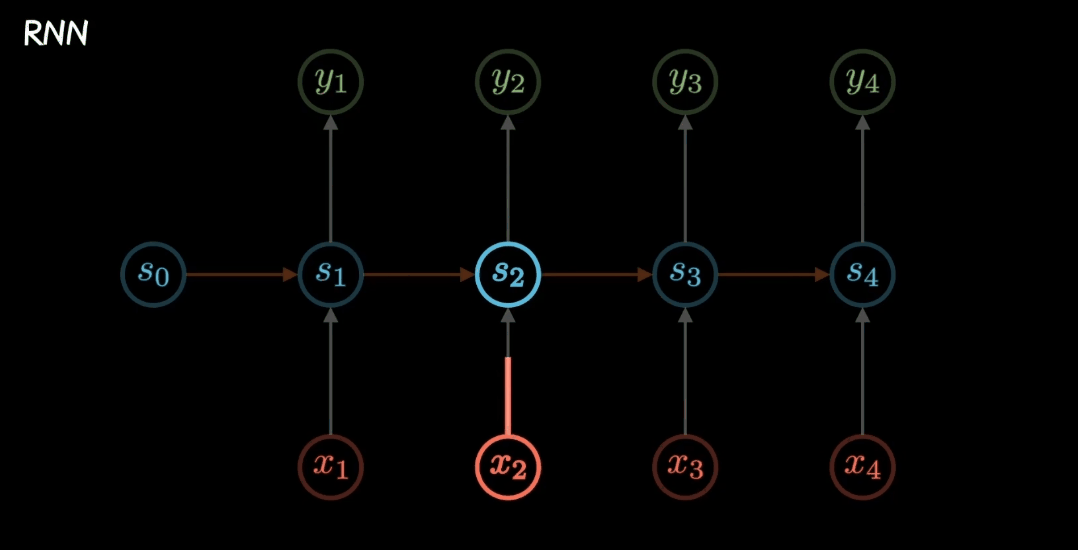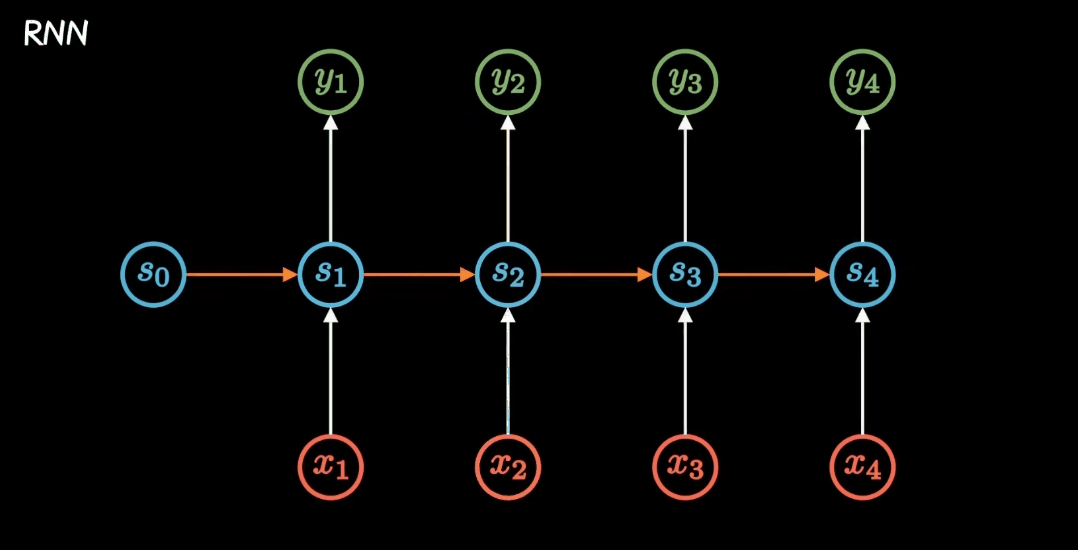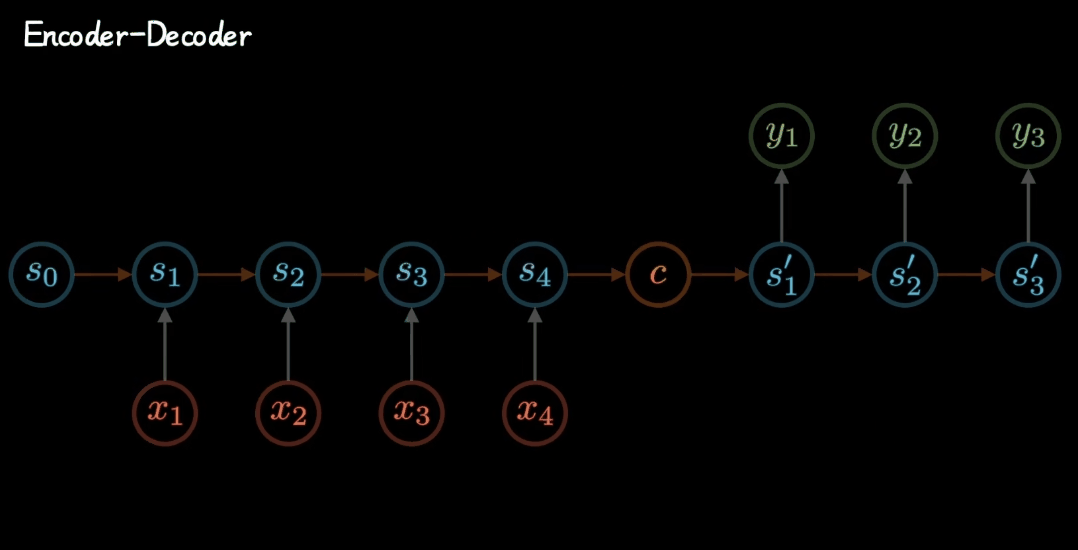
Seq2Seq模型,作为RNN的一种特定形式,不仅继承了RNN的基本特性,还以其独特的网络形态展现出了强大的能力。更具体地说,Seq2Seq模型由编码器(Encoder)和解码器(Decoder)两部分构成,这两部分各自扮演着不同的角色,共同完成了从输入序列到输出序列的转换过程。
(1)编码器(Encoder)
负责读取并理解输入序列。它将输入序列中的每个元素(比如单词或者音素)转换成一个高维向量表示,这个过程可以看作是将原始序列的信息压缩到一个固定长度或可变长度的向量中,我们称之为上下文向量(Context Vector)或者编码状态(Encoded State)。编码器通常使用循环神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来实现,因为这些网络结构能够很好地处理序列数据中的时间依赖性。
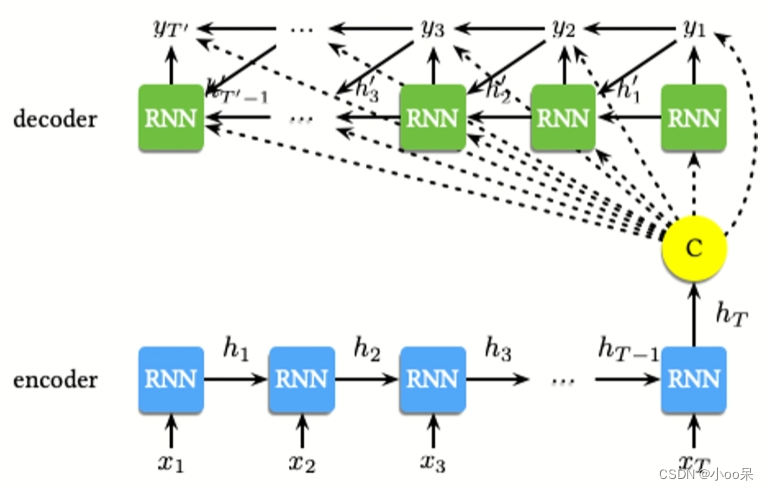
(2)解码器(Decoder)
基于编码器产生的上下文向量,生成目标序列。解码器同样常采用循环神经网络结构,并且其第一个时间步的输入可能是一个特殊的开始标记(如在机器翻译中常用的“<sos>”),以及编码器的最终状态。解码器逐步生成目标序列的每一个元素,直到产生结束标记(如“<eos>”)为止。
二、Seq2Seq模型的目标是什么?
Seq2Seq模型的目标是在给定一个输入序列的情况下,生成一个相关的输出序列,使得整个模型能够执行如机器翻译、对话生成、文本摘要等任务。
(1)目标函数
对于Seq2Seq模型,目标函数(loss function)通常是最小化输出序列与真实序列间的某种距离,这通常是通过最大化给定输入序列情况下的输出序列的条件概率来实现的。即给定输入序列
的条件下,输出序列
出现的概率。这个概率可以分解为各个时间步的概率的乘积:
在这个公式中,是输出序列,
是输入序列。
表示模型参数,
表示在给定模型参数下,给定输入序列
前
个输出单词
的条件下,生成下一个单词
的条件概率。
为了优化这个目标函数,模型在训练过程中会使用如最大似然估计等方法来调整其参数,确保能够为给定的输入序列生成最有可能的正确输出序列。
三、以机器翻译为例说明Seq2Seq模型的工作原理
在机器翻译任务中,其目标是构建一个系统,能够准确、流畅地将原文句子转换为目标文句子。原文与目标文的长度是不一定相等的。

(1)输入编码
- 输入序列:句子首先被转换成计算机可理解的形式,通常是分词,然后每个词被映射到一个向量表示(词嵌入)。
- 编码过程:这些词嵌入序列被送入编码器,编码器通常由一个或多个循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)。编码器的目的是捕获输入序列的上下文信息,并将其压缩成一个固定长度的向量(上下文向量或编码状态),该向量试图包含整个输入序列的语义信息。
(2)输出编码
- 初始化:解码器开始时可能会接收到一个特殊的开始标记(如"<sos>"),以及编码器产生的上下文向量。
- 逐词生成:解码器以生成序列的方式工作,每一步基于先前生成的单词(及其隐藏状态)、编码器的输出以及可能的注意力权重,预测下一个最有可能的英文单词。这一过程重复,直到生成结束标记(如"<eos>")或达到预设的最大长度。
- 预测与生成:每一步,解码器都会输出一个概率分布,表示下一个词的可能性。通常使用如贪婪解码、束搜索(Beam Search)等策略来从这个分布中选择实际的单词,以生成最终的翻译句子。
【注】如果词典太大,模型搜索所有词的概率找出最大概率的词所花费的时间颇巨,Seq2Seq模型是如何解决这个问题?可以采取简单的策略如贪婪解码,或者常用策略集束搜索(Beam Search)。
(3)计算损失
在训练阶段,模型会计算其预测序列与真实翻译之间的差异,通常使用交叉熵损失函数。通过反向传播和梯度下降等优化算法,模型参数被逐步调整,以最小化这个损失,从而提高翻译的准确性。
原文地址:https://blog.csdn.net/qq_39780701/article/details/139862415
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!