面试经典150题——从中序与后序遍历序列构造二叉树

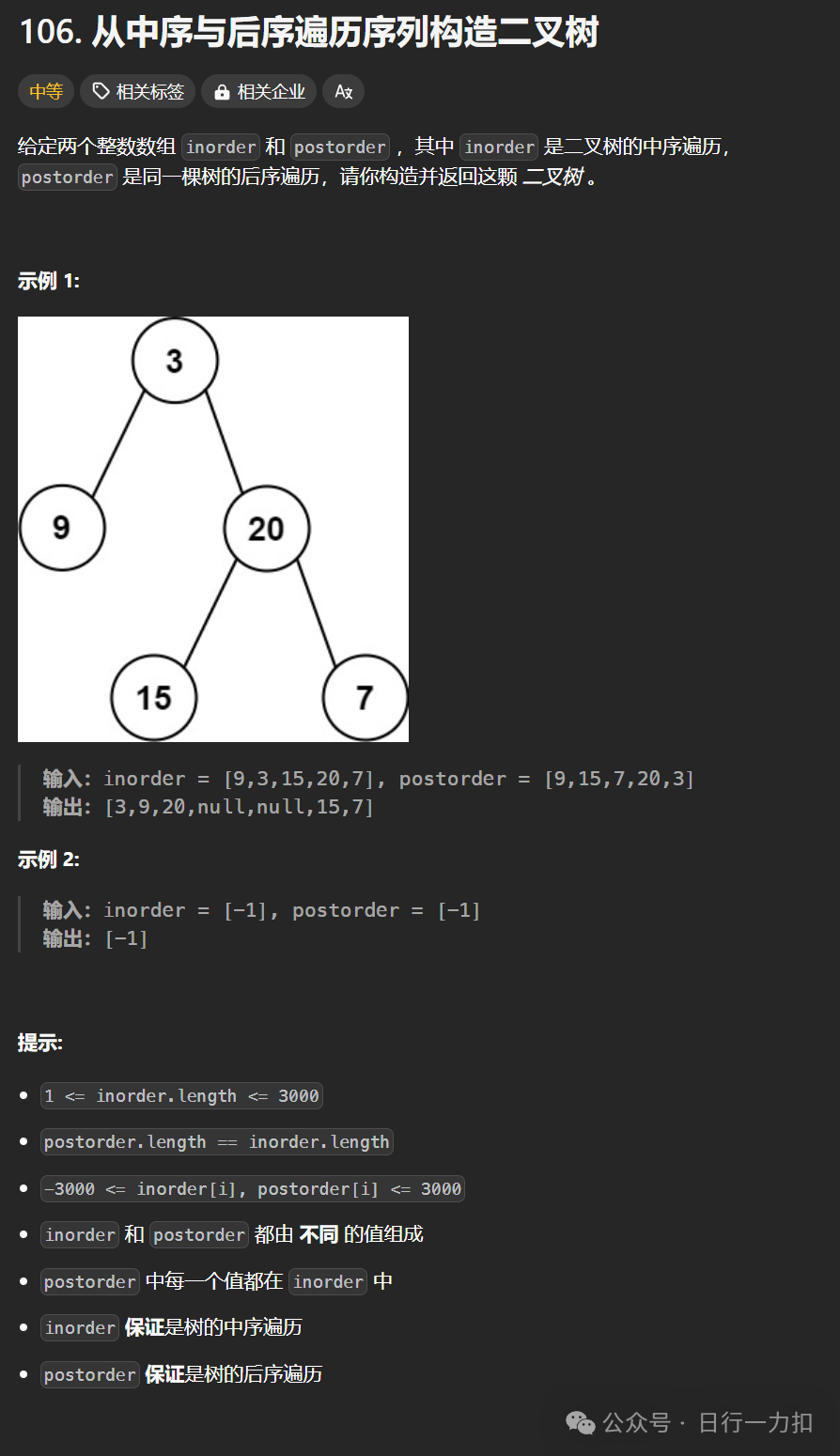
1. 题目描述
2. 题目分析与解析
其实这个题目和昨天那个很相似,思考思路如下:
解决从中序(inorder)与后序(postorder)遍历序列构造二叉树的问题时,考虑到这两个遍历序列为我们提供了树结构中节点的位置信息。
-
理解遍历序列的特性:
-
中序遍历:对于任何给定的树,中序遍历首先遍历左子树,然后是根节点,最后是右子树。因此,如果我们知道根节点的位置,我们可以确定哪部分是左子树,哪部分是右子树。
-
后序遍历:后序遍历首先遍历左子树,然后是右子树,最后是根节点。在后序遍历的数组中,最后一个元素总是根节点。
-
-
使用后序遍历确定根节点:
-
根据后序遍历的特性,数组的最后一个元素是当前子树的根节点。这为我们提供了一个切入点,从后序数组的末尾开始构建树。
-
-
利用中序遍历定位左右子树:
-
一旦我们从后序遍历中识别出根节点,我们可以在中序遍历数组中找到这个根节点的位置。根据中序遍历的性质,根节点将数组分割为左右子树。
-
知道左右子树的节点数量后,我们可以递归地使用同样的方法构建左右子树。
-
-
使用HashMap优化查找:
-
在中序数组中频繁查找根节点的位置可能非常耗时,特别是在大数据集上。因此,通过使用HashMap来存储中序遍历中每个值的索引,我们可以将查找时间降到O(1)。
-
-
递归构建:
-
使用上述找到的索引和节点数,我们递归地构建左子树和右子树。每次递归都会缩小问题的规模,直至到达叶节点。
-
-
考虑边界情况:
-
在构建过程中,如果发现没有更多的节点可以用于构建子树(即左边界超过右边界),这时应该返回null,表示当前没有子树。
-
通过以上思路,利用中序和后序遍历的独特属性和递归方法,我们就可以高效地重构出原始的二叉树结构。
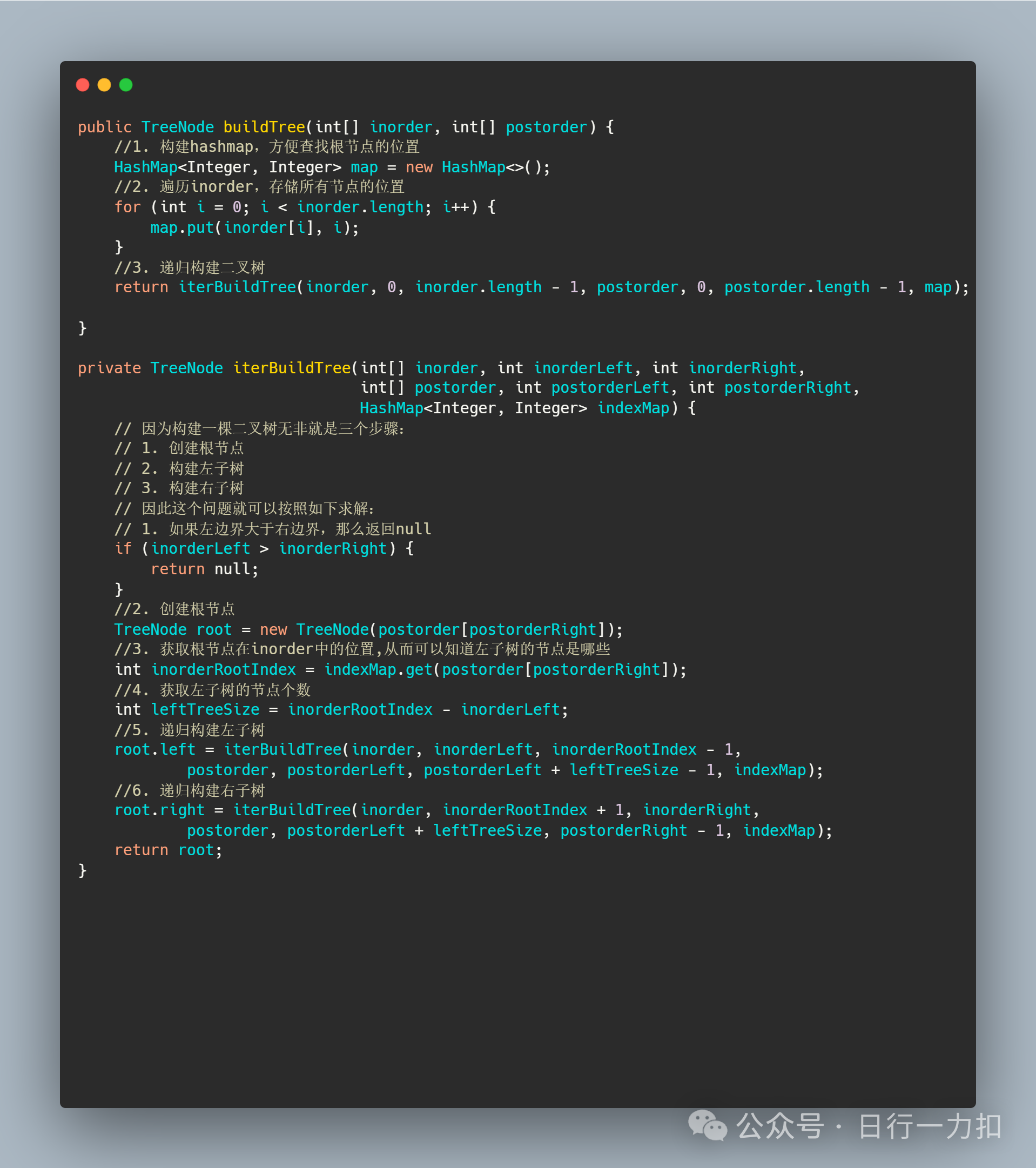
3. 代码实现

4. 相关复杂度分析
时间复杂度
-
递归调用:我们对每个节点都执行一次递归操作,来构建这个节点作为根的子树。每次递归会处理一个节点,并且总的节点数量等于数组的长度。
-
查找根节点索引:使用HashMap存储中序遍历中每个元素的索引,使得每次查找根节点的索引时的时间复杂度降至O(1)。初始化这个HashMap的时间复杂度为O(n),其中n是遍历数组的长度。
-
计算左右子树的大小:这一步只涉及简单的算术运算,因此其时间复杂度为O(1)。
综上所述,虽然每次递归调用中包含了对HashMap的O(1)时间复杂度操作,但因为每个节点都会被处理一次,总的时间复杂度为O(n),其中n是树中节点的数量。
空间复杂度
-
递归栈的空间:在最坏情况下,如果树完全不平衡(例如,每个节点只有左子节点或只有右子节点),递归的深度可以达到n。因此,递归栈的空间复杂度为O(n)。
-
HashMap的空间:HashMap存储了中序遍历中每个节点值及其对应的索引,因此需要O(n)的空间。
-
参数和临时变量:这些额外的存储需求相对较小,可以视为常数级别。
因此,算法的总体空间复杂度也是O(n),主要由递归栈和HashMap的存储需求决定。这种空间复杂度在二叉树的递归构建问题中是比较常见的,特别是在处理大型数据结构时需要注意这一点。
原文地址:https://blog.csdn.net/m0_60388871/article/details/137961342
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!