鸿蒙多线程开发——Worker多线程

1、概 述
1.1、基本介绍
Worker主要作用是为应用程序提供一个多线程的运行环境,可满足应用程序在执行过程中与主线程分离,在后台线程中运行一个脚本进行耗时操作,极大避免类似于计算密集型或高延迟的任务阻塞主线程的运行。
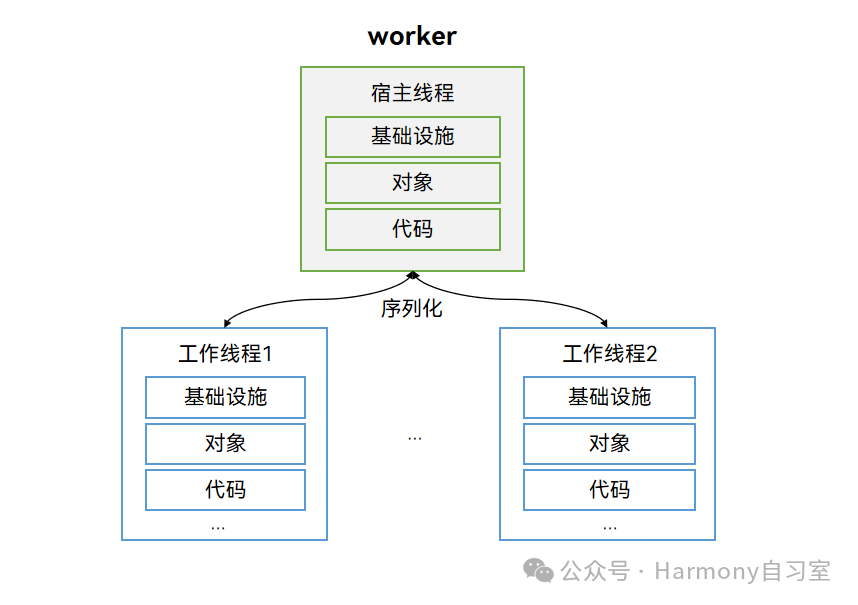
创建Worker的线程称为宿主线程(不一定是主线程,工作线程也支持创建Worker子线程),Worker自身的线程称为Worker子线程(或Actor线程、工作线程)。每个Worker子线程与宿主线程拥有独立的实例,包含基础设施、对象、代码段等,因此每个Worker启动存在一定的内存开销,需要限制Worker的子线程数量。Worker子线程和宿主线程之间的通信是基于消息传递的,Worker通过序列化机制与宿主线程之间相互通信,完成命令及数据交互。示意图如下:
1.2、注意事项
-
创建Worker时,有手动和自动两种创建方式,手动创建Worker线程目录及文件时,还需同步进行相关配置。
👉🏻 手动创建:开发者手动创建相关目录及文件,此时需要配置build-profile.json5的相关字段信息,Worker线程文件才能确保被打包到应用中。配置代码如下:
"buildOption": {"sourceOption": {"workers": ["./src/main/ets/workers/worker.ets"]}}
👉🏻 自动创建:DevEco Studio支持一键生成Worker,在对应的{moduleName}目录下任意位置,点击鼠标右键 > New > Worker,即可自动生成Worker的模板文件及配置信息,无需再手动在build-profile.json5中进行相关配置。
-
使用Worker能力时,构造函数中传入的Worker线程文件的路径在不同版本有不同的规则。示例如下(不同场景中,加载的url路径规则有所不同,细则看后文【1.3、Woker文件路径规则】)
// 导入模块import { worker } from '@kit.ArkTS';// API 9及之后版本使用:const worker1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ets');// API 8及之前版本使用:const worker2: worker.Worker = new worker.Worker('entry/ets/workers/MyWorker.ets');
-
Worker创建后需要手动管理生命周期,且最多同时运行的Worker子线程数量为64个。
-
Worker的创建和销毁耗费性能,建议我们合理管理已创建的Worker并重复使用。Worker空闲时也会一直运行,因此当不需要Worker时,可以调用terminate()接口或close()方法主动销毁Worker。若Worker处于已销毁或正在销毁等非运行状态时,调用其功能接口,会抛出相应的错误。
-
Worker的数量由内存管理策略决定,设定的内存阈值为1.5GB和设备物理内存的60%中的较小者。在内存允许的情况下,系统最多可以同时运行64个Worker。如果尝试创建的Worker数量超出这一上限,系统将抛出错误:“Worker initialization failure, the number of workers exceeds the maximum.”。实际运行的Worker数量会根据当前内存使用情况动态调整。一旦所有Worker和主线程的累积内存占用超过了设定的阈值,系统将触发内存溢出(OOM)错误,导致应用程序崩溃。
-
-
由于不同线程中上下文对象是不同的,因此Worker线程只能使用线程安全的库(例如UI相关的非线程安全库不能使用)
-
序列化传输的数据量大小限制为16MB。
-
使用Worker模块时,需要在主线程中注册onerror接口,否则当Worker线程出现异常时会发生jscrash问题。
-
不支持跨HAP使用Worker线程文件。
-
创建Worker对象时仅允许加载本模块下存在的Worker线程文件,不支持加载其他模块的Worker线程文件。若依赖其他模块提供的Worker功能,需要将Worker实现的整套逻辑封装到方法中,将方法导出后供其他模块使用。
-
引用HAR/HSP前,需要先配置对HAR/HSP的依赖。
-
不支持在Worker工作线程中使用AppStorage。
1.3、Woker文件路径规则
构造函数中的scriptURL要求如下:
-
scriptURL的组成包含 {moduleName}/ets 和相对路径 relativePath。
-
relativePath是Worker线程文件相对于"{moduleName}/src/main/ets/"目录的相对路径。
👉🏻 场景1:加载Ability中的Worker线程文件
加载Ability中的worker线程文件,加载路径规则:{moduleName}/ets/{relativePath}。
import { worker } from '@kit.ArkTS';// worker线程文件所在路径:"entry/src/main/ets/workers/worker.ets"const workerStage1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/worker.ets');// worker线程文件所在路径:"phone/src/main/ets/ThreadFile/workers/worker.ets"const workerStage2: worker.ThreadWorker = new worker.ThreadWorker('phone/ets/ThreadFile/workers/worker.ets');
👉🏻 场景2:加载HSP中的Worker线程文件
加载HSP中worker线程文件,加载路径规则:{moduleName}/ets/{relativePath}。
import { worker } from '@kit.ArkTS';// worker线程文件所在路径:"hsp/src/main/ets/workers/worker.ets"const workerStage3: worker.ThreadWorker = new worker.ThreadWorker('hsp/ets/workers/worker.ets');
👉🏻 场景3:加载HSP中的Worker线程文件
加载HAR中worker线程文件存在以下两种情况:
-
@标识路径加载形式:所有种类的模块加载本地HAR中的Worker线程文件,加载路径规则:@{moduleName}/ets/{relativePath}。
-
相对路径加载形式:本地HAR加载该包内的Worker线程文件,加载路径规则:创建Worker对象所在文件与Worker线程文件的相对路径.
import { worker } from '@kit.ArkTS';// @标识路径加载形式:// worker线程文件所在路径: "har/src/main/ets/workers/worker.ets"const workerStage4: worker.ThreadWorker = new worker.ThreadWorker('@har/ets/workers/worker.ets');// worker线程文件所在路径: "har/src/main/ets/workers/worker.ets"// 创建Worker对象的文件所在路径:"har/src/main/ets/components/mainpage/MainPage.ets"const workerStage5: worker.ThreadWorker = new worker.ThreadWorker('../../workers/worker.ets');
2、案 例
下面将使用一个CPU密集型任务来做案例。
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。
基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。
当任务不需要长时间(3分钟)占据后台线程,而是一个个独立的任务时,推荐使用TaskPool,反之推荐使用Worker。开发步骤如下:
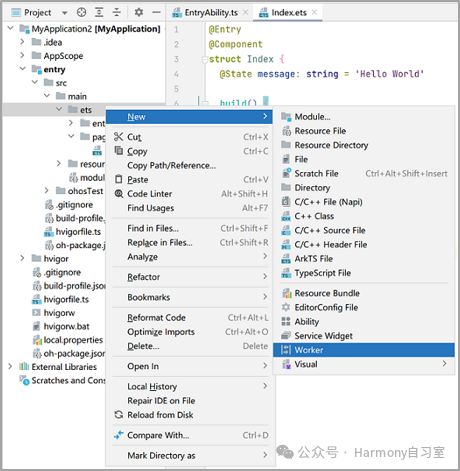
👉🏻 step 1:DevEco Studio提供了Worker创建的模板,新建一个Worker线程,例如命名为“MyWorker”。
👉🏻 step 2:在主线程中通过调用ThreadWorker的constructor()方法创建Worker对象,当前线程为宿主线程。
// Index.etsimport { worker } from '@kit.ArkTS';const workerInstance: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');
👉🏻 step 3: 在宿主线程中通过调用onmessage()方法接收Worker线程发送过来的消息,并通过调用postMessage()方法向Worker线程发送消息。
例如向Worker线程发送训练和预测的消息,同时接收Worker线程发送回来的消息。
// Index.etslet done = false;// 接收Worker子线程的结果workerInstance.onmessage = (() => {console.info('MyWorker.ts onmessage');if (!done) {workerInstance.postMessage({ 'type': 1, 'value': 0 });done = true;}})workerInstance.onerror = (() => {// 接收Worker子线程的错误信息})// 向Worker子线程发送训练消息workerInstance.postMessage({ 'type': 0 });
👉🏻 step 4: 在MyWorker.ts文件中绑定Worker对象,当前线程为Worker线程。
// MyWorker.tsimport { worker, ThreadWorkerGlobalScope, MessageEvents, ErrorEvent } from '@kit.ArkTS';let workerPort: ThreadWorkerGlobalScope = worker.workerPort;
👉🏻 step 5:在Worker线程中通过调用onmessage()方法接收宿主线程发送的消息内容,并通过调用postMessage()方法向宿主线程发送消息。
例如在Worker线程中定义预测模型及其训练过程,同时与主线程进行信息交互。
// MyWorker.ts// 定义训练模型及结果let result: Array<number>;// 定义预测函数function predict(x: number): number {return result[x];}// 定义优化器训练过程function optimize(): void {result = [0];}// Worker线程的onmessage逻辑workerPort.onmessage = (e: MessageEvents): void => {// 根据传输的数据的type选择进行操作switch (e.data.type as number) {case 0:// 进行训练optimize();// 训练之后发送主线程训练成功的消息workerPort.postMessage({ type: 'message', value: 'train success.' });break;case 1:// 执行预测const output: number = predict(e.data.value as number);// 发送主线程预测的结果workerPort.postMessage({ type: 'predict', value: output });break;default:workerPort.postMessage({ type: 'message', value: 'send message is invalid' });break;}}
👉🏻 step 6:在Worker线程中完成任务之后,执行Worker线程销毁操作。销毁线程的方式主要有两种:根据需要可以在宿主线程中对Worker线程进行销毁;也可以在Worker线程中主动销毁Worker线程。
在宿主线程中通过调用onexit()方法定义Worker线程销毁后的处理逻辑。
// Worker线程销毁后,执行onexit回调方法workerInstance.onexit = (): void => {console.info("main thread terminate");}// 方式一:在宿主线程中通过调用terminate()方法销毁Worker线程,并终止Worker接收消息。// 销毁Worker线程workerInstance.terminate();// 方式二:在Worker线程中通过调用close()方法主动销毁Worker线程,并终止Worker接收消息。// 销毁线程workerPort.close();
原文地址:https://blog.csdn.net/harmonyClassRoom/article/details/143650533
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!